💡 이 글은 Spring, JPA에 대한 기본적인 지식을 필요로 합니다. 혹시나 잘 모르는 용어가 나온다면, 검색해서 찾아보거나 댓글로 질문 해주시면 감사하겠습니다.
✅ 글에서 작성한 코드들은 여기에서 확인할 수 있습니다.
☕ 시작
어느 정도 규모가 있는 서비스는 읽기용 DB 서버(Read Replica)와 쓰기용 DB서버(Write Replica)를 따로 구성해서, 많은 양의 트래픽을 분산 처리하도록 설정하곤 한다.
이번 글에서는 Spring에서 제공하는 @Transactional 어노테이션을 통해서, 읽기 기능은 Read replica로 쿼리가 실행되고 쓰기 기능은 Write replica로 쿼리가 실행될 수 있도록 설정해보도록 하겠다.
@Transactional ?
@Transactional은 JPA를 최적화해서 사용할 수 있도록 도와주는 어노테이션이다.
보통은 Service 클래스 또는 Service 클래스의 메서드에 붙여서 자주 사용하는데 어떤 특징들이 있는지 알아보자.
1) commit
@Transactional 이 붙은 로직은 그 로직이 종료되는 시점에 수행된 쿼리들을 DB에 commit을 한다.
Commit 자체가 되지 않았기 때문에 로직이 수행되던 중에 에러가 발생해도 내가 직접 롤백을 해줄 필요가 없게 된다.
2) 영속성 유지
JPA에서 데이터를 들고 있는 것을 영속성이라고 하는데, @Transactional이 붙은 로직은 해당 로직이 끝나기 전까지 영속성을 유지하고 있게 된다.
3) Connection
@Transactional이 붙은 로직이 시작되면, DB에 연결되고 로직이 종료되면 연결이 해제된다.
그래서, 너무 긴 시간동안 실행되는 로직 전체에 @Transactional을 붙이면, 커넥션 풀이 모두 소진될 위험이 있으므로 작은 기능 단위로 @Transactional을 붙여줄 필요가 있다.
🔨 DataSource 구성하기
1) application.yml 생성
spring:
datasource:
read:
jdbc-url: jdbc:mysql://localhost:3306/testRead # Read replica의 호스트명
username: {DB Username}
password: {DB Pw}
write:
jdbc-url: jdbc:mysql://localhost:3306/testWrite # Write replica의 호스트명
username: {DB Username}
password: {DB Pw}먼저 이렇게 설정 파일을 생성해주도록 하겠다.
💡 지금은 실습용으로 만든 것이기 때문에 개념적으로 분리된 DB를 사용하지만, 실제로는
jdbc-url에 Read replica의 호스트와 Write replica의 호스트를 적어주면 된다.
2) Router 클래스 만들기
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.transaction.support.TransactionSynchronizationManager;
public class DataSourceRouter extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// @Transactionl(readOnly = true) 이면 True 이다.
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
return readOnly ? "read" : "write";
}
}원하는 위치에 위와 같이 DataSource 라우팅에 필요한 클래스를 만들어주자.
3) DataSource 설정 클래스 만들기
import com.zaxxer.hikari.HikariDataSource;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.DependsOn;
import org.springframework.context.annotation.Primary;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.jdbc.datasource.LazyConnectionDataSourceProxy;
import javax.sql.DataSource;
import java.util.HashMap;
@Configuration
@RequiredArgsConstructor
@EnableJpaRepositories(basePackages = "study.jpaReadWrite.repository")
public class DataSourceConfig {
// Write replica 정보로 만든 DataSource
@Bean
@ConfigurationProperties(prefix = "spring.datasource.write")
public DataSource writeDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
// Read replica 정보로 만든 DataSource
@Bean
@ConfigurationProperties(prefix = "spring.datasource.read")
public DataSource readDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
// 읽기 모드인지 여부로 DataSource를 분기 처리
@Bean
@DependsOn({"writeDataSource", "readDataSource"})
public DataSource routeDataSource() {
DataSourceRouter dataSourceRouter = new DataSourceRouter();
DataSource writeDataSource = writeDataSource();
DataSource readDataSource = readDataSource();
HashMap<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("write", writeDataSource);
dataSourceMap.put("read", readDataSource);
dataSourceRouter.setTargetDataSources(dataSourceMap);
dataSourceRouter.setDefaultTargetDataSource(writeDataSource);
return dataSourceRouter;
}
@Bean
@Primary
@DependsOn({"routeDataSource"})
public DataSource dataSource() {
return new LazyConnectionDataSourceProxy(routeDataSource());
}
}이렇게 DataSource까지 설정까지 마치면, 모든 준비가 끝났다. 😎
테스트 코드를 작성해서 우리가 원하는대로 잘 동작하는지 알아보도로 하자.
