클라우드 환경의 EC2 활용 방식
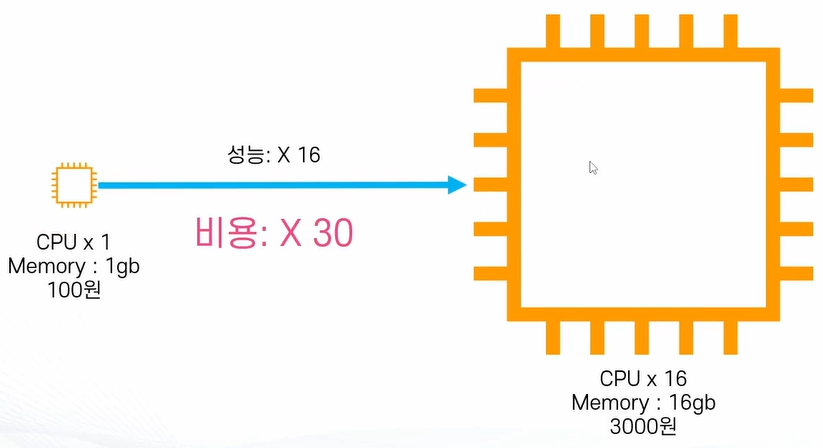
수직 확장(Vertical Scale / Scale Up)
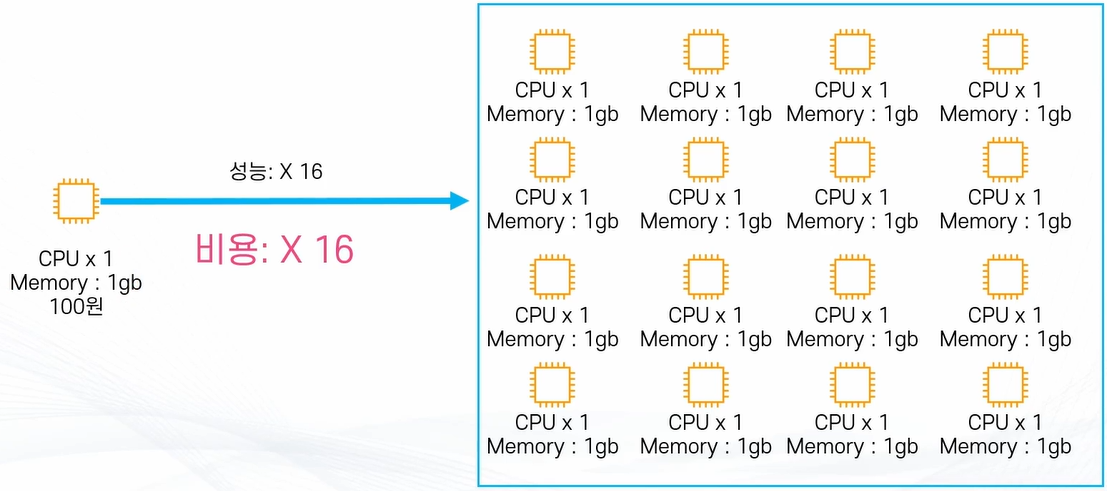
수평 확장(Horizontal Scale / Scale Out)
클라우드 환경에서 컴퓨팅 자원 활용
- 온프레미스 환경에선 각 서버를 반영구적으로 사용
- 반면 클라우드 환경에서는 각 인스턴스는 소모품
- 예고없이 장애가 발생하거나 통제된 방법으로 종료되는 것이 정상. 즉, "언제나 인스턴스는 예고없이 종료된다"라고 가정하고 아키텍처 설계 필요
- 필요하면 더 가져다 쓰고 필요 없으면 버릴 수 있어야 함
- Stateless 하며 고가용성의 확보 필요
고가용성과 Stateless
- 고가용성: 인스턴스 중 하나가 떨어져도 자동으로 복구 가능
- Stateless: 인스턴스가 상태에 의존적이지 않음
- 어떤 인스턴스도 특정 정보를 특별하게 저장하지 않음
- 언제나 추가될 수 있고 언제나 삭제되어도 무방
* EC2를 잘 활용하려면?
- 인스턴스를 자동으로 프로비전할 수 있는 방법 필요
- 인스턴스를 가용영역 별로 분산할 수 있는 방법 필요
- 인스턴스 클러스터에 트래픽을 분산할 수 있는 방법 필요
- 인스턴스 각자가 상태를 저장하지 않고 언제나 삭제되고 추가되도 무방할 수 있는 방법 필요
EC2 Auto Scaling

AWS Auto Scaling은 애플리케이션을 모니터링하고 용량을 자동으로 조정하여, 최대한 저렴한 비용으로 안정적이고 예측 가능한 성능을 유지합니다. AWS Auto Scaling을 사용하면 몇 분 만에 손쉽게 여러 서비스 전체에서 여러 리소스에 대해 애플리케이션 규모 조정을 설정할 수 있습니다.
EC2 Auto Scaling의 목적
- 정확한 수의 EC2 인스턴스를 보유하도록 보장
- 그룹의 최소 인스턴스 숫자 및 최대 인스턴스 숫자
- 최소 숫자 이하로 내려가지 않도록 인스턴스 숫자 유지(인스턴스 추가)
- 최대 숫자 이상 늘어나지 않도록 인스턴스 숫자 유지(인스턴스 삭제)
- 그룹의 최소 인스턴스 숫자 및 최대 인스턴스 숫자
- 다양한 스케일링 정책 적용
- 다양한 스케일링 정책
- 예: CPU의 부하에 따라 인스턴스 크기를 늘리기
- 예: 특정 시간에 인스턴스 개수를 늘리고 다른 시간에 줄이기
- 가용영역에 인스턴스가 골고루 분산 될 수 있도록 인스턴스를 분배
- 다양한 스케일링 정책
EC2 Auto Scaling의 구성
시작 구성(Launch configurations) / 시작 템플릿(Launch template)
- EC2의 유형, 크기
- AMI, 보안 그룹, Key, IAM 역할
- 유저 데이터(EC2 실행 시 실행할 자동 스크립트)
- 기타 설정
모니터링: 언제 실행시킬 것인가? + 상태 확인
- 예: CPU 점유율이 일정 %을 넘어섰을 때 추가로 실행
- 예: 2개 이상이 필요한 스택에서 EC2 하나가 죽었을 때
- CloudWatch (and/or) ELB와 연계
설정: 얼마나 어떻게 실행시킬 것인가?
- 최대 / 최소 / 원하는 인스턴스 숫자
- ELB와 연동
기타 설정 사항
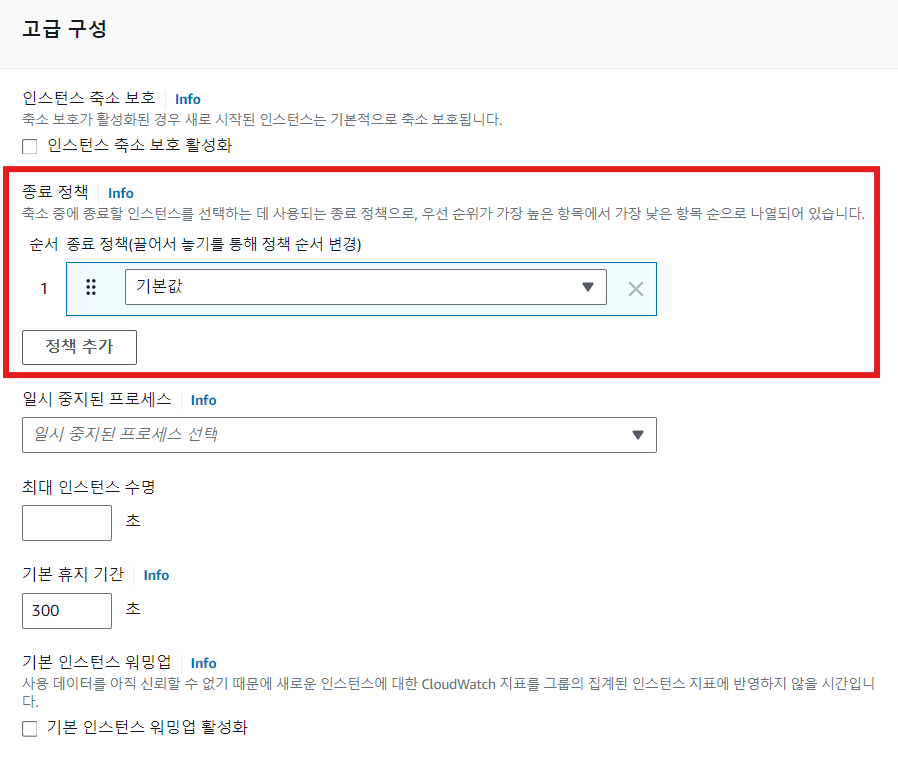
- 종료 정책: 인스턴스 숫자를 줄일 경우(Scale-in) 어떤 순서로 인스턴스를 종료시킬지에 관한 정책
- 기본: 인스턴스가 2개 이상인 가용영역의 인스턴스에서 가장 오래된 시작 템플릿을 종료하고, 모두 같은 시작 템플릿이라면 다음 과금 시간에 가장 가까운 인스턴스를 종료
- 커스텀: 가장 예전 시작 템플릿 부터, 가장 오래된 인스턴스부터, 가장 최근 인스턴스부터 등으로 커스텀 가능
- Lambda를 활용해서 커스텀 정책 적용 가능
AutoScale Scaling 정책
- AutoScale에서 관리하고 있는 인스턴스의 숫자를 조절하는 방식
- 크게 네 가지로 분류
- 수동 스케일: 수동으로 직접 인스턴스 숫자를 증감
- 스케쥴 기반 스케일: 특정 시점에 인스턴스 숫자를 증감
