교착상태?
프로세스 집합 내의 모든 프로세스가 그 집합의 다른 프로세스에 의해서만 일어날 수 있는 이벤트를 기다리는 상황
= waiting thread(또는 process)가 계속해서 waiting 상태에 있는 것 - 요청한 자원이 waiting 상태에 있는 다른 thread에 의해 점유되어있기 때문에
시스템 모델
한정된 개수의 자원을 가진 모델을 생각해보자. 이 자원들은 threads 에게 분배돼야하겠지.
그 때 resource를 여러개의 같은 instance를 갖는 type으로 구분할 수 있다.
(e.g. CPU cycles, files, and I/O devices)
→ 동일한 type에 한해서는 어떤 Instance를 할당받아도 상관이 없다.
교착 상태의 특성
교착 상태는 한 시스템에 네 가지 조건이 동시에 성립될 때 발생할 수 있다.
필요 조건들
Mutual Exclusion
최소한 하나의 자원이 non-sharable(비공유) 하다.
- non-sharable : 한 번에 한 스레드가 자원을 사용할 수 있다.
Hold and Wait
스레드는 최소한 하나의 자원을 점유(hold)한 채 다른 스레드가 점유하고 있는 자원을 추가로 얻기 위해 대기(wait)하고 있어야한다.
no preemption 비선점
자원은 선점이 불가하다.
circular wait
T1, T2 ... Tn 개의 스레드가 있을 때 T1이 T2가 점유한 자원을 대기하고, T2는 T3가 점유한 자원을 대기하고... Tn은 T1이 점유한 자원을 대기하는 순으로 순환적으로 구성돼야 한다.
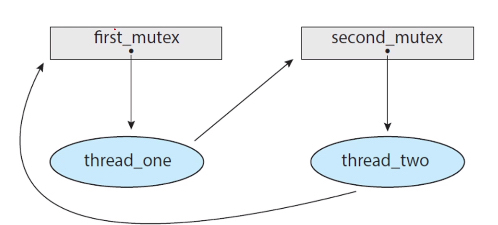
Resource-Allocation Graph 자원 할당 그래프
- deadlock을 정확하게 설명하기 위한 방향 그래프
- 두 종류의 node vertex가 존재 : active threads(T), resource types(R)
- request edge : Ti -> Ri - Ti가 Ri 자원을 요청했음을 의미
- assignment edge : Rj -> Tj - Rj 가 Tj에게 할당되었음을 의미
자원할당그래프에 사이클이 없다면, 시스템은 교착 상태가 아니다. 반면에, 사이클이 있다면 시스템은 교착상태일수도 있고, 아닐수도 있다.
교착상태를 처리하는 방법
3가지 방법이 있다.
- 문제를 무시하고 교착 상태가 절대 발생하지 않는 척 한다.
- 시스템이 교착 상태가 되는 것을 막기 위해 교착 상태를 예방 or 회피(Banker 알고리즘)하는 프로토콜을 사용한다. (어려움)
- 시스템이 교착 상태가 되도록 허용한 다음에 복구한다. -> detection and recover
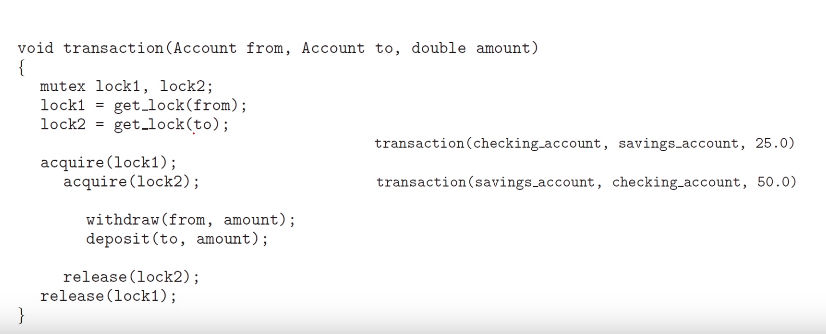
교착 상태 예방
교착 상태의 네가지 조건 중 최소한 하나가 성립하지 않도록 보장하기
상호 배제
모든 자원을 공유가능하게 만든다.
→ 불가능하다. 어떤 자원은 애초에 공유가 불가능(ex: mutex lock)
Hold and wait
스레드가 자원을 요청할 땐 다른 자원을 가지고 있지 않아야 한다.
