데이터베이스?
특정 조직의 여러 사용자가 공유하여 사용할 수 있도록 통합해서 저장한 운영데이터의 집합
- 데이터베이스의 특징
사용자의 데이터 요구에 실시간으로 응답할 수 있어야 하며, → 실시간 접근성
동적인 특징이 있어 계속해서 변화하며 현재의 변화와 동기화 → 계속 변화
여러 사용자가 동시에 이용 가능한 동시 공유의 특징을 제공해야 하고, → 동시 공유
저장된 주소나 위치가 아닌, 데이터의 내용(값)으로 참조. → 내용으로 참조
데이터베이스 관리 시스템(DBMS)
과거에는 데이터를 관리하기 위해 파일 시스템을 이용했다. 각각의 서비스마다 파일을 따로 유지하고, 파일의 논리적인 구조뿐 아니라 물리적인 구조까지 정확히 파악해야한다. 그래서 다음과 같은 문제점들이 발생했다.
- 데이터 중복성
- 응용프로그램이 파일에 종속적 (파일의 구조가 바뀌면 응용 프로그램이 접근하는 방식도 모두 변경해야함)
- 동시 공유 기능을 제공하지 않는다
-
데이터베이스 관리 시스템
이러한 파일 시스템의 데이터 중복과 데이터 종속문제를 헤결하기 위해 제시된 소프트웨어. 데이터를 db에 통합하여 저장하고, 이에 대한 관리를 집중적으로 담당한다.
db생성과 접근, 관리를 모두 담당하고 손쉬운 인터페이스를 제공한다. -
주요 기능
- 정의 기능: db의 구조를 정의하고 수정
- 조작 기능: 데이터를 삽입,수정, 검색
- 제어 기능: 데이터를 항상 정확하고 안전하게 유지(특히 여러 사용자의 공유에서)
-
대신 단점으로는 높은 비용과, 백업과 회복 방법이 복잡함(장애 원인 판단이 어려움)을 들 수 있다.
데이터베이스 시스템
db에 데이터를 저장하고, 저장된 데이터를 관리하여 조직에 필요한 정보를 생성해주는 시스템
데이터베이스 → 저장된 데이터의 집합
DBMS → db에 저장된 데이터가 일관되고 무결한 상태로 유지되도록 관리하는 역할
데이터베이스 시스템 → db와 DBMS를 이용하여 조직에 필요한 정보를 제공해주는 전체 시스템
데이터베이스의 구조
-
스키마
db에 저장되는 데이터 구조와 제약조건
정의된 스키마에 따라 실제 db에 저장된 값 → 인스턴스
사용자의 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마로 구분한다.
각 단계에서 추상 -
3단계 데이터베이스 구조
- 외부 스키마: 개별 사용자에게 필요한 데이터베이스를 정의한 것
- 개념 스키마: 데이터베이스를 이용하는 사용자들의 관점을 통합하여, 조직 전체의 관점에서 이해. + 전체 db에 어떤 데이터가 저장되는지, 어떤 관계가 존재하는지, 보안정책이나 접근 권한에 대한 정의도 포함. 일반적으로 스키마 == 개념 스키마
- 내부 스키마: 데이터베이스를 디스크나 테이프같은 저장 장치의 관점에서 이해하고 표현. 전체 db가 실제로 저장되는 방법을 정의하게 된다. ex 접근 경로, 필드 크기
데이터 독립성
결국에는 위의 서로 다른 스키마들은 유기적으로 연결되어있어야 한다.
이렇게 데이터베이스를 3단계 구조로 나누고, 단계별로 스키마를 유지하며 스키마 사이의 대응 관계를 정의하는 궁극적인 목적은 데이터 독립성을 실현하기 위함이다.
