Introduction to Databases
Database: 대량의 데이터를 저장하고 검색할 수 있는 일관되고 체계적인 구조
- 주문을 받고, 결제를 처리하고, 추천을 하는 등 더 복잡한 애플리케이션을 구축 가능
- nature of data, fundamentals, types에 대해 알아보자
What is Database?
컴퓨터는 정보 참조·변경 전에 정보 저장 필요
컴퓨터는 적절한 시간에 적절한 정보 찾아야함
Database: 논리적으로 조직화된 정보의 집합체. 컴퓨터 프로그램이 내부 정보를 사용할수있게 설계됨
- 안전한 환경에서 무결성(integrity)을 유지하면서 데이터 엑세스 제공

Flat File Approach
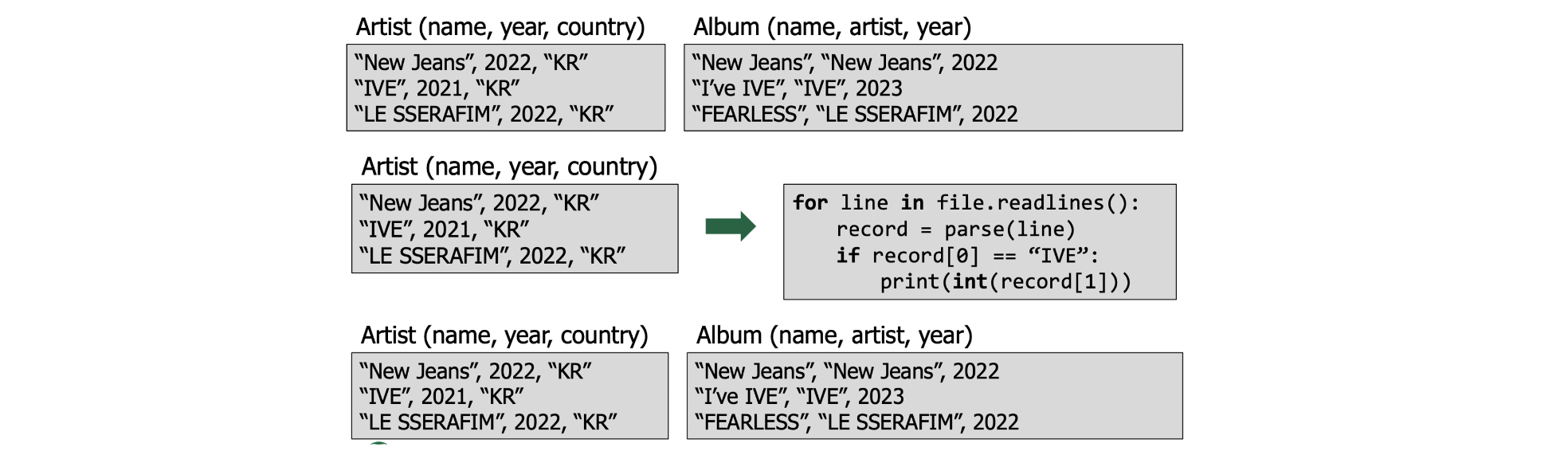
데이터베이스를 애플리케이션 코드로 우리가 관리하는 comma-separated value (CSV) 파일로 저장
- entity마다 별도의 파일 사용
- application는 records를 read/update 할때마다 파일을 분석해야함
Challenges:
- 데이터 무결성(integrity): 잘못된 문자열로 덮어쓰는경우, 한 앨범에 여러명의 아티스트, 앨범이 있는 아티스트 삭제
- 구현(Implementation): 특정 레코드 어떻게 찾나, 데베 쓰는 새로운 응용프로그램만드려면?, 두개의 스레드가 같은 파일을 쓰면?
- 내구성(Durability): 업데이트하는동안 기계 고장나면? 높은 유용성을 위해 여러 시스템에 복제하려면?
