✍️ 이 글에서 사용한 코드: 깃헙
☕ 개요
지난 글에서는 Kafka 프로듀서에 대해서 알아보고 간단한 애플리케이션을 만들어봤다면, 이번 글에서는 Kafka 컨슈머에 대해서 알아보고, Java와 Spring으로 Kafka 컨슈머 애플리케이션을 만들어보도록 하겠다.
이 글은 Dev원영님의 강의를 듣고 정리한 내용이다. 🙏
🧐 컨슈머 애플리케이션의 구조
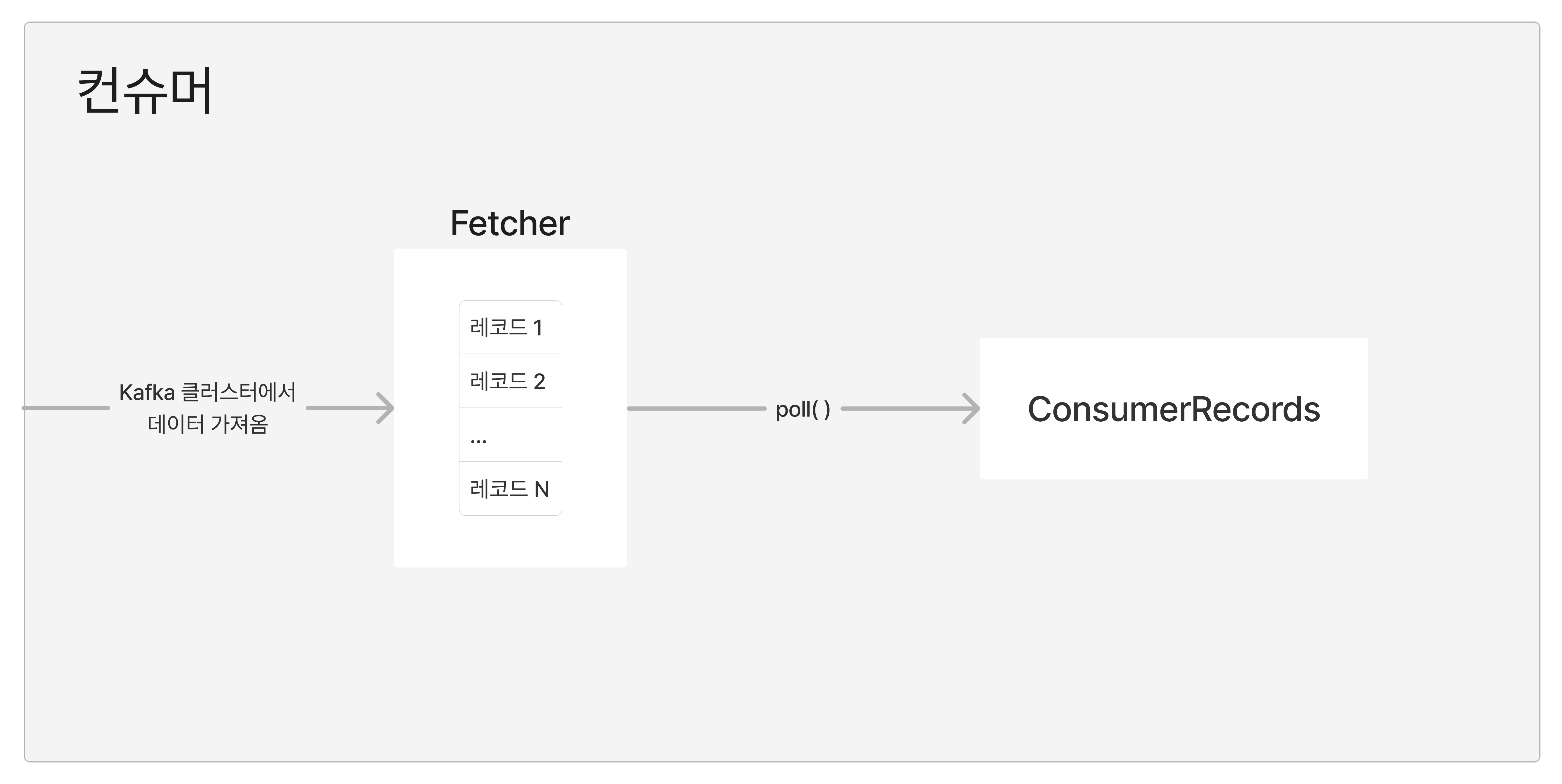
컨슈머는 대략 이러한 형태의 구조를 갖고 있다. 하나 하나 어떤 역할을 하는지 자세히 알아보자.
