https://m.blog.naver.com/ca1ibre/223039483745
dataflow
dataflow 모델링은 입출력 사이의 신호 흐름을 연산자를 사용하여 나타내는 방법이다.
dataflow 모델링으로 만든 반가산기
module half_adder_dataflow( //수식으로 처리하는것 dataflow
input a, b,
output s, c);
wire[1:0] sum_value; //2비트짜리 sum_value 선언
//1비트 a, b의 합은 최대 2비트
//레지스터는 저장, wire는 연결
assign sum_value = a + b; //2비트 sum_value를 a+b로 할당
//assign문은 wire변수로 선언, 덧셈기는 vivado 기본 기능으로 장착
assign s = sum_value[0]; //2비트 sum_value의 0번 비트를 s에 할당
assign c= sum_value[1]; //2비트 sum_vaule의 1번 비트를 c에 할당
endmodule동작적 모델링, 구조적 모델링, 데이터플로우 모델링
전가산기
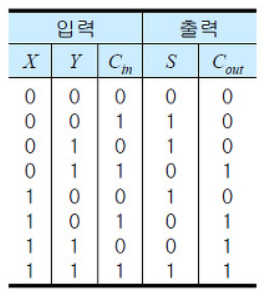
전가산기는 뒷자리에서 올라운 올림수를 포함하여 1비트 입력들을 더해 합과 올림수를 구하는 회로이다
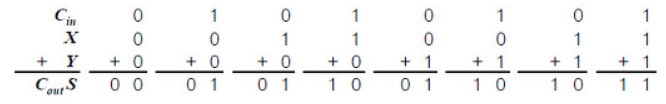
진리표
논리식
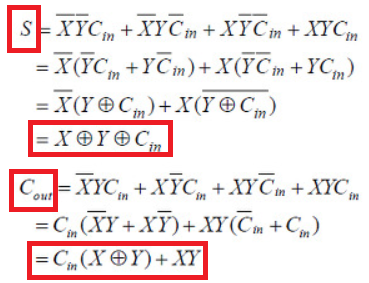 합 비트는 세 입력 비트의 XOR(배타적 OR) 연산으로 계산된다.
합 비트는 세 입력 비트의 XOR(배타적 OR) 연산으로 계산된다.
A xor B를 한것에 다시 Cin을 xor
Cout은 A xor B 한것에 Cin을 and하고 이것과 A and b를 or한것
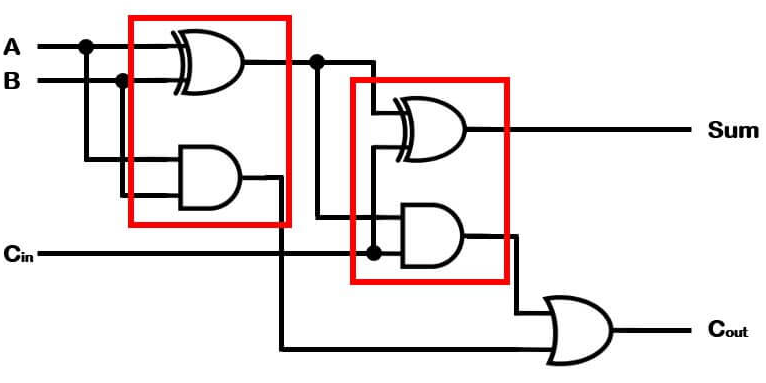
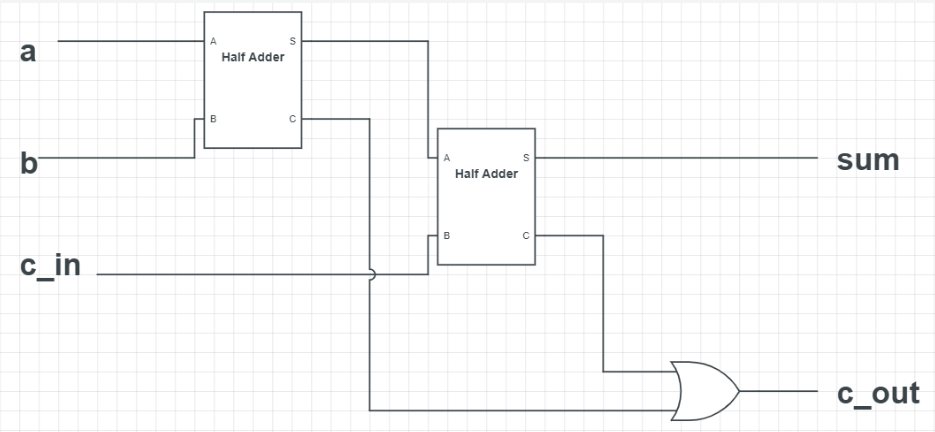
가산기-구조적
반가산기2개 OR게이트1개로 구성
module full_adder_structural(
input a, b, c, //입력과 전단의 캐리
output sum, carry); //합과 발생하는 캐리
