☕️ 개요
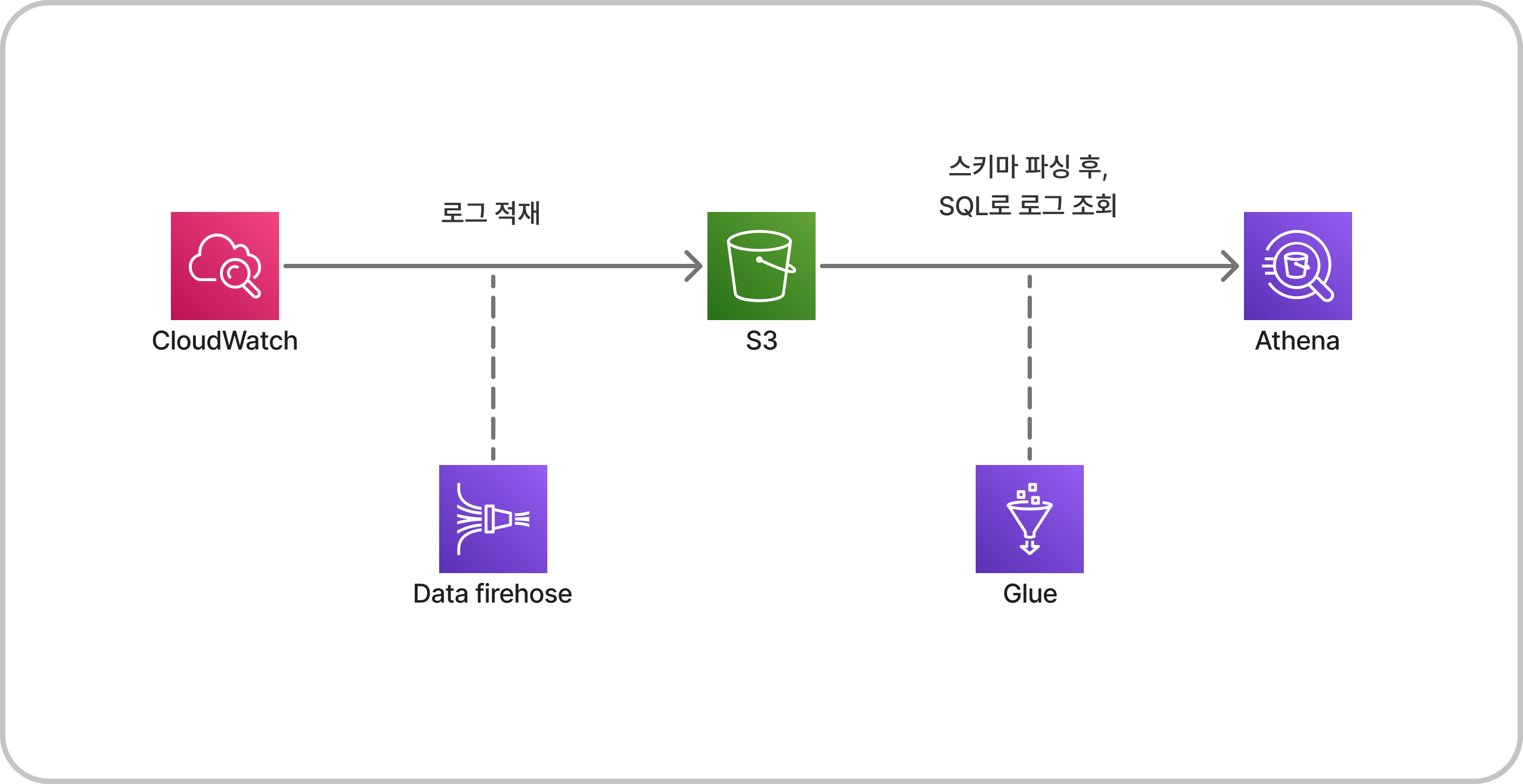
이번 글에서는 AWS CloudWatch 로그를 Data firehose를 이용해서 S3에 적재한 후, 이 로그를 Athena를 통해서 조회할 수 있도록 파이프라인을 구축해보도록 하겠다.
🧙♂️ S3 버킷 생성
버킷은 특별한 설정없이 적당한 이름으로 만들어주기만 하면 된다.
👩🚒 Data firehose 스트림 만들기
1) 소스 및 대상 설정
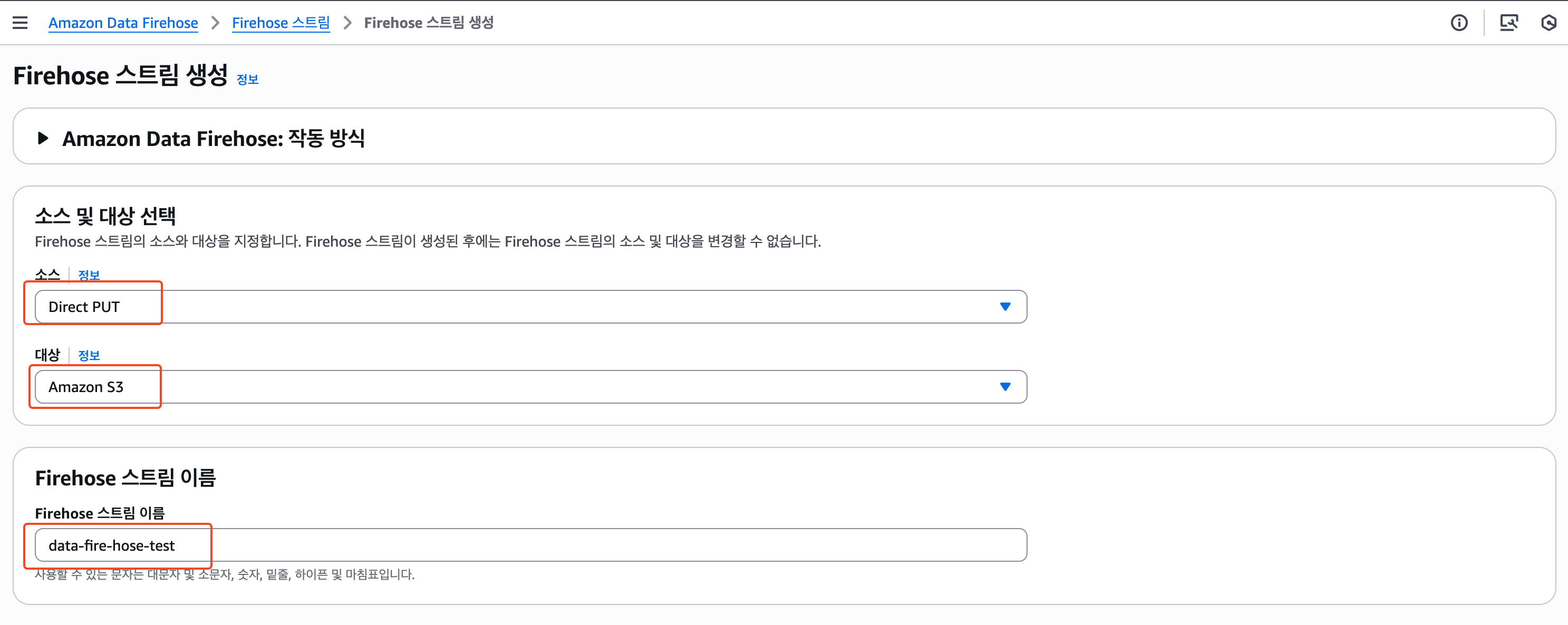
CloudWatch로그를 S3로 적재하는 경우, 소스는 DirectPUT으로 설정하고 대상은 Amazon S3로 설정한다.