- 데이터 독립성: 하위 스키마를 변경하더라도 상위 스키마가 영향을 받지 않는 특성
- 논리적 데이터 독립성: 개념 스키마가 변하더라도 외부 스키마가 영향을 받지 않는 것
- 물리적 데이터 독립성 : 내부 스키마가 변경되더라도 개념 스키마는 영향을 받지 않는 것
데이터 언어
- 데이터 정의어(DDL, Data Definition Language). 새로운 db를 구축하기 위해 스키마를 정의하거나 기존 스키마의 정의를 삭제 또는 수정하기 위해 사용하는 데이터 언어
- 데이터 조작어(DML, Data Manipulation Language). 사용자가 데이터의 삽입, 삭제, 수정, 검색 등의 처리를 DBMS에 요구하기 위해 사용하는 데이터 언어
- 데이터 제어어(DCL, Data Control Language), db를 올바르게 관리하기 위해 필요한 규칙과 기법을 DBMS에 설명하는 언어
관계 데이터 모델
- 릴레이션 : 하나의 개체에 관한 데이터가 하나의 릴레이션이 된다.
- 속성 : 열
- tuple : 행
- domain : 속성 하나가 가질 수 있는 모든 값의 집합, 일반적으로 데이터 타입
- 차수 : 속성의 전체 개수
- cardinality : 튜플의 전체 개수
- 릴레이션의 특성
- 튜플의 유일성
- 튜플의 무순서
- 속성의 무순서
- 속성의 원자성(값 하나만)
키의 종류
키? 검색이나 정렬 시 tuple을 구분할 수 있는 기준이 되는 attribute
1. 슈퍼키
유일성(key로 하나의 tuple을 유일하게 식별)만 만족
2. 후보키
유일성과 최소성(꼭 필요한 속성으로만 구성)을 만족하는 속성 또는 그 집합.
3. 기본키
후보 키 중 선택된 Main 키
아래 조건을 만족해야한다.
유일성최소성개체 무결성: Entity integrity is an integrity rule which states that every table must have a primary key and that the column or columns chosen to be the primary key should be unique and not null.(위키피디아(Data Integrity)
4. 외래키
서로 다른 table을 연결하기 위해 이용된 키
보통 다른 테이블의 primary key를 참조하게 된다.
외래키가 null일 수 있다. (관계가 없거나, 관계가 unknown임을 의미한다)
The referential integrity rule states that any foreign-key value can only be in one of two states. The usual state of affairs is that the _foreign-key value refers to a primary key value of some table in the database. Occasionally, and this will depend on the rules of the data owner, a foreign-key value can be null. In this case, we are explicitly saying that either there is no relationship between the objects represented in the database or that this relationship is unknown.(위키피디아(Data Integrity))_
SQL Injection
해커에 의해 조작된 쿼리문이 데이터베이스에 그대로 전달되어 비정상적인 명령을 실행시키는 공력 기법
공격 방법
1) Incorrectly constructed SQL statements
SQL 문은 보통 data와 명령어로 구성되게 된다. 이 때 data를 user input으로 받는 경우가 생기는데 이 때 중간에 attacker가 data를 넣는 대신 명령어를 삽입하므로써 쿼리를 변화시키거나, 새로운 쿼리를 추가할 수 있다.
→ 한 번에 하나의 statement만 실행시킴으로써 새로운 쿼리를 추가하는 것을 막을 수 있다. but 이 방법으로는 쿼리 수정은 못막음
2) Blind SQL Injection
에러 메시지를 이용하여 공격하는 방법이다.
인위적으로 에러를 발생시키고, 오류 메시지를 통해 db 구조를 유추하여 해킹에 활용한다.
방어방법
1) input 값을 받을 때 특수 문자 여부 검사하기
2) SQL 서버 오류 발생시 에러 메시지에 유저가 접근할 수 없도록
3) prepare statement 사용하기
4) ORM 을 이용하기
5) Parameterized statements(prepared statement): placeholder를 이용 → placeholder에는 SQL 문 못들어가고 정해진 타입의 값만 들어갈 수 있도록
SQL JOIN
조인
- 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
- 적어도 하나의 column을 서로 공유하고 있어야 한다.