wire sum_0, carry_0, carry_1; //전가산기 내부 반가산기2개와 OR게이트를 내부적으로 연결하기 위한 wire들 3개 선언
//전에 미리 만들어져있는 half_adder_structural모듈이 있어 사용
half_adder_structural ha0(.a(a), .b(b), .s(sum_0), .c(carry_0)); //첫번째 반가산기를 연결
half_adder_structural ha1(.a(sum_0), .b(c), .s(sum), .c(carry_1)); //두번째 반가산기를 연결
or (carry, carry_0, carry_1);
endmodule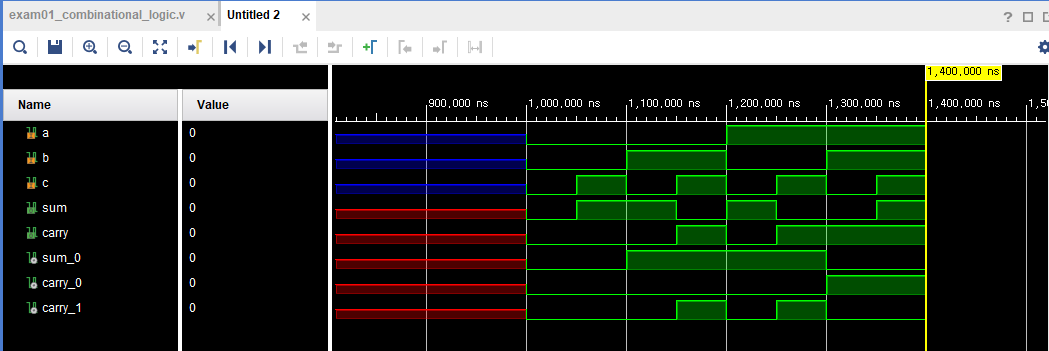
가산기-동작적
module full_adder_behavioral(
input a, b, c,
output reg sum, carry); //always 문에 들어가는 변수들 reg 설정
always @(*)begin
case({a, b, c})
3'b000: begin sum = 0; carry = 0; end //진리표대로 작성
3'b001: begin sum = 1; carry = 0; end
3'b010: begin sum = 1; carry = 0; end
3'b011: begin sum = 0; carry = 1; end
3'b100: begin sum = 1; carry = 0; end
3'b101: begin sum = 0; carry = 1; end
3'b110: begin sum = 0; carry = 1; end
3'b111: begin sum = 1; carry = 1; end
default: begin sum = 0; carry =0; end
endcase
end
endmodule가산기 dataflow
 이렇게 있다고 보자
이렇게 있다고 보자
module full_adder_dataflow(
input a, b, c,
output sum, carry);
wire [1:0] sum_value; //출력값을 위한 2비트짜리 sum_value 만듬
assign sum_value = a + b + c; //sum_value는 a+b+c라는 덧셈회로 구성
