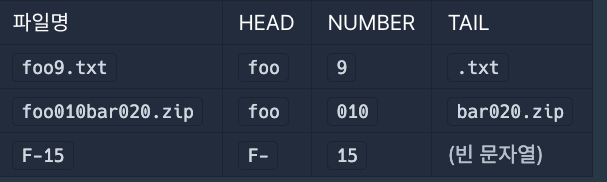
파일명을 HEAD 알파벳 순(대문자, 소문자 구분 없이), number 숫자 순으로 정렬하는 것.
def solution(files):
def parse(file):
i = 0
while i < len(file) and file[i] not in '0123456789':
i+=1
head = file[:i]
j = i
while i < len(file) and file[i] in '0123456789':
i+=1
num = file[j:i]
tail = file.split('.')[1] if len(file.split('.')) > 1 else ''
return (head.lower(), int(num), tail)
datas = {file: parse(file) for file in files}
files.sort(key = lambda x: (datas[x][0], datas[x][1]))
return files열심히 head, num, tail 을 분리하는 parse 함수를 짰다.
import re
def solution(files):
a = sorted(files, key=lambda file : int(re.findall('\d+', file)[0]))
b = sorted(a, key=lambda file : re.split('\d+', file.lower())[0])
return b아 re 모듈을 좀 더 공부해야겠다...
여기에서 \d+ 는 숫자가 하나 이상...

개발블로그