- 주로 예측 가능한 시점의 부하 처리를 목적으로 활용
- 동적 스케일: 특정 기준을 두고 기준치에 따라 인스턴스 숫자를 증감
- 예: CPU 사용률 기반, 요청 숫자 기반, 판매량 기반 등
- 예측 기반 스케일: 과거의 기록의 패턴을 기반으로 수요량을 예측해서 인스턴턴스 숫자를 증감
수동 스케일
- 말 그대로 수동으로 인스턴스 숫자를 조절하는 방법
- 주로 개발 환경 혹은 다른 정책을 적용하기 전 사전 테스트 용도로 활용
- 되도록이면 다른 스케일 정책을 비활성화 시킨 후 적용 추천
스케쥴 기반 스케일
- 예측 가능한 시점의 변동사항에 대비해서 인스턴스 숫자를 조절하는 방식
- 예: 매주 수요일마다 주간 이벤트가 있는 게임의 경우
- 예: 매일 새벽 특정 시간에 하루동안 모인 데이터를 분석
- 적용 방식
- 범위 지정(Min, Max, Desired 셋 중 최소 한 가지)
- 지정한 범위보다 인스턴스가 작다면 Scale Out
- 지정한 범위보다 인스턴스가 크다면 Scale In
- 범위 지정(Min, Max, Desired 셋 중 최소 한 가지)
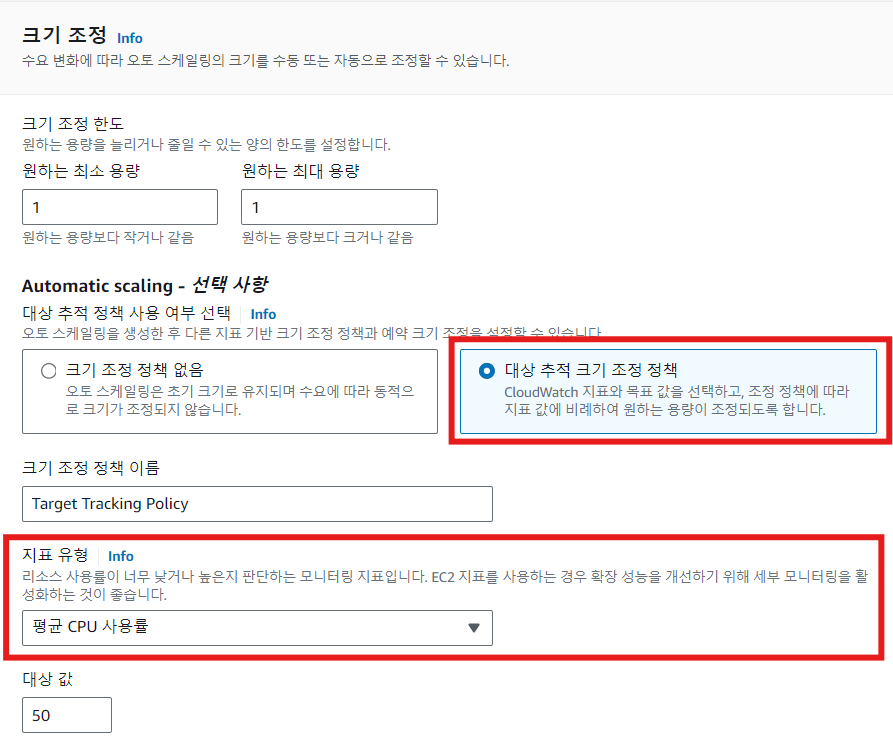
동적 스케일
- 지표에 반응해서 인스턴스 숫자를 조절하는 방식
- 주로 CloudWatch의 지표 활용
- 혹은 자신만의 기준으로 스케일링 정책 조절 가능
- 주로 AutoScale에서 지원하는 추적 조정 정책(target Tracking Policy) 활용
- 내부적으로 CloudWatch 경보(Alarm)를 생성해서 경보에 반응하여 자동으로 증감
- 지표 증감에 따라 얼마나 민감하게 반응할 것인지 결정 가능
- 필요 시 커스텀 로직을 활용해서 AutoScale의 증감을 수동으로 조절 가능
※ 경보: CloudWatch 지표에 반응하여 트리거되는 이벤트
※ Scale Out은 3분 정도지만, Scale In은 15분 이상 소요
예측 기반 스케일
- 사용 패턴의 히스토리를 기반으로 인스턴스 수요량을 예측하여 인스턴스 숫자를 조절하는 방식
- 주로 반복되는 패턴이 명확한 경우, 혹은 인스턴스 준비가 오래 걸리는 경우 사용
- 예: 매일 오후 2시에 레이드 이벤트가 열리는 게임 서비스의 서버
- CloudWatch 지표를 14일간 분석하여 패턴을 만들고 다음 48시간의 사용 패턴을 분석
- 수요량에 따라 증가만 가능. 즉, 인스턴스 숫자를 감소시키려면 동적 시케일링 정책 필요
- 주의사항
- AutoScale Group에 다양한 인스턴스 종류가 섞여있을 경우 효율성이 매우 떨어짐
- 다양한 스케일링 정책이 공존할 경우 효율성이 떨어짐
- AutoScale Group에 충분한 데이터가 쌓일 때 까지(2주) 기다림 필요
* AutoScale Scaling 정책 적용
AutoScale 기타 기능
Health Check
- 인스턴스의 상태를 체크하는 기능
- 상태 확인 소스
- EC2: 인스턴스가 실행 중인지, 하드웨어 상태가 정상적인지 확인
- ELB: 트래픽을 발생시켜서 해당 트래픽을 잘 수행하는지 확인
- VPC Lattice
- 커스텀: 직접 커스텀 로직으로 상태를 확인
- 상태 확인에 실패했을 때 Unhealthy 상태로 변경 -> AutoScale에서 직접 해당 인스턴스를 교체
인스턴스 Warm Up
- 인스턴스에 대한 CloudWatch의 모니터링 지표가 수집 되기 전 준비 기간
- 트래픽을 받기 전에 지표 등이 반영되지 않도록 설정 가능
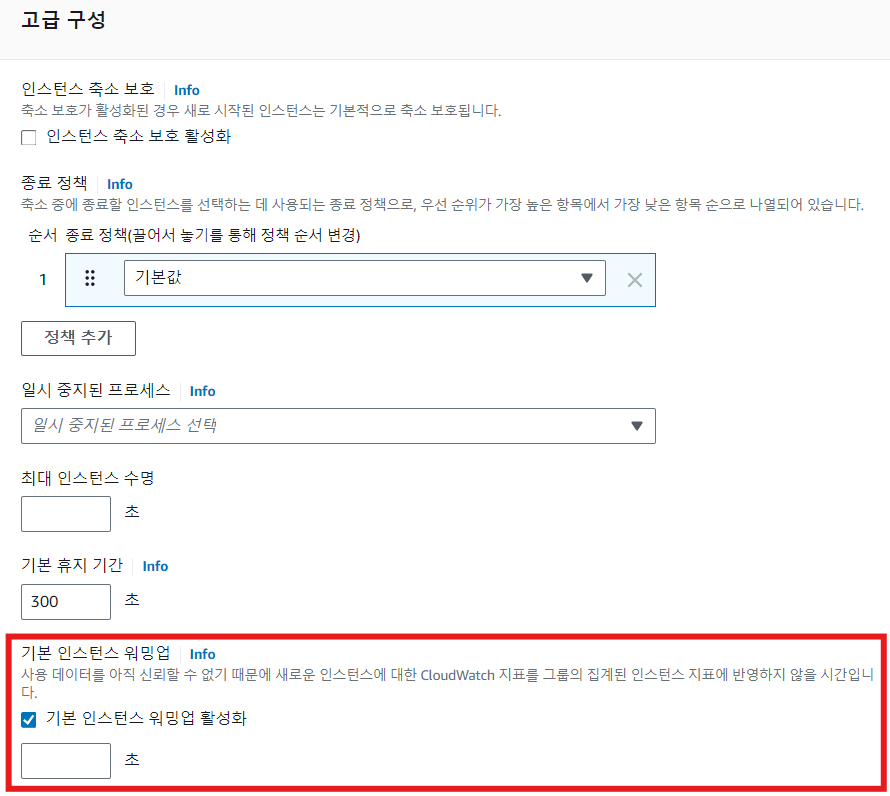
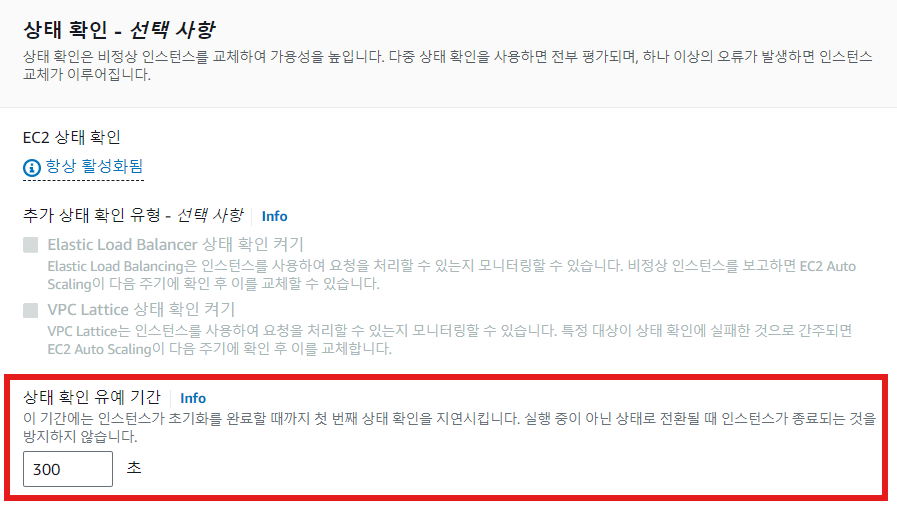
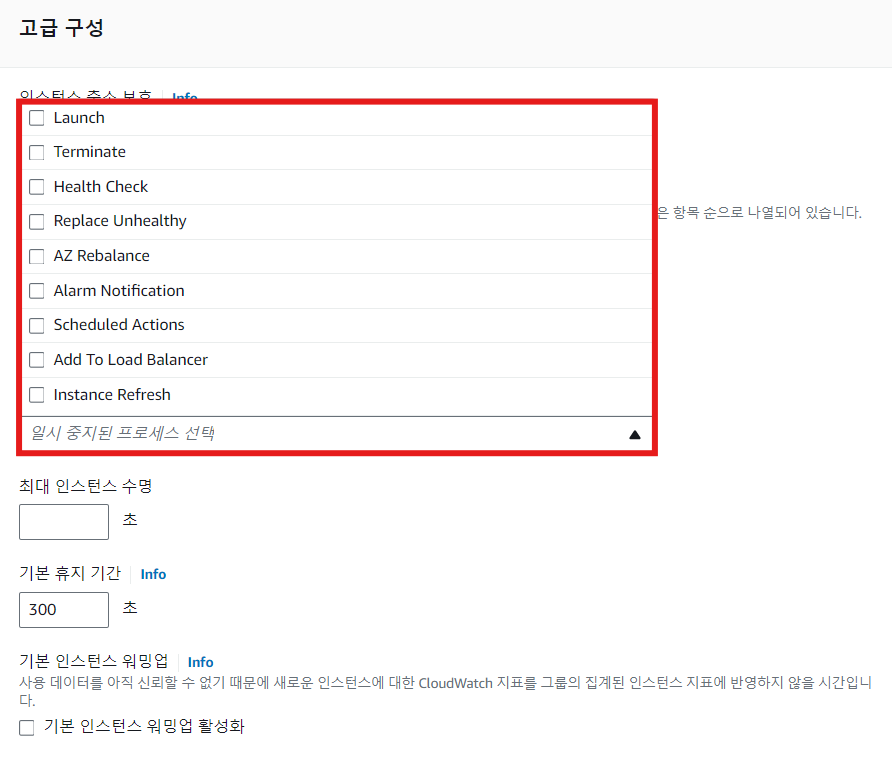
Health Check Grace Period
- 신규로 추가된 인스턴스가 Health Check을 수행하기 전 준비를 위한 기간
- 기본 300초(콘솔 기준, CLI/SDK는 0초)
- 인스턴스가 신규로 올라간 이후 준비가 오래 필요할 경우 등에 활용
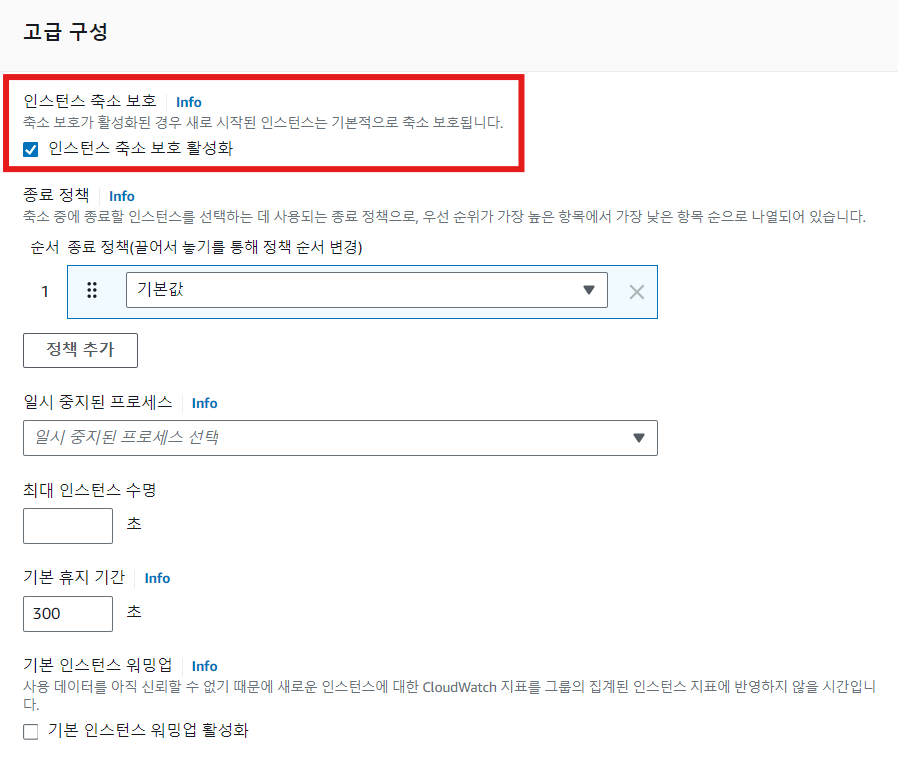
Instance Scale-In Protection