2) 레코드 변형 및 변환 ⭐️
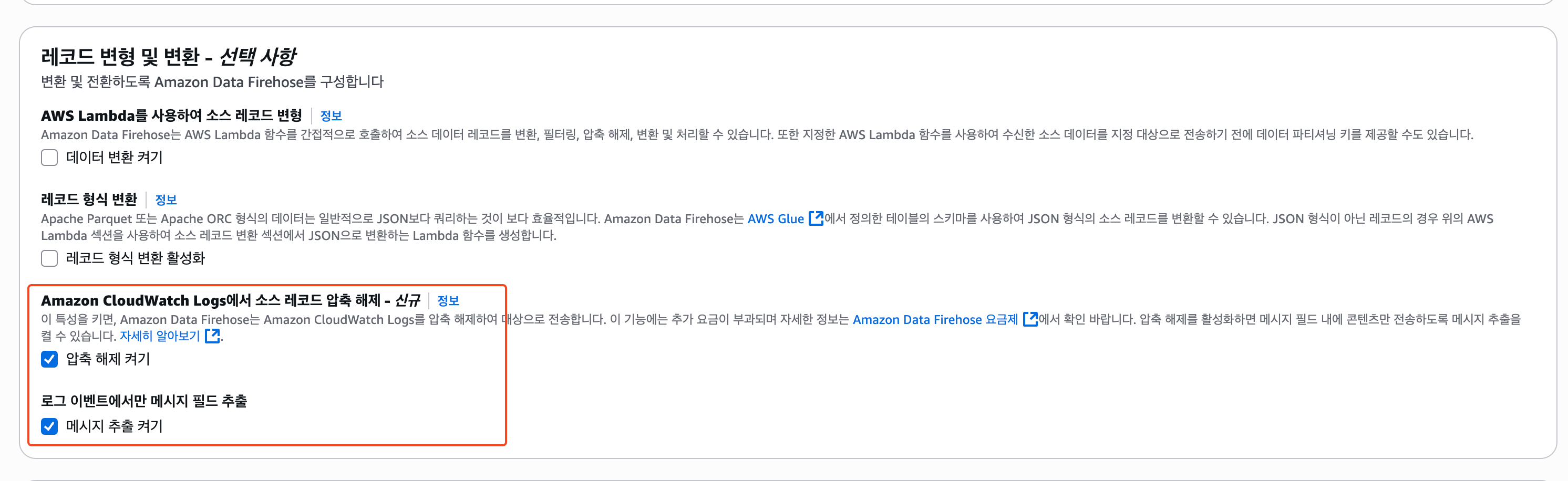
이 설정의 경우, 각자가 기록하고 있는 CloudWatch의 로그 형식과 필요하다면 형변환까지 하는 것을 고려해서 설정해야한다.

나의 경우에는 위와 같이 CloudWatch를 Json형식으로 적재하고 있으므로, 별도의 형변환이나 압축 없이 바로 처리하도록 설정하였다.
3) 대상 설정
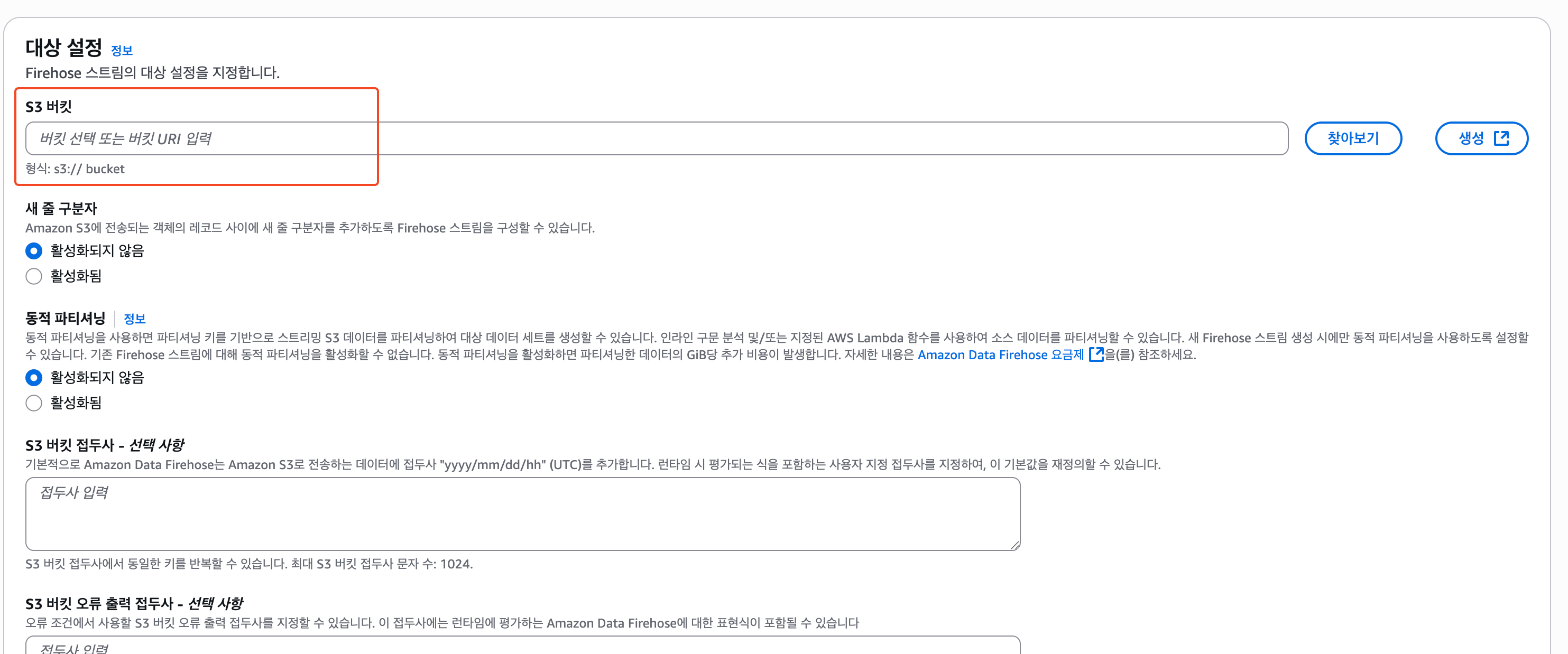
대상에는 이전에 만든 S3를 찾아서 선택해준다.