1) Fetcher
Kafka 클러스터의 리더 파티션으로부터 레코드를 가져오는 역할을 한다.
가져온 레코드를 쌓아두고 애플리케이션 중 어딘가에서 호출될 때까지 기다린다.
Fetcher의 poll() 메서드를 통해서 쌓여져있는 레코드들을 호출할 수 있다.
2) ConsumerRecords
poll()를 호출하면, ConsumerRecords라는 클래스로 쌓여져있던 레코드들이 Return된다. 여기에는 어디까지 처리가 완료됐는지를 표기하는 Offset 값도 포함되어 있다.
🤓 컨슈머 주요 개념
1) 컨슈머 그룹
N개의 컨슈머 애플리케이션으로 구성된 그룹을 "컨슈머 그룹"이라고 한다.
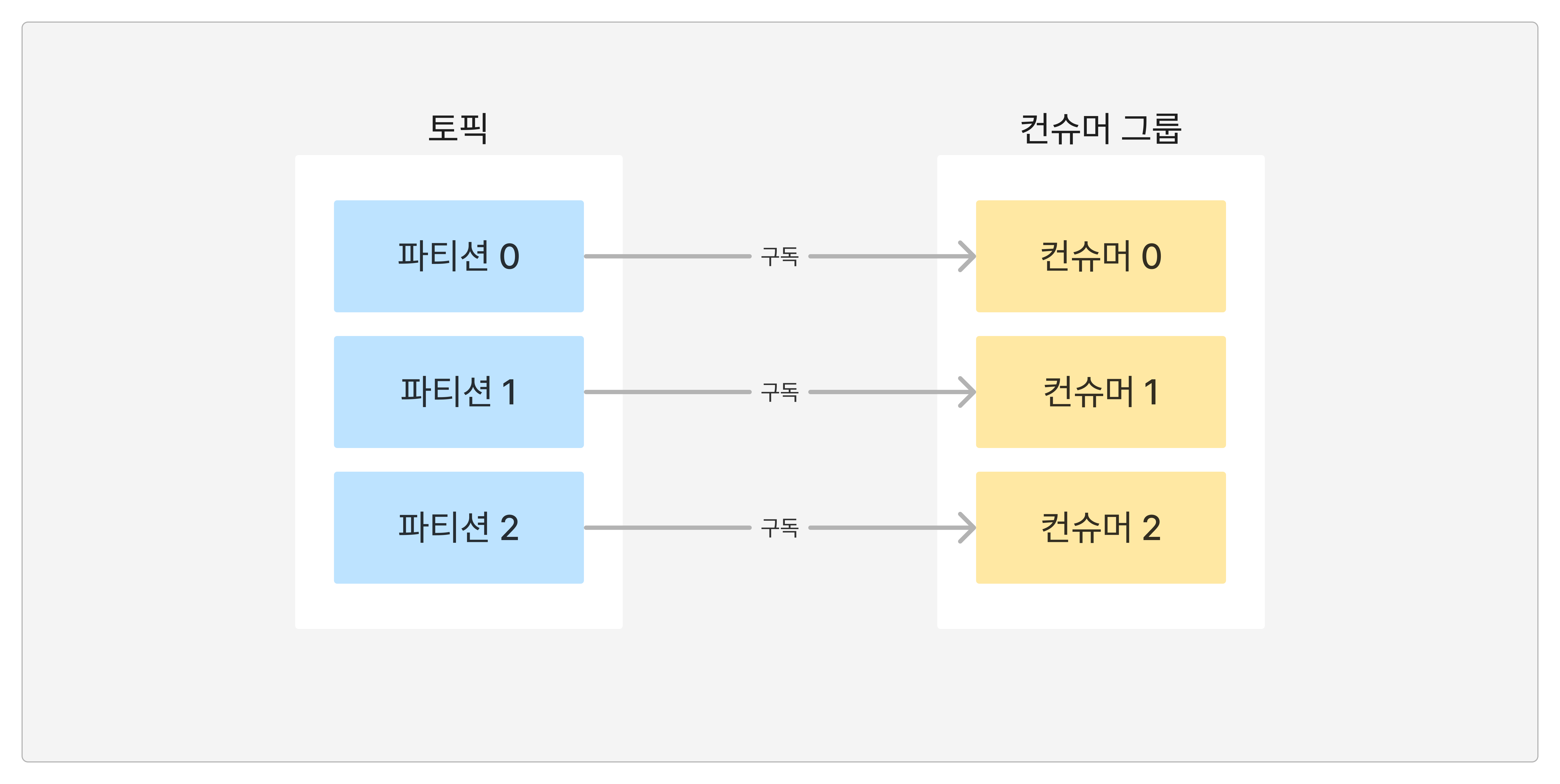
하나의 컨슈머 그룹에 N개의 컨슈머 애플리케이션이 속해 있다면, 각 컨슈머 애플리케이션은 구독중인 토픽의 파티션을 하나씩 바라보고 레코드를 컨슈밍한다.
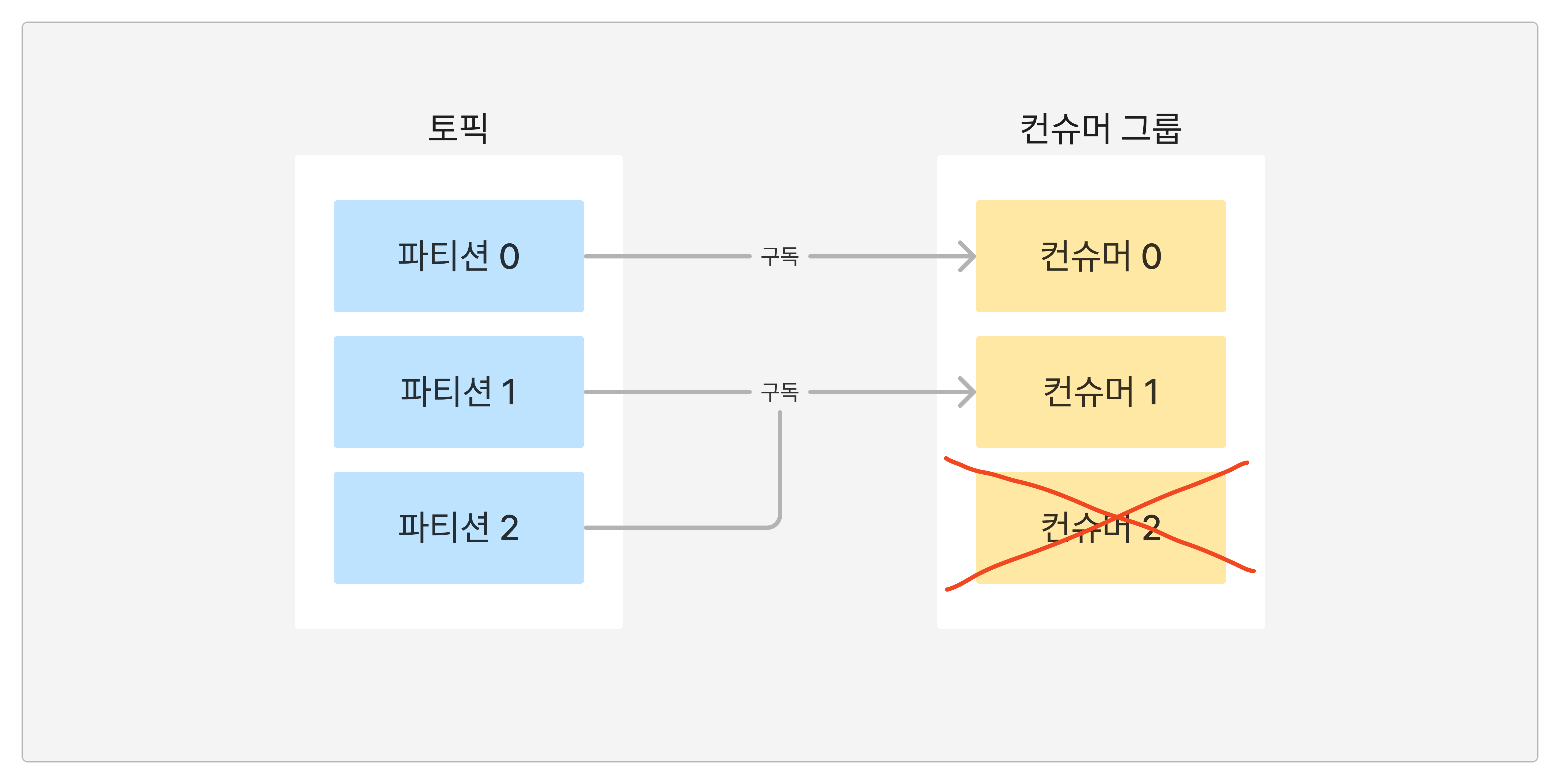
혹시나 컨슈머 애플리케이션 하나가 장애가 발생한다면, 그 컨슈머에 붙어있던 파티션은 남아 있는 파티션 중 하나가 구독해서 처리한다. 그리고, 새로운 컨슈머 애플리케이션이 뜨게 되고, 파티션과 컨슈머의 개수가 동일한 기존의 상태로 만들어진다.
이렇게 컨슈머에 장애가 발생해서 컨슈머가 제외되거나 추가되는 프로세스를 "리밸런싱"이라고 부른다.