- AutoScale 혹은 인스턴스 단위로 인스턴스의 종료를 막는 기능
- 디버그 목적 혹은 특정 로직을 끝까지 수행할 수 있도록 보장하기 위해서 사용
- 예: SQS에서 받아온 데이터를 처리하는 특정 로직이 끝까지 수행될 수 있도록 보장하기 위해 해당 로직이 완료 전까지 Protection을 활성화
- Protection이 있어도 종료되는 경우
- Health Check Fail
- Spot 인스턴스
- 수동으로 삭제(콘솔, CLI/SDK)
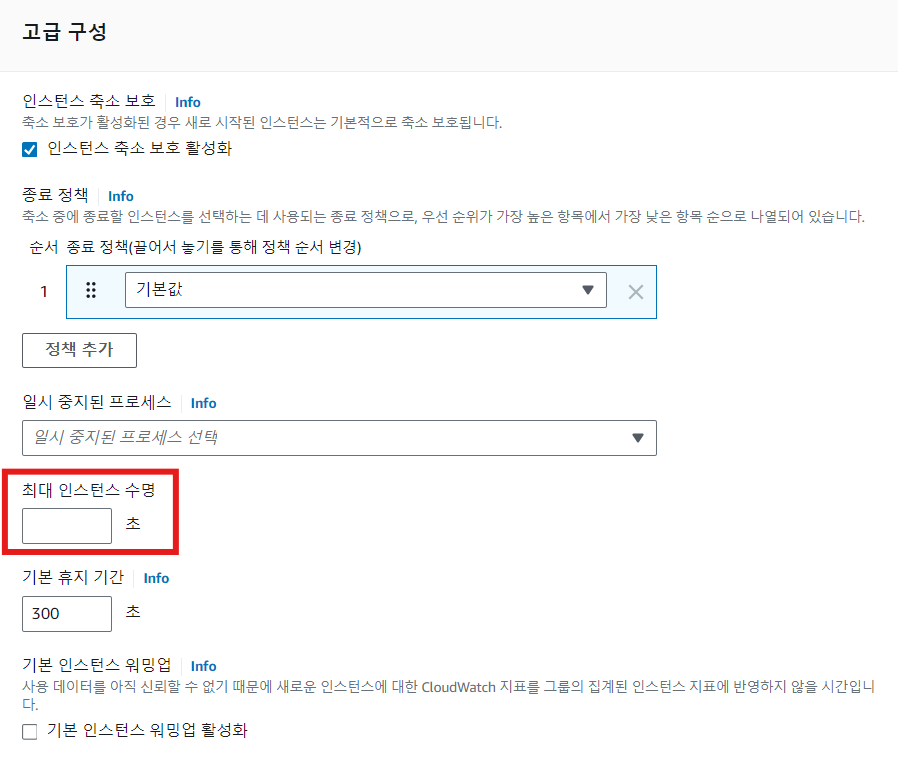
인스턴스 Lifetime 관리
- 인스턴스가 최대로 실행되어 있는 기간(초 단위)을 설정 가능
- 해당 기간 이후 자동으로 교체(Replace)
- 최소 86,400초(1일)
- 설정을 취소하려면 새로운 값을 0으로 입력 -> 모든 인스턴스에 적용
- Scale In Protection이 걸려있을 경우, 해당 기능 우선. 즉, 인스턴스가 종료되지 않을 수 있음
- 기본 교체 방법은 인스턴스가 종료된 후 신규 인스턴스 생성
인스턴스 유지 관리 정책
인스턴스의 숫자가 변동할 때 어떤 우선순위로 어떻게 변동할지를 정하는 정책
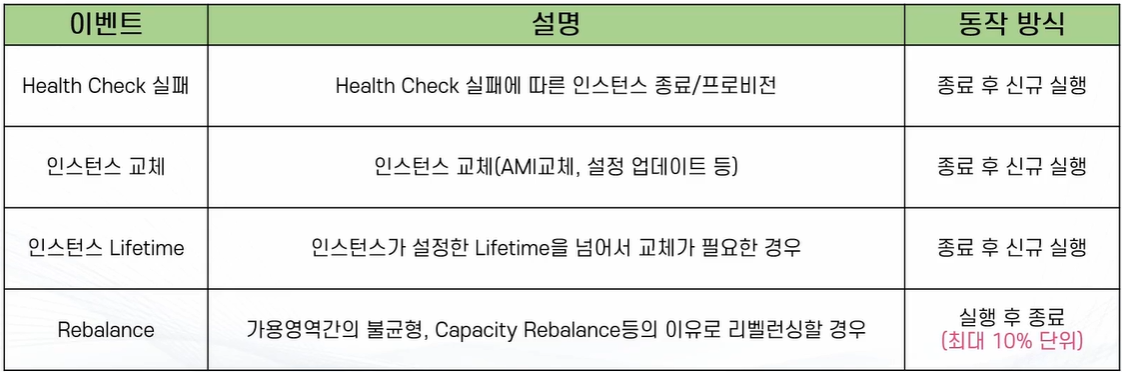
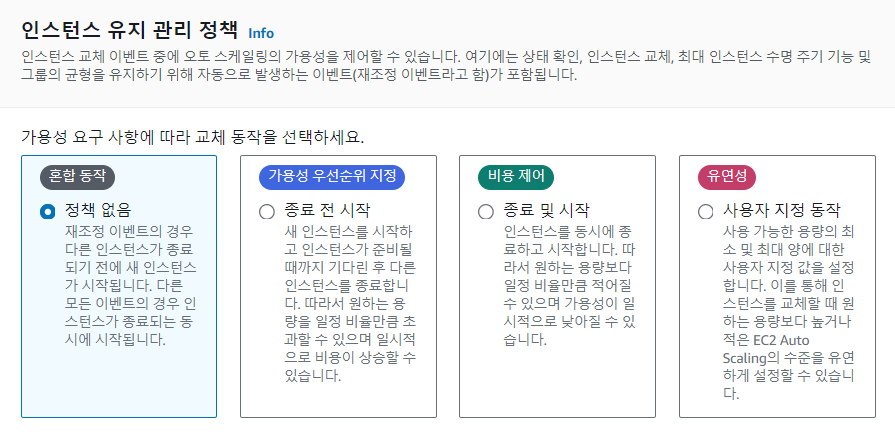
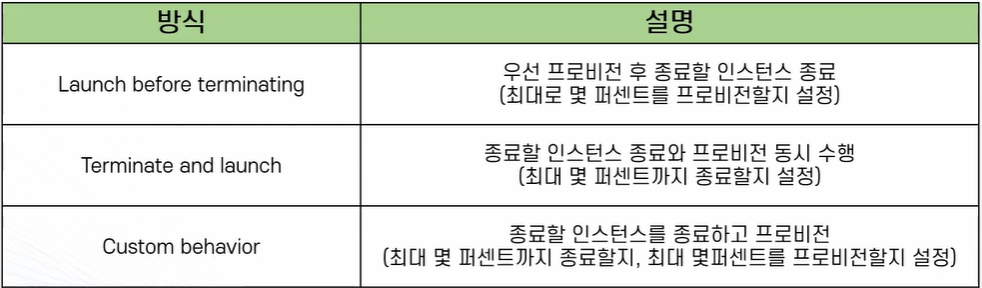
* 인스턴스 유지 관리 커스텀 정책
AutoScale 기능 임시 비활성화
- 임시로 AutoScale의 다양한 기능을 비활성화/활성화 가능
- 주로 디버그/상황 대응의 목적으로 활용
- 주요 비활성화 가능한 기능
- Launch: 인스턴스의 Scale Out이 필요할 때 신규 인스턴스 시작을 비활성화
- Terminate: 인스턴스의 Scale In이 필요할 때(Health Check Fail 포함) 인스턴스 중지를 비활성화
- AddToLoadBalancer: ELB에 인스턴스 등록을 중지
- AZRebalance: 가용영역간에 골고루 인스턴스가 분배되도록 인스턴스 조절(신규 프로비전/종료 포함) 기능을 중지
- HealthCheck: 인스턴스의 상태 체크(ELB 포함)을 비활성화
- ReplaceUnhealthy: HealthCheck에 실패한 인스턴스의 교체 비활성화
AutoScale 관리 임시 해제
- 임시로 AutoScale으로 관리중인 인스턴스를 StandBy 상태로 전환 가능
- StandBy: ELB의 트래픽을 받지 않고 HealthCheck도 임시로 비활성화 된 상태
- 업데이트, 디버그 등등 목적으로 활용 가능
- 예: 인스턴스를 StandBy로 두고 관련 소프트웨어 업데이트 후 복귀
- StandBy 설정 시 desired capacity 조절 가능
- desired capacity를 하나 낮추면 AutoScale 그룹에서 인스턴스 숫자 유지
- desired capacity 변경 없이 진행한다면 AutoScale 그룹에서 인스턴스를 추가
- AZRebalance가 비활성화 되어 있지 않다면, StandBy가 풀리면서 인스턴스 조정 가능
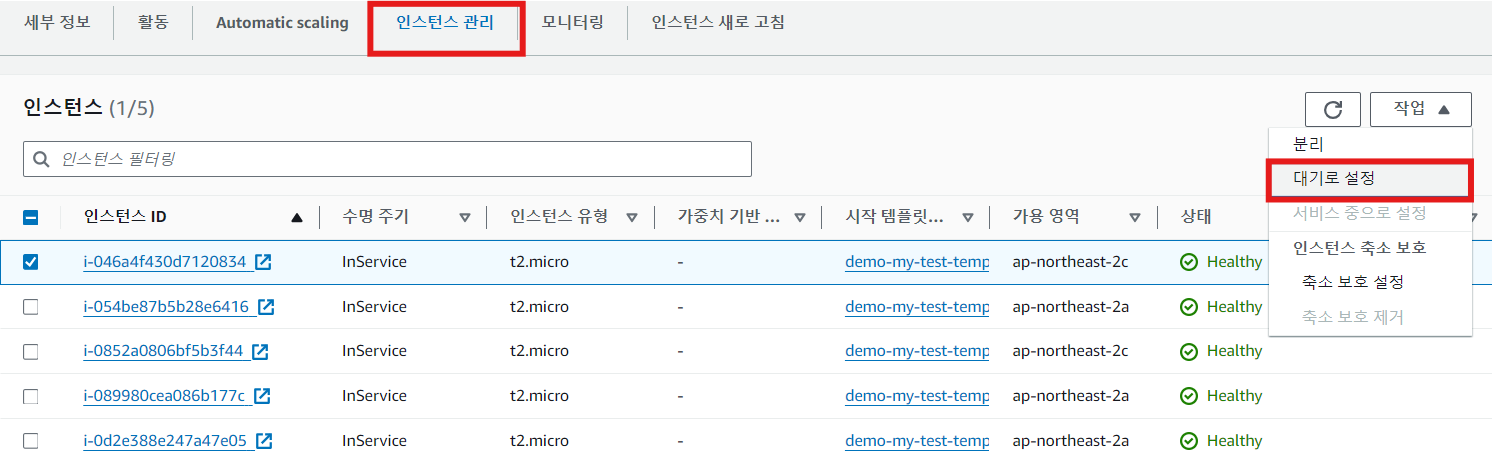
※ 주의
StandBy 상태에서 다시 서비스 상태로 전환 시 의도와 달리 StandByt 했던 인스턴스가 사라질 수 있음
-> 종료 정책으로 조절
AutoScale Lifecycle Hooks
- AutoScaling의 각 단계(Pending, Terminating)에서 특정 로직을 수행할 수 있는 기능
- 주로 미리 수행되어야 하는 작업, CI/CD 파이프라인을 통한 배포 등을 수행
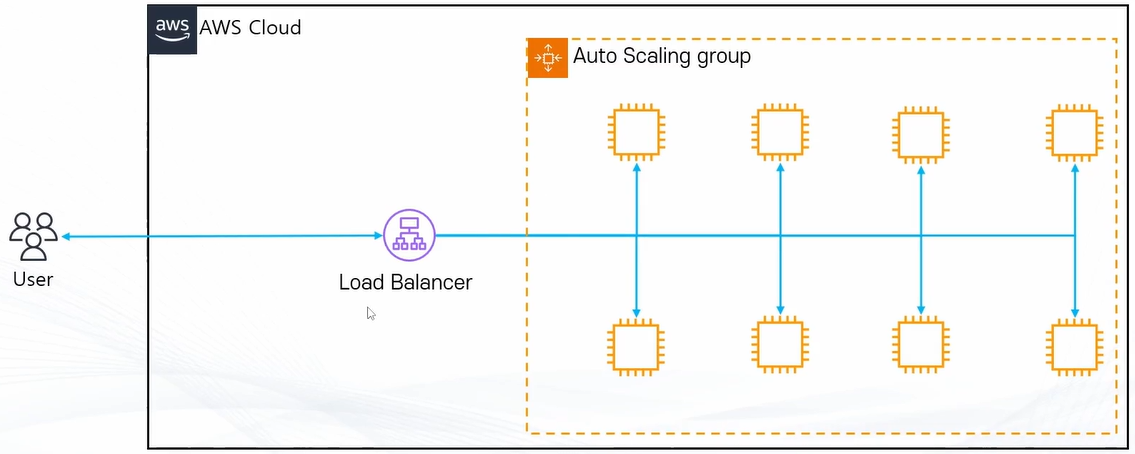
Elastic Load Balancer

Elastic Load Balancing은 둘 이상의 가용 영역에서 EC2 인스턴스, 컨테이너, IP 주소 등 여러 대상에 걸쳐 수신되는 트래픽을 자동으로 분산합니다. 등록된 대상의 상태를 모니터링하면서 상태가 양호한 대상으로만 트래픽을 라우팅합니다.
ELB란?