4) IAM Role 부여
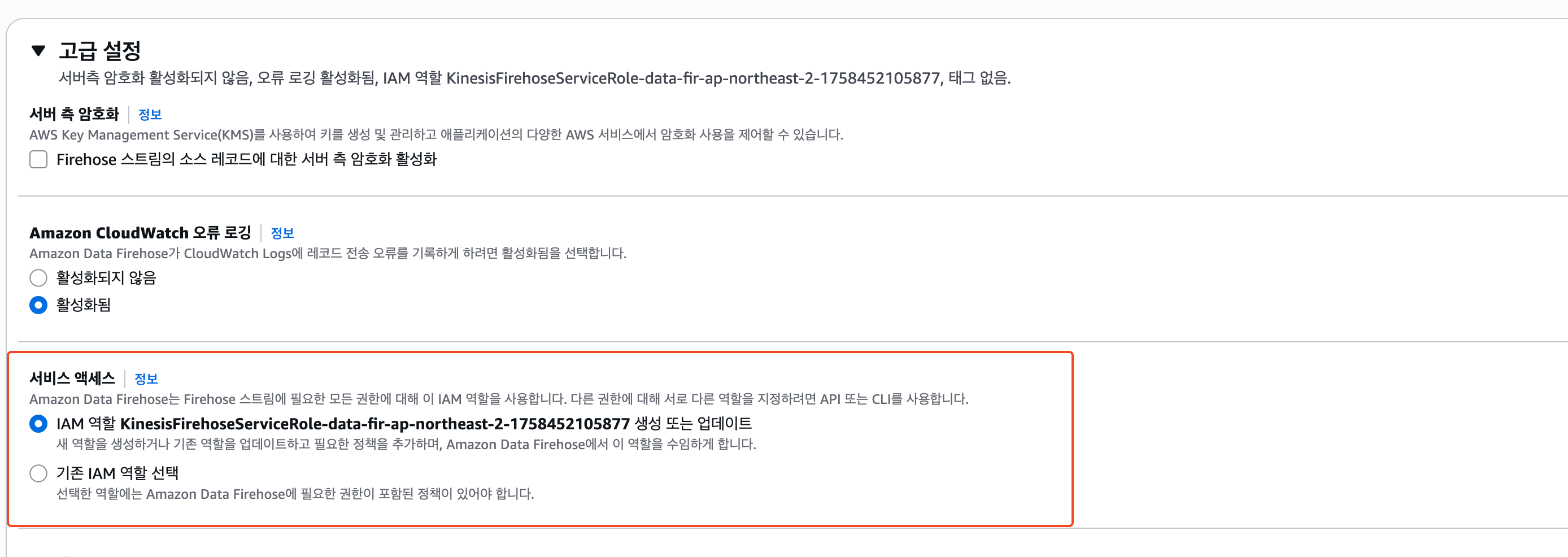
Firehose를 생성하기 전, 고급 옵션을 열어보면 IAM Role 관련 설정이 있는데 별도로 생성해준 Role이 있다면 그 Role을 선택하고 그렇지 않다면 자동으로 생성해주는 것을 사용한다.
🚀 CloudWatch 구독 필터 생성
1) 구독 필터 생성
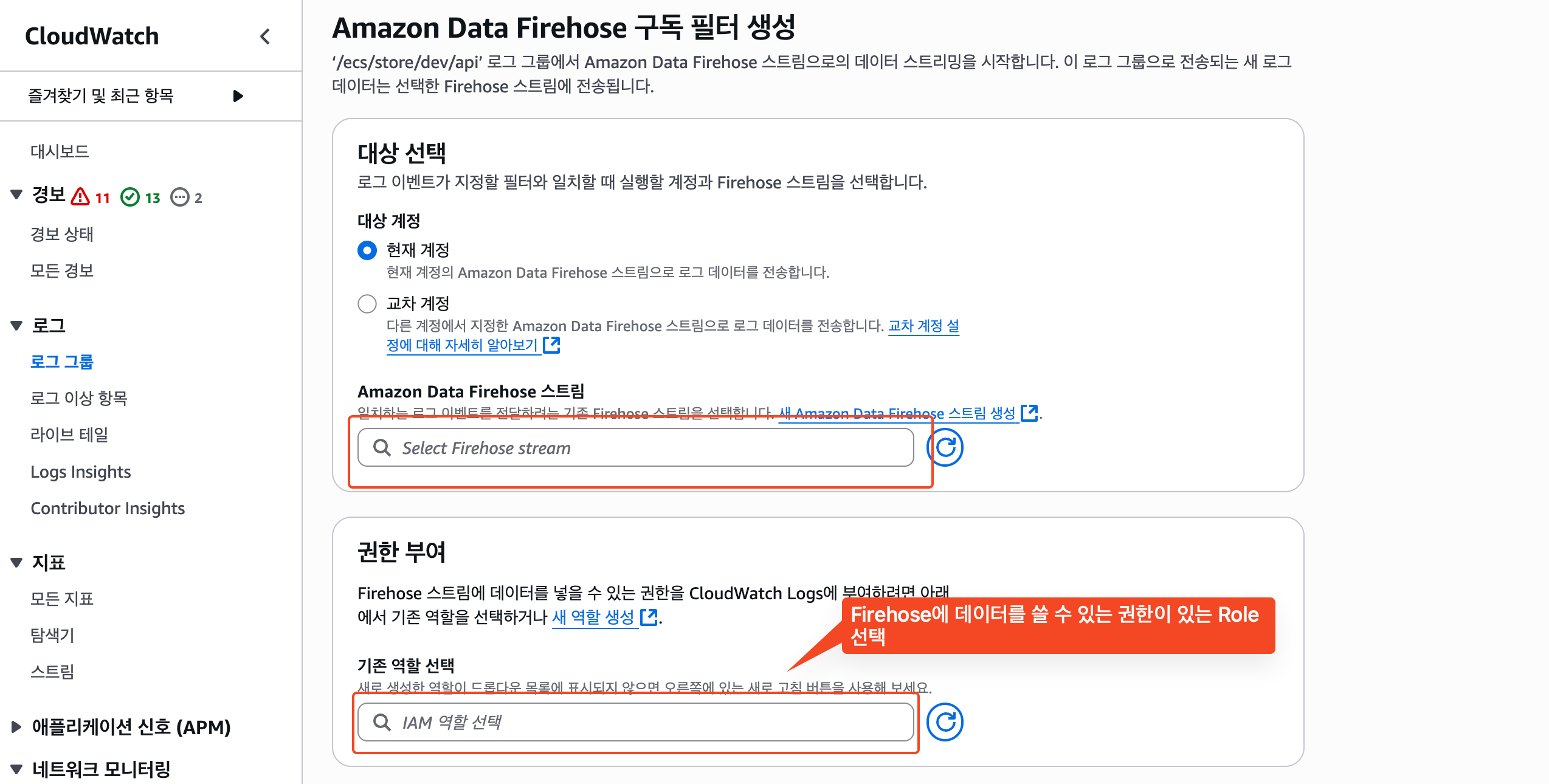
CloudWatch 콘솔로 이동한 후, 구독 필터를 만들고자하는 로그 그룹을 선택한 후, Data firehose로 구독 필터를 생성한다.
Data firehose는 이전에 생성한 Firehose를 선택하고, Role은 Firehose에 데이터를 쓸 수 있는 Role을 선택해준다. 없다면, 새롭게 만들어준다.
