OCR
삼성SDS
노이즈가 많은 실제 문서 이미지 OCR 모델 개선
https://youtu.be/pECt2rXbpTk
Text Detection의 어려운 점
- 문자 위 서명
- 워터마크
- 저해상도
- 반전(배경과 글자 색), 펀치홀
- 복사방지 패턴
학습 데이터 확보
노이즈에 강한 모델을 만들기 위해서 많은 양의 데이터 확보가 필수
진짜같은 데이터 만들기
Data Generation
모델 학습에서 필요한 Label까지 데이터 생성과정에서 해결할 수 있다.
--> Fully Supervised Learning
Real 데이터를 다양하게 변형
Data Augmentation
Label은 그대로 사용할 수 있도록
- 부분 반전
- QR코드 삽입 etc.
모델 학습에서 필요한 Label 중에 De-noising Label이 존재하지 않는다. 따라서 Detection Label을 통해 Weakly Supervised Learning
모델 학습
Multi Task Learning
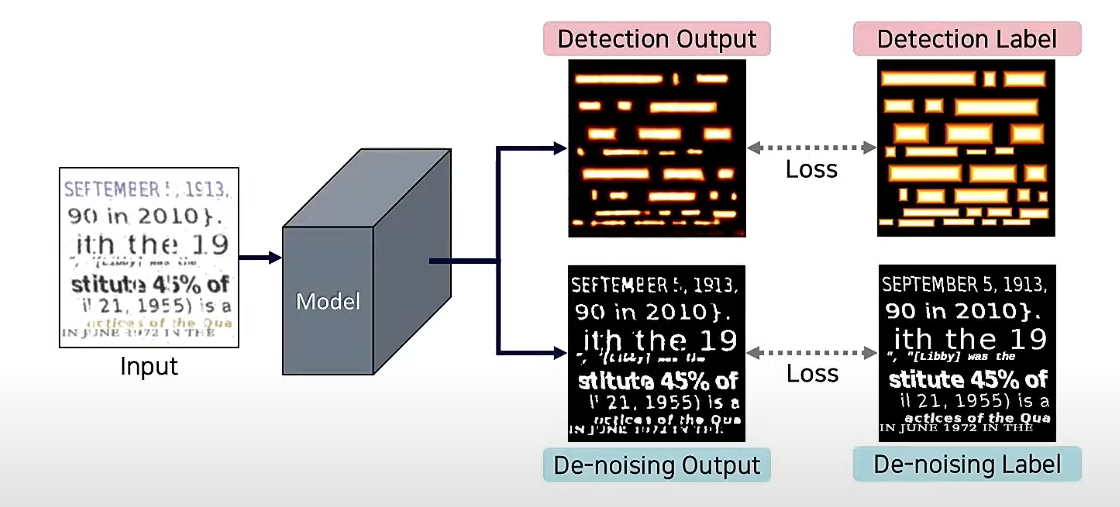
기존의 detection output 외에, De-noising Output을 추가한다.
De-noising Output
Segmentation을 통해 글자, 단어와 배경을 binary하게 구분한 것
모델 학습은 자세히 이해가 가지 않는다.
모델 구조를 확인할 필요가 있을 것 같다.
현재 이해가 가지 않는 것은
multi task, 즉 원래의 detection output과
de-noising output을 출력하는 모델이 학습을
각각 output에 대해서 진행한다면 가중치 학습이 어떻게 진행되는 건지,
Real Data를 이용한 모델 학습에서 2단계 학습 중인 모델 이용 과정도 모르겠다.
OCR 평가
- Precision : 인식한 글자, 단어가 올바른 객체인 비율(높을수록 놓친 글자가 적다)
- Recall : 감지할 글자, 단어 대비 실제 감지한 글자, 단어의 비율(높을수록 문자로 인식한 노이즈가 적다)
- F1 Score : Precision과 Recall의 조화 평균
