[SAA] 9 AWS 기초: RDS + Aurora + ElastiCache
RDS (Relational Database Service)
DB 엔진의 유형: PostgreSQL, MySQL, MariaDB, Oracle Microsoft SQL Server, Aurora
관리형 서비스→데이터베이스 프로비저닝, 기본 운영체제 패치 완전 자동화
한 가지 단점- RDS 인스턴스에 SSH 액세스 불가
⭐️Storage Auto Scaling
활성화→RDS가 db공간 부족 감지해서 자동으로 스토리지를 확장 (db다운 x)
최대 스토리지 임곗값 설정 후 10% 미만 남으면 자동 수정
RDS Read Replica
요청이 너무 많아서 읽기를 스케일링
read replica 15개까지 생성 가능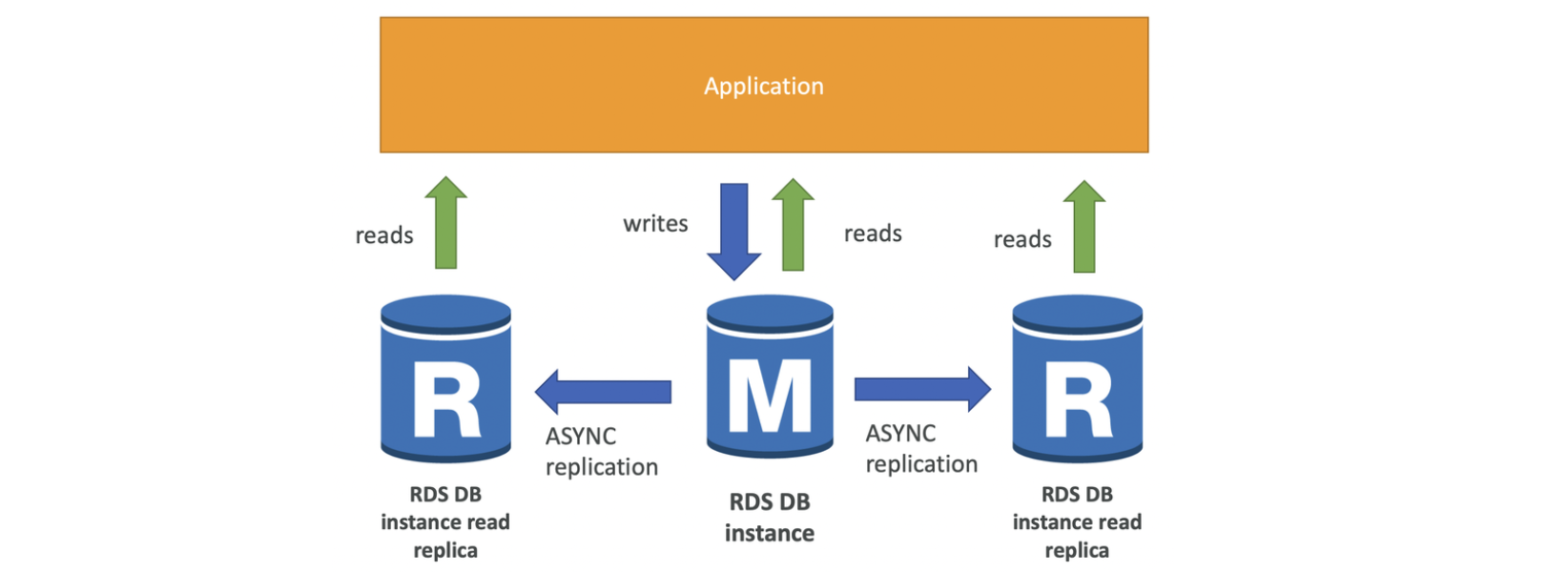 주 데이터베이스 인스턴스와 두 읽기 전용 복제본 사이에 비동기식 복제가 발생 (읽기 일관적으로 유지)
주 데이터베이스 인스턴스와 두 읽기 전용 복제본 사이에 비동기식 복제가 발생 (읽기 일관적으로 유지)
SELECT문만 가능
복제본 중 하나 승격시켜 db로 사용할수도있음 → 복제메커니즘 탈피, 자체적 life cycle 가짐
UseCase:
현재 내 데이터 기반으로 보고와 분석 실시할 예정, 보고 애플리케이션을 메인 rds에 연결하면 오버로드가 발생하고 생산 애플리케이션의 속도가 느려짐 → 이 workload를 위한 read replica 생성
Read Replica는 관리형 서비스로, 다른 AZ로 이동할 때 같은 region내라면 비용발생X
리전을 넘나들때는 네트워크 복제 비용 O