→ starvation 일어날 수 있고, 자원 이용률이 낮아진다.
→ 실제 적용은 어렵다.
no preemption
자원을 선점 가능하게 한다. 대기중인 스레드로부터 원하는 자원을 선점하여 할당한다.
→ CPU 레지스터나 데이터베이스 트랜젝션처럼 상태가 쉽게 저장되고 복원되는 자원에는 적용 가능하지만 mutex 락이나 세마포어에는 적용 불가능하다.
circular wait
실제 이용 가능한 solution.
자원의 type에 indexing을 한다. (1. file, 2.memory, 3.SDD...)
→ 내가 점유하고 있는 resource index보다 index가 높은 순서로 요청하고
→ 점유 불가한 자원이 있으면 모든 자원을 방출
deadlock은 방지되지만 starvation이 발생할 수 있다.
→ 만약 락이 동적으로 획득될 수 있다면 락 순서를 부여한다고 해서 데드락 예방을 보장하진 않는다.
교착 상태 회피
교착 상태 예방은 장치 이용률도 저하시키고, throughput 도 감소시킨다.
교착상태 회피는 각 요청에 대해 교착 상태를 일으킬 가능성이 있으면 대기시킨다.
→ 리소스가 어떻게 요청될 지에 대한 추가 정보가 필요하다.
정보를 가지고 deadlock을 일으키지 않을 algorithm을 찾아내는 것
→ 가장 단순하면서 유용한 모델은, 각 스레드가 자신이 필요로 하는 각 유형의 자원마다 최대 수를 선언하도록 요구하는 것이다.
가용 자원의 수, 할당된 자원의 수, 스레드들의 최대 요구 수를 통해 알고리즘을 짠다
safe state
safe state (deadlock free) : deadlock을 방지하면서 모든 thread에 자원을 할당할 수 있는 순서가 존재한다.
==> safe sequence
-> deadlock avoidance algorithm의 핵심
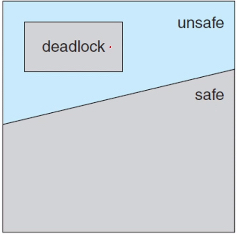
모든 unsafe state가 deadlock을 발생시키지는 않지만, 가능성이 있기에 safe state에만 머무르도록 하자.
이러한 safe state 개념을 가지고 두가지의 deadlock 회피 알고리즘을 작성할 수 있다.
시스템 초기 상태에는 safe state 이다. 어떤 스레드도 자원을 가지고 있지 않기에 hold and state 조건을 만족시킬 수 없다.
그렇다면 그 이후의 모든 request에 대하여 우리는 deadlock의 발생을 판단해야한다.
deadlock이 발생하지 않는 경우에만 자원을 할당하도록 한다.
resource-allocation graph algorithm
원래의 request edge와 assignment edge에, claim edge(예약 간선 - 점선으로 표현한다)를 추가한다.
스레드가 실행되기 전에 스레드의 모든 예약 간선은 자원 할당 그래프에 추가돼야 한다.
claim edge를 통해 cycle dection 을 실행하여 cycle을 생성하지 않는 경우에만 request edge로 바꾸어 자원을 할당한다.
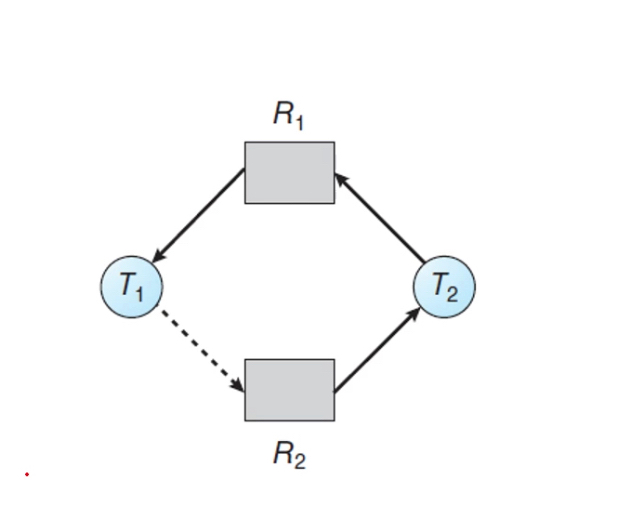
RAG는 각 resource type에 여러개의 instance가 있을 때는 활용할 수 없다.
은행원 알고리즘
RAG 보다 비효율적이고 더 복잡하다.