assign sum = sum_value[0]; //첫번째 비트 덧셈값, 첫번째 비트값 sum에 할당
assign carry = sum_value[1]; //캐리발생시 두번째 비트값, 두번째 비트값 carry에 할당
endmodule
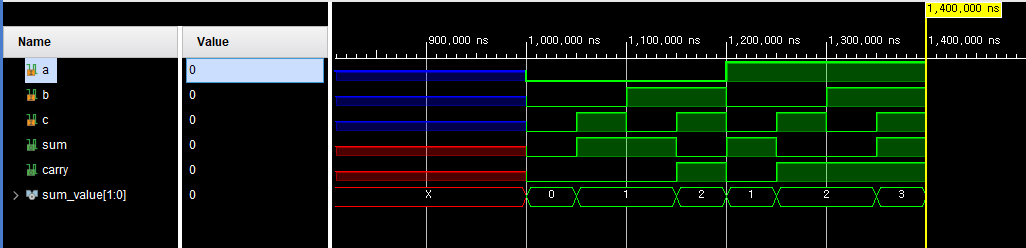

비트값이 바뀌는 시점들을 표현하면서 비트값을 16진수로 표현
4비트 전가산기
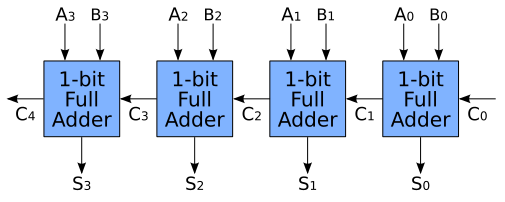 4비트 전가산기(4-bit full adder)는 4비트의 두 이진수를 더할 수 있는 디지털 회로이다. 이를 위해 각 비트 위치에서의 합을 계산하고, 각 자리올림(carry) 비트를 다음 자리로 전달한다.
4비트 전가산기(4-bit full adder)는 4비트의 두 이진수를 더할 수 있는 디지털 회로이다. 이를 위해 각 비트 위치에서의 합을 계산하고, 각 자리올림(carry) 비트를 다음 자리로 전달한다.
4비트 전가산기는 네 개의 1비트 전가산기(full adder)를 연결하여 구현된다. 이 회로는 더 복잡한 덧셈 연산을 수행하는 데 사용되며, 큰 수의 덧셈을 쉽게 처리할 수 있도록 설계된다.
4비트 전가산기-구조적
module fadder_4bits_s(
input [3:0] a, b, //첫번째 비트 a1+b1, 두번째 비트 a2+b2....., 입력비트 4개씩
input cin, //입력 캐리
output [3:0] sum, //출력 덧셈값 4개
output carry); //출력 캐리
wire [2:0] carry_w; //내부연결 와이어 선언(3개)
//위에 만들어두었던 full_adder_structural모듈 사용 이름 fa0,1,2,3 선언
full_adder_structural fa0(.a(a[0]), .b(b[0]), .c(cin), .sum(sum[0]), .carry(carry_w[0]));
full_adder_structural fa1(.a(a[1]), .b(b[1]), .c(carry_w[0]), .sum(sum[1]), .carry(carry_w[1]));