RDS Multi AZ
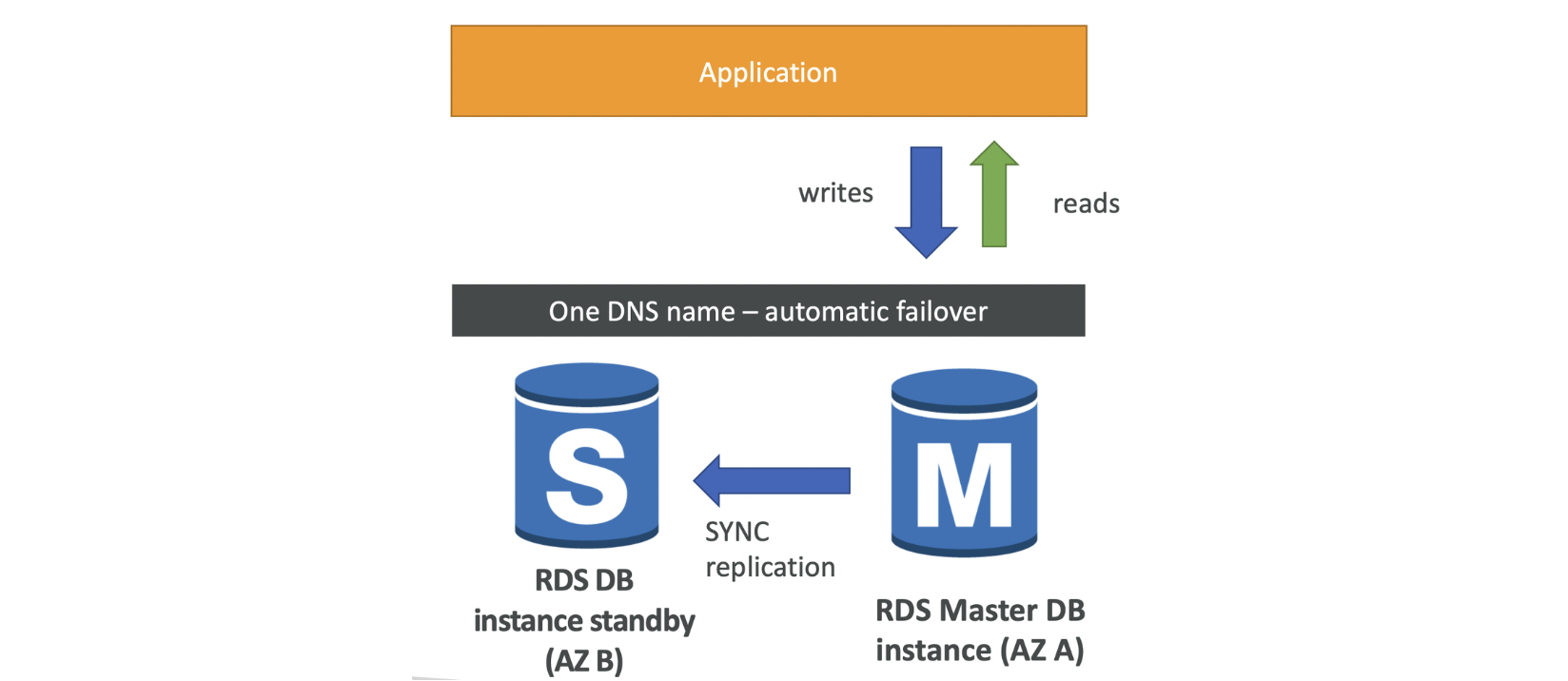
주로 재해 복구에 사용 (가용성 👆)
AZ A의 마스터 데이터베이스 인스턴스를 동기식으로 이를 AZ B에 스탠바이 인스턴스로 복제
애플리케이션의 마스터에 쓰이는 변경 사항이 대기 인스턴스에도 그대로 복제
하나의 DNS 이름을 갖고 통신하며 마스터에 문제가 발생시 스탠바이 데이터베이스에 자동으로 새로운 마스터
스탠바이 db는 대기목적 하나. 읽거나 쓰지x(scalingX)
⭐️RDS 읽기 전용 복제본 VS 다중 AZ:
⭐️ 재해 복구를 대비해서 읽기 전용 복제본을 다중 AZ로 설정 가능
⭐️단일 AZ에서 다중 AZ로 RDS 데이터베이스 전환이 가능, zero downtime operation(=단일 AZ에서 다중 AZ로 전환할 때 db 중지X)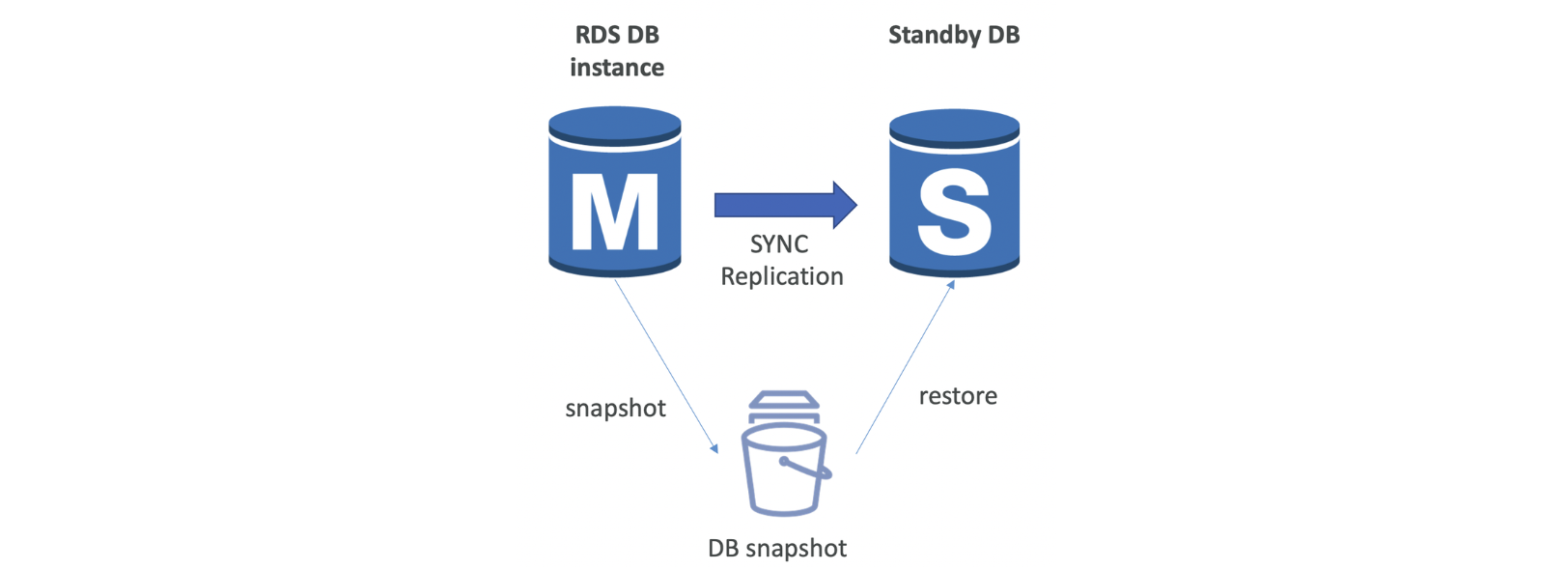
기본 데이터베이스의 RDS가 자동으로 스냅샷을 생성, 새로운 스탠바이 데이터베이스에 복원
두 데이터베이스 간 동기화 설정되어 스탠바이 데이터베이스가 메인 RDS 데이터베이스 내용을 모두 수용, 다중 AZ 설정 상태가 됨
실습에서 쓰는 SQL Electron (처음보는데 편해보임)
** 아는데…! 아는데! 자꾸 헷..갈리고 동기식/비동기식 “복제”는 어떤건지 궁금해져서
- 동기식 복제와 비동기식 복제동기 복제 와 비동기 복제 의 주요 차이점은 데이터가 복제본에 기록되는 방식입니다. 대부분의 동기식 복제 제품은 기본 스토리지와 복제본에 동시에 데이터를 씁니다. 따라서 기본 복사본과 복제본은 항상 동기화된 상태를 유지해야 합니다.