Data Models and Structure
Data model
- database의 논리적 구조
- 정보 구성하고 사용할 수 있는 방법에 대한 규칙 결정
선택한 data model은 데이터 구조에 영향 받음
데이터는 세가지 방식으로 구성: Structured(정형), Unstructured(비정형), Semistructured(반구조적)
Structured Data
Structured Data(구조화된 데이터): 관련 테이블에 일련의 데이터값으로 저장됨
data that can be made in table
효과적인 처리 및 분석을 위해 요소들을 다룰 수 있도록 초기화됨(formatted)
data는 highly complex queries에 사용됨

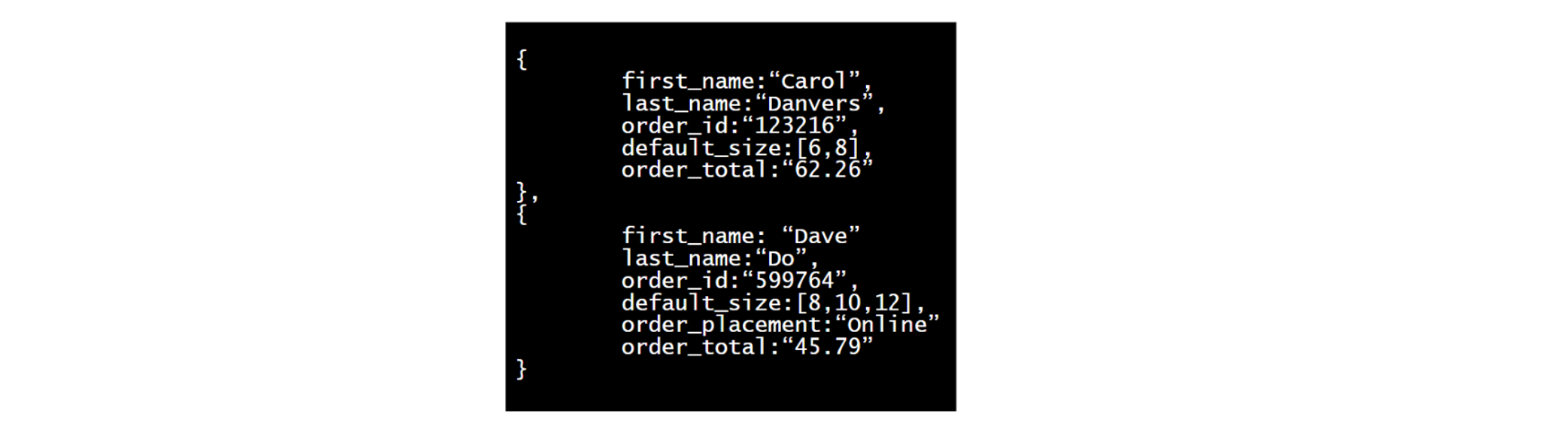
Unstructured and Semi-structured Data
Unstructured data는 file로 저장 (.jpg .avi .doc)
- 미리 정의된 구조가 없으며 data를 목록으로만들고(catalog) 묻는(query) 특별한 도구가 필요
Semi-structured data
- 구조가 엄격하지 않아 테이블 내에서 필요에 따라 변경가능. 유연성이 높음
- 구조화된 데이터의 분석과 같은 수준의 복잡성으로 분석 가능
Database Terms and Concepts (용어·개념)
Schema
- db스키마는 db의 상세한 계획(청사진)
- db내의 관계와 제약조건의 outline(윤곽)
Read/Write
- Read: 특정 목적을 위해 데이터에 액세스
- Write: 새 데이터를 넣거나 데이터를 변경
Input/output operations per second (IOPS) 초당 입출력 작업 수
- storage에 대한 읽기쓰기 성능 척도
- db는 IOPS 중점적(intensive)
Indexes
- query가 결과를 생성하는데 필요한 데이터를 신속하게 찾게도움
- key values를 기반으로 예측가능한 순서로 레코드를 물리적으로 그룹화
- index없으면 쿼리는 전체 테이블을 검색해야 함 SQL query language (SQL)
