텍스트 요약기
요약 방식
Extractive summarization; 추출적 요약
원문의 문장을 그대로 추출하는 것으로 요약하는 방식.
핵심 문장임을 Binary Classification; 분류 라고 볼 수 있다.
텍스트 랭크; textrank와 같은 알고리즘을 사용하며 포털 사이트 네이버 기사에서 요약봇을 통해 확인할 수 있다.
단점 : 문단의 문장을 그대로 추출하기 때문에 문장 간 상호연결이 어색하다.
from summa.summarizer import summarize
summarize(text, word=, ratio=, split=)Abstractive summarization; 추상적 요약
원문의 내용을 토대로 '새로운 내용을 생성'함으로 요약
RNN을 이용하여 구현한다.
Long term dependency; 장기 의존성 을 해결하기 위해서 LSTM을 사용할 것이며
아키텍쳐는 sequence to sequence, 추가로 attention
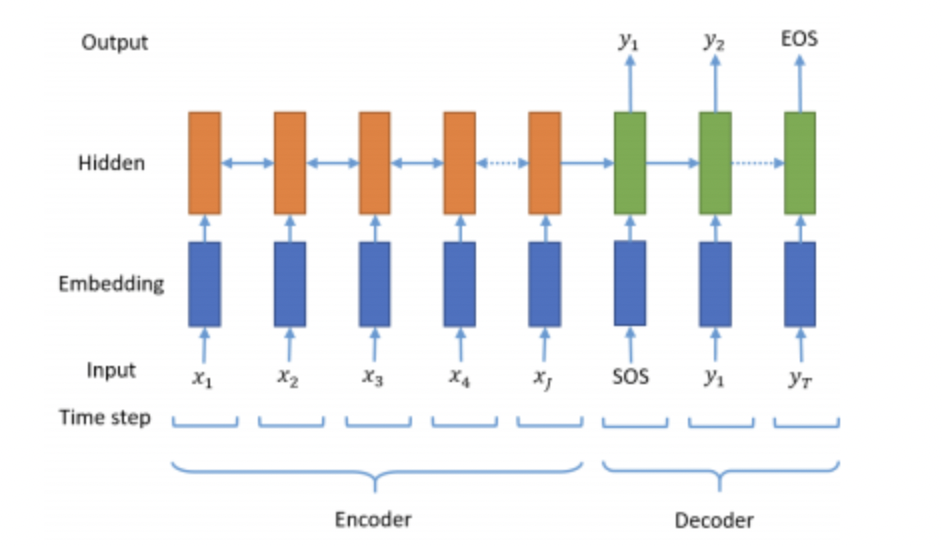
seq2seq
sequence to sequence
출처 : https://arxiv.org/pdf/1812.02303.pdf
encoder -> context vector -> decoder -> 요약 생성
encoder의 마지막 time step의 hidden state -> context vector
이 때, context vector는 고정
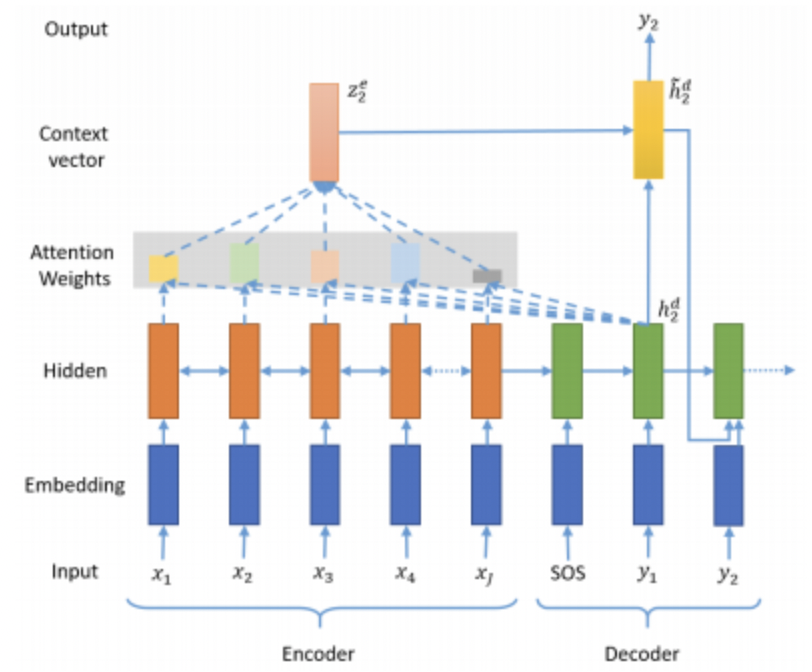
하지만 attention mechanism을 곁들이면
출처 : https://arxiv.org/pdf/1812.02303.pdf
encoder의 모든 hidden state가 context vector에 가중곱으로 포함
decoder의 각 예측 마다 가중곱을 달리함
don' forget train_dataset into decoder must include token of start and end
훈련 시에 decoder input data를 넣어줌으로 attention 가중곱을 time step을 학습 시킨다. context vector에 따른 출력이 input과 비교함으로 loss 계산을 한다.
things confused
seq2seq는 모델인가? 아키텍쳐인가? cell로 쓰이는 LSTM은 모델인가?
stopwords in NLTK
natural language toolkit
자주 등장하지만 유의미한 토큰을 만드는 것에 기여하지 못하는 단어들
Ex> i me my mine, 조사, 접미사 등
text data preprocessing
- text.lower(); 소문자화
- BeautifulSoup(sentence, "lxml").text; html 문구 제거
- special character process; by regular expression
- removing from possesive case
- after preprocessing, we need to check NaN
text normalization
같은 의미이지만 표기법이 다른 것들을 표기를 통일시키는 것
Ex> I'm -> i am
Additional
fix random seed
tf.random.set_seed(42)
np.random.seed(42)