✍️ 높은 처리량을 확보하기 위해서는 파티션의 개수와 컨슈머 애플리케이션의 개수를 동일하게 맞춰주면 된다.
2) Commit
"특정 토픽의 파티션을 특정 컨슈머 그룹이 몇번째까지 가져갔는가?"를 기록하는 값이 Offset이고, __consumer_offsets 토픽에 기록된다.
이렇게 Offset을 기록하기 위해서는 각 컨슈머 애플리케이션에서 레코드에 대한 처리를 완료한 후, Commit을 해주어야한다.
3) Assignor
컨슈머와 파티션 할당 정책을 Assignor라고 부른다. 기본적으로 제공되는 Assignor 클래스는 아래와 같다.
RangeAssignor(Default): 각 토픽에서 파티션을 숫자로 정렬하고 컨슈머를 사전(Dictionary) 순서로 정렬하고 할당한다.RoundRobinAssignor: 모든 파티션을 컨슈머에서 번갈아가면서 할당.StickyAssignor: 최대한 균등하게 파티션을 할당.
📒 컨슈머 주요 옵션
1) 필수 옵션
bootstrap.servers: Kafka 브로커 정보를 입력한다. (호스트 이름:포트)key.deserializer: 레코드의 키 값을 역직렬화하는 클래스를 지정한다.value.deserializer: 레코드의 메세지 값을 역직렬화하는 클래스를 지정한다.
2) 선택 옵션