- 다수의 EC2에 트래픽을 분산 시켜주는 서비스
- 총 4가지 종류
- Application Load Balancer
- Network Load Balancer
- Classic Load Balancer
- Gateway Laod Balancer
- Health Check: 직접 트래픽을 발생시켜 인스턴스가 살아있는지 체크
- Auto Scaling과 연동 가능
- 지속적으로 IP 주소가 바뀌며 IP 고정 불가능: 항상 도메인 기반으로 사용
ELB의 종류
Application Load Balancer
- 똑똑한 녀석
- OSI Model Layer 7
- 트래픽을 모니터링 하여 라우팅 가능
Network Load Balancer
- 빠른 녀석
- I Model Layer 4
- TCP, UDP 기반 빠른 트래픽 분산
- Elastic IP 할당 가능(IP 고정 가능)
Classic Load Balancer
- 옛날 녀석
- 예전에 사용되던 타입으로 현재는 잘 사용하지 않음
Gateway Load Balancer
- 먼저 트래픽을 체크하는 녀석
- OSI Layer 3
- 가상 어플라이언스 배포/확장 관리를 위한 서비스
ELB + Auto Scaling
- Auto Scaling을 통해 EC2 인스턴스 숫자를 관리하고 ELB를 통해 분산 트래픽 처리
- Auto Scaling의 인스턴스 증감과 같이 ELB에 연결
대상 그룹(Target Group)
- ELB가 라우팅 할 대상의 집합
- 구성
- 대상 종류
- Instance
- IP
- Lambda
- ALB
- 프로토콜(HTTP, HTTPS, gRPC, TCP 등)
- 기타 설정
- 트래픽 분산 알고리즘, 고정 세션 등
- 대상 종류
리스너
- ALB로 들어오는 요청을 처리하는 주체
- 들어오는 트래픽의 프로토콜 + 포트 단위
- 규칙(Rule)으로 ALB에서 어떤 요청을 받을지, 요청을 어떻게 어디로 처리할 지 결정
- 예: http:8080 포트로 트래픽을 받아서 A 대상그룹의 80번 포트로 배분
- 예: https 프로토콜(443) 포트로 트래픽을 받아 B 대상그룹의 80번 포트로 배분
- 예: http post 요청이 들어왔을 경우 지정된 응답 전달(에러페이지 등)
- 규칙을 활용해 다양한 조건에 따라 트래픽 배분 가능
- 활용 가능한 조건: Header, QueryString, source IP, Method 등
