트랜잭션(Transaction)
데이터베이스의 상태를 변화시키기 위한 일련의 연속적이 작업들의 모음
거래과정 전체가 있을때 모든 과정이 원활하게 되서 완료까지 된 것
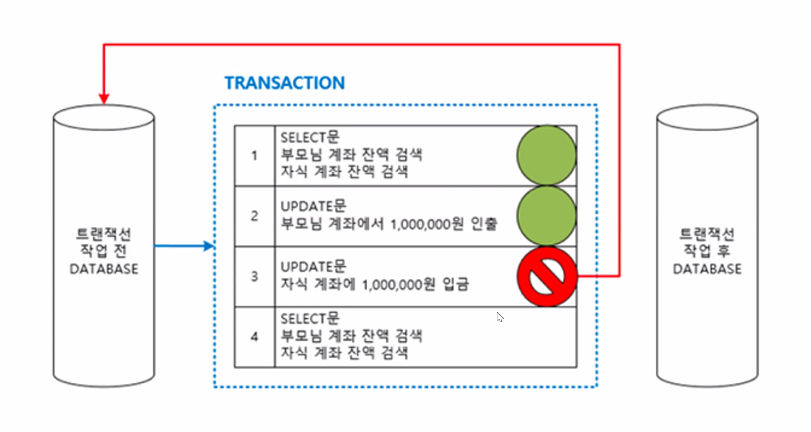
이 과정이 전부 일어난 다음에는 commit을 해주어야 DB에 입력
정상적으로 일어났다고 말할 수 있음
ACID
하나의 트랜잭션의 안정성을 보장하기 위한 성질
-
Atomicity(원자성) : 전체가 완료가 되어야 하나의 트랜잭션이 일어난 것. 하나의 오류도 있으면 안된다는 것
전부 성공하거나 실패해야함 -
consistency(일관성) : DB의 규칙이 잘 준수되도록 테이블을 구성하고, 그에 맞게 활용하는 것. NULL허용을 하지 않는 것 자체도 일관성 유지!
데이터베이스의 제약을 따라야함 -
Isolation(고립,독립성) : 작업을 하는데 있어서 둘간에 간섭이 있지 않고 별개로 일어나게 하는 것
각각의 트랜잭션은 독립적이어야함
ex) 내가 2만원 가지고 있을 때, 넷플 1.7, 디플 .99 결제 불가능 -
Durability(연속성) : 한번 정해지면 바뀌지 않는다. 1원을 송금한 기록이 사라지지 않고 지속적으로 남아 있어야 된다
해당 기록은 영구적이어야함
실습해보기
트랜잭션과 ACID 속성이 중요한 작업 → RDB로 작업해보자
(관계형DB로 작업해보자)
SELECT CustomerID, AVG(Total)
FROM invoices
WHERE CustomerID >= 10;where조건. 아이디와 평균 가져와라. invoices에서
SELECT CustomerID, AVG(Total)
FROM invoices
WHERE CustomerID >= 10
GROUP BY CustomerId
HAVING SUM(Total)>=30
ORDER BY 2;❗ where와 having의 차이
: where은 레코드 하나하나에 대한 조건을 거는 것이고,
having은 그룹 전체에 대한 조건을 거는 것
그래서 where절 다음에 group by절을 사용해야하고, group by절 다음에 having절을 사용한다.
🔑 실행 순서
FROM→ON→JOIN→WHERE→GROUP BY→HAVING→SELECT→ORDER BY
🔑 작성 순서
SELECT→FROM→JOIN→ON→WHERE→GROUPBY→HAVING→ORDER BY
GROUP BY
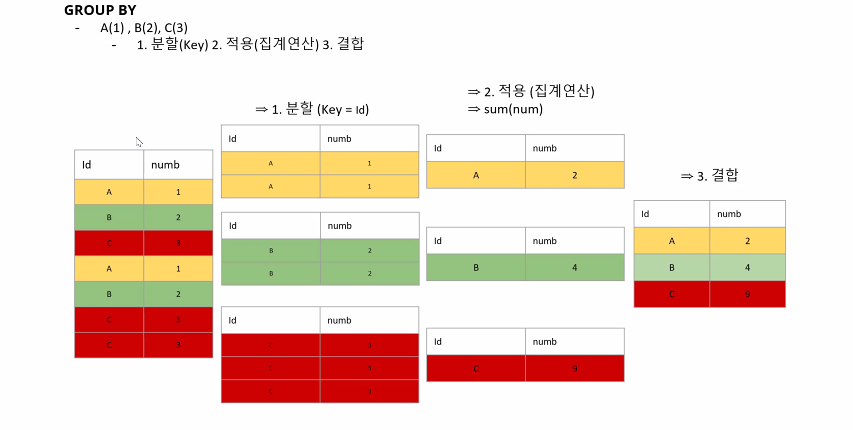
procedure : state → sprit → apply (count,sum...) → combine
순서 : 상태 → 분할(key=id) → 적용(집계연산) → 결합
HAVING

SubQuery
- 하나의 변수처럼 사용한다
- 테이블을 리턴 받아서 사용한다
- 하나의 칼럼처럼 사용한다
- 가급적이면 짧게 사용!