group.id: 컨슈머 그룹 ID를 지정한다.subscribe()로 토픽을 구독할 경우엔 필수로 이 값을 입력해줘야한다. (Default:null)auto.offset.reset: 컨슈머 그룹이 특정 파티션을 읽을 때, 저장되어 있던 Offset 값이 없는 경우 어떤 레코드부터 컨슈밍할지 선택하는 옵션이다. (Default: latest)enable.auto.commit: 자동 커밋 여부. (Default:true)auto.commit.interval.ms: 자동 커밋일 경우, 자동 커밋을 실행할 주기를 지정한다. (Default:5000ms)max.poll.records:poll()을 통해서 반환되는 레코드의 최대 개수를 지정한다. (Default:500)session.timeout.ms: 컨슈머와 브로커의 연결이 끊기는 최대 시간. 리밸런싱의 기준 중, 하나이다. (Default:10000ms)hearbeat.interval.ms: 브로커가 살아있는지 컨슈머가 주기적으로 보낼 신호의 주기를 설정한다. 리밸런싱의 기준 중, 하나이다. (Default:3000ms)max.poll.interval.ms:poll()메서드를 호출하는 간격의 최대 시간이다. 이 시간안데poll()이 재호출되지 않으면, 리밸런싱이 이루어지게 된다. (Default:300000ms)isolation.level: 트랜잭션 프로듀서가 레코드를 트랜잭션 단위로 보낼 경우 사용하는 옵션이다.