1) INNER JOIN
- 교집합
- 두 개 테이블이 모두 가지고 있는 데이터만 검색
2) LEFT OUTER JOIN
- 왼쪽 테이블을 기준으로 join하는 것
- 왼쪽 테이블이 가진 모든 값들에 오른쪽 테이블이 연결되어 나타난다.
- 오른쪽 테이블만 가지고 있는 row는 나오지 않는다.
3) RIGHT OUTER JOIN
4) FULL OUTER JOIN
- 합집합
- 데이터가 모두 검색된다
5) SELF JOIN
- 자기자신을 JOIN
6) CROSS JOIN
- 두개의 테이블의 row들의 모든 조합을 보고 싶을 때 이용한다.
SQL과 NoSQL
SQL
- Structured Query Language
- 관계형 데이터베이스(RDBMS)
- key-value의 관계를 테이블화 시킨 것
- 정해진 스키마에 따라 테이블에 저장되고,
- 데이터는 relation에 따라 연결된다.
- ACID(Atomicity, Consistency, Isolation, Durability)를 지켜야 할 때 쓴다.
NoSQL
- Not Only SQL
- data를 좀 더 flexible하게 처리한다
- 고정된 테이블은 없고, 테이블에 상응하는 컬렉션이 존재한다.
- 데이터의 일관성을 보장해주는 기능은 약하지만, 데이터를 바르게 삽입할 수 있고,
- scale out(데이터베이스를 여러 서버에 분산)이 가능하다.
- 굉장히 큰 데이터를 저장할 때 유용하다.
- Rapid Development → Schema 정의 등 초기 세팅에 드는 시간이 적다
트랜잭션
데이터의 상태를 변화시키기 위하여 수행하는 작업 단위
Commit: 하나의 트랜잭션이 성공적으로 끝났고, DB가 일관성 있는 상태임을 알려주기 위해 사용RollBack: 하나의 트랜잭션 처리가 비정상적으로 종료되었을 때 last consistent state로 되돌아간다.
ACID
에러 등의 상황에서도 데이터가 유효할 수 있도록 database transaction이 보장해야 하는 네 가지 properties
-
Atomicity: 각각의 transaction은 하나의
unit으로 동작하여야 함. 모두 함께 시행되던가, 아예 시행되지 않던가. 일부만 시행되는 것이 안된다는 것. 완전하게 시행되는 것에 실패하면 RollBack을 통해 트랜잭션 이전의 상태로 DB를 되돌린다. transaction이 실행중에 있을 때 다른 database client에 의해 접근되는 것도 막는다. -
Consistency: transaction이 항상 valid Database를 유지하도록 한다. (모든 데이터들이 constraints, cascade 등의 룰을 모두 따르도록) illegal 한 transaction의 접근을 막는다.
-
Isolation: transaction이 동시에 실행될 때, 순차적으로 실행될 때와 같은 결과를 전달해야 한다.
-
Durability:
commit이 완료된 트랜잭션은 어떤 상황에서도 계속해서 commit 상태로 남아있어야 한다. → 휘발적이지 않은 메모리에 completed transaction(또는 그 결과)을 저장해야 한다.
Transaction Isolation Level(트랜잭션 격리 수준)
ACID property 중 하나인 isolation은 가끔 relaxed 된다. level이 높아질수록 concurrency가 낮아지고, deadlock 가능성이 높아진다.