SQL query language (SQL)
- 관계형(relational) 데이터베이스에 엑세스하여 작업할 수 있는 표준언어
- 쿼리 실행, 데이터 검색, 레코드 삽입, 레코드 업데이트, 레코드 삭제, 새 데이터베이스 만들기, 데이터베이스에 새 테이블 만들기
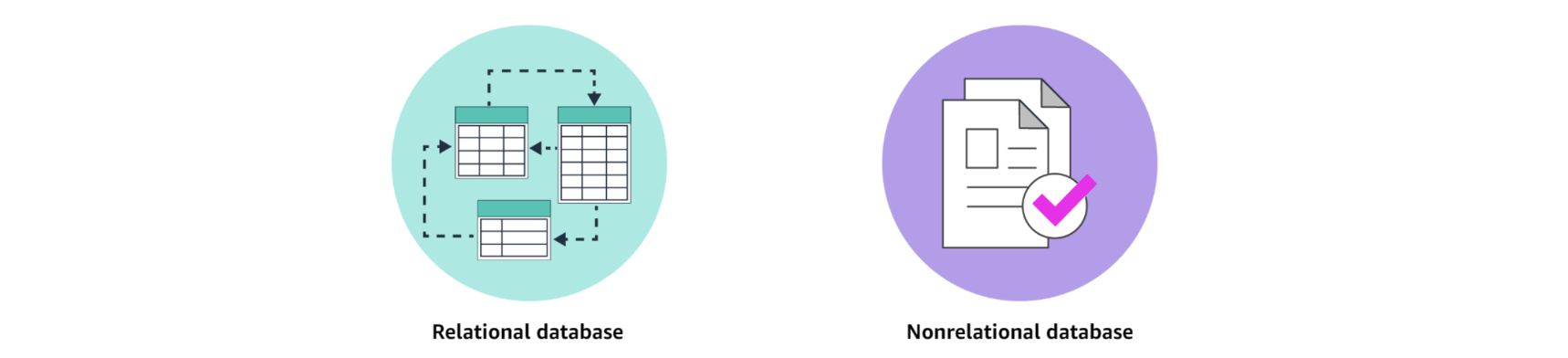
Relational and Nonrelational
Relational database: structured data에 적합
Nonrelational database: unstructured·semi-structured data에 적합
Relational Databases Tables
관계형 데이터베이스는 행과 열이 있는 테이블 집합으로 구성된 데이터 레코드의 집합
- 각 행: 레코드에 대한 정보
- 각 열: 데이터의 속성
각 행에는 레코드를 다른 레코드와 고유하게 구별하기 위한 식별자 열 존재
외래 키(foreign key): 기본키(primary key)를 참조하는 다른 테이블의 레코드

Relational Databases Benefits
가장 대중적이고 가장 많이 사용되는 데이터베이스
인기있는 이유:
- ease of use
- 데이터 무결성(integrity) 및 정확성(accuracy)
- 공통 공유 쿼리 언어 (SQL 등)
- redundancy(중복) 및 overall(전체) data storage 절감의 우수함
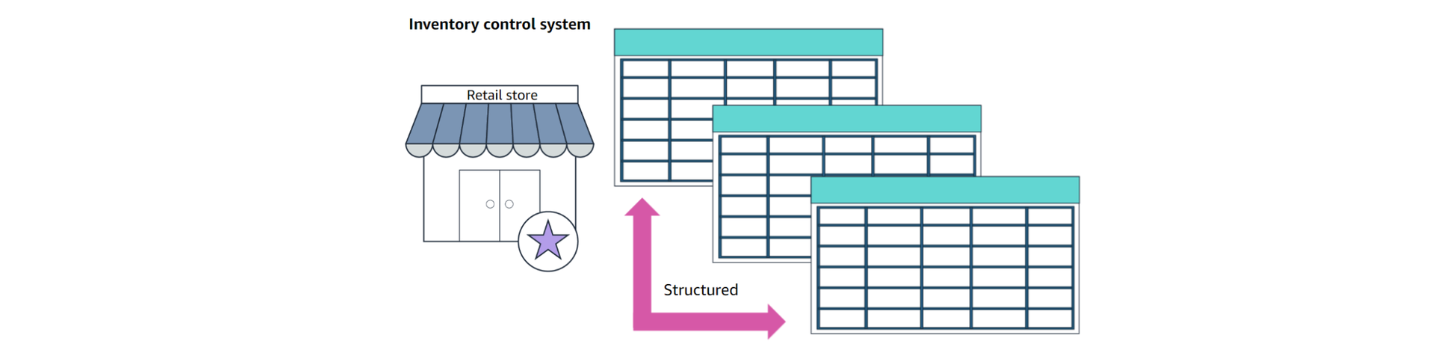
Relational Databases Use Case
좋은 예) 소매 회사의 재고 관리 시스템 - 재고(Inventory) 데이터가 구조화됨
관계형 데이터베이스는 속성에 따라 그룹화할 수 있는 데이터에 적합
열과 행을 빠르고 효율적으로 인덱싱, 쿼리
Nonrelational Databases
비관계형 데이터베이스는 key-value pairs, documents, graphs 등 다양한 storage models중 하나를 사용해 unstructured ways로 data 저장
- 스키마는 동적(dynamic)
