☕ Map
Map은 Key-Value의 쌍들을 저장하는 자료구조이다.
그 중에서 가장 오래 전에 만들어진 Map의 조상님(?)인 HashTable과 그 외에 구현체들을 알아보자.
💡 HashTable
배열과 해시 함수(Hash function)를 사용한 Map의 구현체이다. Map의 구현체 중에서 가장 초기에 만들어진 구현체이고, HashMap과 LinkedHashMap은 HashTable에서 새로운 기능이 추가되거나 개선된 버전이라고 볼 수 있다.
HashTable의 배열
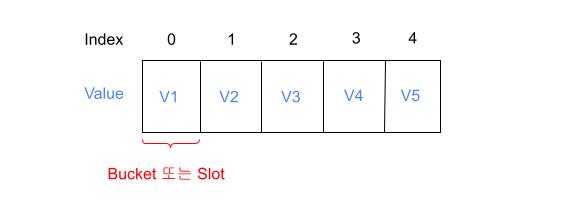
배열이라고 하면, 여러 '칸'으로 구성된 자료구조를 의미한다. 그에 맞게 각 칸의 위치를 뜻하는 Index값이 있을 것이고, 그 안에 담을 '값(Value)' 또한 있을 것이다.
HashTable에서 사용되는 배열은 이 '칸'을 Bucket 또는 Slot이라고 부른다.
Hash function
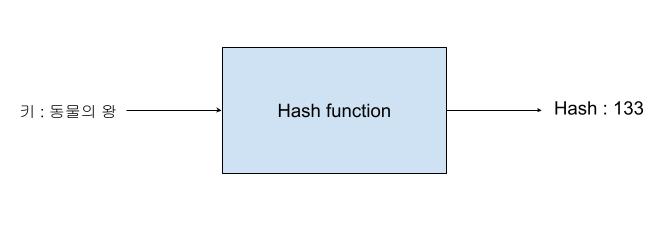
해시 함수는 배열에 저장할 데이터를 임의의 정수로 변환하는 역할을 한다.
이렇게 변환된 값을 Hashing된 값 또는 Hash라고 부른다.
이 Hash를 배열의 크기로 모듈러 연산(%, 나머지 연산)한 값이 바로 배열의 Index 값에 해당한다.
Hash Table의 동작 : PUT
@Test
public void hashTableTest() {
Hashtable<String, String> animals = new Hashtable<>();
animals.put("동물의 왕", "사자");
}이렇게 HashTable에 데이터를 추가하는 코드는 어떻게 동작하게 될까?
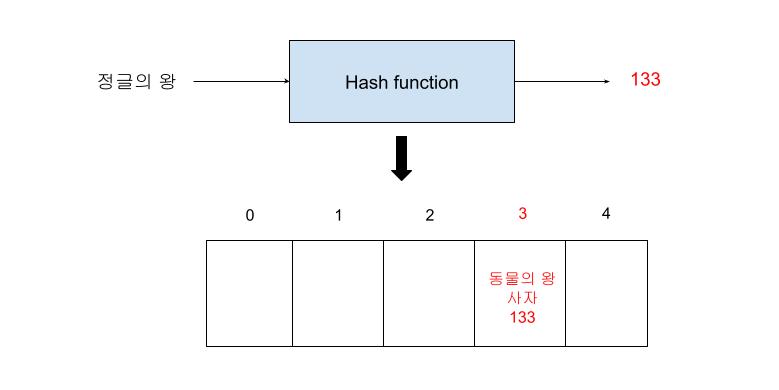
먼저 동물의 왕이라는 Key값을 Hash function이 받아서, 배열의 크기를 기준으로 어디에 위치시킬지를 Hashing알고리즘을 통해서 계산한다. 그 결과가 133이라면, 동물의 왕, 사자,133(키, 값, 해시)이 배열의 133 % 5에 해당하는 Index에 위치하게 되는 것이다. 즉, Index가 3인 4번째 Slot에 위치하게 된다는 의미이다.
Hash Table의 동작 : GET
@Test
public void hashTableGet() {
Hashtable<String, String> animals = new Hashtable<>();
String 사자일까 = animals.get("동물의 왕");
}그렇다면, HashTable.get()은 어떻게 동작할까?
PUT과 동일한 절차를 밟는다. 우선 동물의 왕이라는 Key를 갖고 있는 값을 찾고 있으니 동물의 왕을 Hash function이 받아서 Hash값을 만든다. 당연히도 동일한 Hash알고리즘을 사용했을 테니 133이라는 값이 나올 것이다.
그리고는 바로 모듈러 연산(나머지 연산)을 통해서 Index가 3이라는 것을 알 수 있을 것이고, 해당 위치에 존재하는 Key와 Value를 찾아서 Key값이 동물의 왕이 맞는지 체크하고, 값을 반환하게 된다.
HashTable을 사용하는 이유
HashTable을 사용하는 이유는 특정 Key에 대한 값을 찾는 속도가 보통의 Array나 List같은 형태의 자료구조보다 빠르기 때문이다.