3) auto.offset.reset
아래 3개 값 중에 하나로 설정할 수 있다.
latest: 가장 큰 Offset(가장 최근의 레코드)부터 읽는다.earliest: 가장 작은 Offset(가장 오래된 레코드)부터 읽는다.none: 커밋한 기록이 없으면, 즉 Offset이 이미 존재하지 않으면 에러를 뱉는 옵션이다.
💻 컨슈머 만들기
1) build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.kafka:spring-kafka'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.kafka:spring-kafka-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
}나는 이렇게 라이브러리들을 설치해주었다.
컨슈머를 만들기 위해서 필수적으로 필요한 라이브러리는 spring-kafka 또는 kafka-clients인데, 나는 spring-kafka를 사용하도록 하겠다.
2) KafkaConsumerConfig
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9094");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "hello-world-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}위와 같이 설정 클래스를 하나 만들어준다.
3) KafkaConsumer
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = "test")
public void receive(ConsumerRecord<String, String> consumerRecord) {
log.info("수신한 키: {}", consumerRecord.key());
log.info("수신한 메세지: {}", consumerRecord.value());
}
}test라는 토픽을 구독하고, 처리할 메서드와 그 메서드를 갖고 있는 컴포넌트 클래스를 하나 만들어준다.
4) 동작 확인
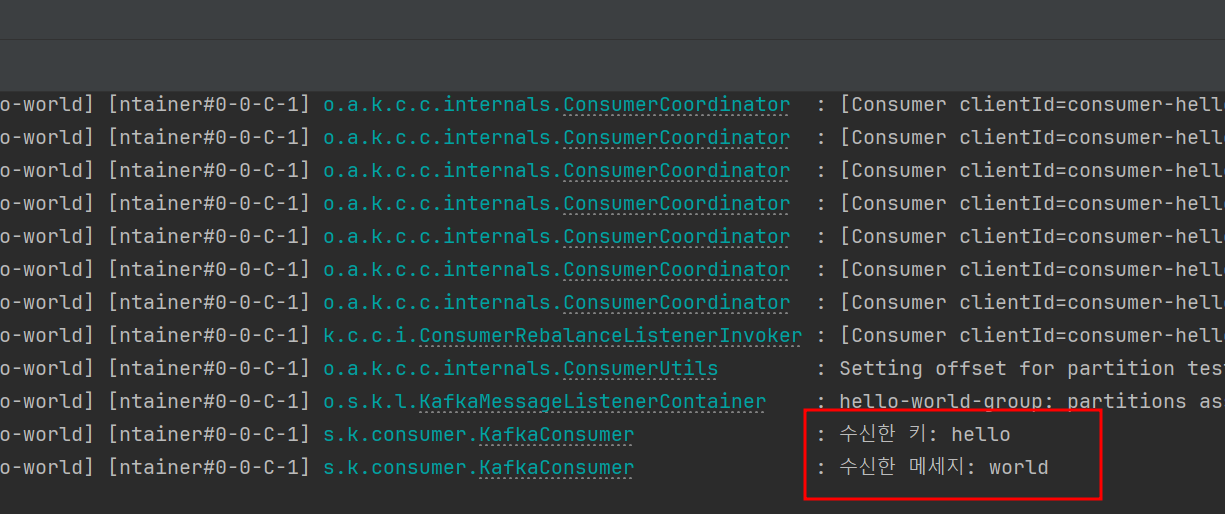
아무 메세지나 프로듀싱해보면, 위와 같이 정상적으로 로직이 수행되는 것을 확인할 수 있다.