- 대조적으로, 비동기식 복제 제품은 먼저 기본 스토리지에 데이터를 쓴 다음 복제본에 데이터를 복사합니다. 복제 프로세스가 거의 실시간으로 발생할 수 있지만 복제가 예약된 방식으로 발생하는 것이 더 일반적입니다. 예를 들어, 쓰기 작업은 주기적으로(예: 5분마다) 일괄적으로 복제본에 전송될 수 있습니다.
RDS Custom
RDS에서는 기저 운영 체제나 사용자 지정 기능에 액세스 불가 / RDS Custom에선 가능
- Oracle
- Microsoft SQL Server
Custom: 기본 데이터베이스 및 OS에 액세스하여
• 설정 구성
• 패치 설치
• 기본 기능 사용
• SSH 또는 SSM Session Manager를 사용하여 기본 EC2 인스턴스 액세스
커스터마이징 하려면 Automation mode 비활성화 (ec2 인스턴스에 액세스가 가능해지면 문제발생 쉬우므로 db스냅샷 만들어두는게 좋음
RDS vs RDS Custom
RDS: 전체 데이터베이스 및 OS를 AWS가 관리
RDS Custom: 기본 OS 및 데이터베이스에 대한 전체 관리자(admin) 권한을 가짐
⭐️Amazon Aurora
AWS 고유의 기술( 오픈 소스X )
Postgres 및 MySQL과 호환
클라우드에 최적화되어 있고 여러 가지 똑똑한 최적화→ RDS의 MySQL보다 5배, Psostgres보다는 3배 높은 성능
스토리지 자동 확장 (10GB에서 시작, 12TB까지 커짐)
15개의 Read Replica 가능 (MySQL에서는 5개), 복제속도 빠름
Aurora High Availability and Read Scaling
AZ 3개에 걸쳐 기록할때마다 6개의 copies
write에 사본 중 4개만 있으면 됨(AZ하나 작동 안해도 ㄱㅊ)
read에는 사본 중 3개만 있으면 됨(읽기 가용성 높음)
마스터가 작동안하면 평균 30초 이내로 장애조치
백엔드 peer-to-peer replication으로 self healing
수백개의 볼륨 사용(단일볼륨에 의존x)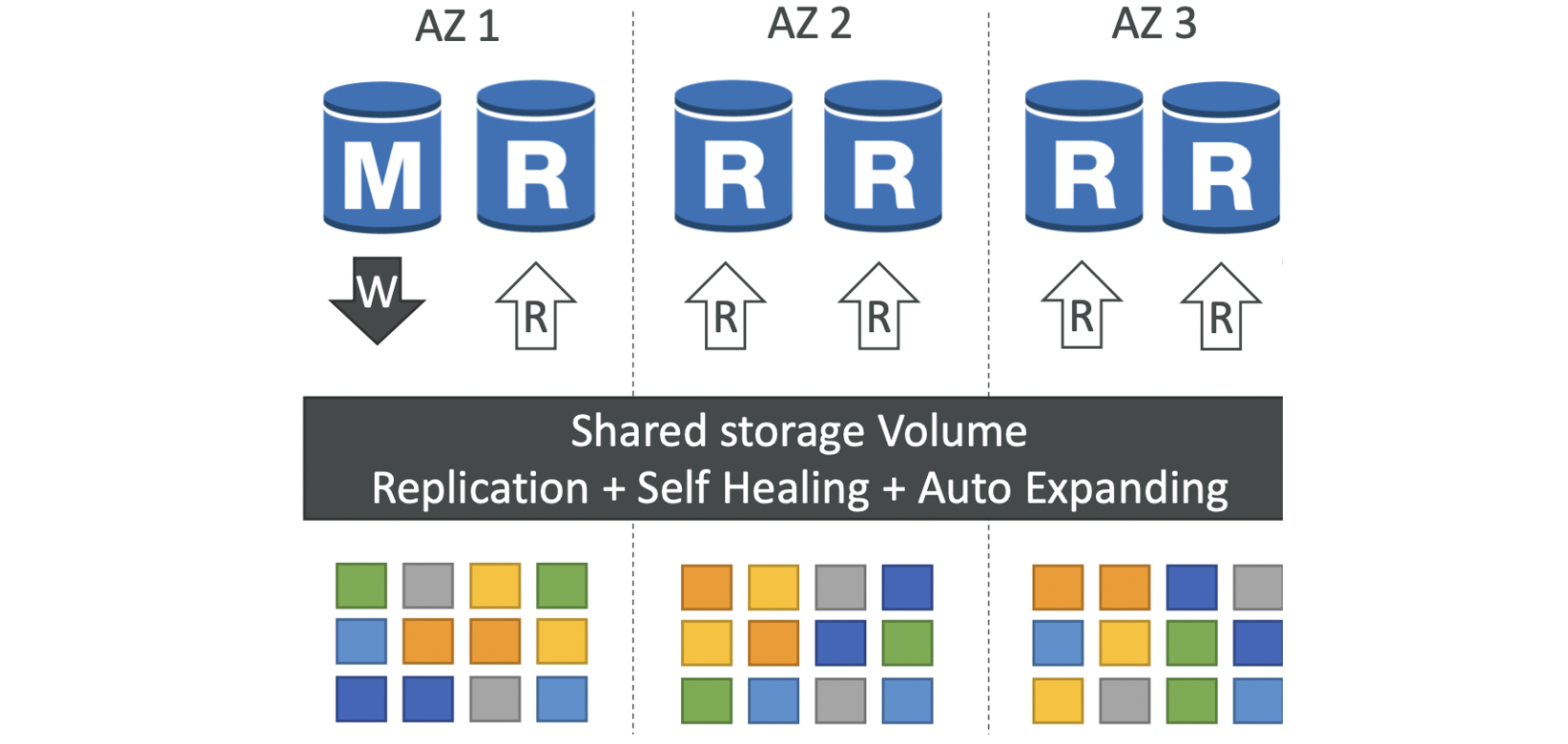 마스터가 하나, 복제본들은 리전 간 복제 가능 , 작은 블록 단위로 자가 복구·확장
마스터가 하나, 복제본들은 리전 간 복제 가능 , 작은 블록 단위로 자가 복구·확장
Aurora DB Cluster
 마스터만 write가능- ⭐️라이터(Writer) 엔드포인트 제공 = DNS 이름 (마스터 가리킴)
마스터만 write가능- ⭐️라이터(Writer) 엔드포인트 제공 = DNS 이름 (마스터 가리킴)
클라이언트가 라이터 엔드포인트와 상호작용, 올바른 인스턴스로 자동 리다이렉트
