- 닭 잡는 데 소 잡는 칼을 쓸 필요는 없습니다
- 더 나은 html구조 가진 모바일 버전 사이트 찾기
- 자바스크립트 파일 분석
- 원하는 정보가 url에 있기도
- 다른 웹사이트에 같은 데이터가 있을 가능성
이와같은 대안이 없다면 고급 HTML분석이 필요
복잡한 HTML페이지를 분석해서 원하는 정보만 추출하는 방법을 알아보자
2.다시 BeautifulSoup
속성을 통해 태그 검색, 태그목록 다루기, 트리 네비게이션 분석하기
css의 id와 class 속성 또한 큰 도움
ex) https://www.pythonscraping.com/pages/warandpeace.html (등장인물 대사 빨강, 이름 초록)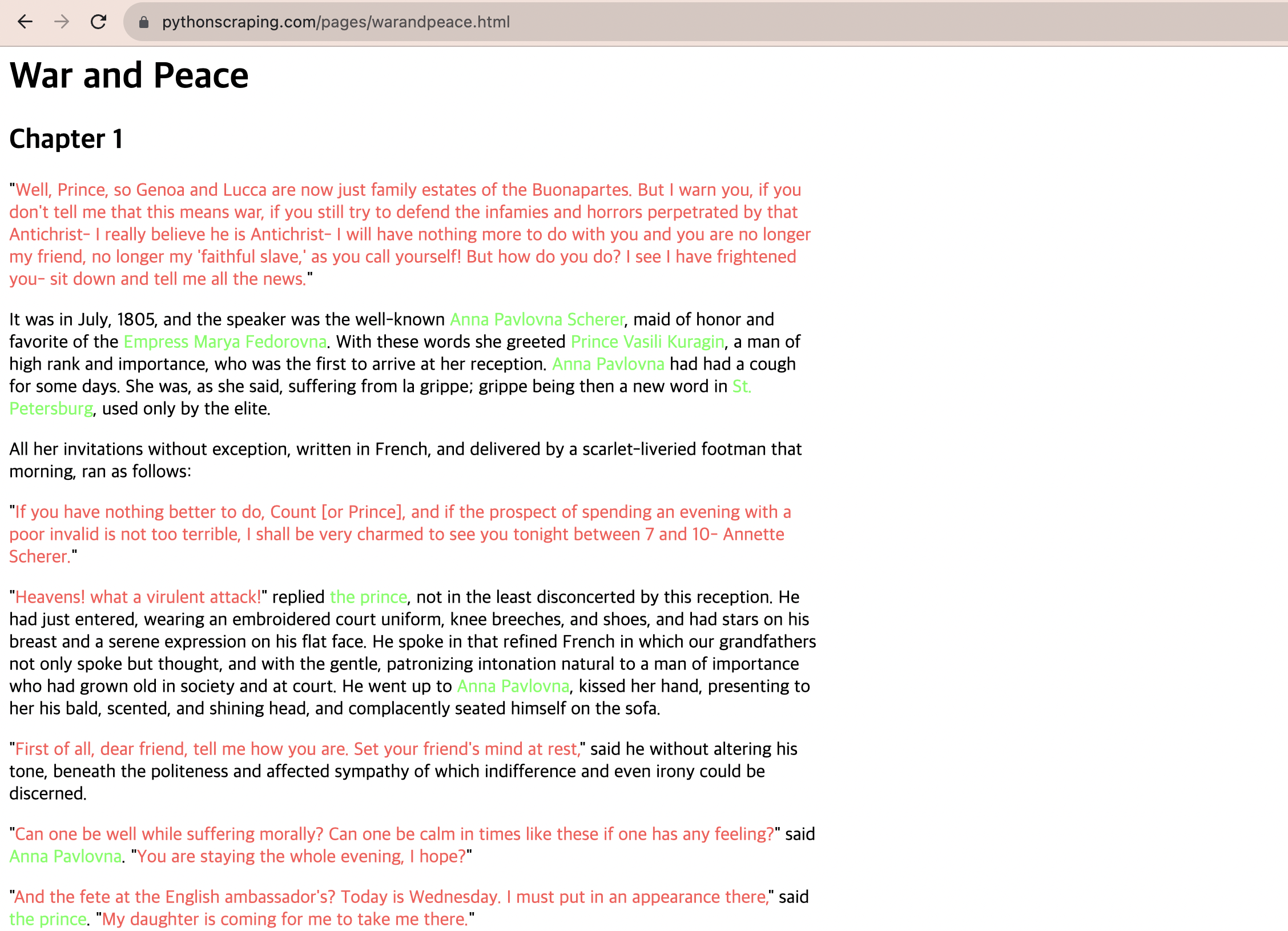
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen('https://www.pythonscraping.com/pages/warandpeace.html')
bs=BeautifulSoup(html,'html.parser')
nameList=bs.findAll('span',{'class':'green'})
for name in nameList:
print(name.get_text())결과:
bs.findAll(tagName, tagAttributes): 페이지의 태그 전체를 찾음
name.get_text(): 태그를 제외하고 콘텐츠만 출력
( 일반적으로 태그구조 가능한 유지. 최종 데이터 출력 저장 조작하기 직전에만 씀 )
find()와 findAll()
findAll( tag, attributes, recursive, text, limit, keywords )
find( tag, attributes, recursive, text, keywords )
(거의 tag와 attributes만 사용)
tag: 태그 이름인 문자열 / 태그 이름으로 이루어진 파이썬 리스트
ex. bs.findAll({ 'h1', 'h2', 'h3' })
attributes: 파이썬 딕셔너리 -> 그중 하나에 일치하는 태그 찾음
ex. bs.findAll('span', {'class' :{'green', 'red'}})
recursive: Boolean. 문서에 얼마나 깊이 찾아들어가고 싶은지
True -> 매개변수에 일치하는 태그를 찾아 자식, 자식의 자식을 검색 (default) (추천)