full_adder_structural fa2(.a(a[2]), .b(b[2]), .c(carry_w[1]), .sum(sum[2]), .carry(carry_w[2]));
full_adder_structural fa3(.a(a[3]), .b(b[3]), .c(carry_w[2]), .sum(sum[3]), .carry(carry));
endmodule 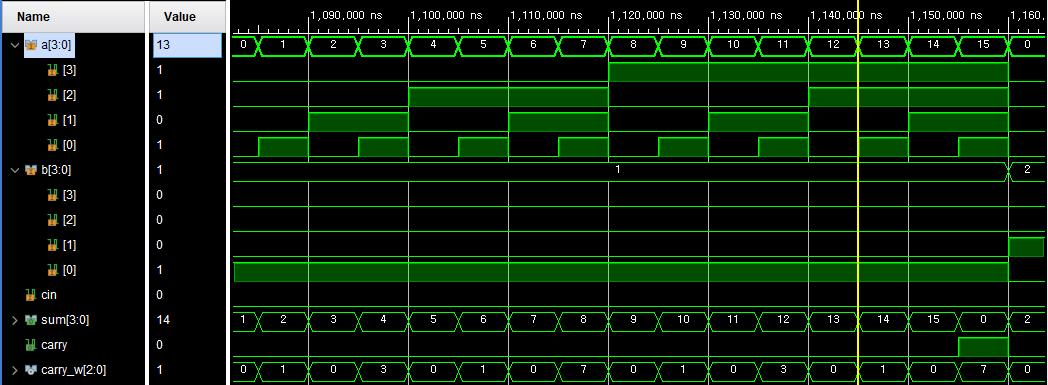
force clock
a : 10, 20, 40, 80
b : 160, 320, 640, 1280
cin : 2560
4비트 a값 0~15
4비트 b값 0~15
b값이 1이고 a값 10진수15==2진수1111 캐리발생
cin 또는 내부적으로 발생한 캐리들과 a비트, b비트와 합할때 캐리발생
표현되는 진수표현 변경가능(현재 부호없는 10진수->+정수만 표현가능)
4비트 전가산기 dataflow
module fadder_4bits_dataflow(
input [3:0] a, b,
input cin,
output [3:0]sum,
output carry);
wire [4:0] sum_value; //5비트짜리 sum_value 만듬
assign sum_value = a + b + cin; //sum_value는 a+b+cin라는 덧셈회로 구성
assign sum = sum_value[3:0]; //4비트의 덧셈값
assign carry = sum_value[4]; //캐리발생시 마지막 비트값
endmodule
동일한 시뮬레이션
보수를통한 감산기
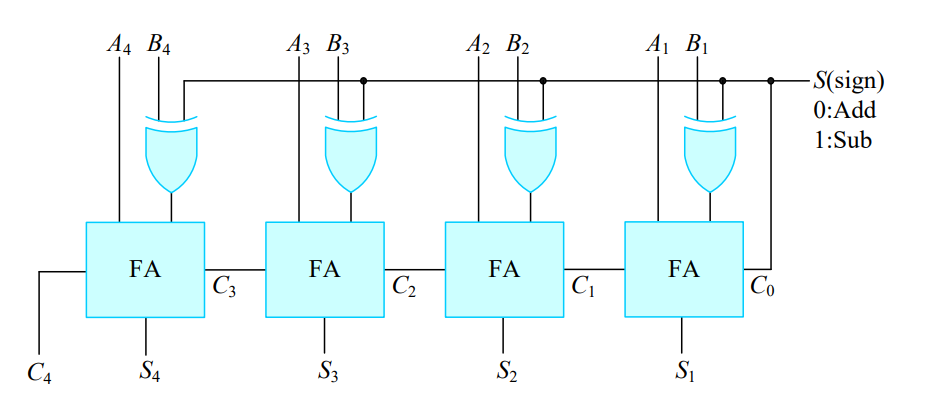 뺄셈은 빼려는 수를 2의보수를 취한뒤 더해준다.
뺄셈은 빼려는 수를 2의보수를 취한뒤 더해준다.
2의 보수는 모든 비트를 반전시킨뒤 마지막에 1을 더해준다
병렬 가감산기는 모든 전가산기 한 쪽 입력에 XOR를 붙이고 XOR한 쪽 입력을 Sign비트와 연결한다. Sign비트가 0이면 가산기로, Sign비트가 1이면 감산기로 사용 할 수 있다. 이렇게 되면 XOR를 통해 빼려는 수의 비트를 반전시켜서 입력할 수 있고 Sign비트를 통해 마지막에 더해주는 1도 만들 수 있다.