read replica 15개까지 자동 스케일링
자동스케일링 켜있으면 우리의 앱이 복제본이 어디있고 URL이 무엇이고 어떻게 연력하는지 파악하기 어려울수도
→ ⭐️리더(Reader) 엔드포인트
라이터 엔드포인트와 정확히 같은 기능
연결 로드 밸런싱에 도움
모든 읽기 전용 복제본과 자동으로 연결
클라이언트가 리더 엔드포인트에 연결될 때마다 읽기 전용 복제본 중 하나로 연결되며 로드 밸런싱을 도와줌
로드 밸런싱 statement 레벨이 아닌 connection 레벨 **
** 클러스터:
컴퓨터 클러스터란 여러 대의 컴퓨터들이 연결되어서 하나의 시스템처럼 동작하는 컴퓨터들의 집합. 여러개의 객체를 하나로 모은다는 개념
DB 클러스터도 똑같은 맥락! DB 서버를 여러개 둔다고 생각하면 된다. 이에 대한 기본적인 장점은 서버 한 대가 죽어도 대비가 가능하다는 점이다.
Aurora Replicas - Auto Scaling
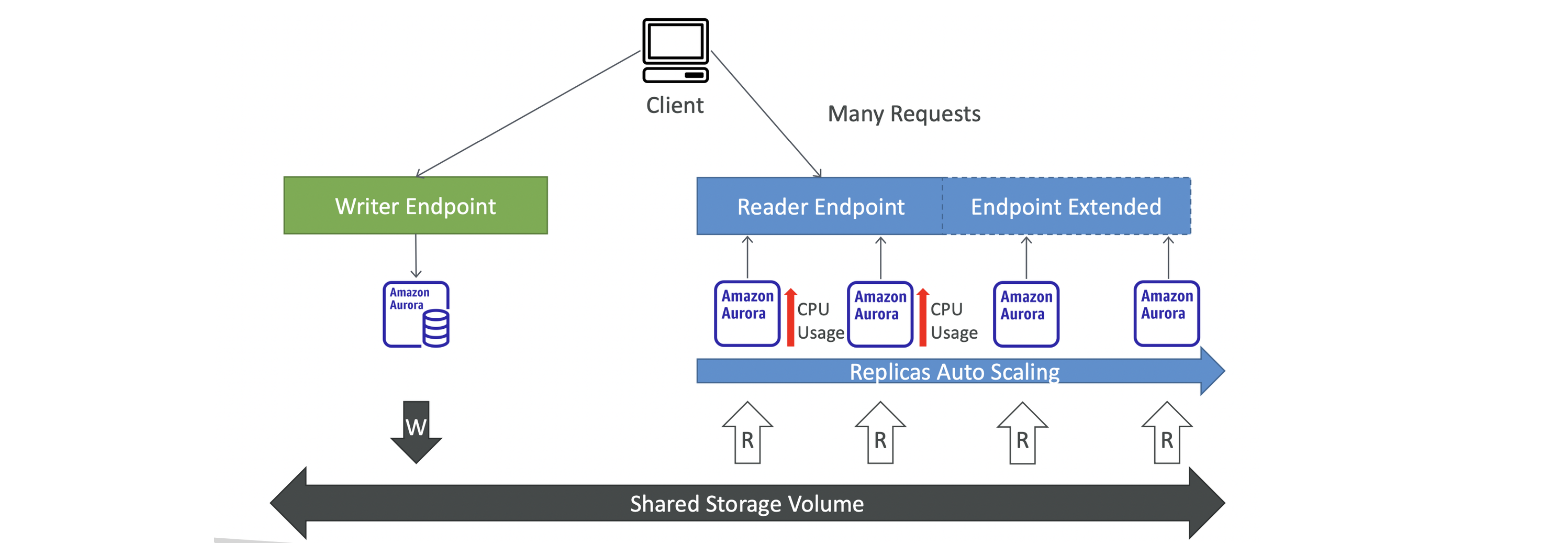
Custom Endpoints
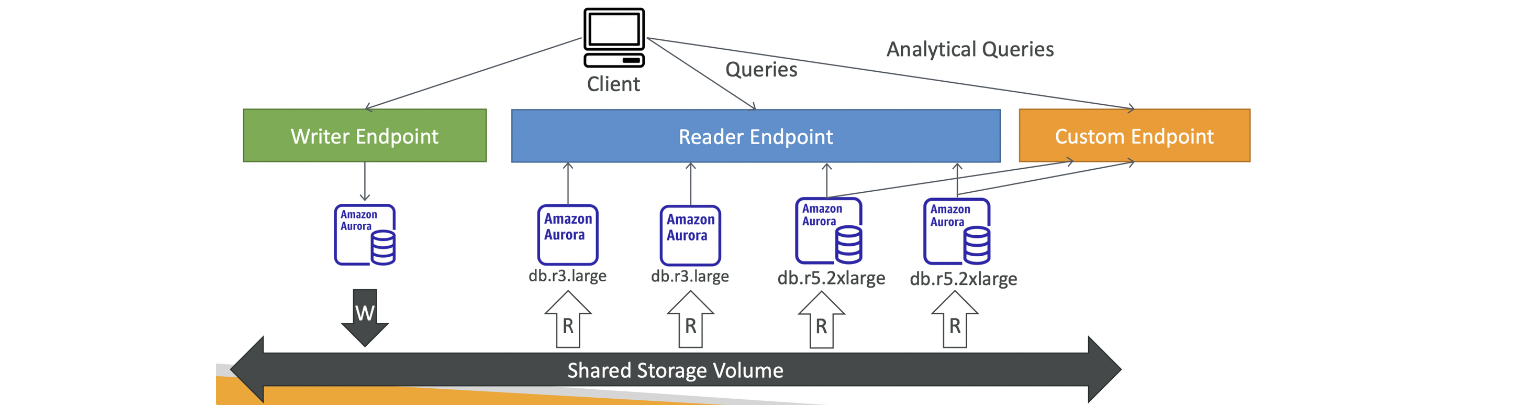 Aurora 인스턴스의 하위 집합을 Custom Endpoint로 정의
Aurora 인스턴스의 하위 집합을 Custom Endpoint로 정의
사용자 지정 엔드포인트가 있는 경우, 일반적으로 리더 엔드포인트는 사용x
Aurora Serverless
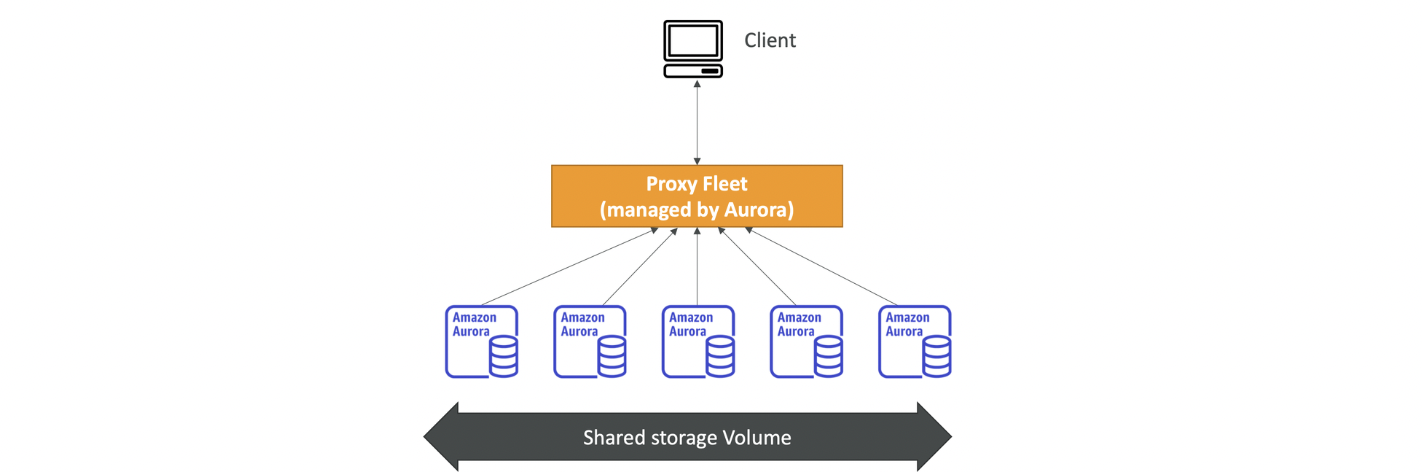 사용량에 따라 자동화된 데이터베이스 인스턴스화 및 오토 스케일링을 제공
사용량에 따라 자동화된 데이터베이스 인스턴스화 및 오토 스케일링을 제공
워크로드가 드물거나 간헐적이거나 예측할 수 없는 경우에 유용
용량 계획을 세울 필요X
클라이언트는 Aurora에서 관리하는 프록시 플릿과 소통
Aurora Multi-Master
continuous write availability를 원하는 경우
모든 aurora 인스턴스가 writer 노드
클라이언트가 Multiple writer endpoints로 연결 유지 가능
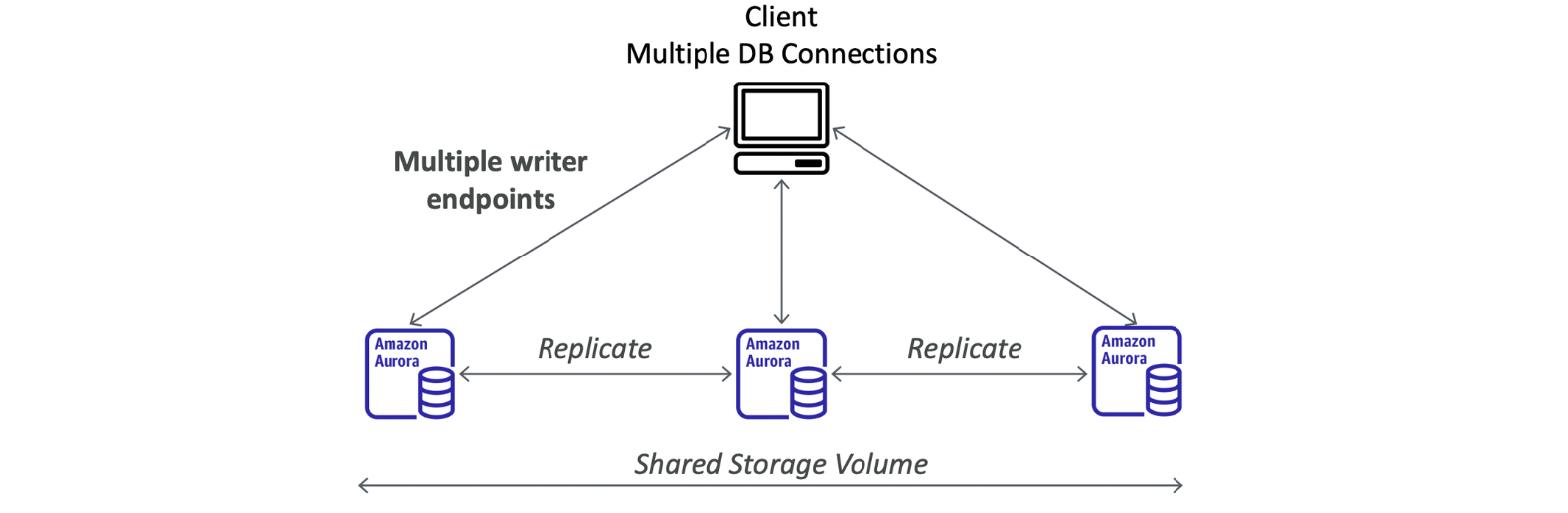
** endpoint가 뭔가
엔드포인트는 서비스를 사용 가능하도록 하는 서비스에서 제공하는 커뮤니케이션 채널의 한쪽 끝
→ 엔드포인트는 AWS 웹 서비스를 위한 진입점의 URL
Global Aurora
Aurora Cross Region Read Replicas → 재해 복구에 유용
Aurora Global Database → 최대 5개의 보조 읽기 전용 리전(복제delay 1초 미만), 중단되면 다른 리전을 활성화(1분 미만) (읽기전용이 읽고쓰게 승격)
