DUS(Depth-Up-Scaling)
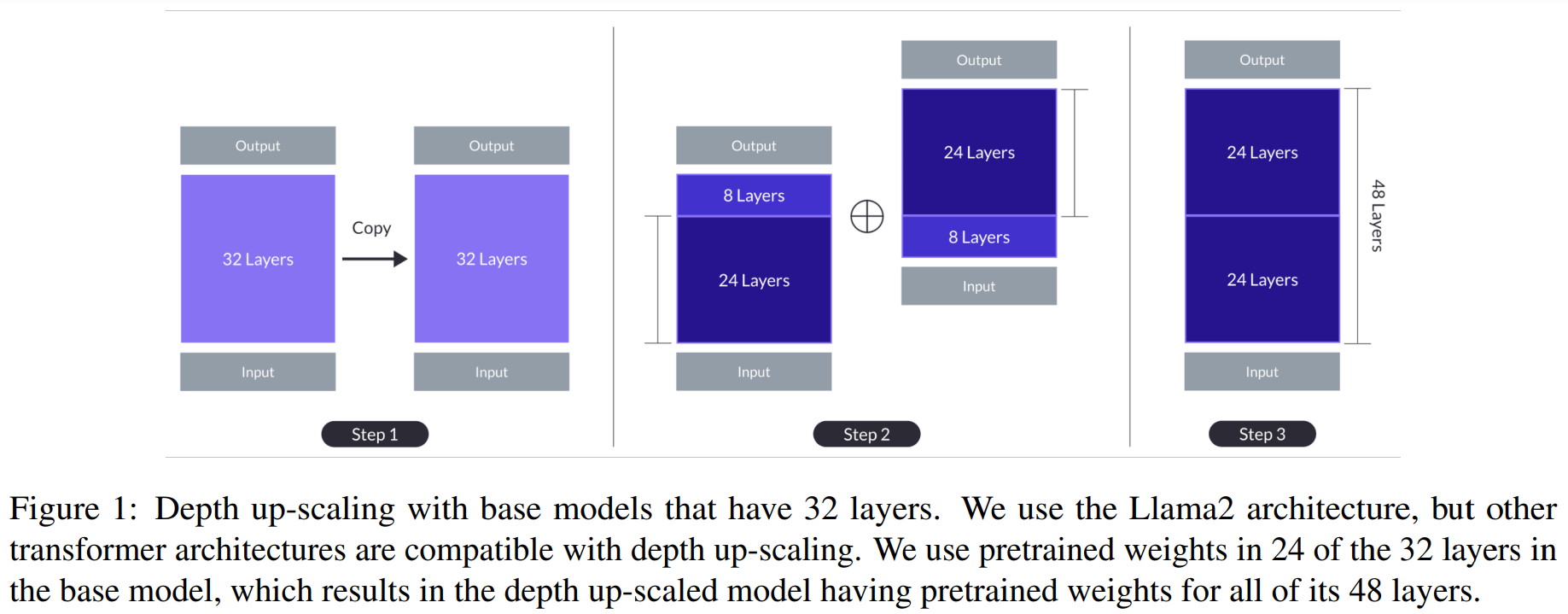
Mistral 7B 모델을 베이스로 해서 복사해서 2개의 모델 만듬
각 위 8개, 아래 8개 layer 제거하고 합쳐서 48 layer 만듬
그러면 10.7B지만 성능이 떨어져서 다시 pretraing -> instruction (QA 데이터) -> alignment (DPO)
Model Merge
DUS도 동일한 아이디어
- SLERP(Spherical Linear Interplation)
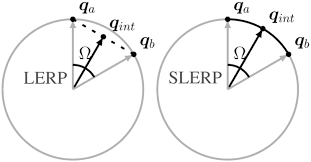
두 벡터 사이를 부드럽게 보간
- TIES-Merging(Trim, Elect Sign & Merge)
chat vector 조사nc 블로그
sakana.ai 조사
여러 모델을 단일 모델로 병합
- 모델 매개변수 중복제거
- 매개변수 간 불일치 해결: 다른 모델이 동일 매개변수에 반대될 때 통합 기호 벡터를 만들어 충돌 해결
- Trim: 가장 중요한 매개변수의 일부만 유지하고 나머지는 0으로 재설정, 모델 중복성 줄임
- Elect Sign: 누적 크기면에서 가장 우세한 방향(양수 혹은 음수)을 기반으로 통합 기호벡터 생성해 기호 충돌 해결
3.Disjoint Merge: 0값을 제외하고 통합 기호 벡터와 정렬되는 매개변수 값의 평균 계산
- Passthrough
다른 LLM 레이어를 연결해 새로운 하나의 모델을 만듬
모델의 매개변수 증가
DUS가 동일한 아이디어
리더보드에선 SLERP가 가장 높았음
- Mergekit
깃헙
모델 앙상블과 유사한 개념인데 더 효율적이고 효과적
방법론
1. Linear: 가중치를 평균
2. slerp: 데이터 포인트를 구면상의 점으로 간주해서 smooth한 곡선을 그리는 방식으로 없는 값 채움, 모델이 2개일 때만
3. task_arithmetic: 다른 모델의 가중치에서 기본 모델의 가중치를 빼 작업 벡터(편차)를 생성 후, 선형적으로 병합하고 기본 모델에 다시 더함, 모델이 여러 개일 때
4. ties
5. dare: 작업 벡터 희소화하고 새로운 재조정 기법 적용. task_arithmetic과 ties 붙일 수 있음
6. passthrough: 레이어 병합, 하나의 입력 모델만 있을 경우 유용
Distillation
student, teacher
Distillkit