❓ QnA
Q. 명령어가 조금씩 다른 것 같아요.
A. 데이터베이스 설계할때마다 특징이 있는데, 이때 효율적으로 관리하기 위해서 command가 조금씩 달라질 수 있다.
SQL More
(https://www.sqlitetutorial.net/sqlite-sample-database/)
sql 사용시에는 각각 데이터를 다루기 전에 어떻게 데이터들이 이루어져있는지 확인하고 진행하는 것이 좋다
내장함수
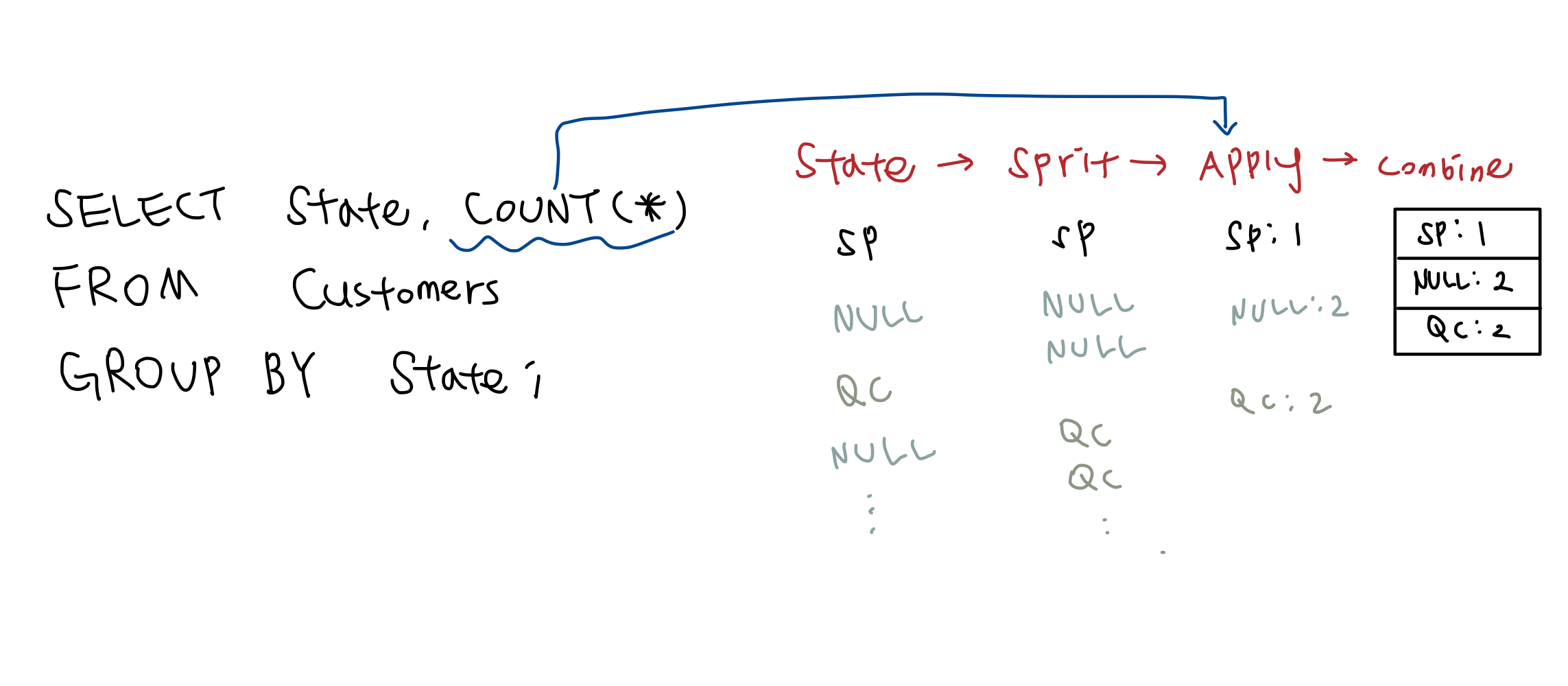
GROUP BY : 통계, 집계할때 사용
SELECT * FROM Customers
GROUP BY State;state를 중심으로 그룹핑되어 나타남. 여러개 있다면 상위 첫번째 레코드가 조회됨
SELECT state, COUNT(*) FROM Customers
GROUP BY State;평균과 합계, 통계적인 것에 같이 사용하는게 더 유의미
group by를 하려는 것은 집계하기 위함. (개수를 세거나, 평균을 내거나, 표준편차를 내거나...통계)
ORDER BY : 순서 정렬
SELECT state, COUNT(*) FROM Customers
GROUP by State
ORDER by State DESC;기본 설정은 ASC 오름차순 (생략 가능). DESC 내림차순
HAVING
SELECT CustomerId, AVG(Total) avgtotal
FROM invoices
GROUP BY CustomerId
HAVING avgtotal > 6.00;그룹화한 결과에 대한 필터. 즉 group by의 결과에 대한 필터
집계함수
COUNT
SUM
AVG
MAX(), MIN()
SELECT CustomerId,
COUNT(CustomerId) InvoiceCnt,
AVG(Total) AvgTotal,
SUM(Total) SumTotal,
MAX(Total) MaxOfTotal
FROM invoices
GROUP BY CustomerId;CASE 사용하기
SELECT
CustomerId,
(
CASE
WHEN CustomerId <= 25 THEN 'GROUP 1'
WHEN CustomerId <= 50 THEN 'GROUP 2'
ELSE 'GROUP 3'
END
) GRP
FROM customers
ORDER BY CustomerId;
sql문에서 if 사용하는 것과 같음
SUBQUERY
조건을 넣어서, 반환값은 필드 하나가 오는 것이 일반적
FROM에도 사용가능함
SELECT CustomerId, CustomerId = 2
FROM customers
WHERE CustomerId < 6;=
SELECT CustomerId, CustomerId = (SELECT CustomerId FROM customers WHERE CustomerId = 2)
FROM customers
WHERE CustomerId < 6;IN, NOT IN
SELECT *
FROM customers
WHERE CustomerId IN (3, 6, 9);3,6,9에 해당하는 customers 가 출력
그가 아닌 것을 출력하고 싶다면 IN 대신에 NOT IN 사용
Pandas vs SQL
개인적으로 비교해보기. N413에 rf로 존재함~~~
그중에서 새롭게 배운(?) 것들 위주로 적어둠
- LIMIT OFFSET
tips.iloc[3:8, :]=
SELECT *
FROM tips
LIMIT 5 OFFSET 3;- CONCAT
pd.concat([df1, df2])=
SELECT city, rank
FROM df1
UNION ALL
SELECT city, rank