- 들어온 트래픽 처리 방식: forward, redirect, fixed-response, cognito 인증 등
실습 - ELB + Auto Scaling 구축하기
- 시작 템플릿 생성: 템플릿 이름, AMI, 인스턴스 유형, 키 페어, 네트워크 유형 등 설정
- Auto Scaling 그룹 생성
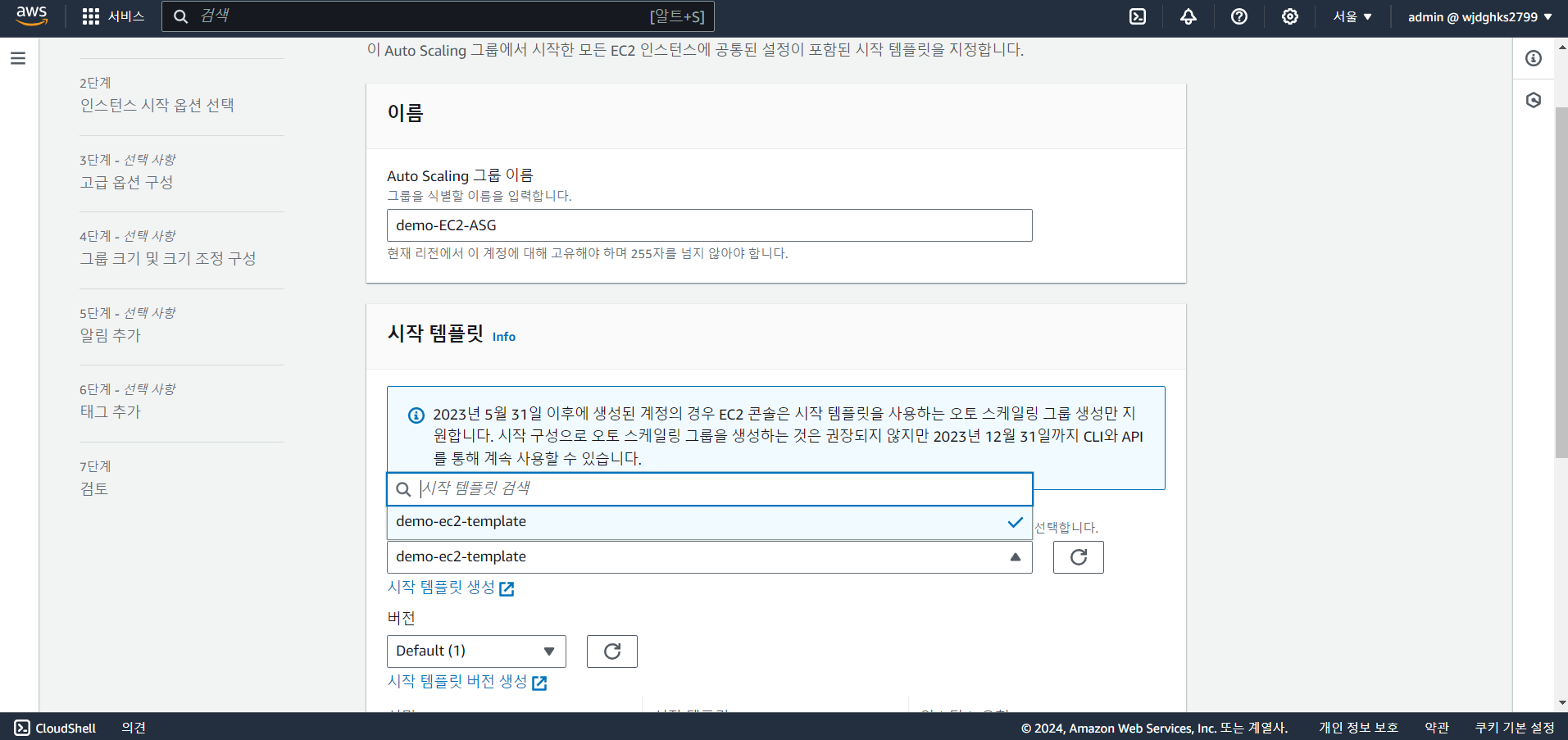
a. 이름 및 시작 템플릿, 가용영역 선택
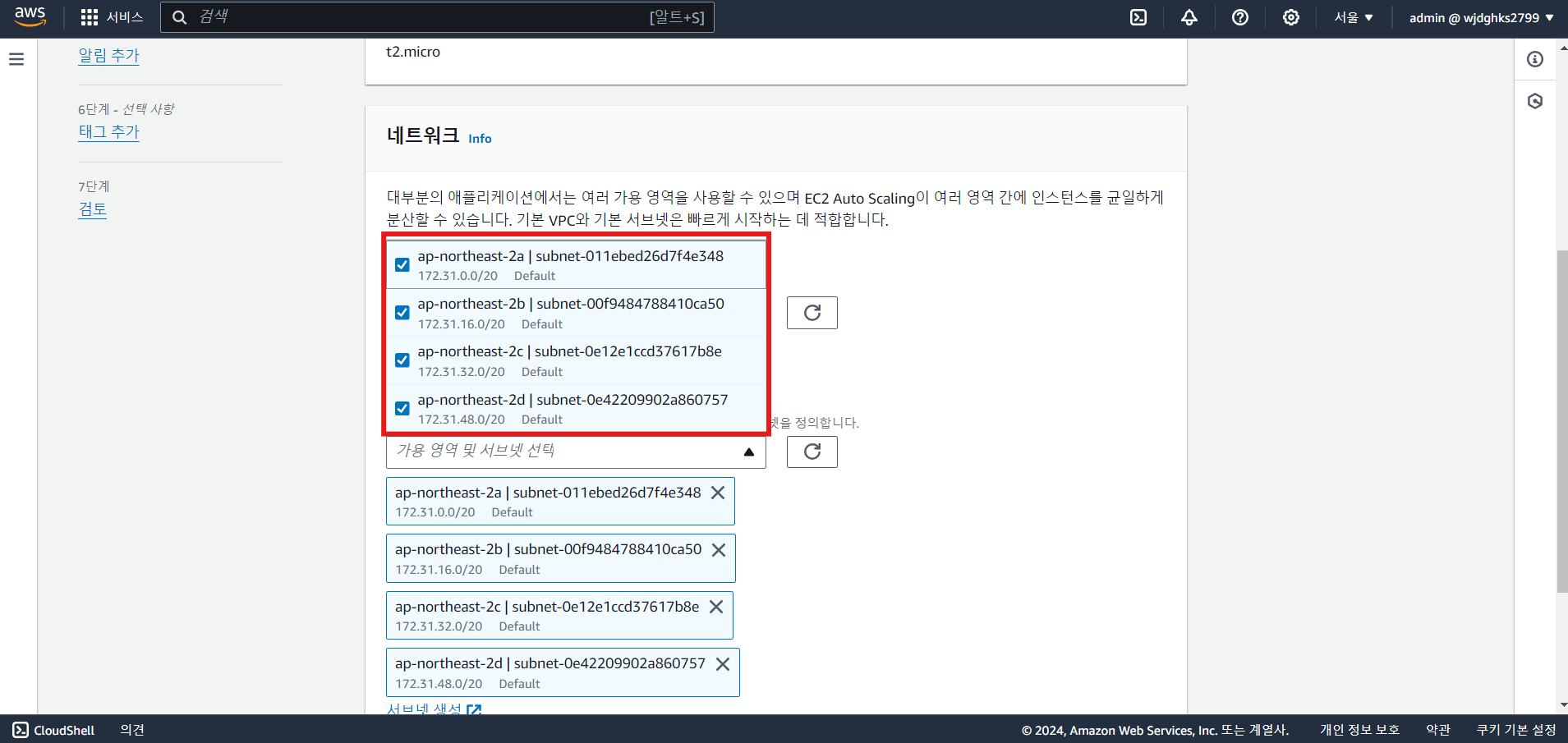
b. 그룹 크기 및 크기 조정
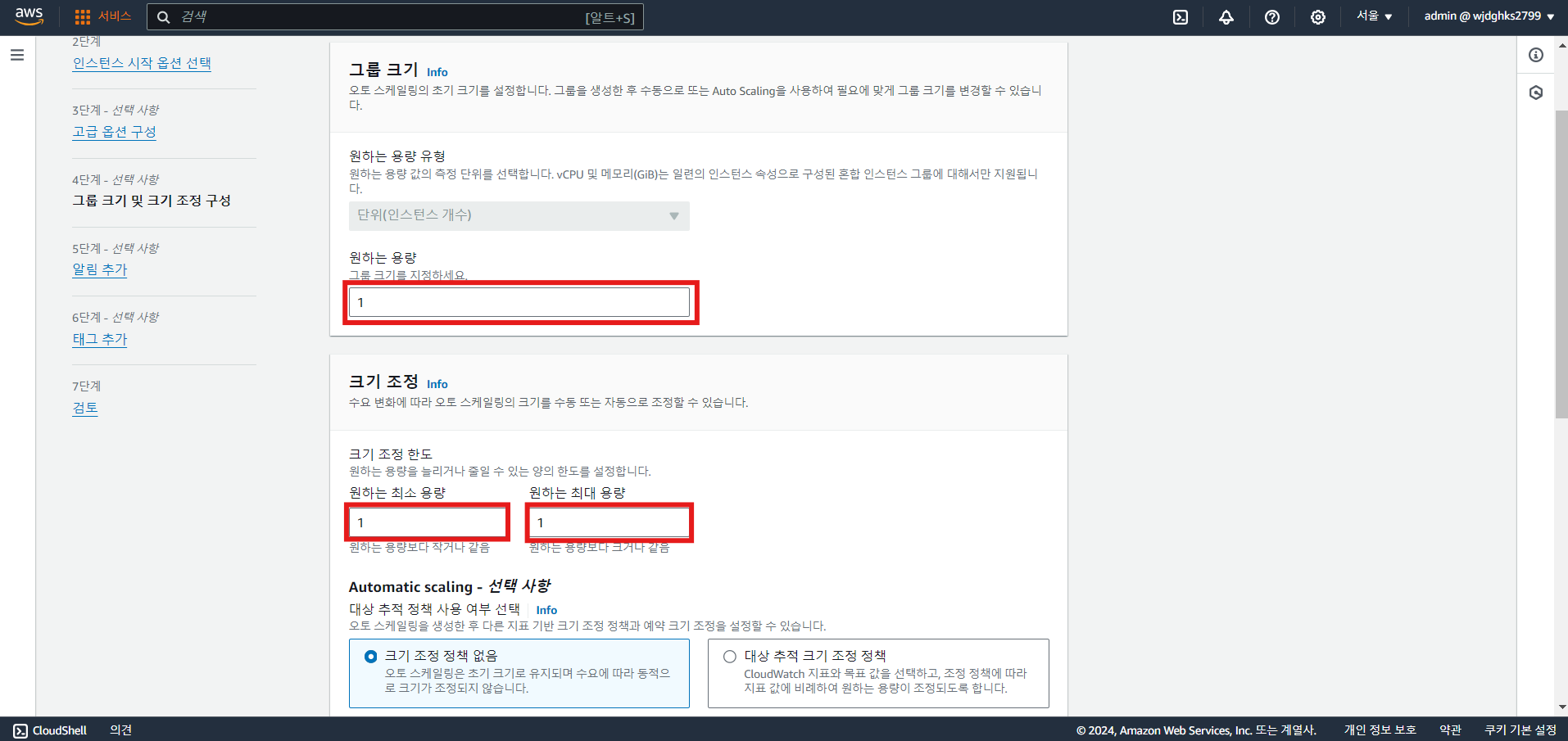
※ 크기 조정 정책 선택 시 지표에 따른 Auto Scaling
- 대상 그룹 생성
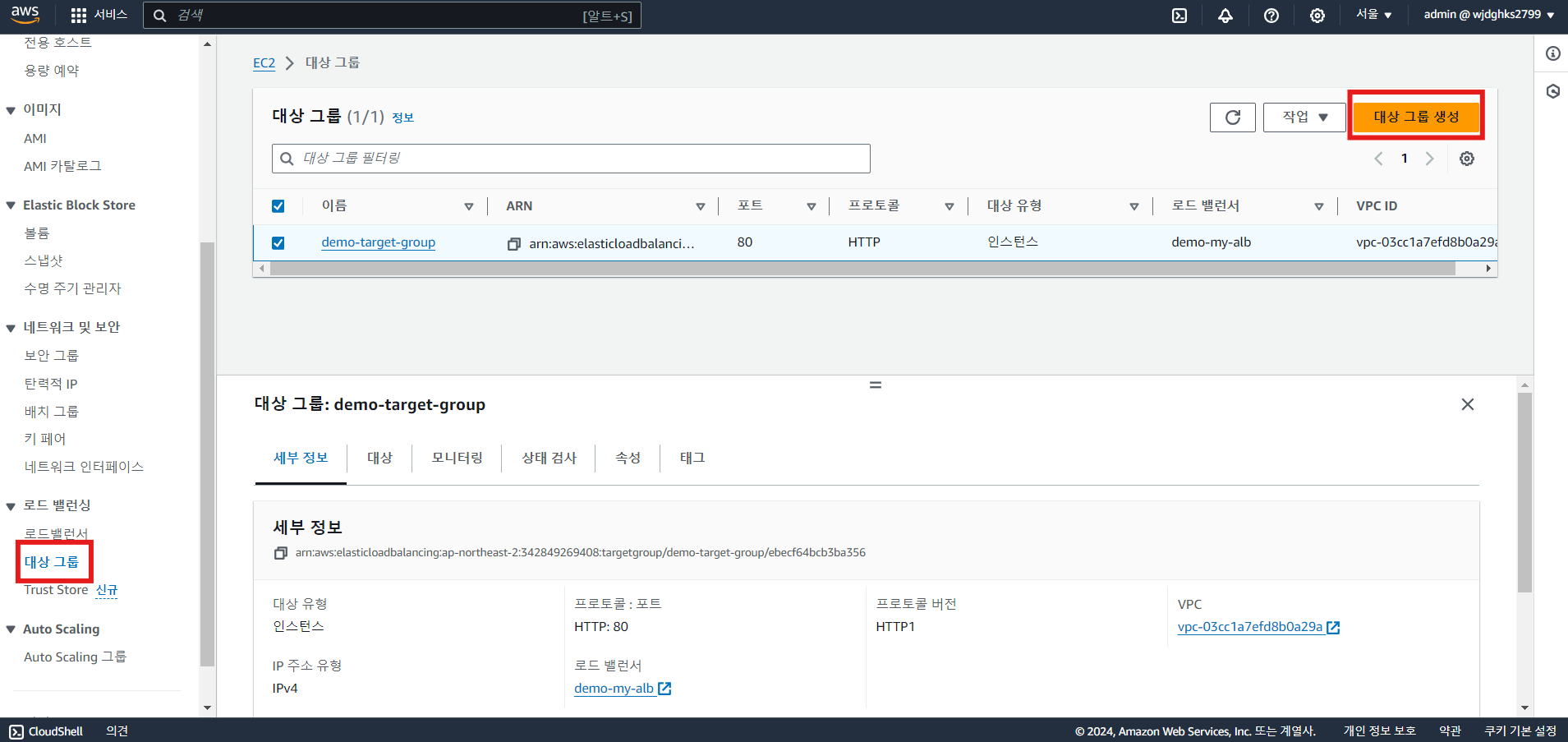
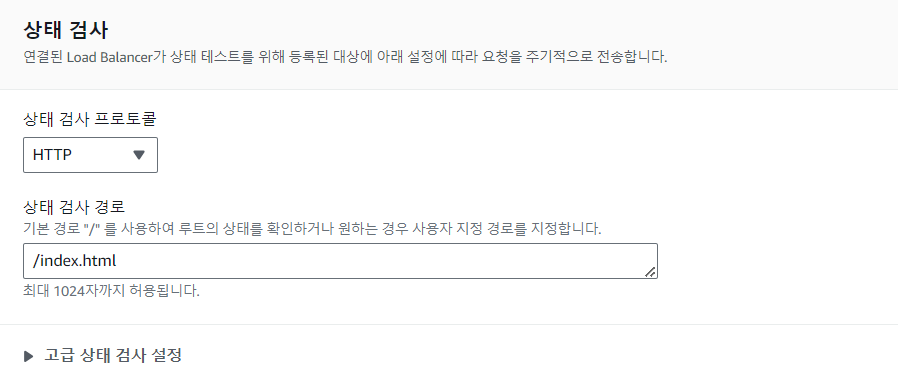
※ 상태 검사 경로 지정: 인스턴스가 켜지기만 한 상태를 검사할 때와 다르게 경로가 정상적으로 불러와지는지까지 검사
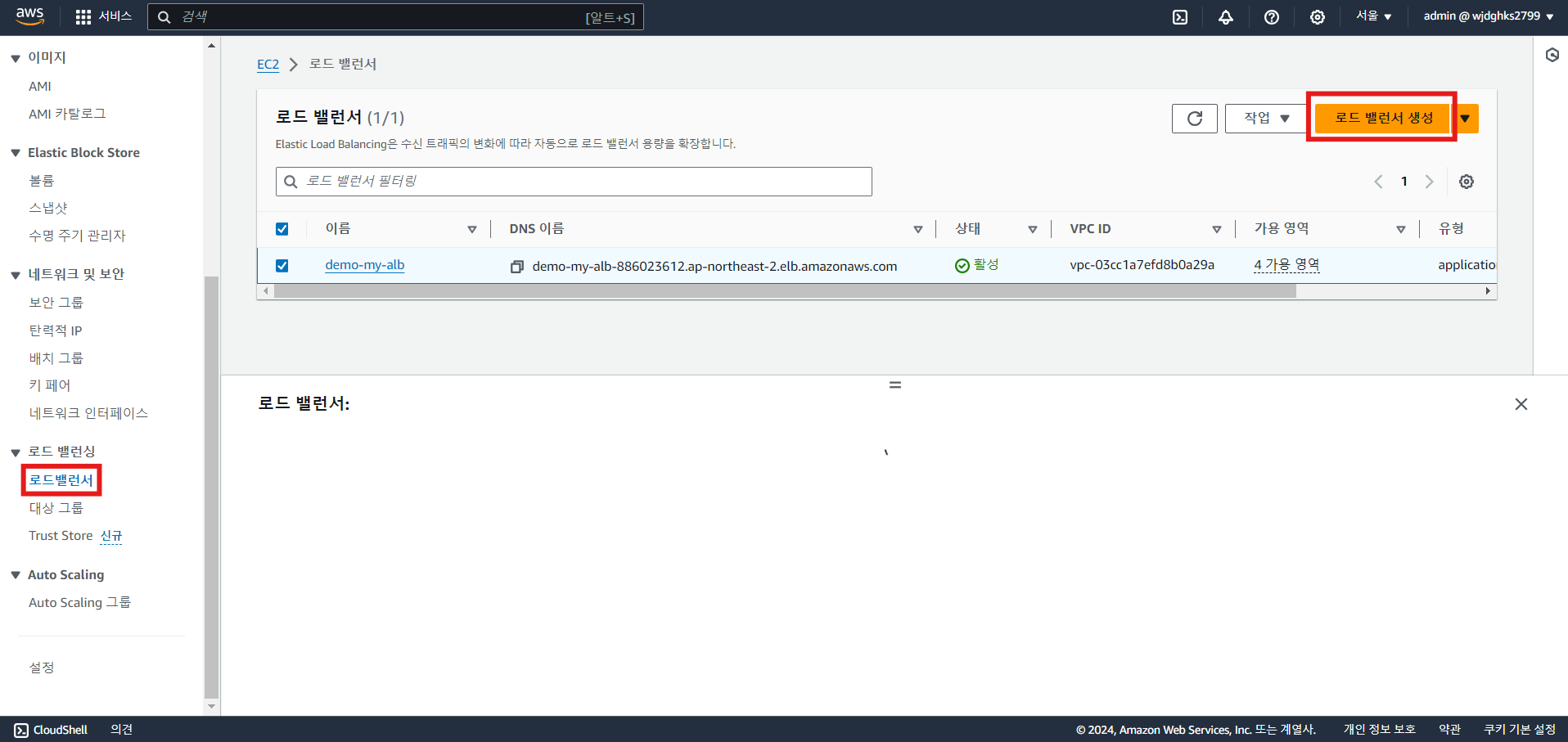
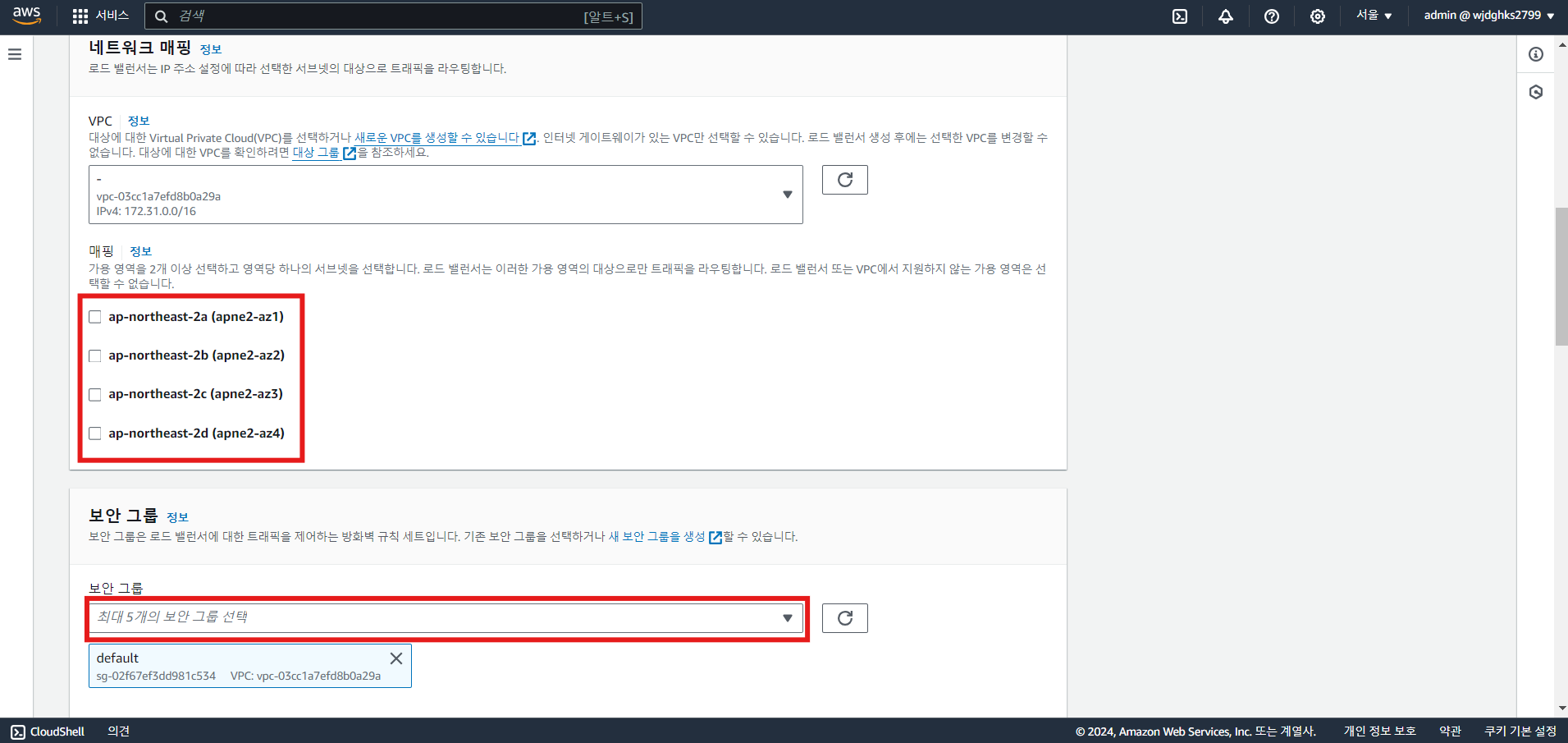
- 로드 밸런서 생성: 로드 밸런서 유형 선택 및 로드 밸런서 구성, 가용영역, 보안 그룹 등 설정
- ASG에 ELB 연결
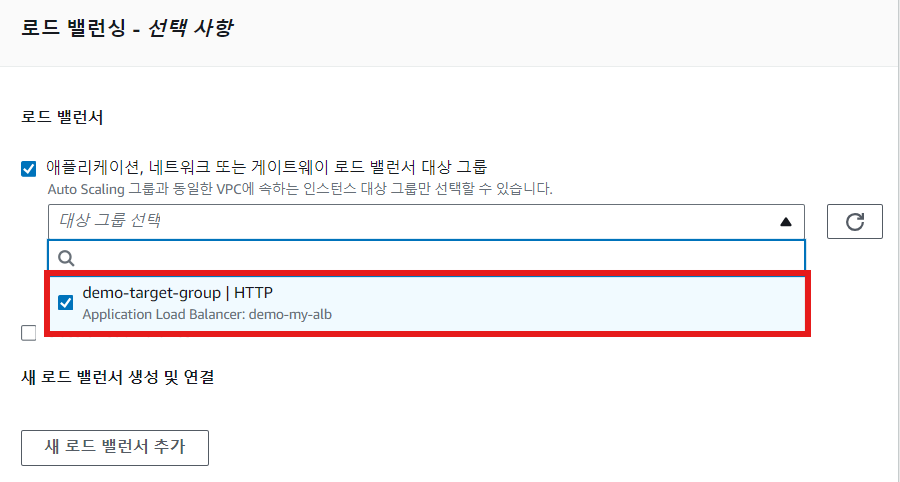
※ ELB가 아닌 대상 그룹을 선택해서 연결함
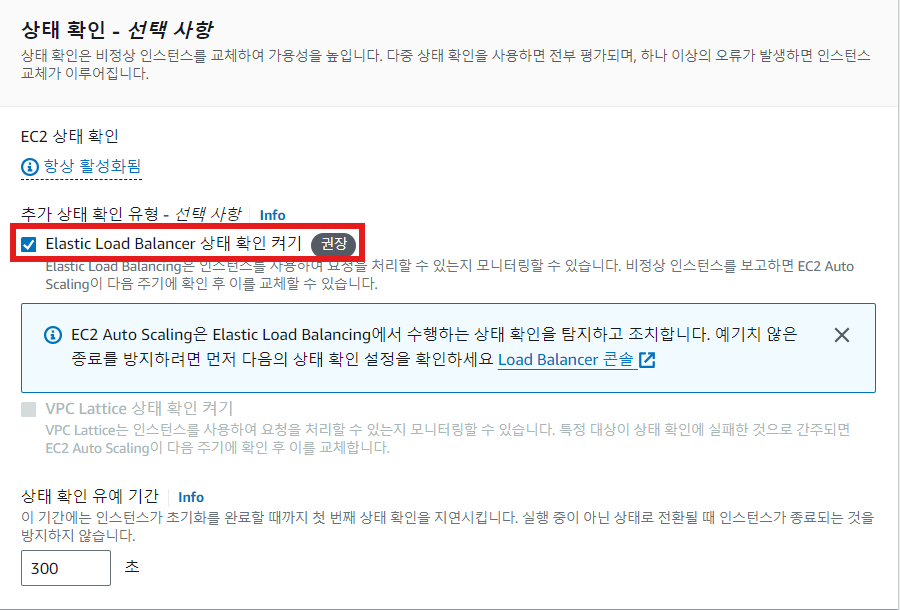
- Elastic Load Balancer 상태 확인 켜기
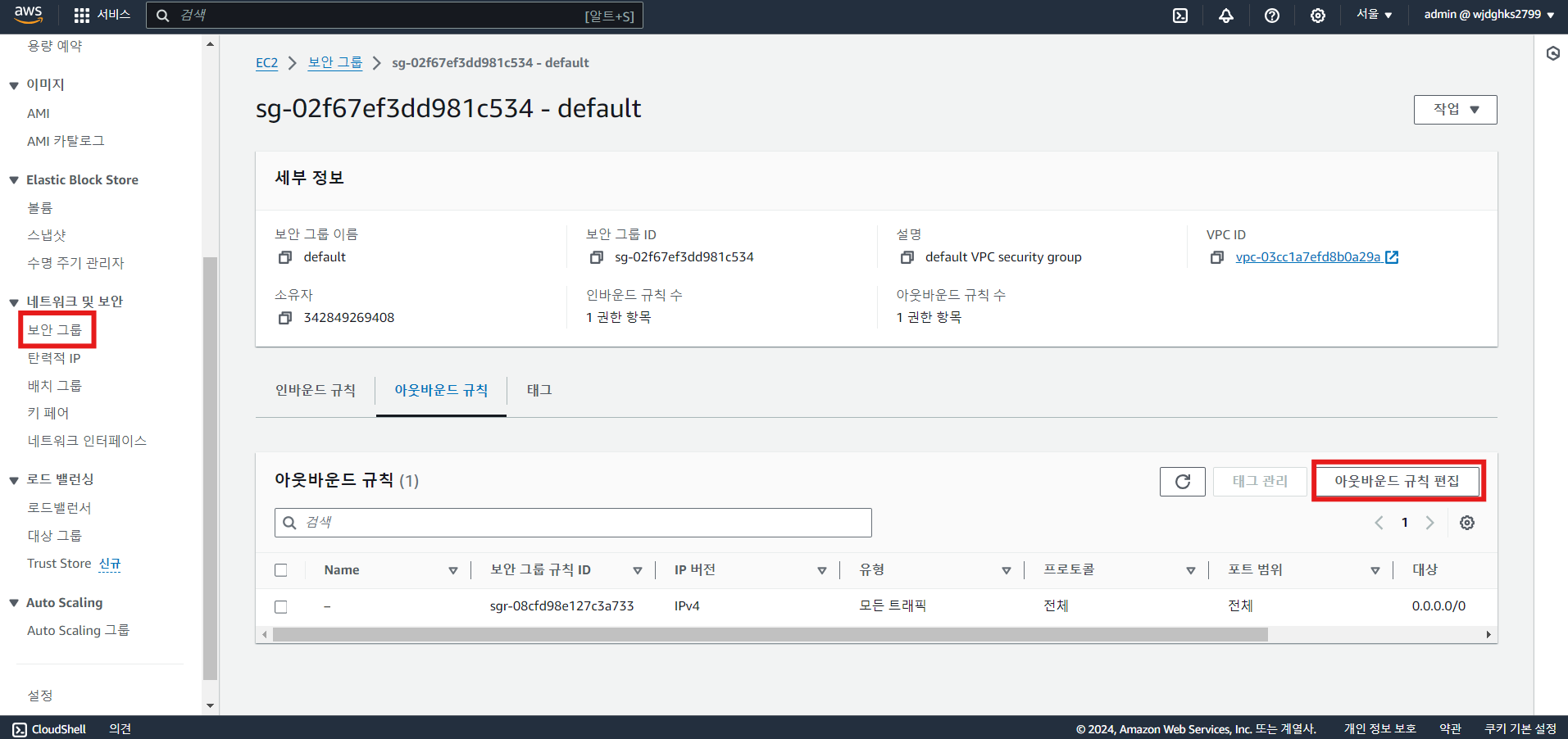
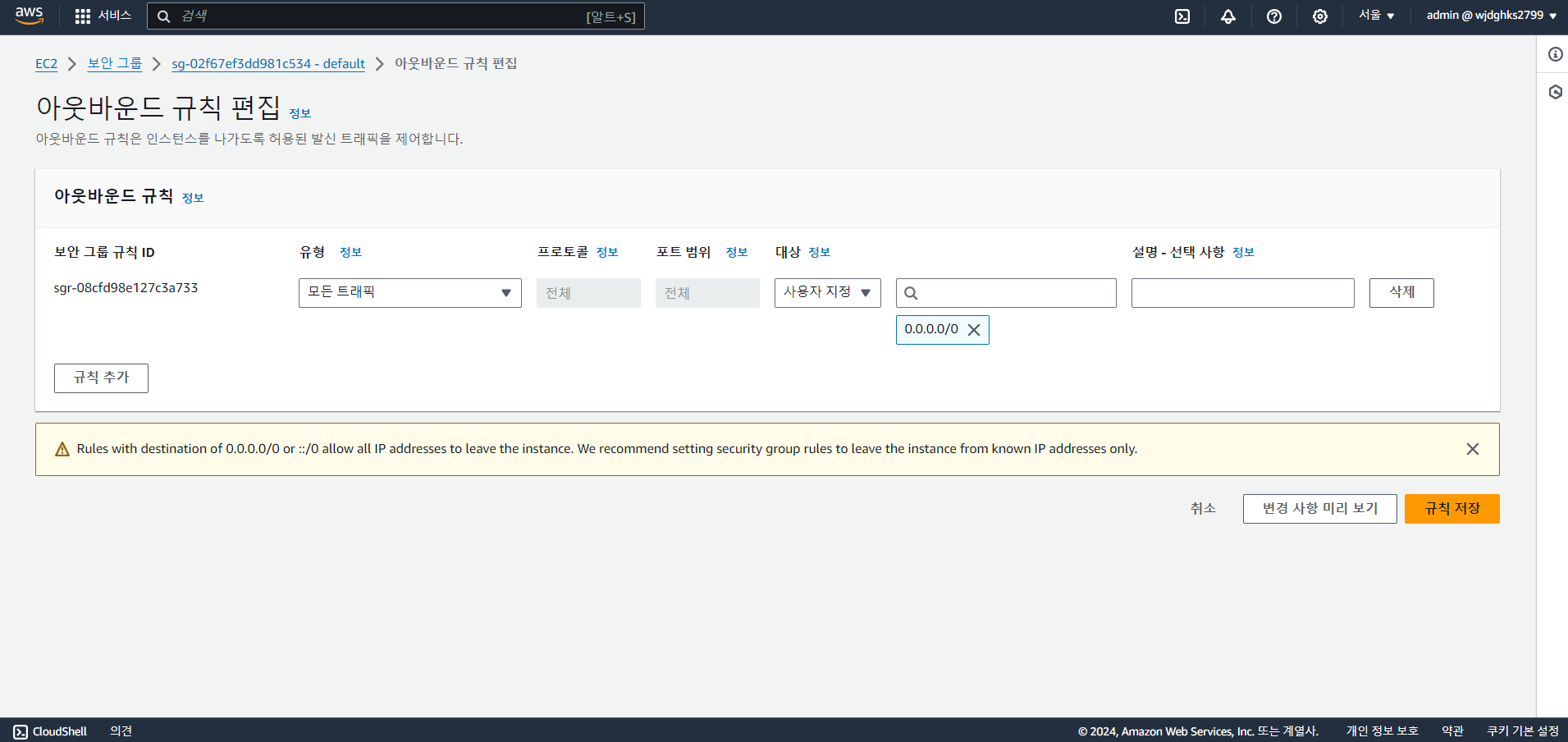
- 웹을 통해 로드 밸런서 DNS 경로로 접속하기 위해 보안 그룹의 인바운드 규칙 설정
EC2 모니터링 기초

Amazon CloudWatch는 DevOps 엔지니어, 개발자, SRE(사이트 안정성 엔지니어) 및 IT 관리자를 위해 구축된 모니터링 및 관찰 기능 서비스입니다. CloudWatch는 애플리케이션을 모니터링하고, 시스템 전반의 성능 변경 사항에 대응하며, 리소스 사용률을 최적화하고, 운영 상태에 대한 통합된 보기를 확보하는 데 필요한 데이터와 실행 가능한 통찰력을 제공합니다.