feaures
-
Logit-based: 같은 아키텍처여야 함
hard target(실제 label), soft target(teacher logit). soft target loss는 Kullback-Leibler (KL) divergence. student가 teacher의 output 분포를 따라하게. student 모델의 generalization 과 efficiency를 높임 -
Hidden States-based: 다른 아키텍처여도 됨
student 모델의 중간 layer representation을 aligning해서 지식 transfer
DPO와 GPT는 나중에 나옴
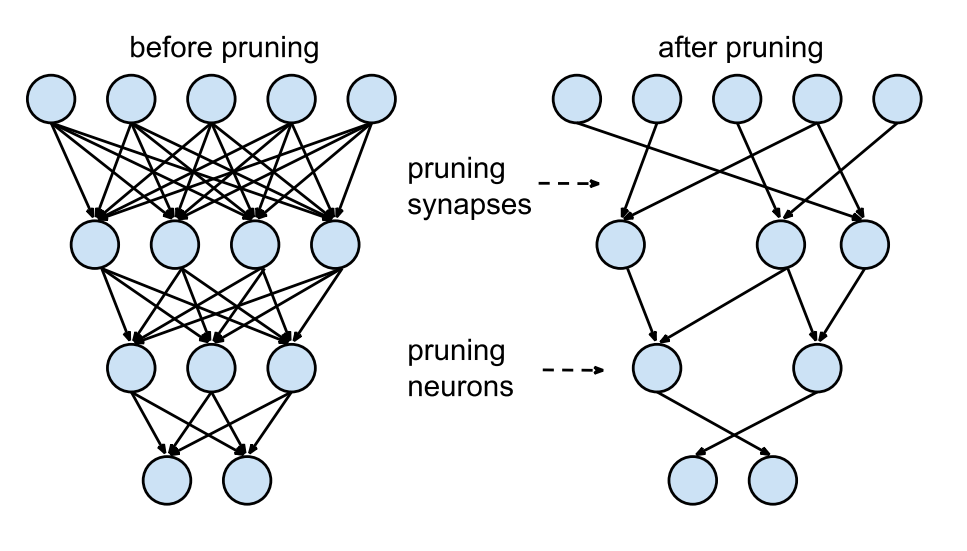
Pruning
중요한 파라미터는 살리고 아닌건 가지치기하는 경량화
KMMLU benchmark
네이버 클라우드 + EleutherAI
인문학, 과학, 기술, 공학, 수학 등 총 45개 주제
다지선형 선택 문제
한국어의 언어적, 문화적 특징을 반영
LLM은 마케팅, 컴퓨터 과학, 정보 기술, 통신 및 무선 기술 분야에선 good
한국사, 수학, 특허, 세무, 형법 같은 특정 문화적 또는 지역적 지식에선 bad
데이터 합성
인위적으로 생성된 데이터
nvidia에서 합성 데이터 생성하는 nemotron-4 340B 출시
prompt 형태 다양화하는 것이 중요(쓰기, Q&A, 주제 다양화, 지시문 다양화:json, 문단, yes or no answers)
CoT는 100B이상의 큰 모델들에게 효과적
LLM기반 합성 데이터 연구
데이터 증강이 일반적
- WizardLM
지시문 데이터 생성 과정에서 사람의 의존도를 줄이고 다양한 난이도의 질문을 확보
-
초기 지시문
{
"Skill": "Writting",
"Difficulty": 3,
"Instruction": "As an experienced writer, (후략)"
} -
LLM을 사용해 지시문 진화
- 수직 진화(In-Depth Evoloving): 복잡하고 어려운 질문, 조건 넣기, 심화, 개념화, 근거의 단계 증가, 복잡한 입력값
- 수평 진화(In-Bradth Evolving): 주제, 태스크 등의 면에서 다양한 질문 만드는 것이 목표
- 특정 조건이 성립되면 중지
- 엔트로피 증가X
- 의미 없는 문자열 나열
- 답변이 지시문 복붙
- LLM이 어려워라고 말한 경우