⭐️ "Aurora 글로벌 데이터베이스의 데이터를 리전 간에 복제하는 데 평균 1초 미만이 소요됩니다"
→ 이 문장이 시험에 나온다면 글로벌 Aurora를 사용하라는 힌트
Aurora Machine Learning
SQL 인터페이스로 애플리케이션에 머신러닝 기반 예측을 적용 가능
- SageMaker : 백엔드에서 모든 종류의 머신러닝 모델을 사용할 수 있게 도움
- Amazon Comprehend : 감정 분석
비스 간의 간단하고 최적화된 안전한 통합입니다
두 가지 서비스에서 지원되는데요, SageMaker는 백엔드에서 모든 종류의 머신러닝 모델을 사용할 수 있게 해줍니다, 그리고 Amazon Comprehend가 있죠
RDS & Aurora- 백업과 모니터링
RDS Backups
Automated backups
RDS 서비스가 자동으로 매일 데이터베이스의 전체 백업을 수행
5분마다 트랜잭션 로그가 백업 (언제라도 5분 전으로 복원 가능), 자동 백업 보존 기간은 1~35일
Manual DB Snapshots
수동 DB 스냅샷은 원하는 기간 동안 보관 가능
⭐️ex. 비용 절감하고싶을 때, 수냅샷 만들고 데이터 베이스 중지하여 사용할때만 스냅샷 복원
Aurora Backups
Automated backups
1~35일 (비활성화 불가능)
point-in-time recovery(시점 복구기능) - 어느 시점으로든 복구 가능
Manual DB Snapshots
사용자가 수동으로 트리거, 원하는 기간동안 유지
Restore options
- RDS / Aurora backup or a snapshot을 복원할 때 새 데이터베이스 생성
- S3에서 MySQL RDS database 복구 (db 백업만 있으면 됨)
- S3에서 MySQL Aurora cluster 복구(Percona XtraBackup으로 백업한 다음, S3에서 Aurora DB 클러스터로 백업)
Aurora Database Cloning
기존 데이터베이스 클러스터에서 새로운 Aurora 데이터베이스 클러스터 생성 가능
ex. 프로덕션 데이터베이스 존재, 테스트 실행하기 위해db 복제→스테이징 Aurora 데이터베이스
(스냅샷 찍고 복원보다 빠름
→ 복제는 copy-on-write 프로토콜**
처음 복제본 만들때 원래 데이터베이스 클러스터와 동일한 볼륨 사용, 데이터 복사 안하니까 빠르고 효율적임
프로덕션 Aurora 데이터베이스 ⇒ 스테이징 Aurora 데이터베이스에 업데이트 : 새로운 추가 스토리지가 할당되고, 데이터 복사