2) 로그 형식 및 필터 구성 ⭐️
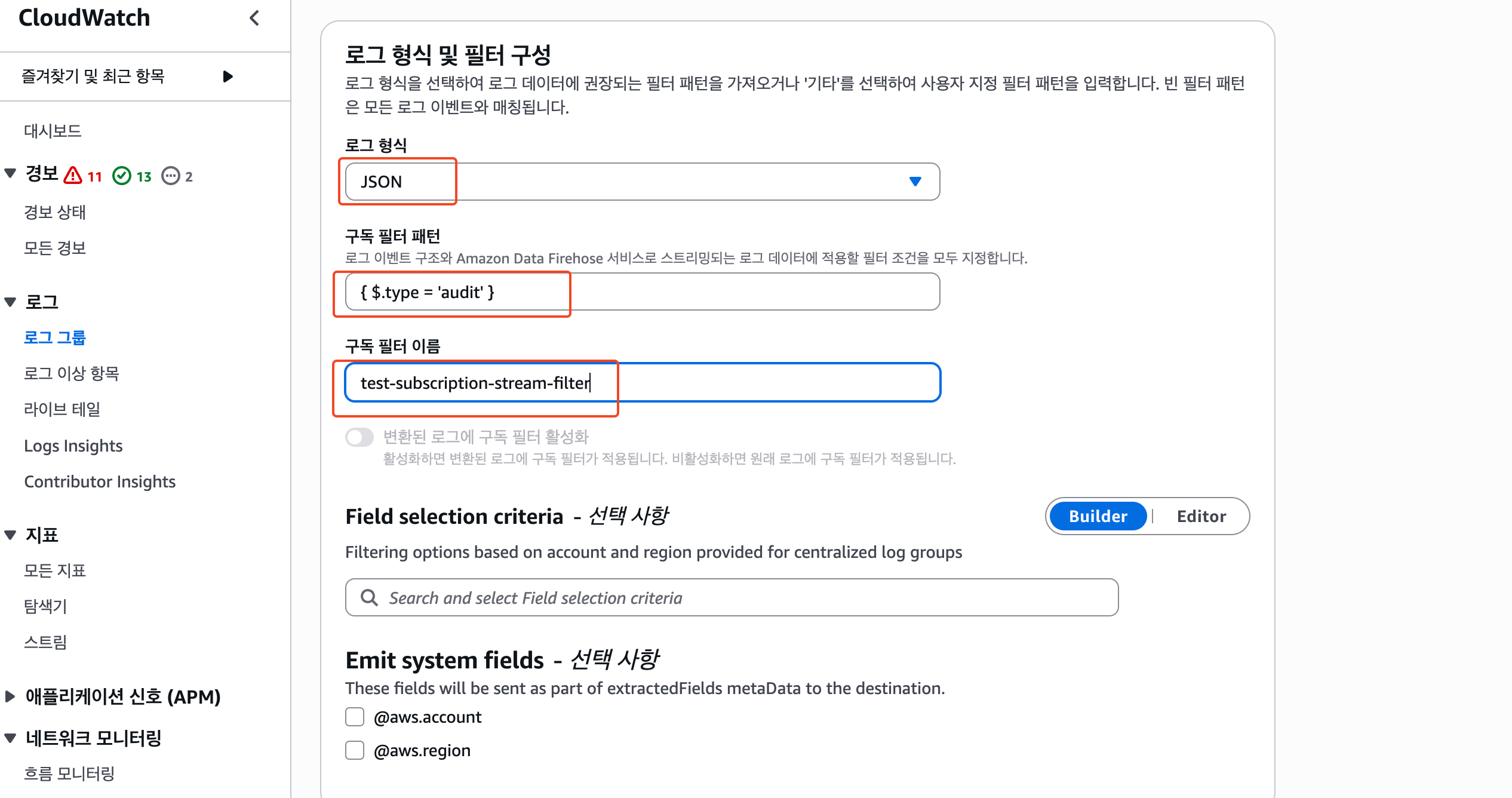
이 부분도 위에서 이야기한 것처럼 각자의 CloudWatch에 적재되고 있는 로그의 형식에 맞게 설정해줘야한다. 나는 JSON으로 적재되고 있고, 그 중에서도 type이 audit인 로그들만을 구독하도록 설정해보았다.
💡 구독 필터 패턴
{ $.type = 'audit' } 이런 패턴은 아래와 같은 Json객체에 대해서 첫번째 뎁스에 있는 type이라는 필드의 값이 audit인 것을 필터링한다는 의미이다.
{
"...": "...",
"type": "audit",
"...": "..."
}3) 필터 패턴 테스트
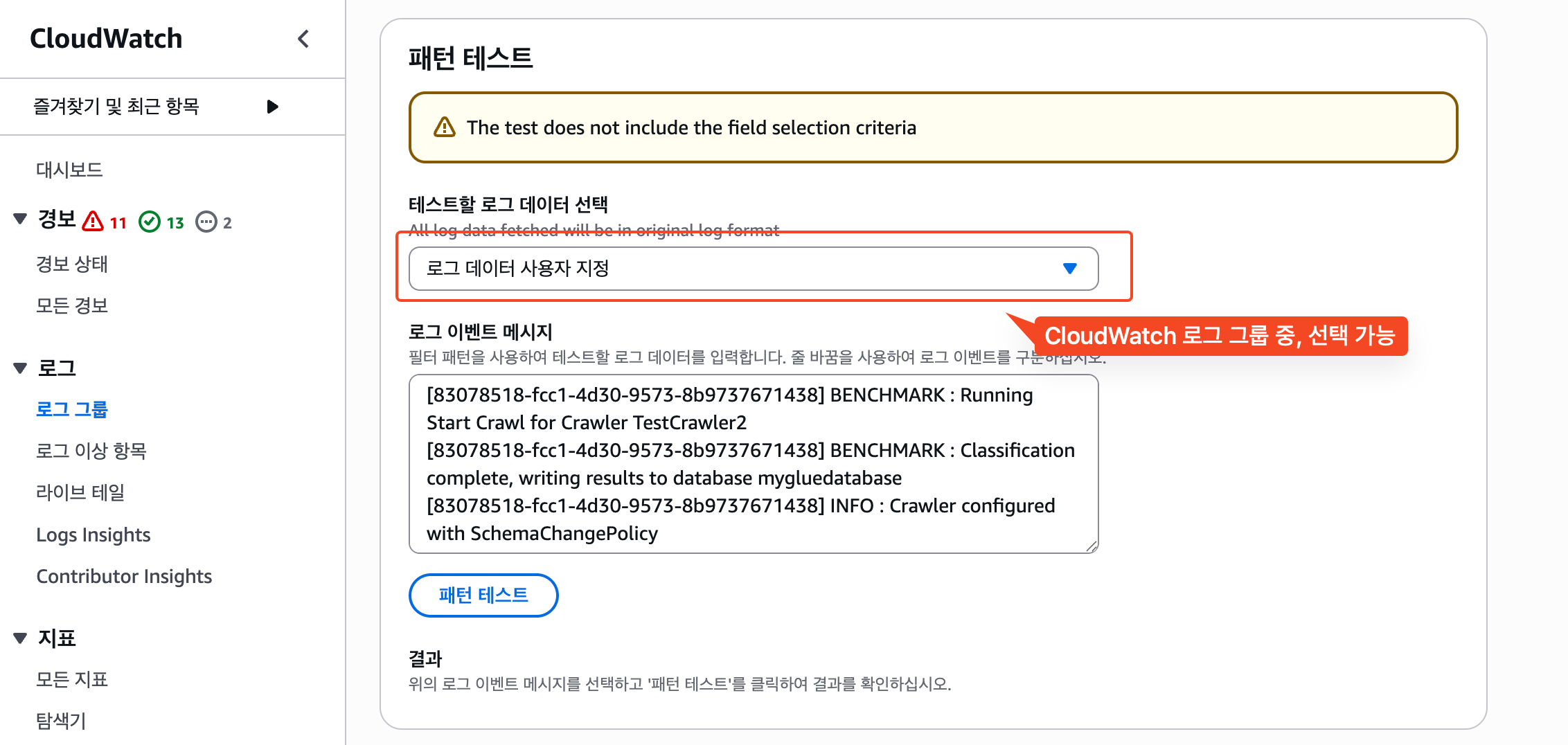
구독 필터 패턴을 입력한 후, 특정 로그 그룹을 선택해서 정상적으로 필터링되는지 테스트할 수도 있다.