False -> 문서의 최상위 태그만 찾음
text: 텍스트 콘텐츠에 일치
ex. 태그에 둘러싸인 'the prince'가 몇번 나타났는가
-> nameList=bs.findAll(text='the prince') print(len(nameList)) => 7
limit: 페이지 항목의 처음 몇개 (find는 limit=1인 findAll)
keyword: 특정 속성이 포함된 태그를 선택
ex. title = bs.findAll(id='title', class_='text')
bs.findAll(id='text') == bs.findAll('',{'id':'text'}
class는 파이썬 예약어이므로 변수나 매개변수 이름으로 사용 불가
bs.findAll(class="green")
-> bs.findAll(class_ ='green') or bs.findAll('',{'class':'green'})
기타 BeautifulSoup 객체
이 네가지 객체가 전부이다
BeautifulSoup 객체
bs와 같은 형태로 사용
Tag 객체
리스트 호출 또는 BeautifulSoup객체에 find와 findAll을 호출해서 or 탐색해들어가기 (bs.div.h1)
NavigableString 객체
태그 안에 들어있는 텍스트를 의미
Comment 객체
주석 태그 안에 들어있는 HTML 주석 (<!--이런주석-->)
트리 이동
findAll함수는 이름과 속성으로 태그를 찾음 / 위치 기준으로 태그 찾으려면 트리 내비게이션 필요
BeautifulSoup 트리를 단방향으로 이동 ex bs.tag.subTag.anotherSubTag
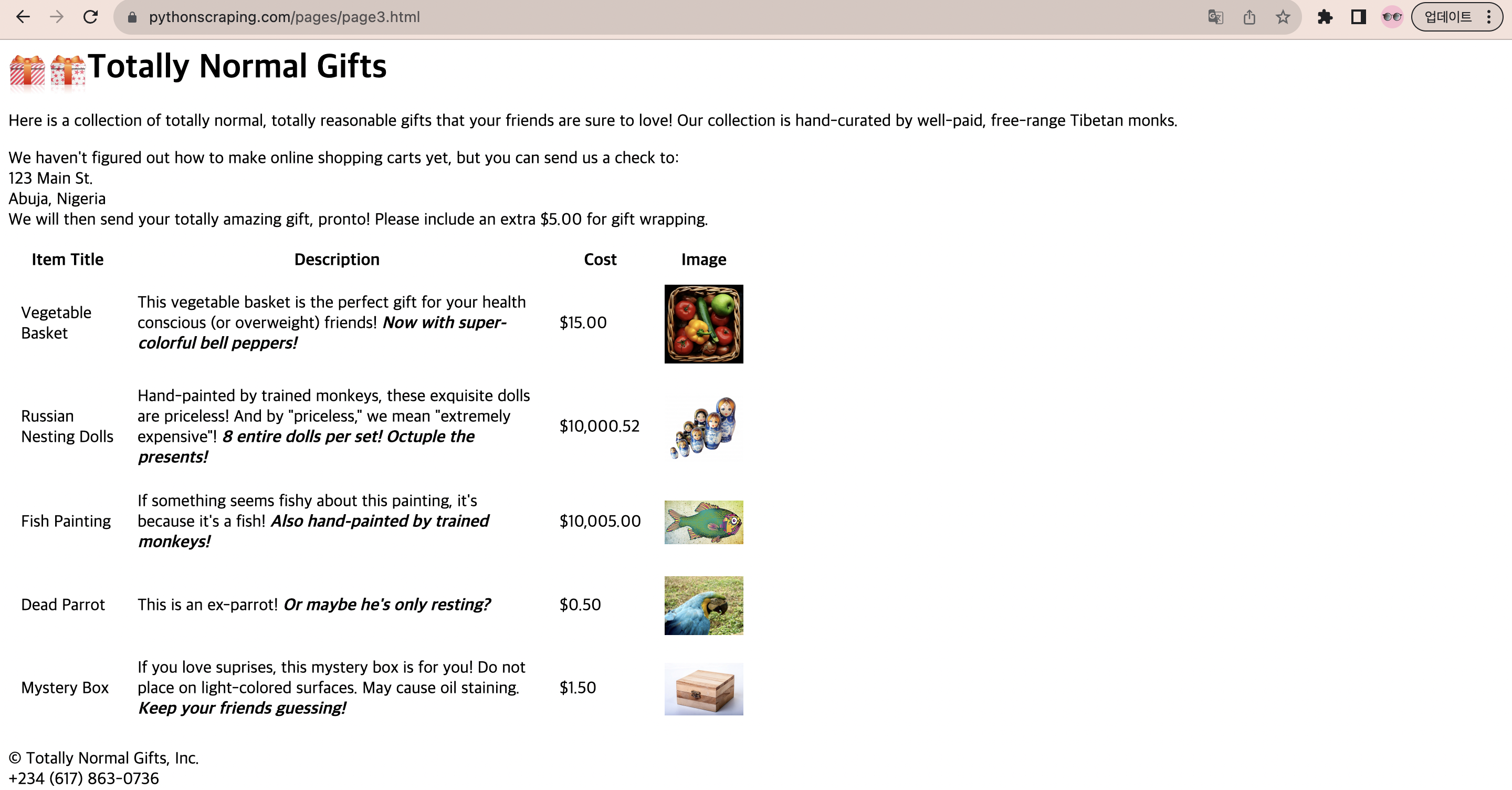
https://www.pythonscraping.com/pages/page3.html의 트리구조:
- html
- body
- div.wrapper
- h1
- div.content
- table#giftList
- tr
- th
- th
- th
- th
- tr.gift#gift1
- td
- td
- span.excitingNote
- td
- td
- img
- . . . 더 많은 테이블 행 . . .
- div.footer
자식과 자손
BeautifulSoup라이브러리에도 자식(children), 자손(descendants) 존재
bs.body.h1 -> body의 자손인 첫번째 h1 태그 선택, body 바깥의 태그는 동작X