📌 부가 설명
-
LazyConnectionDataSourceProxy : 클래스 명에서도 알 수 있겠지만, DataSource를 서버가 실행되는 시점이 아니라 로직이 수행되는 시점에 호출해서 사용하는 기능을 수행하는 클래스이다.
-
@DependsOn : 이 어노테이션 안에 선언된 Bean이 먼저 생성이 된 후에
@DependsOn이 붙은 Bean을 생성하도록 하는 어노테이션이다.
⚡ 동작 확인하기
1) 사전 준비
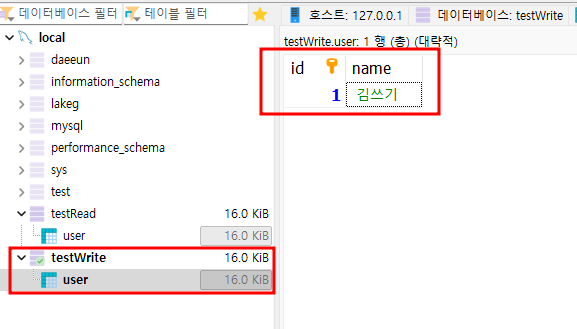
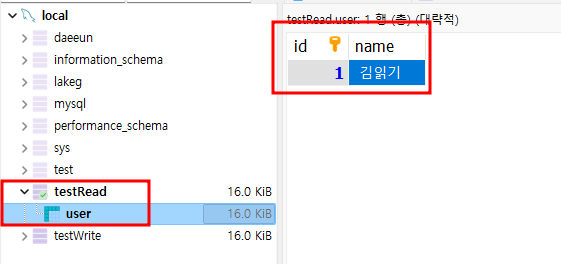
CREATE TABLE `user` (
`id` BIGINT(19) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
PRIMARY KEY (`id`) USING BTREE
)
COLLATE='utf8mb4_general_ci';user라는 이름의 테이블을 testRead DB와 testWrite DB에 만들어주자.
2) 유저 조회 기능 구현
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import study.jpaReadWrite.entity.User;
import study.jpaReadWrite.repository.UserRepository;
import java.util.List;
@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
@Transactional(readOnly = true) // ⭐
public List<User> getListRead() {
return userRepository.findAll();
}
@Transactional // ⭐
public List<User> getListWrite() {
return userRepository.findAll();
}
}
유저 테이블에 있는 모든 유저를 조회하는 동일한 기능이지만, 어노테이션만 달리해서 만들어주었다.
3) 테스트 코드 작성
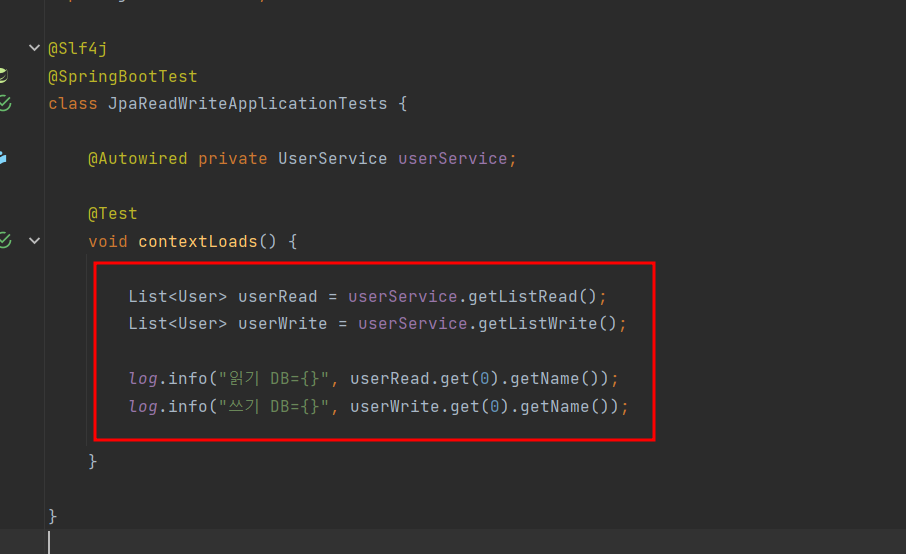
이렇게 테스트 코드를 작성해주고, 실행해보면 서로 다른 결과 값이 출력된다.
이는 DB 커넥션이 각각 다른 곳에 연결됐다는 것을 알 수 있을 것이다.

👍👍👍

좋은 정보 감사합니다