행에 각 열에 대한 데이터 없어도됨
- 수평으로(horizontally) scale out(확장)
- 비정형·반정형 데이터로 작업 가능
가변구조 데이터의 요구를 처리못하는 관계형 데이터베이스의 한계를 극복하기 위해 설계되어 인기 높아짐
Nonrelational Databases Benefits
Nonrelational databases는 특정 데이터 모델을 위해 purpose-built
현대적 응용프로그램 구축을 위해 flexible schema
- Flexibility 유연성
- Scalability 확장성
- High performance 고성능
- Highly functional APIs 고기능성 API
usecase ex: provide personalized customizer experience-customer의 preference, desires, habits 동적인, 유연한 데이터도 저장 가능
Database Deployments and Management
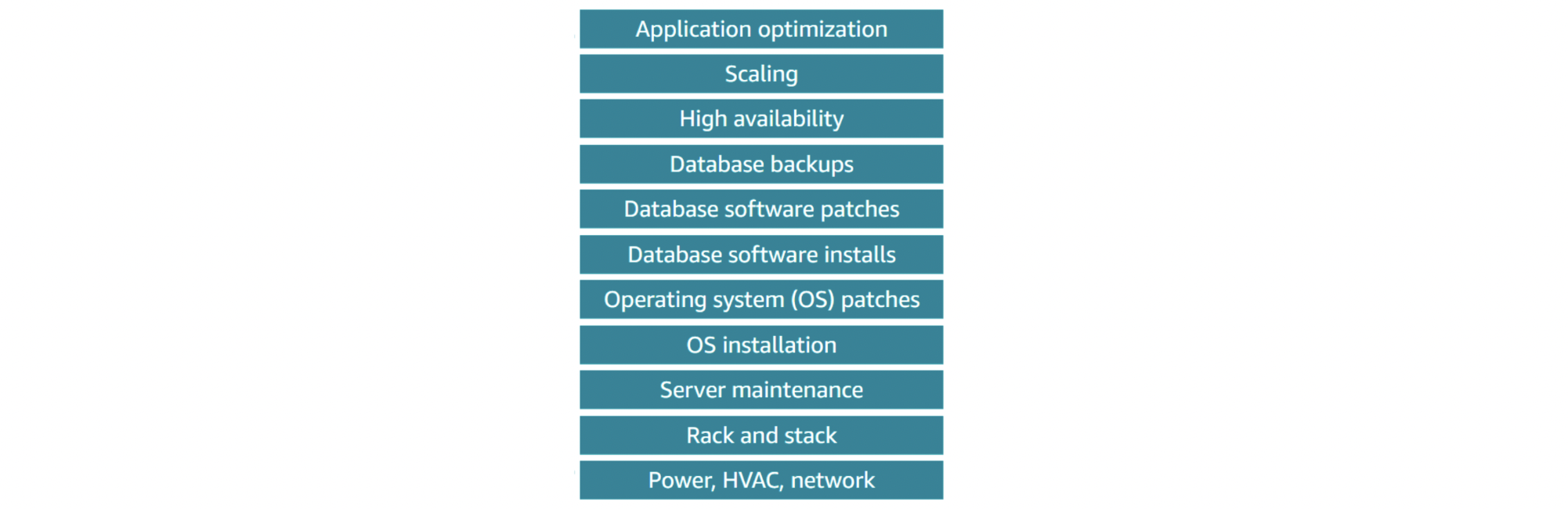
On-premises database (아래 그림 전체가 customer’s responsibility)
Hosted on Amazon EC2 (밑 4개를 AWS의 responsibility)
AWS managed (맨 위 하나만 customerd's responsibility)
AWS Databases
AWS는 고객의 요구사항에 맞게 15개 이상의 purpose-built databases 보유
– Amazon Relational Database Service (RDS)
– Amazon Aurora (MySQL, PostgreSQL)
– Amazon Redshift (데이터 웨어하우스 제품-Large dataset)
– Amazon DynamoDB (Non realational) (key-value)
– Amazon DocumentDB (document database service)
– Amazon Timestream (사물 인터넷(IoT) 및 운영 애플리케이션을 위한 고속의 확장 가능한 서버리스 시계열 데이터베이스 서비스)