특정 데이터를 찾는다고 했을 때, Array계열의 자료구조는 처음부터 한 칸, 한 칸을 확인해야한다. 물론 초반에 있는 데이터는 금방 찾을 수 있겠지만 후반부에 위치한 데이터는 찾는데 오래걸리게 될 것이다.
반면에, HashTable이 데이터를 찾는 속도는 데이터의 크기에 무관하게 거의 일정하다.
키 값을 해시 함수가 해싱하고, Hash를 모듈러 연산하고 배열에서 해당 Index로 찾아들어가는 시간만 존재하기 때문에, 데이터가 배열의 초반부에 있든 후반부에 있든 상관 없이 거의 동일하고, 빠른 속도의 검색 속도를 보장하게 되는 것이다.
⚡ Hash collision
서로 다른 값을 갖고 해싱했는데 동일한 해시 값이 나오 거나 해시 값을 모듈러 연산을 했을 때, 동일한 값이 나오는 것을 해시 충돌(Hash collision)이라고 부르는데, HashTable에서 해시 충돌은 피할 수 없다.
(작은 확률이겠지만) Hashing 알고리즘을 돌려도 당연히 중복된 값이 생길 수 있기도 하고, Hashing 알고리즘에서 무조건 서로 다른 값을 반환하는 것을 보장한다고 해도 모듈러 연산을 해야하기 때문에 최종적으로 산출될 수 있는 Index값은 배열의 크기만큼 밖에 되지 않기 때문에 해시 충돌은 피할 수 없다.
그렇다면, 위에서 이야기한 동작 방식이라면 문제가 있어보이는데 어떻게 이러한 충돌을 해결할 수 있을까?
해결 방법 (Java등등) : Separate chaining
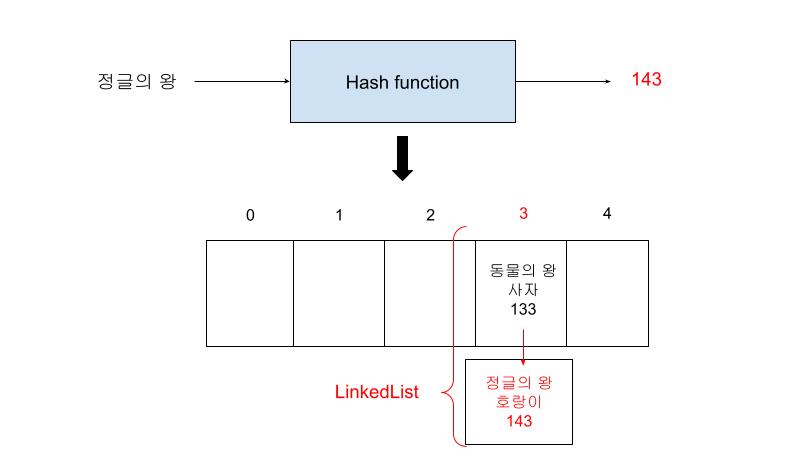
Separate chaining 방식은 슬롯 하나 하나를 LinkedList로 관리를 하는 방법이다. 그래서 해시 충돌이 일어나게 되면, 나중에 기존에 있었던 값은 다음 노드를 가리키는 주소값을 들고 있게 된다.
즉, 동물의 왕,사자,133이 정글의 왕,호랑이,143과 하나의 LinkedList에 담겨 있고 동물의 왕,사자,133이 정글의 왕,호랑이,143의 주소값을 알고 있는 상태인 것이다.
해결 방법 (Python등등) : Open addressing
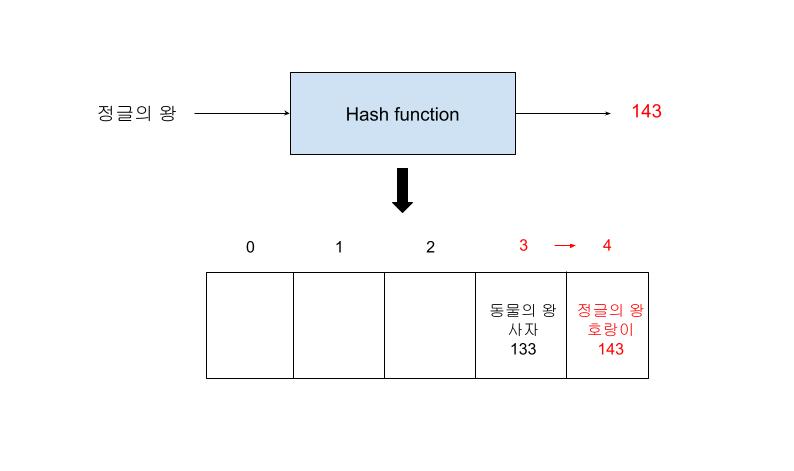
해싱 및 모듈러 연산을 통해서 이미 다른 값이 존재하고 있는 Index가 반환된 경우, 그 다음 빈칸을 찾아서 값을 저장하는 방식이 Open addressing방식이다.