4) 동작 확인
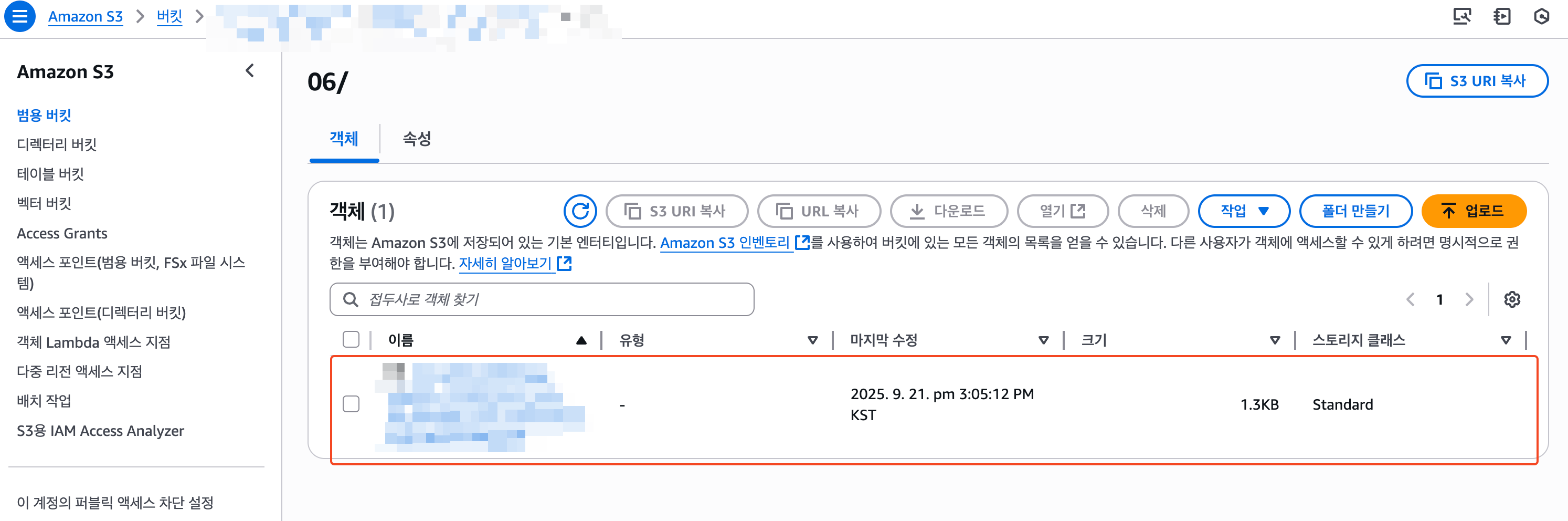
구독 필터까지 생성한 후, 잠시 기다리면 S3에 위와 같이 로그가 정상적으로 적재된 것을 확인할 수 있다.
📔 Glue crawler로 로그에서 스키마 뽑아내기
CloudWatch 로그를 Data firehose로 S3에 적재한 거은 단순히 옮겨 담은 것에 불과하다.
이렇게 옮겨 담은 데이터에서 '유의미'를 도출하기 위해서는 추가적인 처리가 필요한데, 나는 Glue crawler로 로그 데이터에서 Data catalog 테이블 스키마를 뽑아내보도록 하겠다.
1) Crawler 생성하기
2) Data source 연결
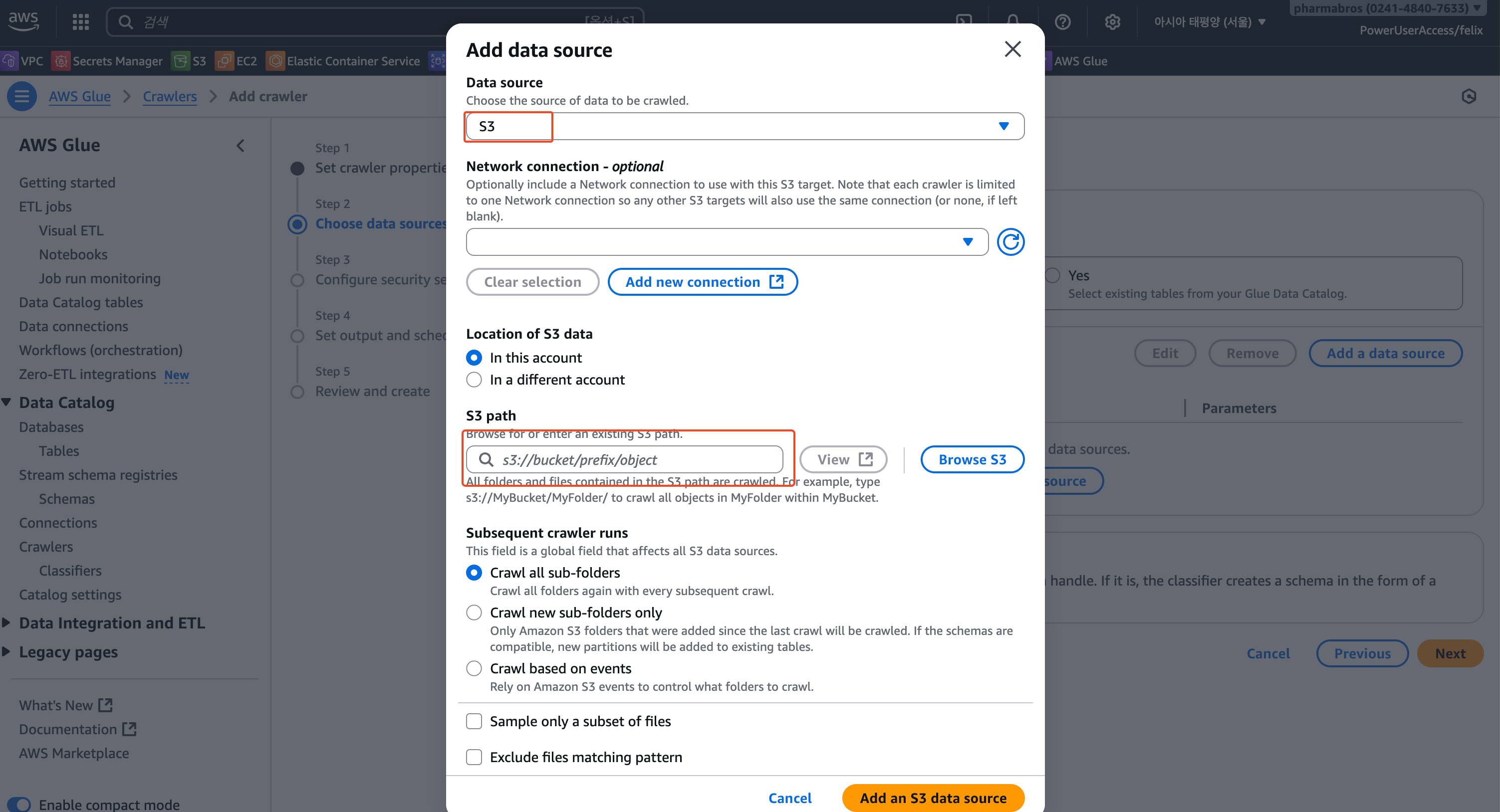
CloudWatch 로그가 적재된 S3를 Crawler의 Data source로 지정해준다.