Database Cloning은 빠르고 비용 효율적, 프로덕션 db에 영향 X, db 복제에 유용 (스냅샷, 복원 기능 필요X)
** https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html
RDS & Aurora Security
At-rest encryption: AWS KMS를 사용해 마스터와 모든 replica 암호화 - 데이터가 볼륨에 암호화됨
마스터 암호화 안했으면 read replica 암호화 불가
암호화 안했던거 암호화하려면 스냅샷생성 → 암호화된 형태로 스냅샷 복원
In-flightencryption: 클라이언트, 데이터베이스 간의 전송중 데이터 암호화
TLS default → 클라이언트가 TLS 루트 인증서 사용해야 함
IAM Authentication: IAM role 사용해 db에 접속
Security Groups: 특정 포트, IP, 보안 그룹 허용/차단
No SSH available: ssh액세스 없음
Audit Logs: 쿼리 기록, 데이터베이스 확인, CloudWatch Logs로 보내서 장기보관
Amazon RDS Proxy
바로 액세스 안하고 프록시하는 이유:
-
애플리케이션이 db내에서 연결 풀을 형성하고 공유 가능
⭐️애플리케이션을 rds인스턴스에 일일이 연결하는 대신 프록시에 연결→ 프록시가 하나의 pool에 연결을 모음 → rbs 인스턴스로의 연결 감소 → CPU, RAM등 db리소스의 부담을 줄여 효율성 향상, db의 open connection과 timeout 최소화 -
rds프록시는 완전한 서버리스 - autoscaling, highly available (multi-AZ)
⭐️장애나면 대기 인스턴스로 실행되어 장애조치시간(failover time) 66% 감소
메인 rds db instance에 애플리케이션 연결하고 각자 장애조치하는 대신, 장애조치와 무관한 RDS프록시에 연결 : RDS프록시가 장애 조치 발생한 RDS데이터베이스 인스턴스 처리해서 장애조치 시간 개선됨 -
애플리케이션 코드 변경 없이 rds프록시에 연결하면 됨 (rds db인스턴스, 오로라인스턴스 대신에)
-
데이터베이스에 IAM 인증 강제하여 IAM인증을 통해서만 rds db instance에 연결하게 함
자격증명은 AWS Secret Manager서비스에 안전하게 저장됨 -
RDS는 public 액세스가 불가능.(VPC 내에서만 액세스 가능) → 보안 훌륭
-
Lambda 함수와 사용하면 유용
람다함수는 빠르게 생성되고 사라져 연결많아지고 시간초과 발생 가능 → rds 프록시로 람다함수의 connection pool을 생성하면 람다함수가 rds프록시를 오버로드, 인스턴스 연결 감소