즉, 정글의 왕이라는 값을 해싱했더니 143이라는 값이 나왔다면, 정글의 왕,호랑이,143은 Index가 3인 슬롯에 위치해야한다. 하지만, 이미 동물의 왕,사자,133이 있기 때문에 그 다음 슬롯이 5번째 슬롯에 위치하게 되는 것이다.
이러한 이유로 .get()을 통해서 값을 찾으려고 할 때에도 해당한는 Index에 위치한 슬롯뿐만아니라 그 다음 슬롯까지도 검색을 하게 된다.
다음 슬롯을 탐색하는 방식은 선형 탐색(Linear probing)과 이차 탐색(Quadratic probing)방식이 있다.
그렇다면, 이미 모든 슬롯이 가득 차 있어서 비어있는 슬롯이 없는 경우엔 어떻게 해야할까?
Java의 경우 HashTable이 75%이상 차면 그 2배로 크기를 자동적으로 늘려주게 된다. 늘리는 과정에서 기존의 값들은 각각의 Hash값을 2배 늘어난 배열의 크기로 새롭게 모듈러 연산을 해서 새로운 위치를 선정하게 된다.
🤔 또 다른 Map의 구현체들
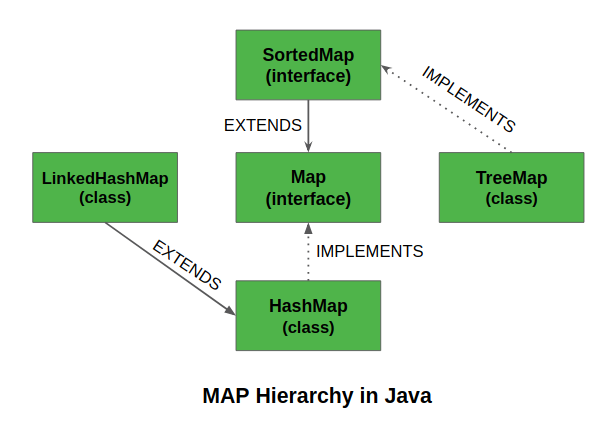
HashMap
'HashTable 버전2'라고 할 수 있을 만큰 HashTable과 거의 유사한 자료구조이다. 둘의 차이점은 아래와 같다.
- Thread-safe :
HashTable은 쓰레드 간의 동기화를 지원하고, HashMap은 쓰레드 간의 동기화를 지원하지 않는다.HashTable은 동기화 기능이 추가되어 있어서, HashMap 보다 성능이 좋지 않다. - Null :
HashMap은 Key가 Null인 값도 허용한다. - 보조 해시 :
HashMap은 보조 해시를 제공해서 비교적 해시 충돌이 일어나는 경우가 적다. 이런 특징으로HashMap이 성능적인 이점을 갖는다.
ConcurrentHashMap
이름에서도 알 수 있듯이 '동시성'을 보장하는 HashMap이다. 즉, Tread-safe하지 않았던 HashMap을 Tread-safe하도록 한 것이다.
HashTable은 쓰레드 간 동기화를 진행할 때, 데이터 전체에 Lock을 걸도록 설계되어 있는 것에 비해서 ConcurrentHashMap은 데이터의 일부만 Lock이 걸리도록 설계되어 있다. 즉, HashMap의 성능과 HashTable의 Tread-safe하다는 장점들을 합친 클래스라고 할 수 있다.
ConcurrentHashMap은 내부적으로 여러 개의 세그먼트(Segment)로 구성되어 있다. 각각의 세그먼트는 HashTable처럼 동작을 하는데, 이러한 이유로 세그먼트의 갯수만큼 병렬처리가 가능한 것이고, 하나의 세그먼트가 하나의 쓰레드를 담당(?)하기 때문에 데이터 전체에 Lock을 걸지 않아도 되는 것이다.
LinkedHashMap
HashMap에서는 하나의 슬롯이 Key, Value, Hash로 구성되는데, LinkedHashMap에서는 Key, Value, Hash, Next, Previous 로 구성이 된다.
Next는 다음 노드의 주소값을 의미하고, Previous는 이전 노드의 주소값을 의미한다.
이러한 이유로 LinkedHashMap은 HashMap과 달리 순서를 보장할 수 있게 된다. 또, 추가적인 정보들을 저장해야하므로, 좀 더 많은 양의 메모리가 사용된다.
TreeMap
이진 탐색 트리(Binary Search Tree) 자료구조를 갖고 있는 Map이다. BST 자료구조를 갖고 있다보니, Key값을 기준으로 오름차순으로 데이터들이 정렬되게 된다.
이러한 이유로 HashMap보다는 전반적인 성능이 떨어지지만, Key값들이 오름차순으로 정렬되어 있다보니 범위 검색이나 반복문에서는 더 나은 성능을 보여준다.