3) IAM Role 부여
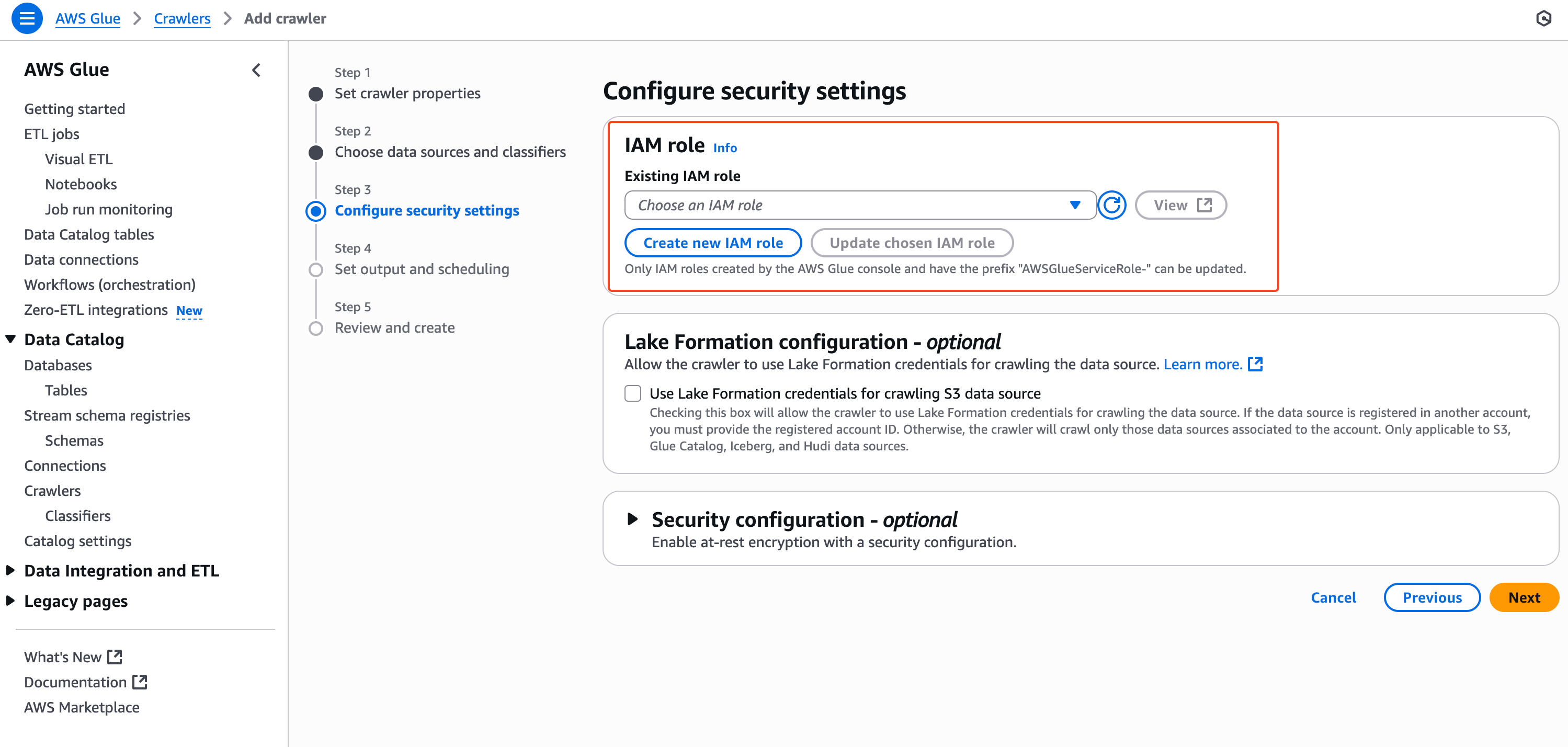
Cralwer가 S3를 읽을 수 있도록 Role을 입력해줘야하는데, 자동으로 생성해주는 Role을 사용하겠다.
4) 크롤링 결과와 스케줄 설정
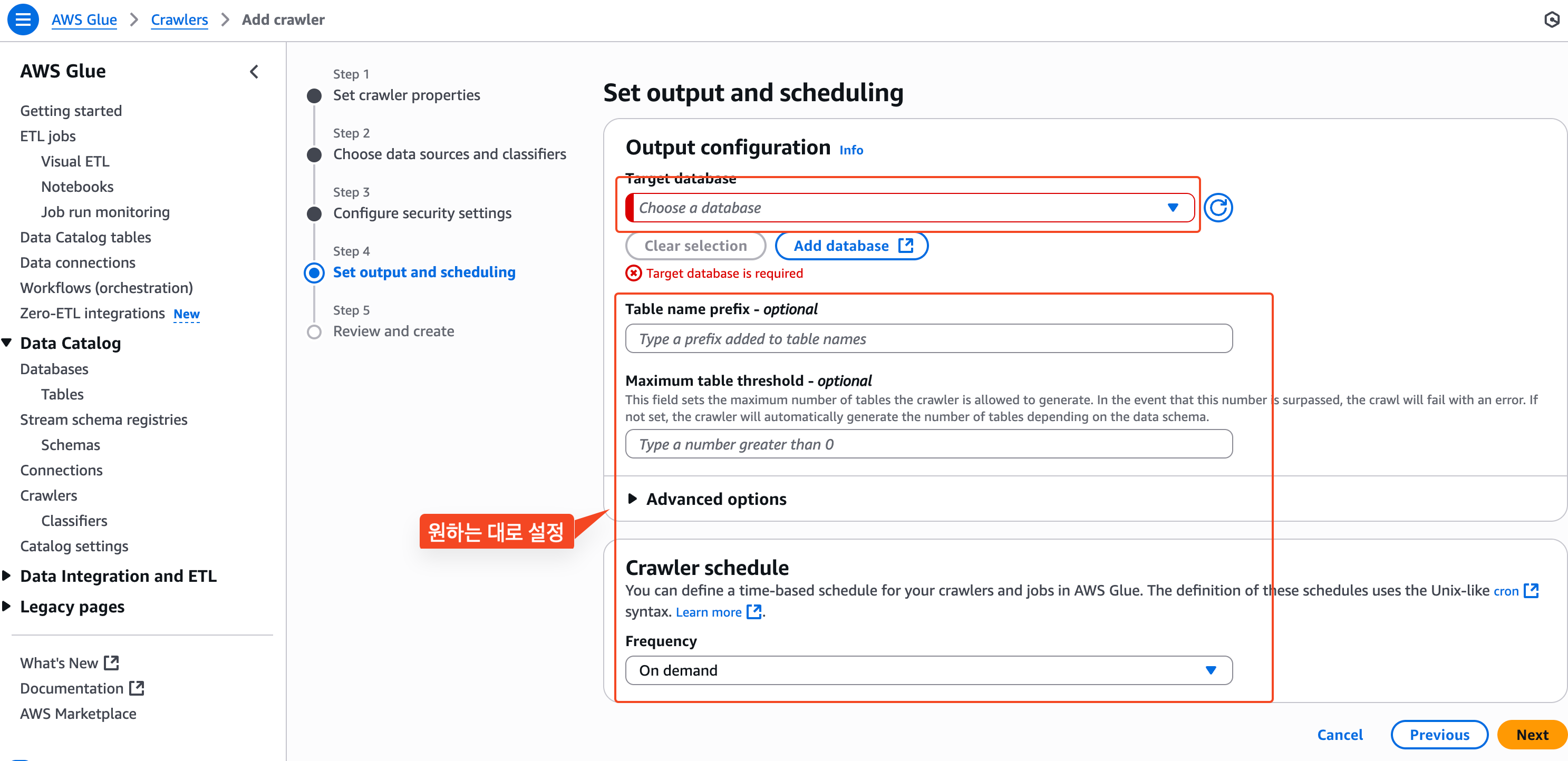
이 부분은 각자가 원하는대로 설정해주면 된다.