– Amazon ElastiCache (완전 관리형 인메모리 데이터 저장소 및 캐시 서비스)(리더보드, realtime, cash)
– Amazon Neptune (관리형 그래프 데이터베이스 제품)
– Amazon Quantum Ledger Database (투명하고, 변경 불가능하며, 암호화 방식으로 검증 가능한 트랜잭션 로그를 제공하는 완전관리형 원장 데이터베이스) (System Records)
– Amazon Keyspaces (확장 가능하고 가용성이 높으며 관리되는 Apache Cassandra와 호환되는 데이터베이스 서비스) (엄청 fast)
Introduction to Amazon RDS
Amazon RDS(Amazon Relational Database Service): 관리 작업을 자동화, cost-efficient이고 용량을 조정할수있는(resizable capacity) 핵심 데이터베이스 서비스
- 관리 작업: hardware provisioning, database setup, patching, backups 등
대부분의 관계형 데이터베이스 use case의 요구에 맞게 여러 db엔진을 지원하는 완벽하게 관리되는 솔루션
- provision infrastructure, install and maintain database software 필요X
Amazon RDS storage는 늘어나는 database workloads에 대응하여 storage 용량을 자동으로 확장
Amazon RDS Engine
six database engines:

Amazon RDS Benefits
administer(관리) 용이함
- Amazon RDS가 완전히 관리됨
Available(가용성), durable(내구성)
- Multi-AZ 데이터베이스 인스턴스를 프로비저닝하면 Amazon RDS가 데이터를 다른 AZ의 대기 인스턴스로 동기적으로(synchronously) 복제
Highly scalable(확장성)
- 여러 Amazon RDS 엔진 유형을 사용하면 하나 이상의 read replicas 실행 가능
Fast