Amazon CloudWatch와 EC2
- AWS에서 제공하는 AWS 서비스 / 어플리케이션의 모니터링 서비스
- EC2를 포함한 AWS의 다양한 서비스에 기본적인 모니터링을 지원
- EC2의 주요 지표(시간 순서로 정리된 데이터의 집합)
- CPU 사용량
- 디스크(Read, Write)
- 네트워크(In, Out, Packet 등)
- CPU Credit 관련 지표
- 상태 관련(Failed 등)
- 이외에 커스텀 지표(메모리 사용량 등) 활용 가능
- EC2의 경우 별도로 활성화 불필요 / 무료
- 기본 5분 단위(상태 확인만 1분 단위)
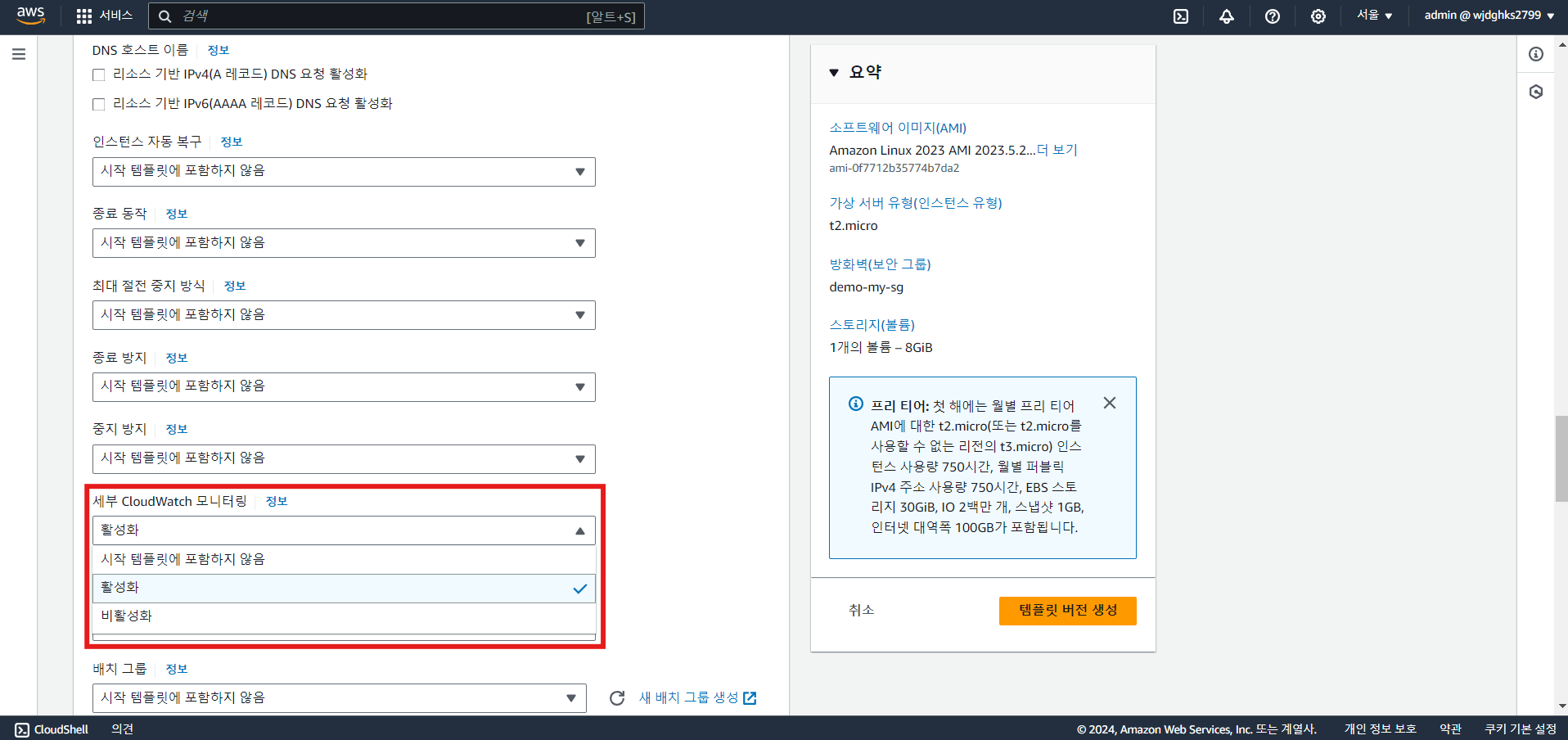
- EC2 세부 모니터링
- 모든 지표에 1분 단위 모니터링
- 메트릭 별로 비용 발생. 단, 저장 비용은 없음
- 별도로 활성화 필요
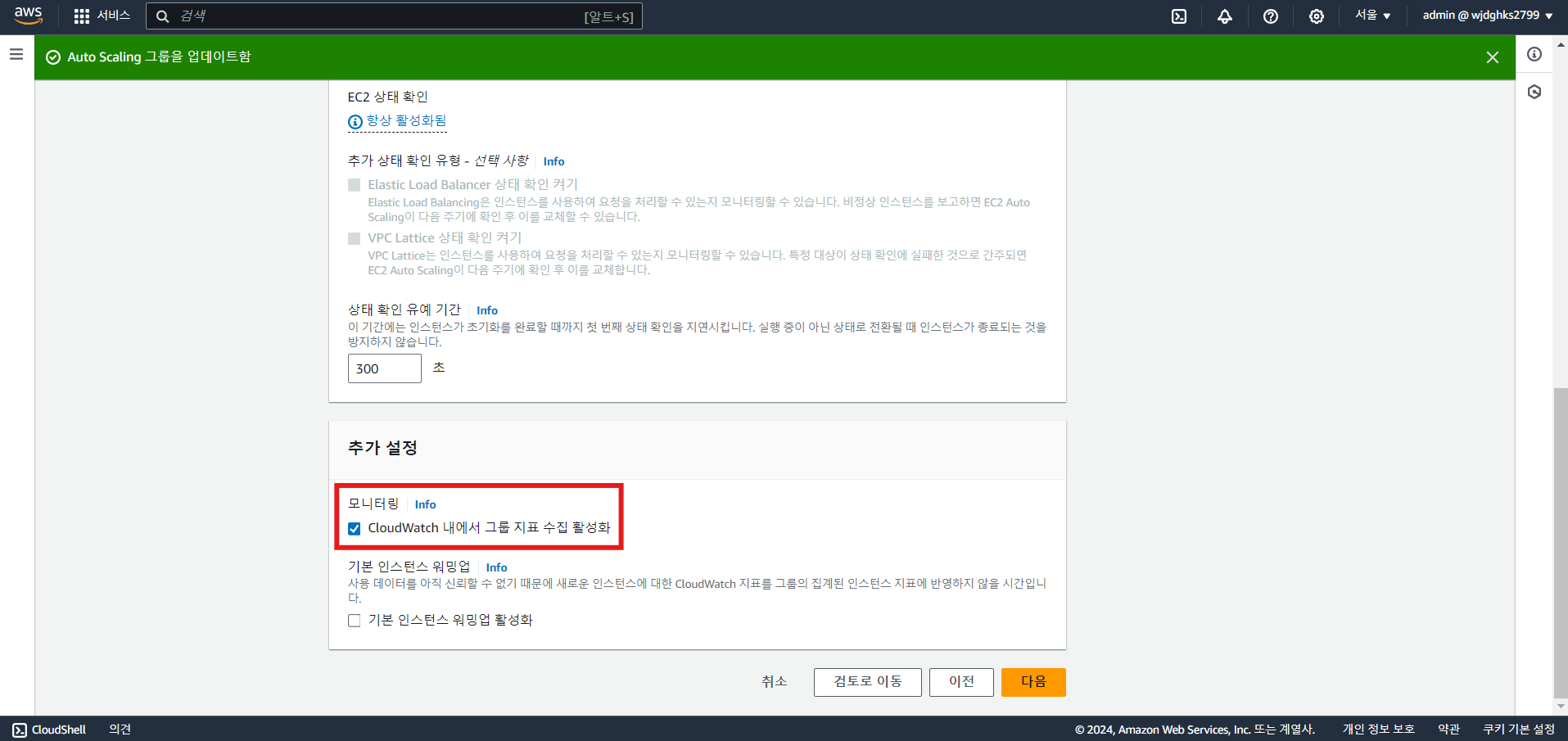
Amazon CloudWatch와 AutoScale
- AutoScale 지표
- AutoScale 관련 지표의 경우 별도로 활성화 필요
- 주요 지표
- 용량(Min/Max/Desired)
- 인스턴스 상태(서비스 중, 종료, 멈춤 등)
- 기타 관리중인 인스턴스 모두의 통합 지표 제공
- 이외에 내부적으로 AutoScaling의 알람, 타겟 추적 스케일링 정책 등은 CloudWatch 기반
Amazon CloudWatch와 ELB
- ELB 지표는 기본적으로 활성화
- 주요 지표
- 요청/연결
- Status Code 별 Count(3xx, 4xx, 5xx)
- IPv6 처리
- 네트워크 지표(처리된 네트워크 트래픽)
* EC2 세부 CloudWatch 모니터링 활성화
* ASG CloudWatch 모니터링 활성화
Amazon Elastic File System

Amazon EFS(Amazon Elastic File System)는 AWS 클라우드 서비스와 온프레미스 리소스에서 사용할 수 있는, 간단하고 확장 가능하며 탄력적인 완전관리형 NFS 파일 시스템을 제공합니다. 이 제품은 애플리케이션을 중단하지 않고 온디맨드 방식으로 페타바이트 규모까지 확장하도록 구축되어, 파일을 추가하고 제거할 때 자동으로 확장하고 축소하며 확장 규모에 맞게 용량을 프로비저닝 및 관리할 필요가 없습니다.