Data catalog 데이터베이스, 테이블 명을 입력해주고, 얼만큼의 간격으로 주기적으로 크롤링을 해줄 것인지 선택한다.
그리고, 최종 검토 후 '생성'버튼을 누르면, Cralwer가 생성된다.
5) 크롤링 실행 & 결과 확인
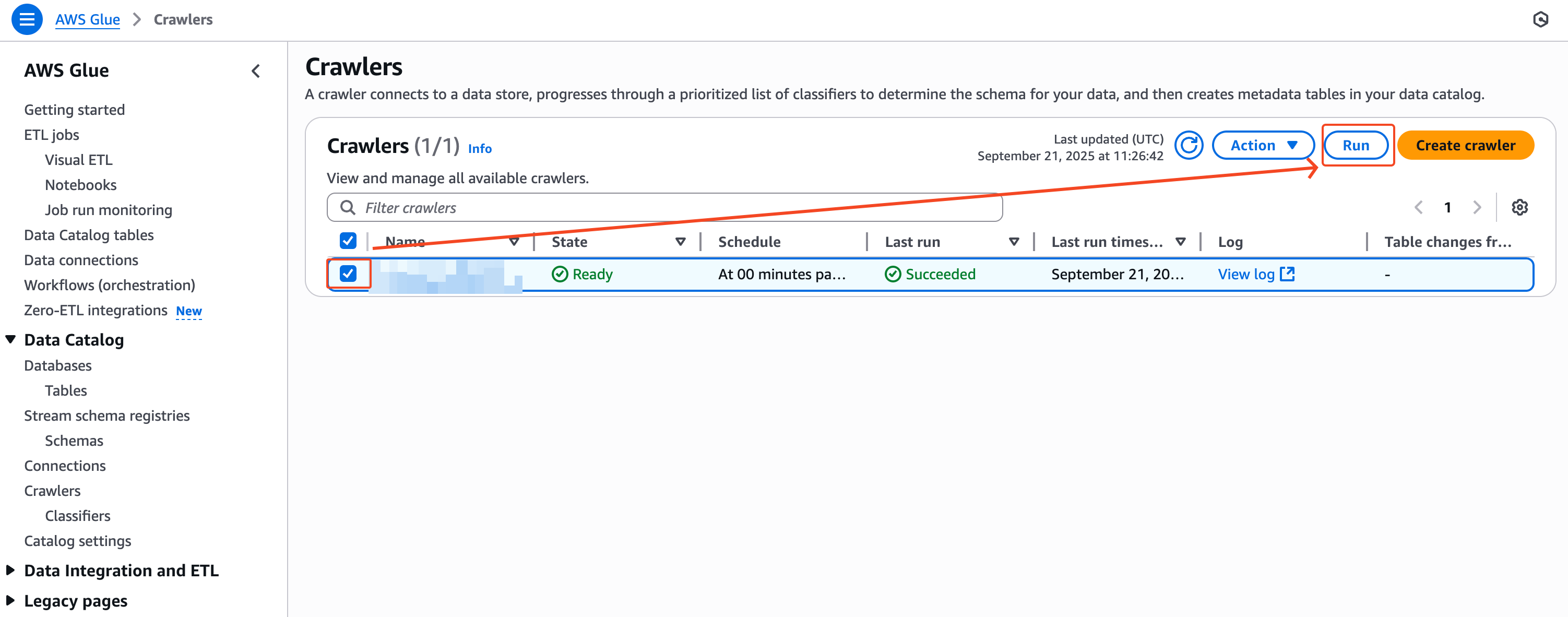
이렇게 만들어진 크롤러를 실행한다.
그리고, 그 결과는 아래와 같이 확인할 수 있다.
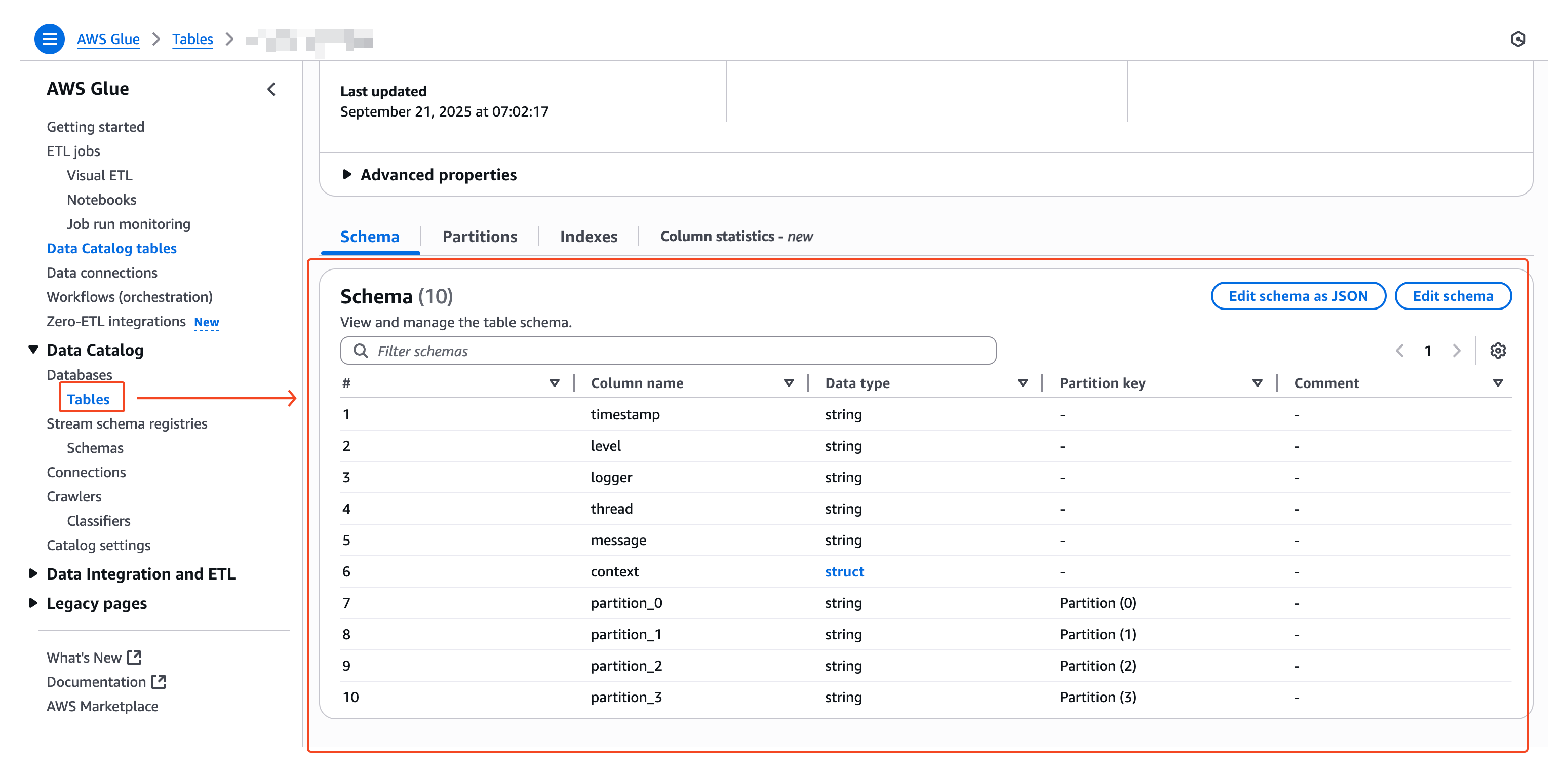
💡 Data catalog 테이블의 의미
- AWS에는 서로 다른 많은 데이터 관련 서비스들이 있는데, Data catalog 테이블을 생성했다는 것은 여러 데이터 서비스에서 참조할 공통적인 규약 생성된 것을 의미한다.