→ 은행에서 여러명의 고객들이 있을 때 일정한 순서에 있게 모든 고객들의 요청을 들어줄 수 있게 하는 알고리즘
스레드가 가지고 있어야 할 자원의 최대 개수를 자원의 종류마다 기록하여 이를 기반으로 request 가 들어올 때마다 시스템이 safe state에 머무를 수 있는 지 확인하여 허가
요청이 들어올때마다,
현재 가지고 있는 자원의 instance 정보와 각 스레드들이 필요로하는 자원 instance 정보를 기반으로
- 현재 요청된 자원들이 available한지(시스템이 필요한 instance 개수를 모두 가지고 있는지) 확인하고,
- 해당 요청을 수락했을 때 safe state로 남을 수 있는 지를 확인하여
위 조건들을 모두 만족시킬 때에만 request를 즉시 할당해준다.
이 때 두개의 알고리즘을 이용한다.
-
안정성 알고리즘 : 시스템이 안전한지 확인한다
-
자원 요청 알고리즘 : 자원 request를 safe하게 해결해줄 수 있는지 확인한다
교착 상태 탐지
unsafe state가 항상 deadlock을 유발하진 않는다. 그렇다면 교착 상태 회피는 시스템상 크게 효율적이지 않은 알고리즘일 수 있다. (→ 절대로 deadlock이 걸리면 안되는 시스템이 아니면 부담이 될 수 있다)
그러니까 일단 허용을 해주고, deadlock에 빠졌는 지 감시를 하고, deadlock이 빠졌을 때 복구를 해주자는 것
Single Instance of Each Resource Type
대기 그래프(wait-for graph, 자원 할당 그래프의 변형)를 이용할 수 있다.
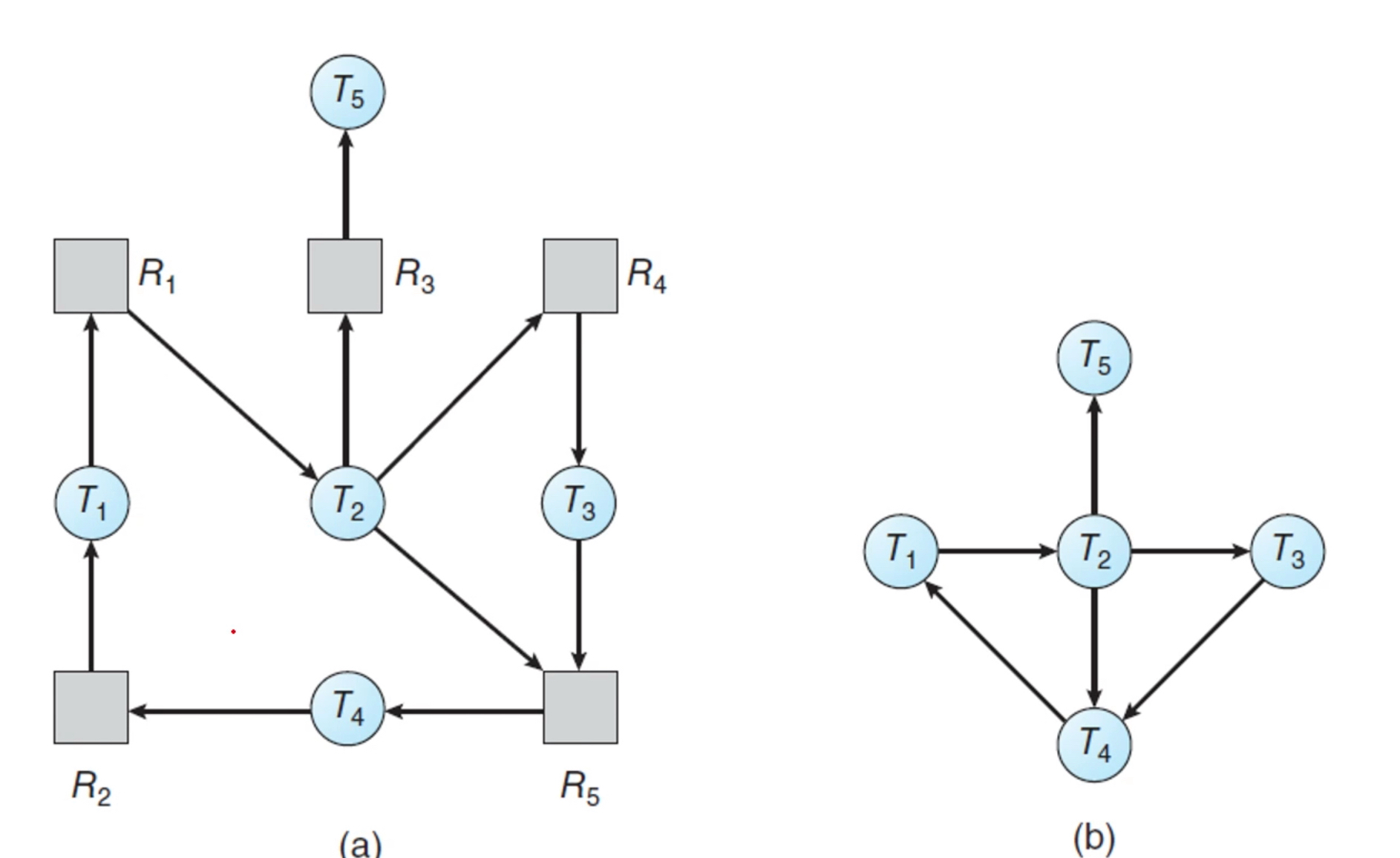
자원 할당 그래프에서 자원을 없애서 dependency graph를 그리면 wait-for graph를 사용한다. → 주기적으로 wait-for graph에 cycle이 존재하는 지를 확인한다.
Several Instances of a Resource Type
은행원 알고리즘과 굉장히 비슷하다.
다른 것이 있다면, 은행원 알고리즘은 Request가 생기면 이를 실행하기 전에 safe state를 없애는 지 확인하고 수행하였다면 교착 상태 탐지에서는 그냥 요청을 시키고 주기적으로 교착 상태에 빠졌는 지를 확인한다.
- 교착 상태 탐지 방법