EFS란?
- NFS 기반 공유 스토리지 서비스(NFSv4)
- 따로 용량을 지정할 필요없이 사용한 만큼 용량이 증가 <-> EBS는 미리 크기를 지정해야 함
- 페타바이트 단위까지 가능
- 몇 천개의 동시 접속 유지 가능
- 데이터는 여러 AZ에 나누어 분산 저장
- 쓰기 후 읽기(Read After Write) 일관성
- Private Service: AWS 외부에서 접속 불가능
- AWS 외부에서 접속하기 위해서는 VPN 혹은 Direct Connect 등으로 별도로 VPC와 연결 필요
- 각 가용영역에 Mount Target을 두고 각각의 가용영역에서 해당 Mount Target을 ㅗ접근
- Linux Only
EFS 타입
- Regional: 리전 전체를 활용하여 고가용성과 내구성 확보
- One-Zone: AZ 하나만 활용하여 고가용성과 내구성을 떨어지지만 저렴한 가격
EFS 퍼포먼스 모드
- General Purpose: 가장 보편적인 모드. 거의 대부분의 경우 사용 권장
- Max IO: 매우 높은 IOPS가 필요한 경우
- 빅데이터, 미디어 처리 등
EFT Throughput 모드
- Elastic Throughput: EFS가 자동으로 Throughput을 조절
- 예측하기 어렵거나 적은 범위에서 변동이 있는 경우
- Bursting Throughput: 낮은 Throughput일 때 크레딧을 모아서 높은 Throughput일 때 사용
- EC2 T타입과 비슷한 개념
- Provisioned Throughput: 미리 지정한 만큼의 Throughput을 미리 확보해두고 사용
EC2 T 타입 정리
T 인스턴스
- T 인스턴스는 Burstable performance instances(버스트 가능한 성능 인스턴스)
- 다른 인스턴스 타입처럼 고정된 용량의 CPU 자원을 제공하지 않음
- CPU 크레딧 제도
- CPU 사용량이 기본 수준(baseline) 이상이라면 크레딧을 차감
- CPU 사용량이 기본 수준(baseline) 미만이라면 크레딧을 제공
- 베이스라인: CPU 사용량을 통해 크레딧의 소모와 증가가 같은 지점
- 인스턴스의 크기에 따라 다름
- 즉 평소에는 baseline 밑으로 유지해 크레딧을 모으고 꼭 필요한 상황에 크레딧을 소모해 Burst
- 크레딧이 없다면 최악의 경우 CPU 사용량이 5% 미만을 제한됨
* CPU 크레딧: vCPU가 사용하는 시간 단위
T 인스턴스 모드
- 스탠다드 모드(Standard Mode)
- 베이스라인 이상으로 Burst가 발생할 경우 미리 저장된 크레딧을 소모해 CPU 사용
- 크레딧이 없다면 베이스라인 이상으로 CPU 사용 불가