** 프록시란?
"대리"의 의미
특히 내부 네트워크에서 인터넷 접속을 할 때에, 빠른 액세스나 안전한 통신등을 확보하기 위한 중계서버를 "프록시 서버” 라고함
클라이언트와 Web서버의 중간에 위치하고 있어, 대신 통신을 받아 주는 것이 프록시 서버
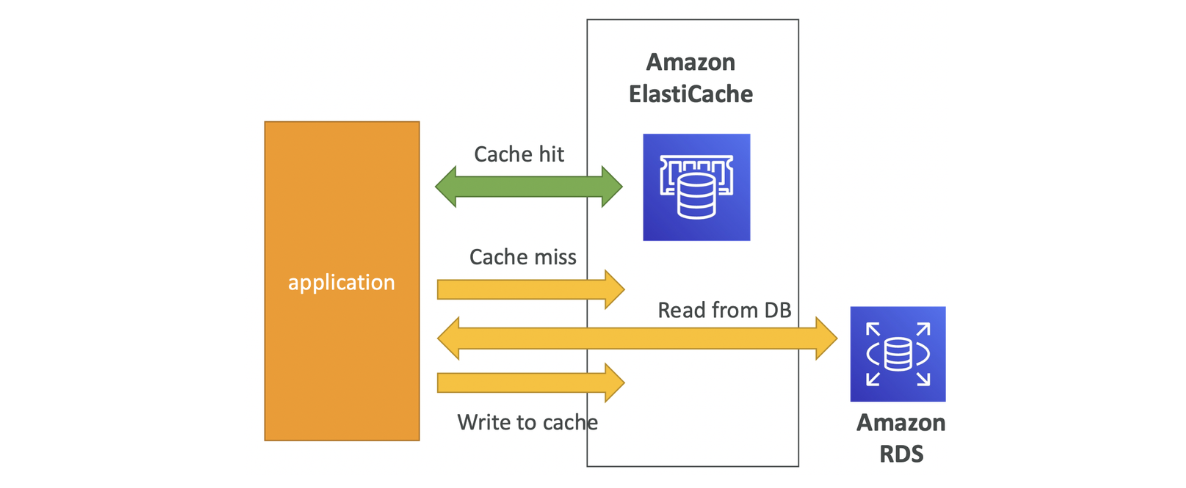
Amazon ElastiCache
캐싱 기술인 Redis 또는 Memcached를 관리하는 것을 도움
(캐시: 높은 성능 짧은 delay의 인메모리(in-memory) 데이터베이스/ 읽기 집약적 워크로드의 db로드 줄여줌
** in-memory 컴퓨터의 주 메모리에 모든 조직 또는 개인의 데이터를 저장
일반적 쿼리는 캐시에 저장, 캐시만 사용해도 쿼리 결과 검색 가능
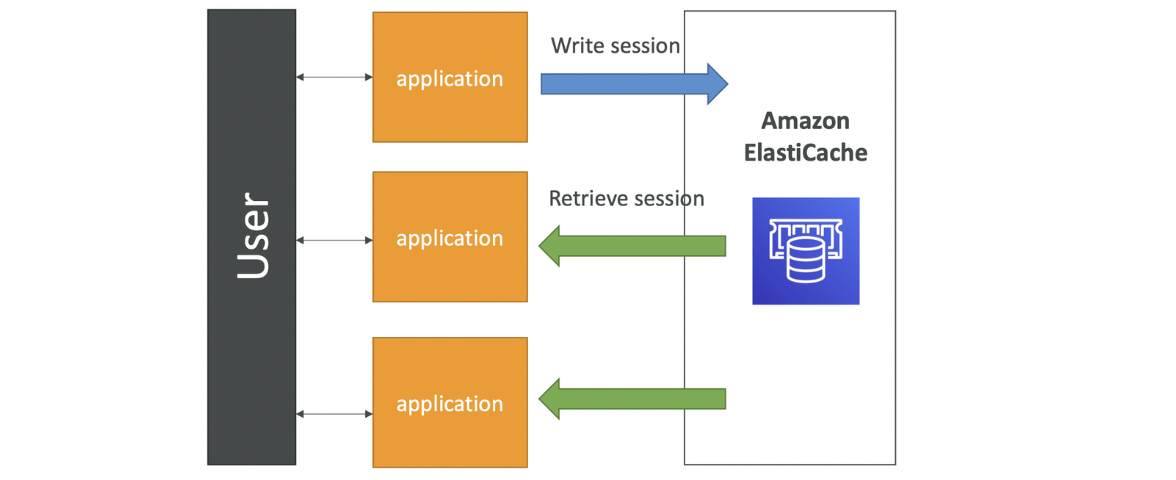
애플리케이션의 상태를 Amazon ElastiCache에 저장해 애플리케이션이 상태 비저장형(stateless)하게 도와줌
애플리케이션의 코드를 많이 바꿔야함**
캐시를 쿼리하는 애플리케이션을 변경해야 함
ex. Amazon , RDS 데이터베이스, 애플리케이션
애플리케이션이 ElastiCache를 쿼리 → 이미 그 결과가 발생하여 저장하되어 있으면 Cache hit
⇒ 쿼리 수행 위해 RDS로 이동하는 시간 절약
캐시 무효화 전략 (invalidation strategy) - 최신 데이터만 사용해야 함
ex. 애플리케이션을 stateless로 만들기 위해 사용자 세션을 저장
사용자가 application에 로그인하면 세션 데이터를 ElastiCache에 씀
세션 캐시를 ElastiCache에서 검색가능하면 계속 로그인 상태인 것
Redis vs Memcache
Redis: 가용성 내구성이 뛰어난 복제된 캐시, 고가용성, 백업, 읽기 복제본을 위해 존재
Multi AZ → Auto-Failover(자동 장애 조치 기능)
Read Replicas → ( scale reads, high availability)
AOF persistence → Data Durability(내구성)
Backup, restore
⭐️Supports Sets, ⭐️Sorted Sets
Memcache: 분산되어있는 순수한 캐시. 데이터 손실되어도 괜찮음
Multi-node for partitioning of data (=sharding)
No high availability (replication X)
Non persistent 영구 캐시 아님
No backup and restore
Multi-threaded architecture
** https://docs.aws.amazon.com/ko_kr/AmazonElastiCache/latest/mem-ug/SelectEngine.html
Redis랑 Memcached는 Amazon ElastiCache에서 지원하는 캐시엔진
Cache Security
Redis만 IAM 인증 지원 (나머진 id pw)
IAM 정책 정의→AWS API-level security만 사용