4비트 가감산기-구조적
module fadd_sub_4bits_s(
input [3:0] a, b, //4비트 입력
input s, //sign비트
output [3:0] sum, //4비트 출력
output carry); //캐리비트
wire [2:0] carry_w; //전가산기들을 연결하기 위한 와이어
wire [3:0] b_w; //xor와 전가산기를 연결하기 위한 와이어
xor(b_w[0], b[0], s); //(출력, 입력, 입력)순서로 연결
xor(b_w[1], b[1], s);
xor(b_w[2], b[2], s);
xor(b_w[3], b[3], s);
//full_adder_structural를 인스턴스로 가져와 구조적으로 연결
full_adder_structural fa0(.a(a[0]), .b(b_w[0]), .c(s), .sum(sum[0]), .carry(carry_w[0]));
full_adder_structural fa1(.a(a[1]), .b(b_w[1]), .c(carry_w[0]), .sum(sum[1]), .carry(carry_w[1]));
full_adder_structural fa2(.a(a[2]), .b(b_w[2]), .c(carry_w[1]), .sum(sum[2]), .carry(carry_w[2]));
full_adder_structural fa3(.a(a[3]), .b(b_w[3]), .c(carry_w[2]), .sum(sum[3]), .carry(carry));
endmodule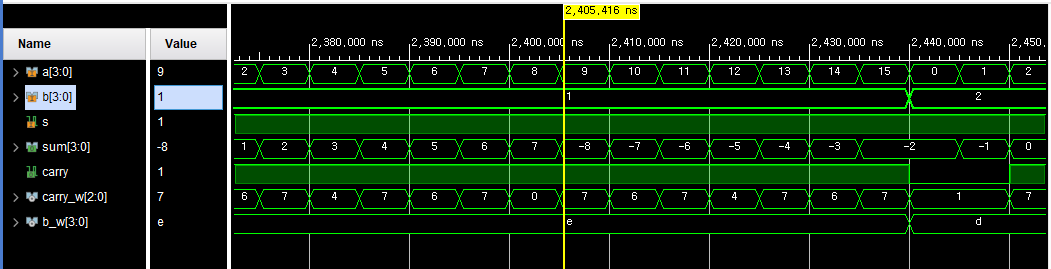
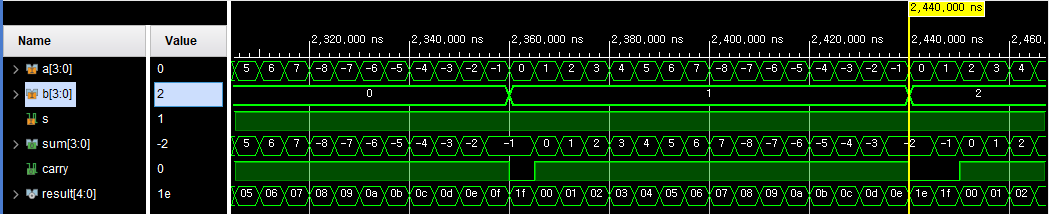
4비트 가감산기 dataflow
module fadd_sub_4bits(
input [3:0] a, b,
input s,
output [3:0] sum,
output carry);
wire [4:0] result;
assign result = s ? a - b : a + b; //조건 연산자 s가 0이면 가산기로써 a+b, s가 1이면 감산기로써 a-b
assign sum = result[3:0];