- 언리미티드 모드(Unlimited Mode)
- 제한없이 필요한만큼 CPU 사용
- 베이스라인 이상으로 Burst가 발생할 경우 미리 저장된 크레딧을 소모해 사용
- 크레딧이 없을 경우 24시간 안으로 크레딧을 빌려 충당
- 24시간 안에 베이스라인 미만으로 CPU를 유지해 추가된 크레딧으로 갚기 가능
- 갚지 못한 크레딧을 비용을 지불해 충당
- T2 = 스탠다드 모드, T3 = 언리미티드 모드 디폴트
Launch Credit
- T2 인스턴스의 경우 Launch Credit을 제공
- 인스턴스가 처음 생성될 때 제공
- 생성 직후에 Burst로 진입할 경우를 대비
- Standard 모드가 Default이기 때문
- T3의 경우 Unlimited Mode가 Default이기 때문에 Launch Credit이 부여되지 않음. 즉, T3를 Standard 모드로 사용해서 생성할 경우, 바로 Burst 진입 불가
EC2 사이즈 변경
인스턴스 타입 변경
- 클라우드 컴퓨팅의 장점을 최대한 이용하여 프로비전 이후에도 적절한 타입/사이즈로 변경 가능
- 두 가지 변경
- 사이즈 변경: 같은 인스턴스 패밀리에서 사용량에 따라 크기 조절(예: t3.micro -> t3.medium)
- 패밀리 변경: 워크로드의 성격에 따라 다른 인스턴스 패밀리로 변경(예: t3.micro -> m5.large)
- 호환성 체크 필요
- 가상화 타입(HVM, PV), 아키텍처(ARM, 32bit...), EBS 볼륨 개수 등
- 인스턴스 정지 필요
- Spot 인스턴스는 변경 불가능
- HealthCheck 불가능 -> AutoScale에 영향
- 참고 사항
- 인스턴스 아이디는 유지
- Private IP는 유지하지만 Public IP는 변경(Elastic IP의 경우 고정)
- 인스턴스 스토어와 EBS 사용 인스턴스에 따라 과정이 달라짐
- 인스턴스 스토어의 경우 영구적인 스토리지로 백업 필요
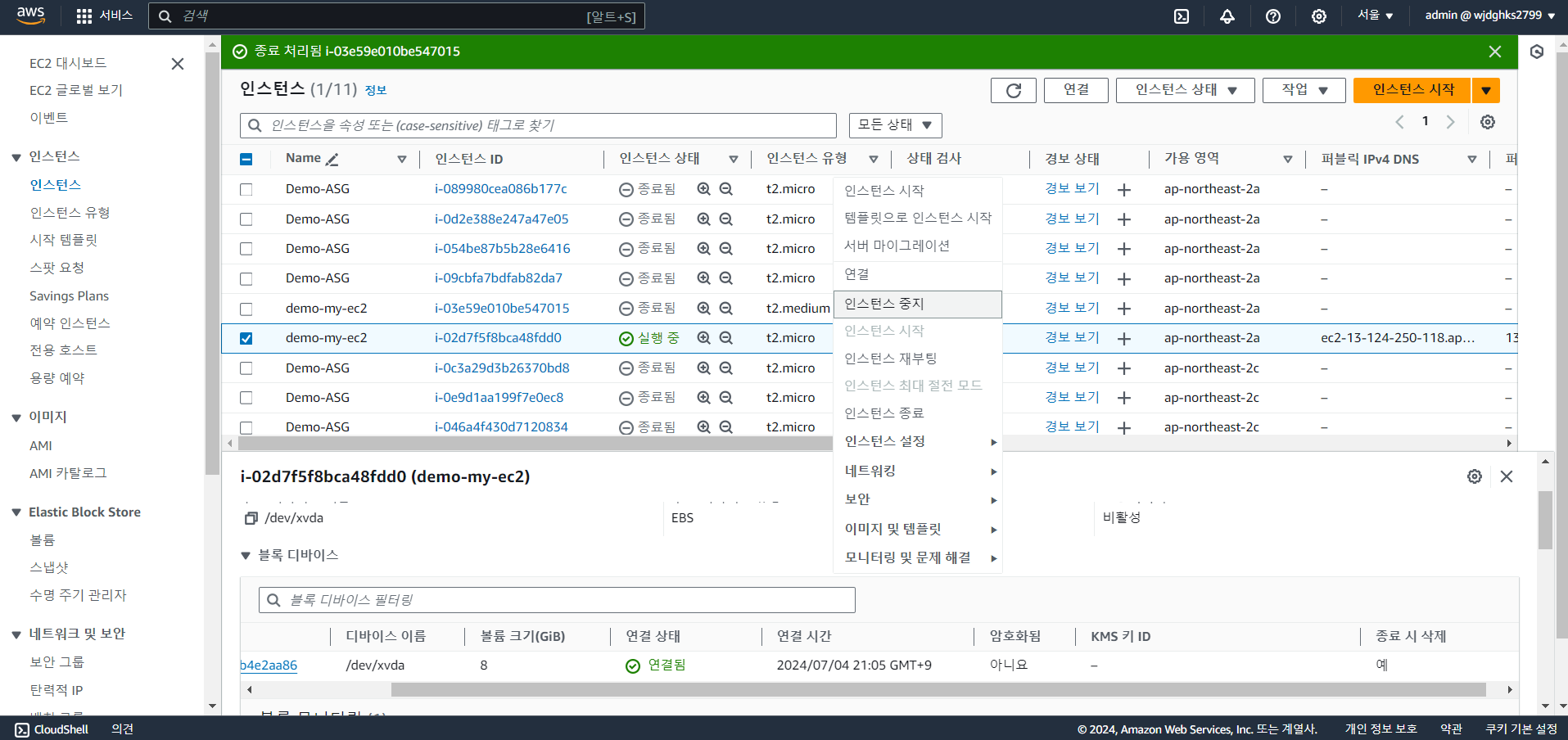
실습 - 호환되는 인스턴스 타입 변경
- 인스턴스 중지
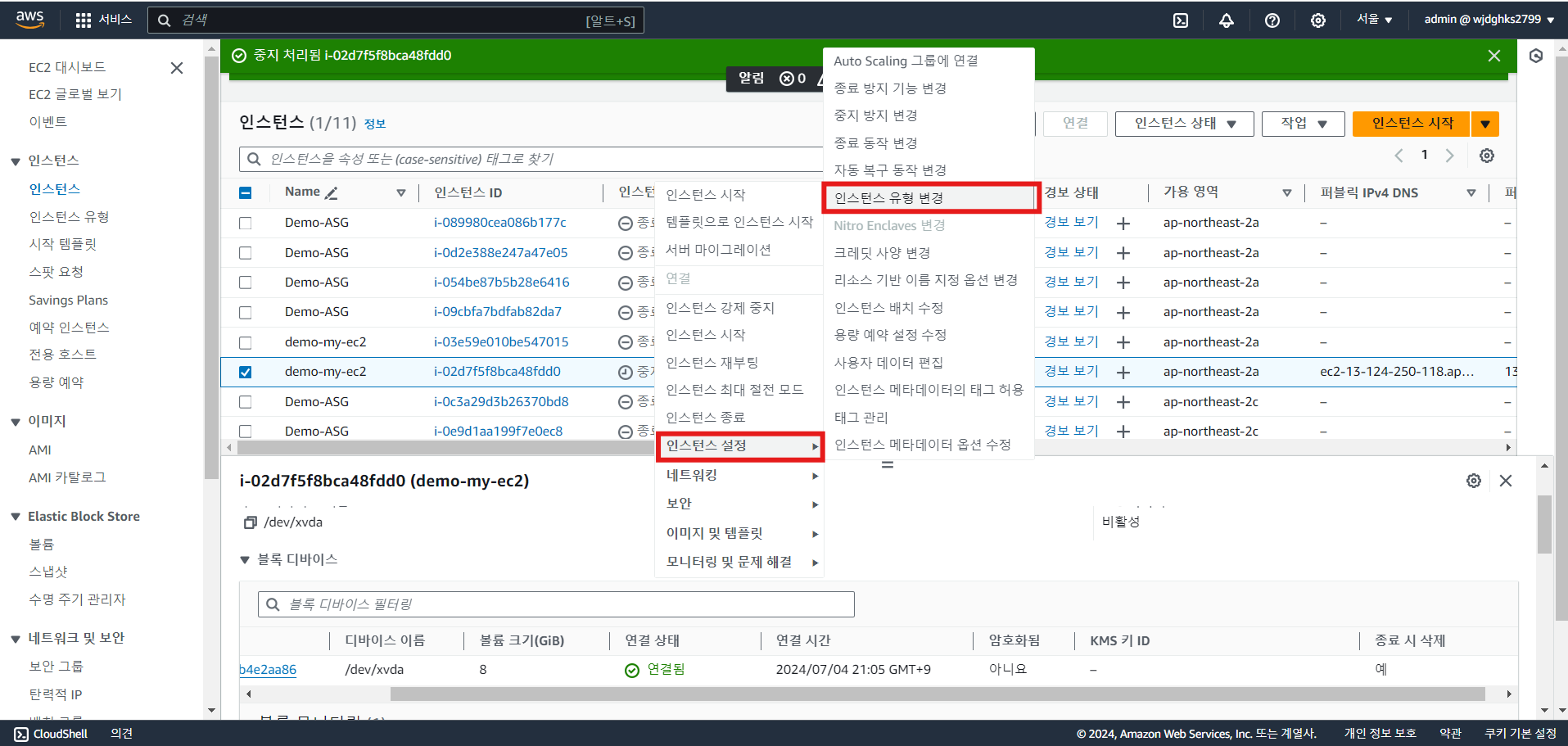
- 인스턴스 유형 변경
실습 - 호환되지 않는 인스턴스 타입 변경
- 인스턴스 중지
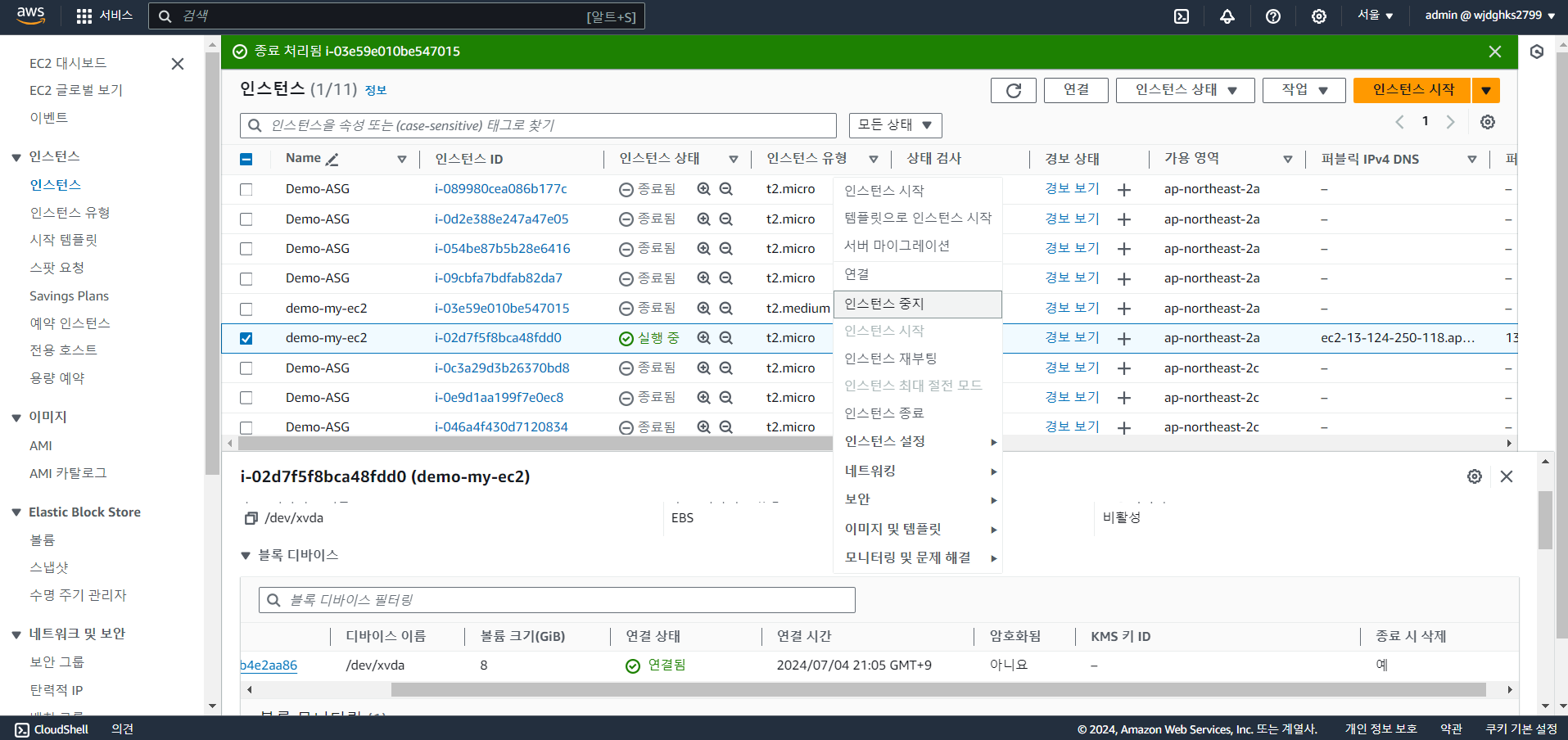
- 볼륨 스냅샷 생성
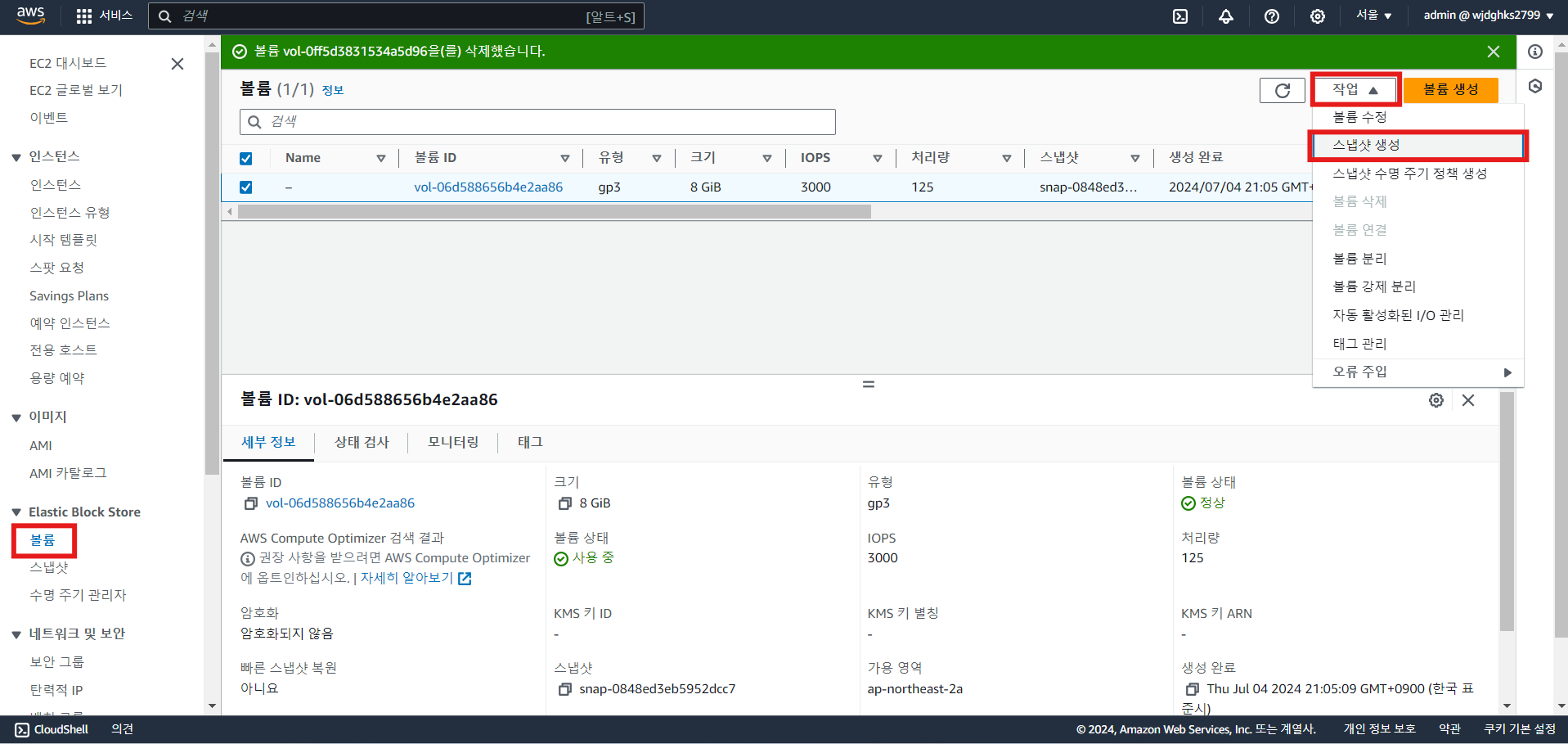
- 스냅샷에서 이미지 생성
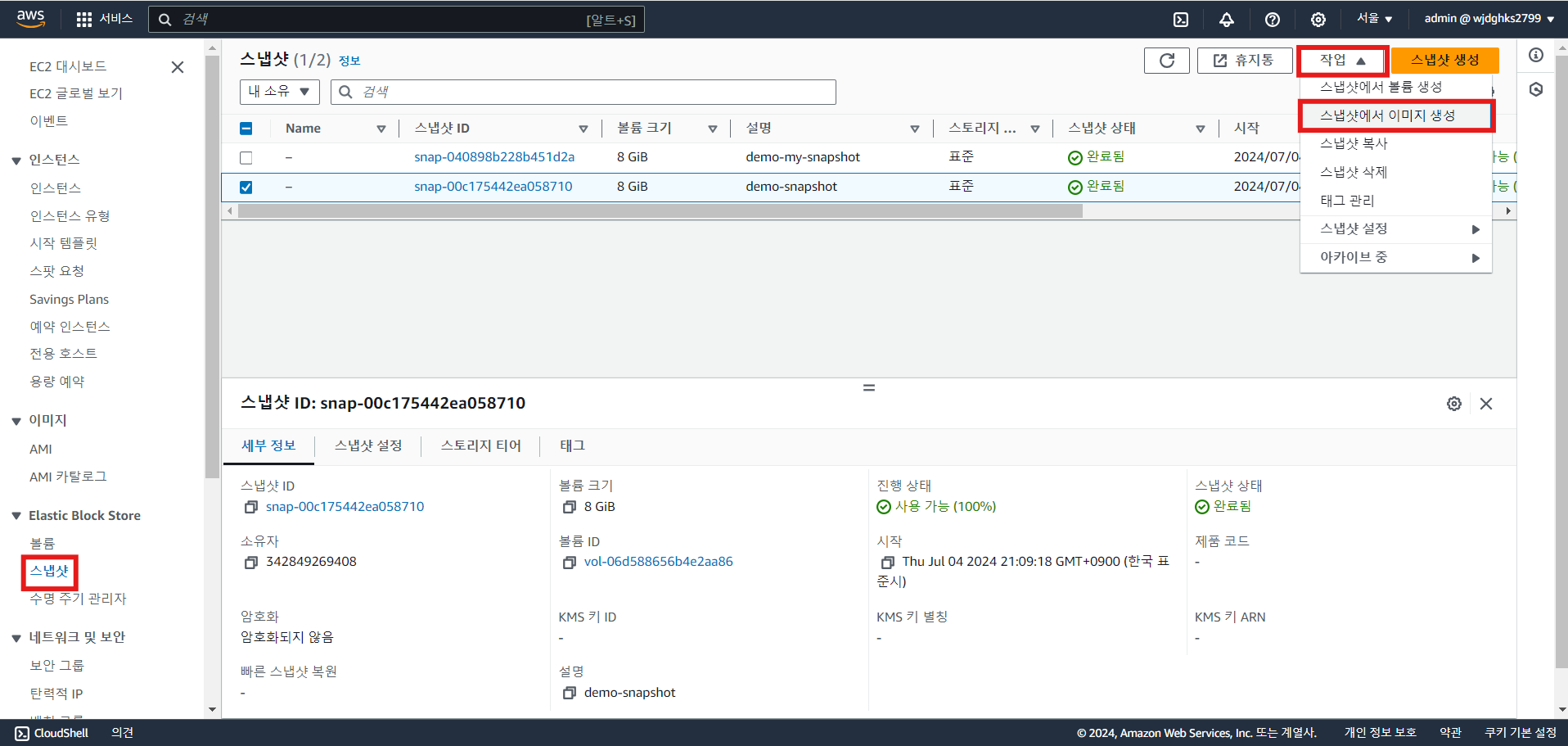
- AMI로 인스턴스 시작