- 이를 통해서 다양한 데이터 분석 환경 구축할 수 있는 기본 토대가 마련된 것이다.
👨🎨 Athena로 쿼리 실행하기
Data catalog 테이블을 생성한 후, 가장 간단하게 테이블을 사용해볼 수 있는 서비스가 바로 Athena이다.
우리가 S3에 적재한 CloudWatch 로그도 Athena로 조회해보자.
1) Athena 결과 저장할 버킷 설정
Athena의 쿼리 결과를 저장할 S3가 필요한데, 적당히 만들어 준 후 연결해준다.
2) 쿼리 실행하기
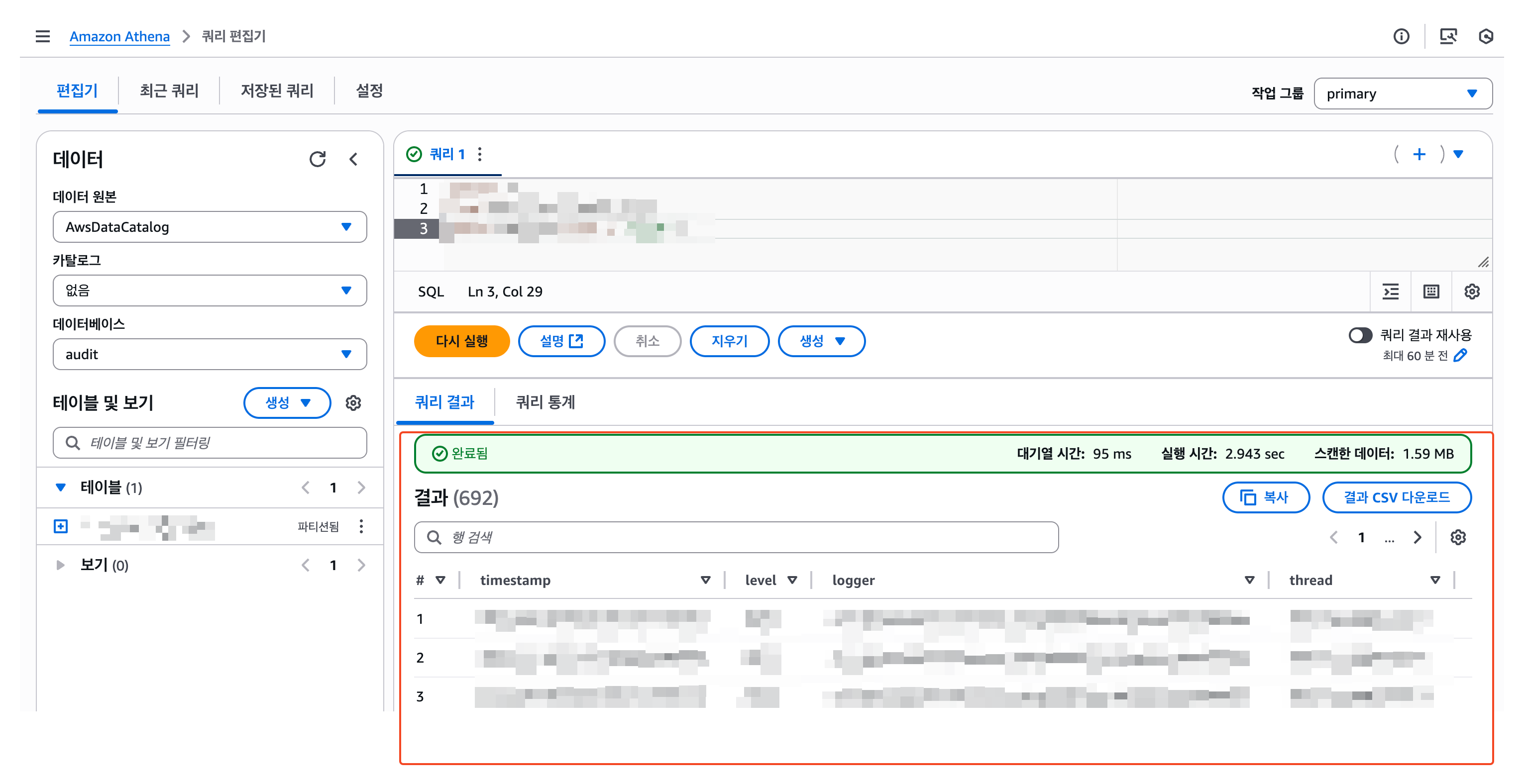
CloudWatch 로그가 Athena로도 조회가 가능한 것을 확인할 수 있다.
☕️ 마무리
이번 글에서는 CloudWatch 로그를 S3에 적재하고, Data catalog 테이블까지 생성해서 Athena에 연동하는 일련의 과정에 대해서 다루어 보았다.
이 파이프라인을 직접 구현한다면 한 세월이 걸릴 작업일텐데, 역시나 AWS는 딸깍으로 손쉽게 CloudWatch 로그 파이프라인을 세팅할 수 있었다. 🙇♂️
기회가 된다면, 이렇게 만든 파이프라인에 좀 더 재미있는 데이터 레이크 서비스(QuickSight, Open Search 등등)를 붙여서 더 유의미한 결과물을 만드는 글 또한 작성해보도록 하겠다.
그럼 이만 🙇♂️