- 두 SSD-backed storage options 중 하나 선택 가능
Secure
- Amazon RDS로 db에 대한 네트워크 액세스 쉽게 제어 가능
Inexpensive
- 실제로 사용하는 리소스에 대해서만 비용을 지불
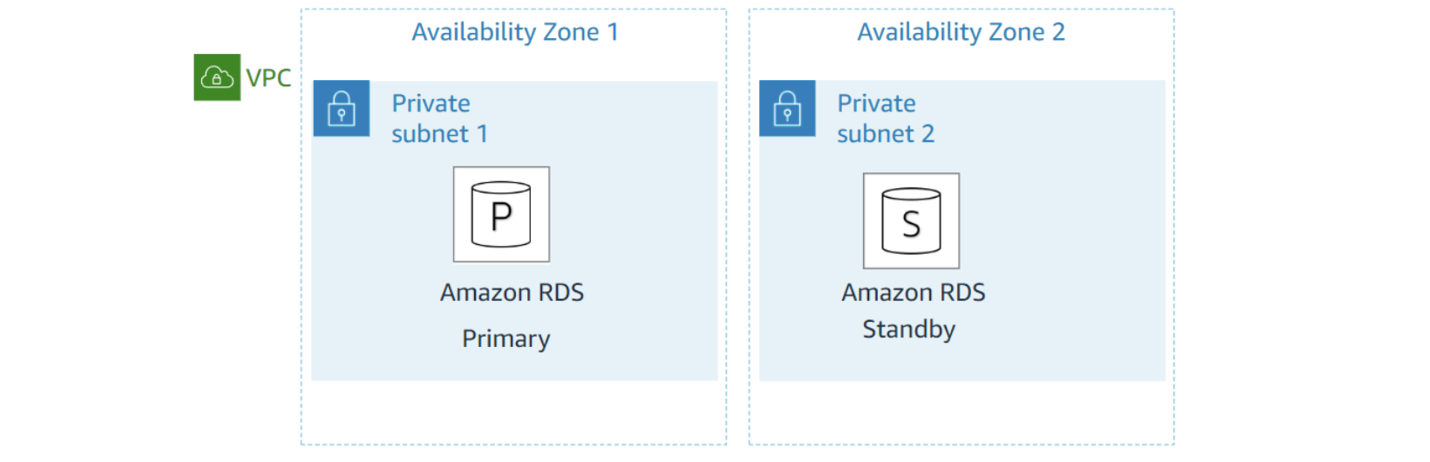
High Availability: Multi-AZ Deployments
redundancy(이중화)을 위해, Multi-AZ를 enable하면 Amazon RDS가 다른 AZ에 db의 보조 복사본(secondary copy)을 만듦(copy synchronously)
- primary db가 응답을 중지하면 db의 보조복사본이 대기 db로 사용됨
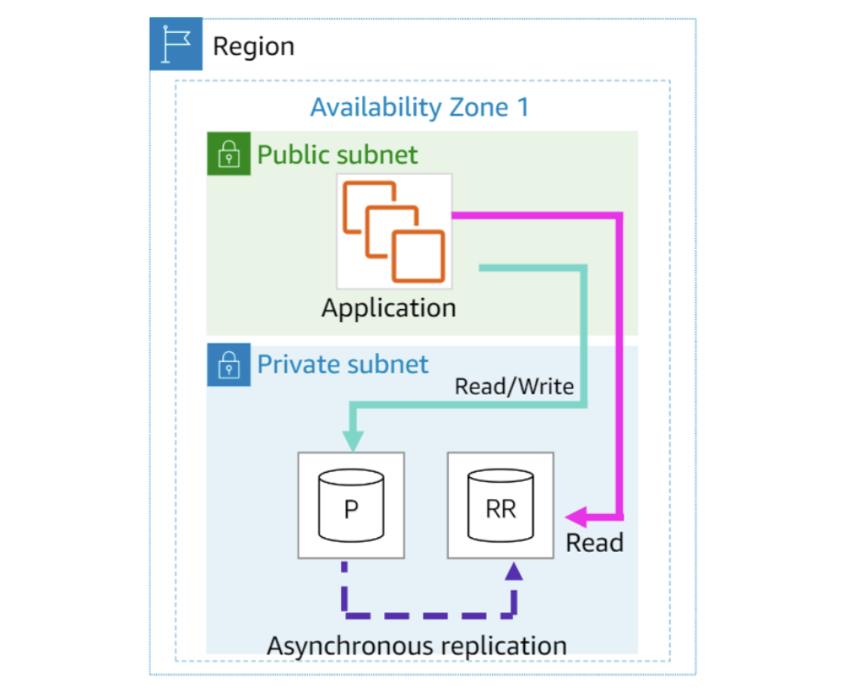
Amazon RDS Read Replicas
Amazon RDS가 read replica라는 특수 유형의 db 인스턴스 생성을 허용
원본 db instance에 대한 업데이트는 논리적 복제를 사용해 read replica에 비동기적(asynchronous)으로 복사됨
응용 프로그램의 read queries를 read replica으로 라우팅해 원본 db 인스턴스의 부하(load)를 줄일수 있음
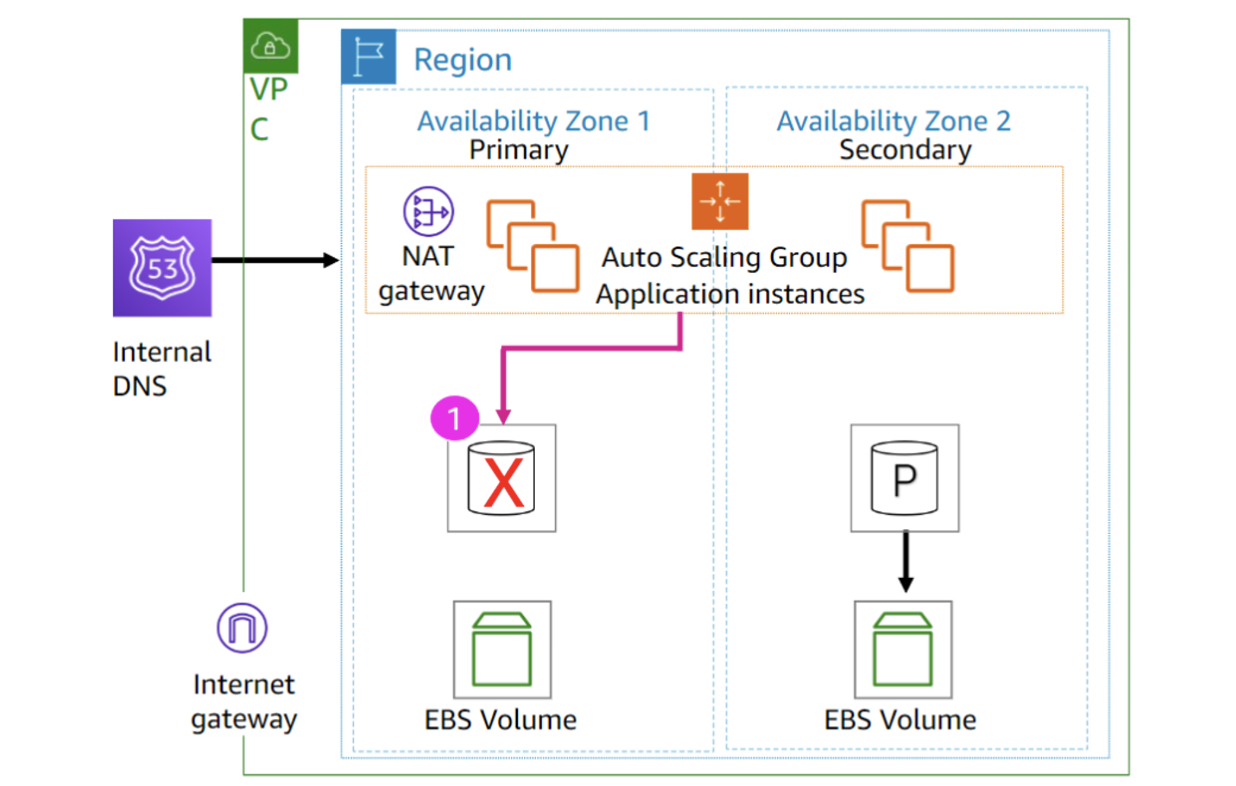
High Availability Example
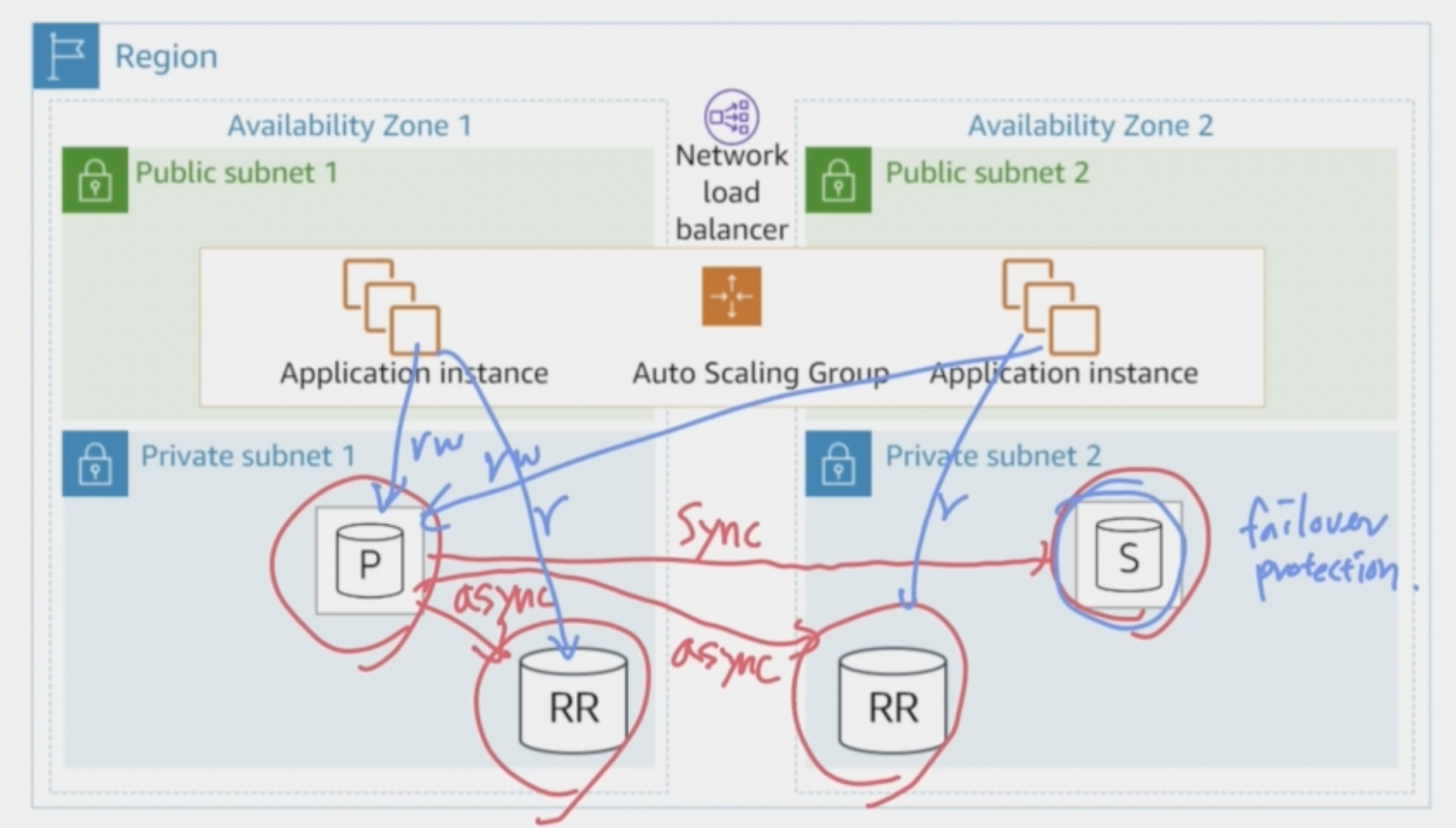 s엔 인스턴스들이 r,w 불가, S가 standby.
s엔 인스턴스들이 r,w 불가, S가 standby.
P가 down해서 S가 primary가 되면 또다른 S를 synchronous하게 생성함
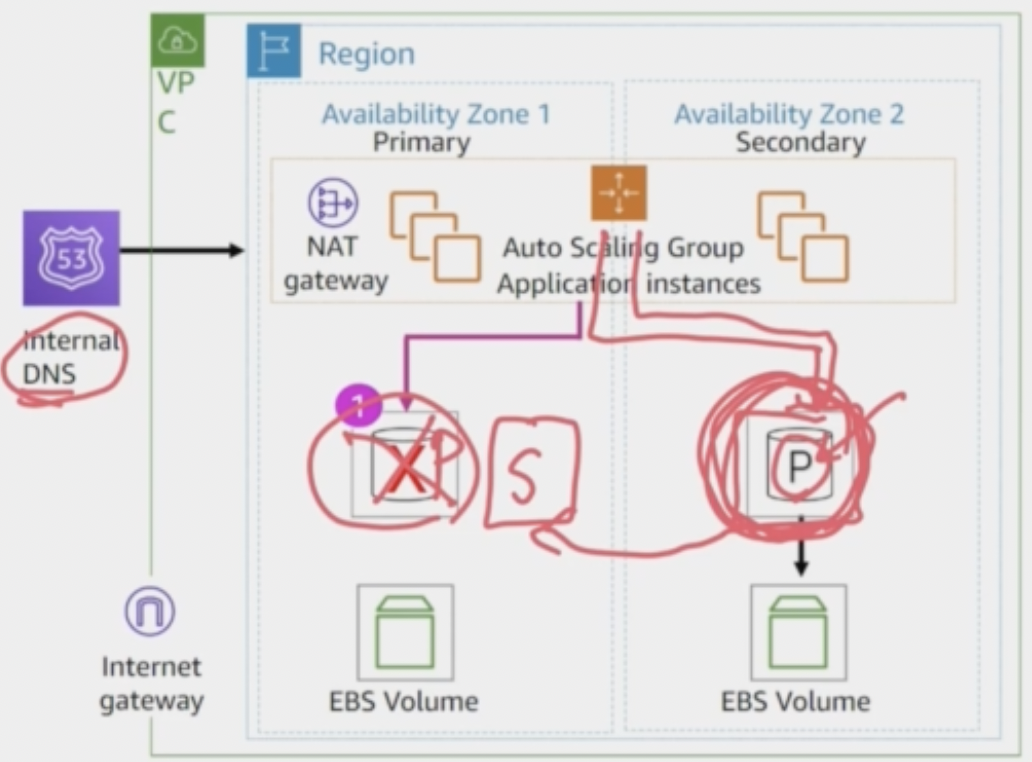
Amazon RDS High Availability Failover
Amazon RDS는 multi-AZ deployments(다중AZ구축)에 대한 가장 일반적인 장애 시나리오를 자동으로 감지
장애발생시
1 RDS가 주 인스턴스의 실패를 인식
2 DNS record가 업데이트