bs.div.dinfAll("img") -> 문서의 첫번째 div태그의 모든 img태그 가진 자손
자식만 찾을땐 .children 사용
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
for child in bs.find('table',{'id':'giftList'}).children:
print(child)=> giftList테이블에 들어있는 제품 행 목록 출력

children대신 descendants함수를 쓰면 테이블에 포함된 태그가 20개 이상 출력됨
(자식과 자손 구분이 중요)
형제 다루기
next_siblings() - 테이블에서 데이터를 쉽게 수집 가능 / 특히 테이블에 타이틀 행이 있을때 유용
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
for siblibg in bs.find('table',{'id':'giftList'}).tr.next_siblings:
print(siblibg)결과: 첫번째 테이블 행을 제외한 모든 제품 행 ( 객체는 저기 자신의 형제가 될 수 없음 )
다음형제 반환
(페이지 레이아웃이 변할수 있으니 가능하면 태그 속성 사용해서 선택을 명확하게)
previous_siblings: 원하는 형제 태그 목록의 마지막에 있는 태그를 쉽게 선택할 때 사용
previous_sibling,next_sibling: 태그 하나만 반환
부모 다루기
.parent, .parents
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
print(bs.find('img',{'src':'../img/gifts/img1.jpg'}).parent.previous_sibling.get_text())이미지를 찾아서 부모태그를 선택한 후 이미지의 이전 형제를 선택, 그 안의 텍스트 선택
- <tr>
- <td>
- <td>
- <td>
- "$15.00"
- <td>
- <img src='../img/gifts/img1.jpg'>
주요 개념 요약
BeautifulSoup 객체, Tag 객체, NavigableString 객체, Comment 객체
findAll(), find()
children, descendants
next_siblings, previous_siblings, next_sibling, previous_sibling
.parent, .parents