assign carry = s ? ~result[4] : result[4]; // 결과가 음수이면 캐리 발생안함, 결과가0또는 양수이면 캐리 발생, 이때의 캐리는 음수인지 아닌지와 크기 비료를 할때 사용
// 32비트 체계에서는 4비트 이상은 0으로 채워져있고 감산기로 써서 반전시키면 1로 채워짐 위의 의미와 반대의 상황이기 때문에
// 5번째 비트를 ~를 통해 반전시킨다
endmodule기본32비트 체계에서 계산, a>b인 경우와 a<b인 경우를 비교를 했을때 a<b인 경우 다른점이 생긴다, a<b인 경우에 (-)연산을 위해 2의 보수와 캐리 발생으로 4비트체계 에서와 32비트체계에서 5번째 비트 이상에서 같은 계산이라도 비트값이 달라지는데 이것을 맞춰주기 위해 not연산을 해준다
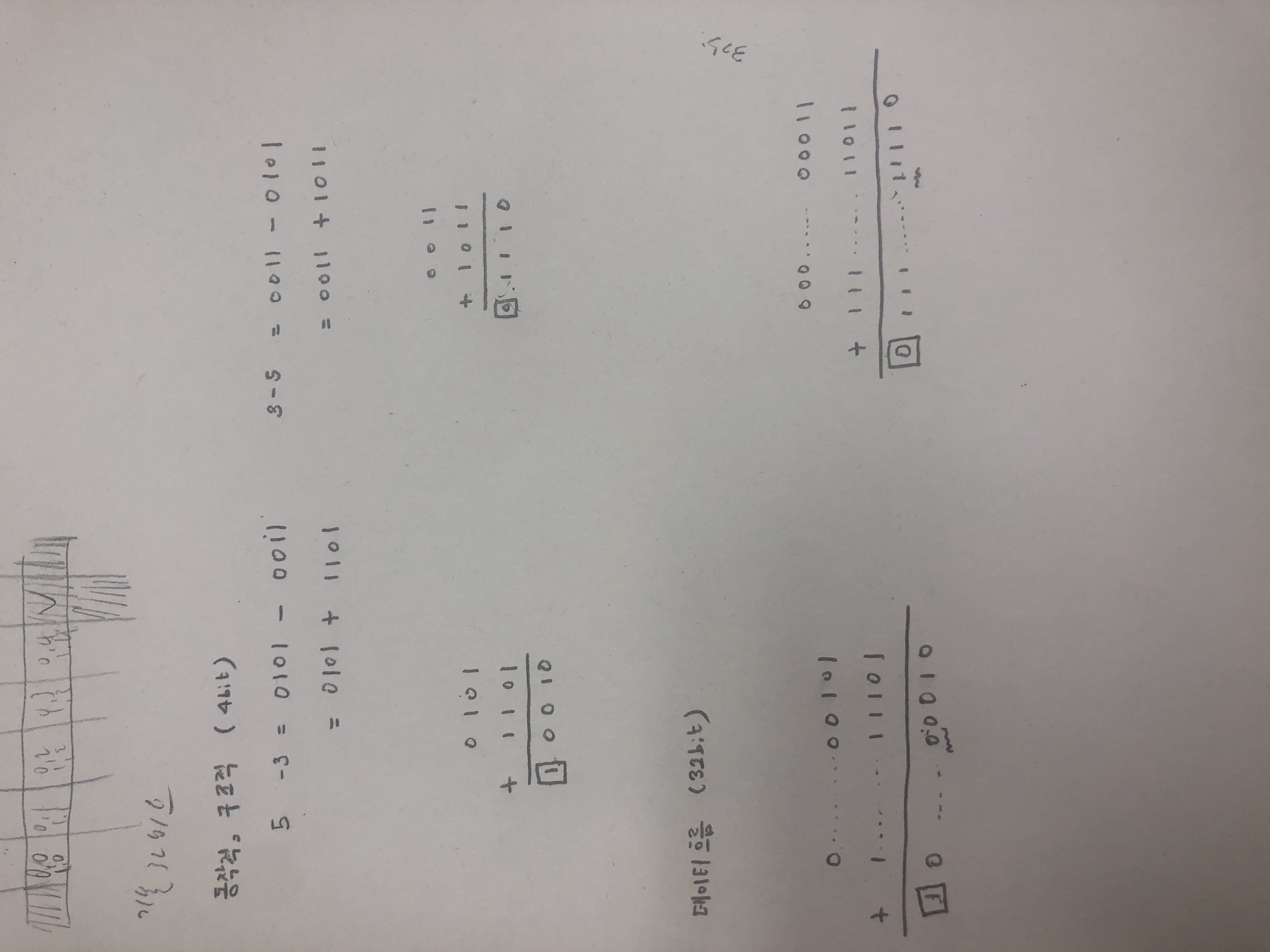
초초고속 가산
아랫단에서 윗단으로 전달되는 캐리 때문에 병렬 가산기는 속도가 느리다
(pdt : 전파지연시간) 고려
비교기
가산기처럼 여러개 이어붙여서 만들수없음 구조적모델링 사용x
2진 비교기->XNOR,XOR,AND,NOT 사용
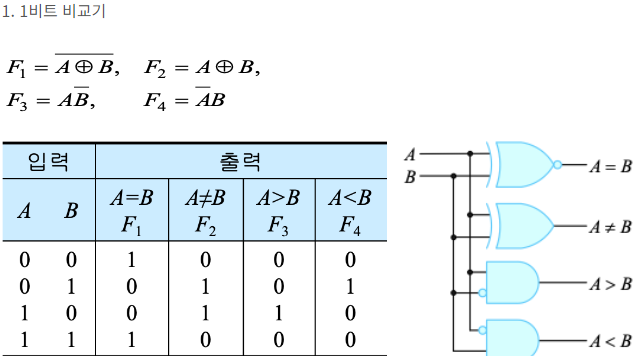
#(parameter N = )
dataflow
module comparator #(parameter N = 8)( //32비트 크기중 8비트 사용
input [N-1:0] a, b,
output equal, greater, less);
assign equal = (a == b) ? 1'b1: 1'b0;
assign greater = (a > b) ? 1'b1: 1'b0;
assign less = (a < b) ? 1'b1: 1'b0;
endmodule 기본 32비트 비교기 제공
구조적
module comparator_n_bits_test(
input [1:0] a, b,
output equal, greater, less);
comparator #(.N(2)) comp_2bit( //comparator를 8비트 짜리 비교기로 해놨지만 2비트짜리로 바꿈