FROM df2- df1과 df2를 세로로 합치기 위해서는 합치고자 하는 데이터 프레임을 리스트에 넣어 concat안에 넣어줍니다. pandas에서는 자동적으로 null을 생성하여 열이 동일하지 않더라도 합쳐줍니다. 반면 SQL에서는 합지는 두 데이터프레임의 열이 같아야 합니다. 만약 다를 경우 error가 발생합니다.
- 만약 두 데이터 프레임을 세로로 합쳐준 다음 중복되는 값들을 제거 하고자 한다면 pandas 에서는 dop_duplicates() 함수를 사용합니다. SQL에서는 UNION ALL 이 아닌 UNION 을 이용하면 됩니다.
과제하면서 배운 것들
- iloc
tips.iloc[3:8,:] # 3:8은 행(3-7출력), 뒤에 :는 열, row 추출- sqlite 에서 concat 하는 법 -> ||
SELECT CustomerId, UPPER(c.City) || ' '|| UPPER(c.Country) AS Country
FROM Customers c; - substring (iloc)
substring(문자열, 시작, 끝)
SELECT SUBSTRING(LOWER(FirstName),1,4)||SUBSTRING(LOWER(LastName), 1,2) new_customerId
FROM customers;- AUTOINCREMENT
테이블의 id 컬럼에 대한 값이 없는 채로 데이터를 넣는 법
CREATE TABLE Teachers(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name VARCHAR(30),
subject VARCHAR(10) NOT NULL,
salary INTEGER);이렇게 설정해주면 아래처럼 id값 넣지 않아도 insert 가능
INSERT INTO Teachers(name, subject, salary)
VAlues ('Spongebob', 'Math', 3500);- record 일련번호 붙이기
→ http://www.sqlprogram.com/TIPS/tip-row-number.aspx
→ https://gent.tistory.com/456
SELECT teacher_id, student_id, ROW_NUMBER() OVER (ORDER BY (select null)) '전체 학생순서'
FROM Student;SELECT teacher_id, student_id, ROW_NUMBER() OVER (PARTITION BY teacher_id ORDER BY (teacher_id)) '선생님별 학생순서'
FROM Student;- 중앙값
median이 되지 않을 때!
→ https://stackoverflow.com/questions/15763965/how-can-i-calculate-the-median-of-values-in-sqlite
SELECT student_id, age as '중앙값'
FROM Student
LIMIT 1
OFFSET (SELECT COUNT(*)
FROM Student) / 2;💌 오늘의 회고
오늘 교수님(?)이 코딩은 암기가 기본이라고 하셨다. 나는 외우는거 글케 못하는디... 머리를 열어서 바꿀 수도 없고. 많이 해보면 외워지는거 아닌가? 싶기도~ 어제 배운 것의 연장선이라서 괜찮았다. sql문이 개인적으로 더 쉽게 느껴지는 것 같은데 뭔가 명확해서 그런듯. select, from, where로만 하면 되기도 하고, 여러 함수 사용안해도 되서 그런가 ㅋㅋ.. 아직 sql의 기본만 다뤄서 그런 것 같기도 하지만,,, 쨌든! 흥미가 있어서 재밌게 따라가는 중. 수학문제 풀듯 해결되는 점이 아주 마음에 든다.