Redis AUTH _ EC2인스턴스와 클라이언트가 있는 경우 Redis AUTH로 Redis 클러스터에 연결
redis클러스터 만들때 “password/token” 설정
캐시에 추가 보안 수준 제공 (보안그룹+α로)
SSL 전송중 암호화 지원
Memcached는 SASL 기반 승인 제공
ElastiCache에 데이터 로드하는 패턴
Lazy Loading(지연로딩) : 모든 데이터 캐시
캐시 히트 없는 경우에만 데이터를 ElastiCache에 로드
Write Through : 데이터가 기록될 떄마다 캐시에 데이터 추가, 엡데이트 (시간지연 X)
Session Store: ElastiCache에 세션 저장
Redis Use Case
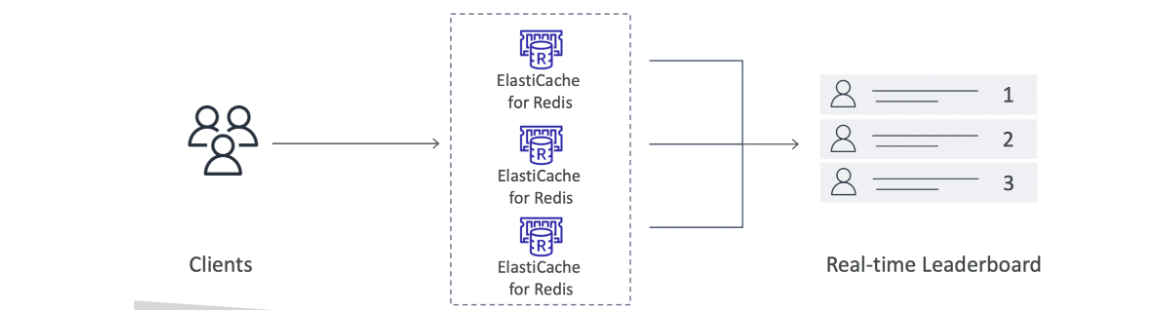
⭐️게이밍 리더보드 만들기:
게임하는 어떤 순간이든 누가 1등? 2등? 3등?
⇒Redis Sorted sets은 고유성(uniqueness), 요소 순서(element ordering) 모두 보장
요소가 추가될 때마다, 실시간으로 순위를 매긴 다음 올바른 순서로 추가
⇒ 애플리케이션에서 기능 프로그래밍할 필요 없이 실시간 리더보드에 액세스 가능
⭐️“중요한 포트”와 “RDS 데이터베이스 포트”를 구분할 줄만 알면 됨
중요한 포트:
FTP: 21
SSH: 22
SFTP: 22 (SSH와 같음)
HTTP: 80
HTTPS: 443
RDS 데이터베이스 포트:
PostgreSQL: 5432
MySQL: 3306
Oracle RDS: 1521
MSSQL Server: 1433
MariaDB: 3306 (MySQL과 같음)
Aurora: 5432 (PostgreSQL와 호환될 경우) 또는 3306 (MySQL과 호환될 경우)
용어 정리
RDS
-
Storage Auto Scaling
-
Read Replica
15개 -
Multi AZ
다른az에 standby -
Custom
-
백업
매일 전체백업, 5분마나 트랜잭션로그 백업 + Manual DB Snapshots -
Proxy
Amazon Aurora -
High Availability and Read Scaling
3개 AZ에 6개의 copies -
Aurora DB Cluster
라이터(Writer) 엔드포인트
리더(Reader) 엔드포인트 -
Aurora Replicas - Auto Scaling
-
Custom Endpoints
-
Aurora Serverless
-
Aurora Multi-Master
Multiple writer endpoints -
Global Aurora
최대 5개 read replica region, 중단되면 메인으로 승격 (복제 1초미만) -
Aurora Machine Learning
-
백업
자동백업 비활성화불가 + Manual DB Snapshots
Aurora Database Cloning
크기같은거 만들고나서 내용 복사. 빠르고 비용효율적
ElastiCache
-
Redis
-
Memcached
쿼리결과캐싱, stateless 애플리케이션, Supports Sets, Sorted Sets