//.a(a), .b(b), .equal(equal), .greater(greater), .less(less)); //.a는 comparator의 것 (a)는comparator_n_bits_test의 것
a, b, equal, greater, less); //comparator_n_bits_test의 변수들, 변수명들을 다써주면 순서상관없지만, .변수를 안쓰면 순서 지켜야함
// 순서는 caomparator의 변수 선언 순서
endmodule동작적
module comparator_N_bits_b #(parameter N = 8)(
input [N-1:0] a, b,
output reg equal, greater, less);
always @(a, b)begin //베릴로그는 병력적으로 실행이지만 always문은 순차적으로 진행
equal = 0;
greater = 0;
less = 0;
if (a == b) equal = 1; //if문은 always문안에서만 사용 가능
else if(a > b)greater = 1;
else if(a < b)less = 1;
end
endmodule위에있는 comparator_n_bits_test모듈에서 comparator인스턴스를 comparator_N_bits_b인스턴스로 바꿔서 comparator_n_bits_test모듈로 실행
module comparator_n_bits_test(
input [1:0] a, b,
output equal, greater, less);
comparator_N_bits_b #(.N(2)) comp_2bit( //comparator를 8비트 짜리 비교기로 해놨지만 2비트짜리로 바꿈
//.a(a), .b(b), .equal(equal), .greater(greater), .less(less)); //.a는 comparator의 것 (a)는comparator_n_bits_test의 것
a, b, equal, greater, less); //comparator_n_bits_test의 변수들, 변수명들을 다써주면 순서상관없지만, .변수를 안쓰면 순서 지켜야함
// 순서는 caomparator의 변수 선언 순서
endmodule