phenomena
- Dirty Reads 아직 commit되지 않은 데이터를 다른 트랜잭션이 읽게 되는 것
- Nonrepeatable Reads 하나의 트랜잭션에서 같은 query가 다른 결과를 가져오는 것(하지만 모두 커밋된 결과)
- Phantoms WHERE이 포함된 SELECT 절을 쓸 때 원래 존재하지 않았던 row가 추가된 것
이러한 세 현상의 유무에 따라 트랜잭션 격리 수준을 네가지로 나눌 수 있다
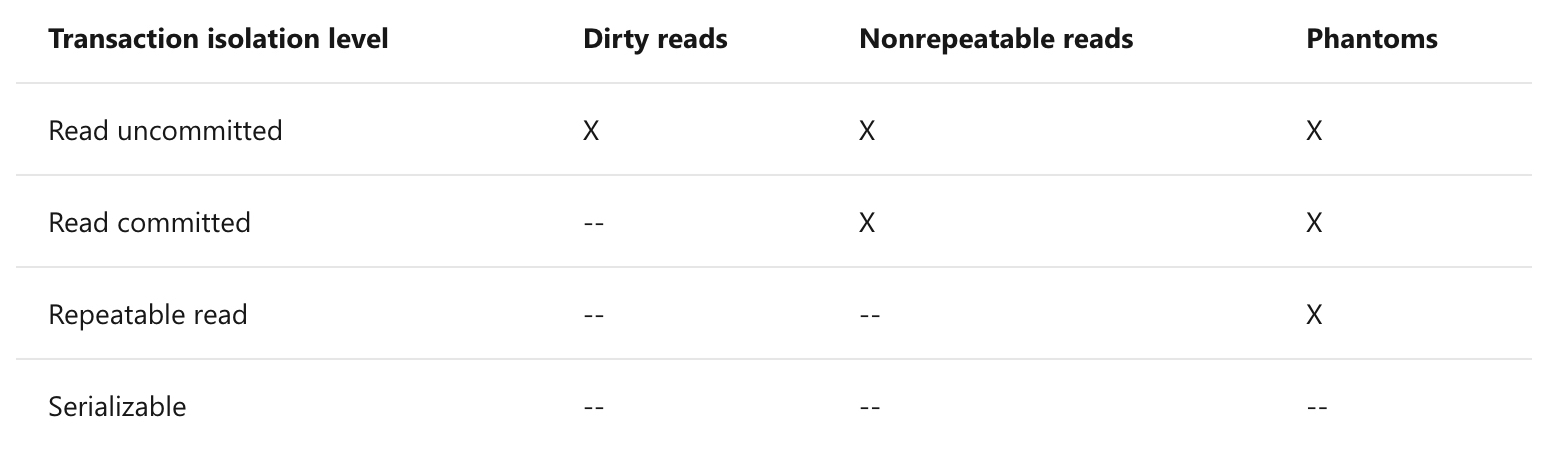
Reference-Microsoft doc(Transaction Isolation Level)
- READ UNCOMMITED
UNCOMMITED도 읽을 수 있음. 보통 READ-ONLY transaction - READ COMMITED
row에write-lock이 걸려있는 동안에는 접근하지 않는다. →"dirty data"에 접근하는 것을 막는다.
다른 row로 옮겨갔을 때 read-lock을 풀어주고, write-lock은 commit / rollback 전까지는 가지고 있는다.
- REPEATABLE READ
역시 row에write-lock이 걸려있는 동안에는 접근하지 않는다.
statement에 fetch할때마다 읽는 row에 모두 read-lock을 걸고, 생성하고 수정하는 등 변경 사항이 있는 모든 row들에 대해서도 write-lock을 건다. 두개의 락 모두 commit/rollback에 의해서만 풀려난다.
lock은 걸리지만 Insertion을 제한하지는 않는다.→ phantoms은 일어난다.
추가로 Write skew(복수가 한번에 같은 column을 수정)가 일어날 수 있다.
- SERIALZABLE
영향을 미치는 row들에 대하여 미리 lock을 걸게된다.
ranged WHERE을 쓰는 SELECT문이 있으면 range lock이 추가되어 phantom을 막는다.
Anomaly 이상현상
잘못된 테이블 설계로 인하여 이상현상이 일어날 수 있다.
