Elastic Stack
1.[Elastic Stack] Filebeat LogBack multiline pattern 적용하기

여러 서비스에 여러대의 BE 서버를 구성하여 운영중에 있다.서비스의 로그를 확인하기 위해서 해당 서비스의 BE 서버에 접속하여 로그를 확인해야 하는 매우 큰 불편함이 있어 Kafka 강의를 들으면서 이걸 써먹어야 겠다는 생각이 들어서 Dev BE 서버에 Elastic
2.[Elastic Stack] Logstash Multi Grok Pattern 적용하기

Logstash에서 Grok Pattern을 적용해서 사용중에 있다.그러다가 같은 log에서 UUID, MongoDB의 ObjectId 등을 Grok Pattern으로 걸러내고 싶은 경우가 생겨 여러 시도를 해본결과 Grok Pattern을 여러개 적용한 방법을 기록해
3.[Elastic Stack] 서비스, 서버 구분하기

0. Summary > Elastic Stack 을 구축을 하고 Kibana에서 모니터링을 할 때 서비스, 서버 구분을 위해 Logstash에서 Multi Topic 설정과 Filebeat Fields를 추가하는 방법을 기록하려고 한다. 1, Architecture
4.[Filebeat] Filebeat Kafka output 설정

ELK를 구성할 때 로그 수집이 필요한 서버에 Filebeat를 설치하여 Kafka로 전송하는 방법에 대한 내용이다. (kafka 다운로드 및 설정은 작성하지 않는다.) 1. Filebeat Download > 우선 로그를 수집할 서버에 filebeat를 다운받는다.
5.[Elastic Stack] Kibana에서 ilm 설정
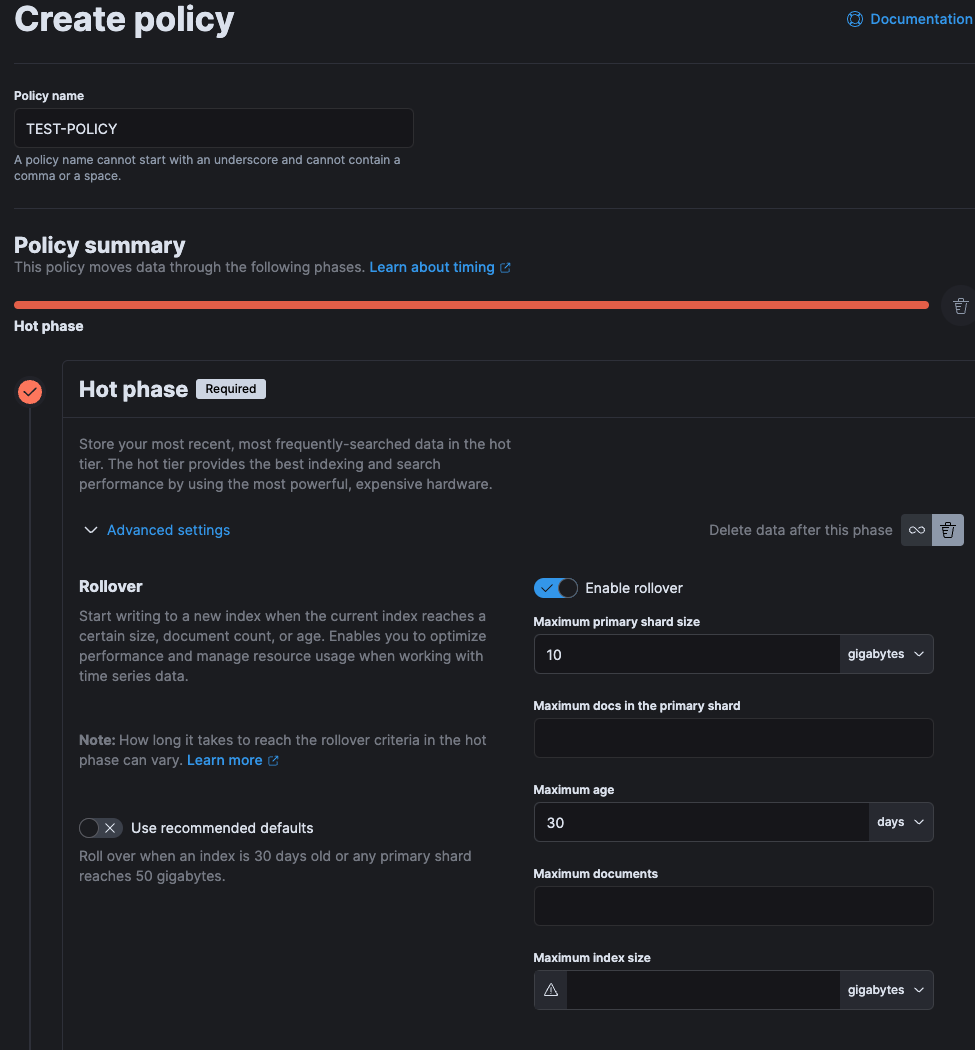
Elastic Stack 구축 후 많은 로그들이 쌓이면서 EC2 디스크 용량이 가득 차는 현상이 발생하여 Elastic Search Index lifeCycle을 Kibana 인터페이스로 관리하는 방법에 대해 정리해 볼려고 한다.Elastic Search의 Index
6.[ELK] 인덱스 삭제 후 로그 수집이 안되는 경우

개발 서버 로그 Index에 Geo-IP를 추가해볼려고 여러 설정을 추가하다가 Index에 Error가 발생해서 현재 쌓이고 있던 Index를 삭제를 진행 했다. 그러자 인덱스 자동 생성이 안되고, 로그 수집이 중단되는 현상이 있어서 인덱스를 살리는 방법에 대해 알아