현재 할당된 자원이 존재하는 thread i에 대하여 Finish[i] = false 로 초기화한다.
→ 현재 available한 자원들로 thread i가 원하는 자원을 모두 충족시켜줄 수 있으면 Finish[i] = true로 바꿔주고 thread i가 가진 자원들을 available 상태로 간주한다.
→ Finish[i] = false인 모든 thread에 대하여 바로 위의 과정을 반복하면 현재 available한 resource를 이용할 수 있는 순서열이 만들어진다.
→ 위 과정을 거친 후에도 Finish[i] = false 인 스레드가 존재한다면 교착 상태에 빠진 것이다.
detection algorithm을 얼마나 자주 돌릴 것인가
- 교착 상태가 얼마나 자주 일어나는 지
- 교착 상태가 일어날 때 보통 몇 개의 스레드가 연루되는 지를 고려해준다. (term이 길어지면 연루되는 스레드도 많아질 수 있다)
일정 시간마다 또는 CPU 이용률이 떨어질때마다 호출할 수 있다.
임의의 시간에 호출하게 되면 여러개의 자원 그래프가 임의의 사이클을 포함하게 되어 어느 스레드가 교착 상태를 일으켰는지 확인하기 어려워질 수 있다.
교착 상태 회복
- 운영자에게 알려주어 운영자가 직접 처리한다.
- 시스템이 자동으로 회복한다
의 두 가지 방법이 있다.
어떻게 처리할 수 있을까?
1. 프로세스와 스레드의 종료
- 교착 상태의 프로세스를 모두 중지하거나
- 교착 상태가 제거될 때까지 하나의 프로세스씩을 중단한다.
첫번째 방법은 프로세스들의 연산 결과를 모두 reset하여 다시 시작하도록 하고, 두번재 방법은 각 프로세스가 중단될 때마다 교착 상태 탐지 알고리즘을 호출하므로 상당한 오버헤드
2. 자원 선점
- 교착 상태가 깨질때까지 프로세스로부터 자원을 선점하여 다른 프로세스에게 준다
이를 위해서는 다음 세 가지 사항을 고려해야 한다.
-
희생자 선택(selection of a victim)
어느 자원과 어느 프로세스들이 선점될 것인가? -
후퇴(rollback)
victim이 된 프로세스를 안전한 상태로 후퇴시키고 그 상태에서 재시작시켜야 한다. 일반적으로는 그냥 중지하고 재시작한다. -
starvation
계속해서 victim이 되는 현상을 방지해준다. victim이 되는 횟수를 제한