1. 삽입이상
불필요한 데이터를 추가해야 삽입이 가능한 상황
-
갱신 이상
중복된 데이터를 저장하는 부분이 발생하여 하나의 row를 변경하였을 때 data inconsistency가 발생. -
삭제 이상
튜플 삭제로 인해 꼭 필요한 데이터가지 함께 삭제됨
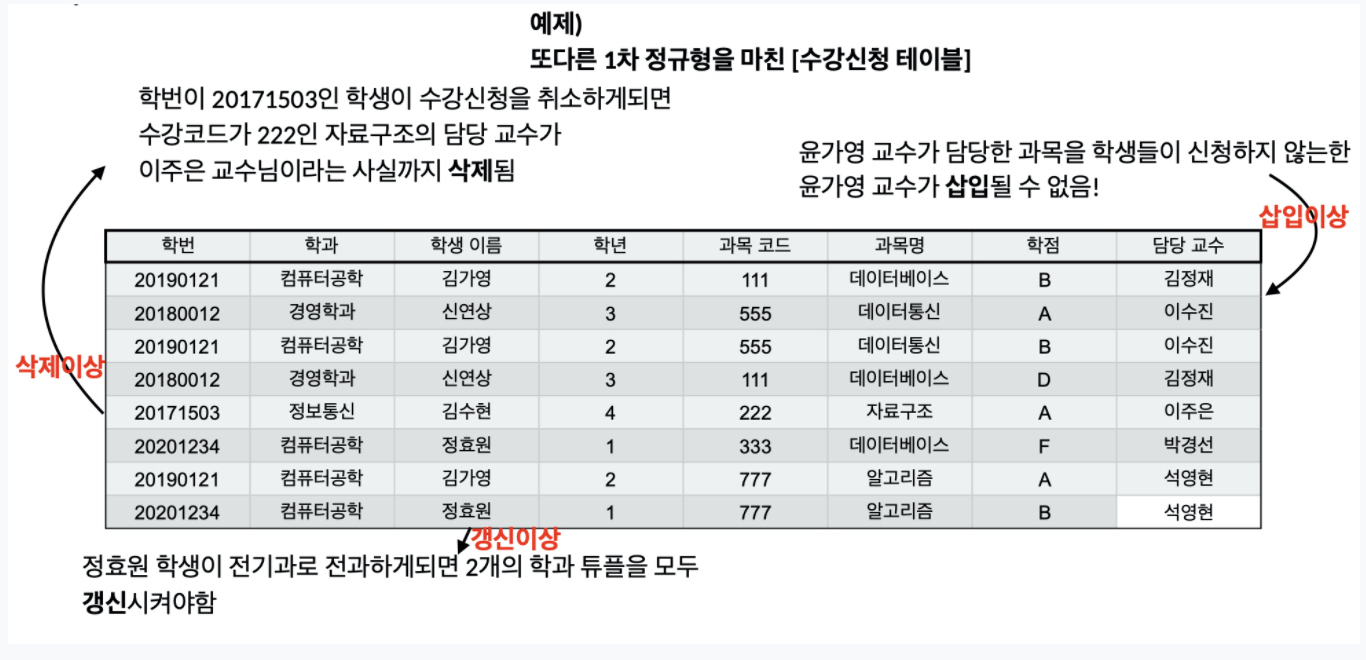
Reference(SOPT 27기 서버 세미나 자료)
정규화
주로 관계형 데이터베이스에서 불필요한 중복 데이터를 제거하고, 이상 현상을 방지하기 위해 db를 구조화하는 것을 말한다.
-
1차 정규화
각 column이 하나의 값만을 가져야 한다. -
2차 정규화
두개의 복합키가 primary key일 때 각각의 키에 모두 dependent해야함. 둘 중 하나에만 dependent하면 부분적으로 dependent하게 된다. 2차정규화는 후보키가 아닌 속성들이 후보키 부분이 아니라 전체에 dependent한 것을 말한다. -
3차 정규화
기본키가 아닌 일반 열에 의존하는 열을 제거하는 것
역정규화
정규화된 db에서 효율을 높이기 위해 이용된다. 중복된 데이터를 추가하거나, data를 그룹화함으로써 write performance를 희생하여 read performance를 향상시킨다.
- relation 병합 : 두 relation간 잦은 참조로 성능이 저하될 경우 병합, 또는 데이터를 중복하여 저장
- relation 분할 : 자주 사용하는 속성이나 튜플을 분할하여 성능을 향상(검색 시 항목이 많으면 느려지게 됨)
References