3 secondary는 primary instance로서 운영을 이어받음(takeover)
4 Multi-AZ 구성에서, 새로운 보조(secondary)가 자동으로 재구축
Multi-AZ vs Read Replicas
| Multi-AZ deployments | Read replicas | |
|---|---|---|
| Replication | Synchronous block-level replication – highly durable 동기식 블록 레벨 복제 – 내구성이 높음 | Asynchronous replication – highly scalable 비동기식 복제 – 확장성이 높음 |
| Instance availability | Only database engine on primary instance is active 기본 인스턴스의 db 엔진만 활성화됨 | All read replicas are accessible and can be used for read scaling 모든 읽기 복제본에 액세스할 수 있으며 읽기 확장에 사용 가능 |
| Backups | Automated backups are taken from standby 자동 백업은 대기 상태에서 수행 | No backups configured by default 기본적으로 구성된 백업 없음 |
| Regions and AZs | Always span two AZs within a Region 한 영역 내에 항상 2개의 AZ에 걸쳐 있음 | Can be within an AZ, cross-AZ, or cross-Region |
| Upgrades | Database engine version upgrades happen on primary db 엔진 버전 업그레이드는 기본으로 수행 | Database engine version upgrade is independent from source instance db 엔진 버전 업그레이드가 소스 인스턴스와 독립적임 |
| Failover(대체작동)/ promotion(승격) | Automatic failover to standby when a problem is detected 문제가 감지되면 대기 상태로 자동 페일오버 | Can be manually promoted to a standalone database instance 독립 실행형 db 인스턴스로 수동 승격 가능 |
Database Backups
Automatic backups
- default 활성화
- Amazon RDS는 db 인스턴스의 storage volume snapshots을 생성하여 전체 데이터베이스 및 트랜잭션 로그를 백업
- latency issues를 방지하기 위해 30-minute backup time 권장
- 백업 최대 35일까지 유지
- DB 인스턴스를 특정 시간으로 복원(restore)
Manual(수동) database snapshots
- DB 인스턴스의 스냅샷
- 35일 이상 소요
- 아마존 S3에 저장
- 삭제할 때까지 사용 가능
Amazon RDS Costs
What costs money?
- on-demand or reserved instances사용시 지불
- DB instance가 available해지면 과금 시작
- 가격은 시간당으로 나열
AWS 프리티어
- 월 750시간
DB 인스턴스에 돈 안쓰려면, DB 인스턴스 시간에 대한 비용이 추가로 청구되지 않도록 중지하거나 삭제
- DB 인스턴스가 중지되는 동안, 프로비저닝된 스토리지 및 백업 스토리지에 대해 비용을 청구 가능
Summary
▪ 데이터베이스 소개
– 다양한 형태의 데이터 구조, 데이터베이스의 기초, 관계형 데이터베이스 및 비관계형 데이터베이스에 대해 배움
– 관계형 데이터베이스는 구조화된 데이터에 가장 적합
– 비정형 데이터베이스는 비정형 데이터에 최적
▪ Amazon RDS 소개
– Amazon RDS, 복제본 읽기, 데이터베이스 백업 및 가격 책정에 대해 배움
– Amazon RDS는 완벽하게 관리되는 서비스입니다
– Amazon RDS를 사용하면 읽기 복제본이라는 특수한 유형의 데이터베이스 인스턴스 생성 가능
– 자동 백업 및 데이터베이스 수동 스냅샷을 사용하여 데이터베이스 백업
– Amazon RDS는 데이터베이스 인스턴스의 스토리지 볼륨 스냅샷을 생성
