Estimator 이해 및 fit(), predict()메서드
fit(): ML 모델 학습
predict(): 학습된 모델의 예측
Classifier: 분류알고리즘 구현한 클래스
Regressor: 회귀 알고리즘을 구현한 클래스
Estimator 클래스:Classifier+Regressor - 지도학습의 모든 알고리즘 구현한 클래스
evaluation 함수( cross_val_score() ), 하이퍼 파라미터 튜닝을 지원하는 클래스( GridSearchCV )가 Estimator를 인자로 받음. 인자 Estimator가 함수내에서 fit(), predict() 호출
비지도학습(차원 축소, 클러스터링, 피처 추출)도 대부분 fit(), transform() 적용
비지도학습의 fit()-입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전구조를 맞추는 과정 (학습X)
transform()으로 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등의 실제 작업
fit_transform()-추후설명
사이킷런의 주요 모듈
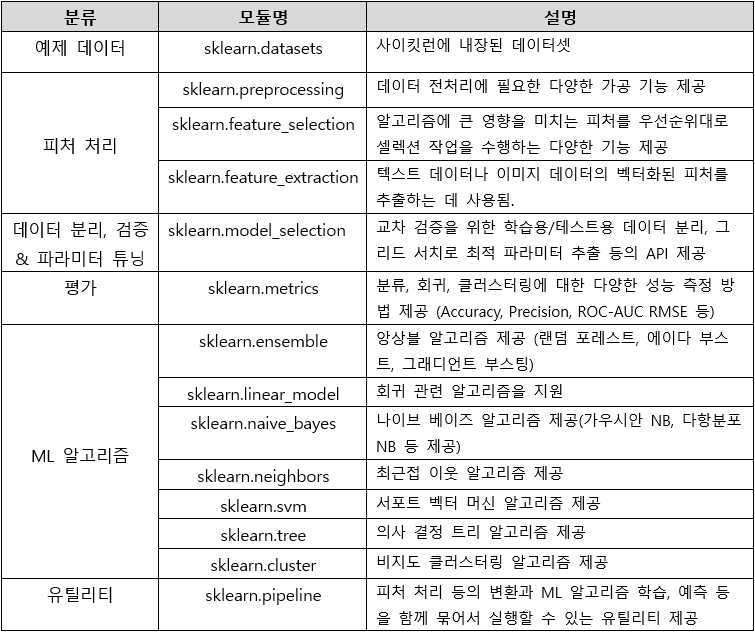
내장된 예제 데이터 세트
사이킷런에 외부 웹사이트에서 내려받을 필요 없이 예제로 활용할 수 있는 좋은 데이터 세트 내장됨
(분류나 회귀를 위한 예제용도의 데이터 세트/분류나 클러스터링을 위해 표본 데이터로 생성될수 있는 데이터 세트)
분류나 회귀 연습용 예제 데이터
| API명 | 설명 |
|---|---|
| datasets.load_boston() | 회귀용도, 미국 보스턴 집 피처, 가격 |
| datasets.load_breast_cancer() | 분류 용도, 위스콘신 유방암 피처, 악성/음성 레이블 데이터 |
| datasets.load_diabets() | 회귀 용도, 당뇨 데이터 세트 |
| datasets.load_digits() | 분류 용도, 0~9숫자 이미지 픽셀 데이터 |
| datasets.load_iris | 분류 용도, 붓꽃 피처 |
fetch계열 명령: 인터넷에서 내려받아 sicikit_learn_data라는 서브 디렉터리에 저장 후 불러들이는 데이터
fetch_covtype() # 회귀 분석용 토지 조사 자료
fetch_20newsgroupw() # 뉴스 그룹 텍스트 자료
fetch_olivtti_faces() # 얼굴 이미지 자료
fetch_lfw_people() # 얼굴 이미지 자료
fetch_lfw_pairs() # 얼굴 이미지 자료
fetch_rcv() # 로이터 뉴스 말뭉치
fetch_mldata() # ML 웹사이트에서 다운로드구성
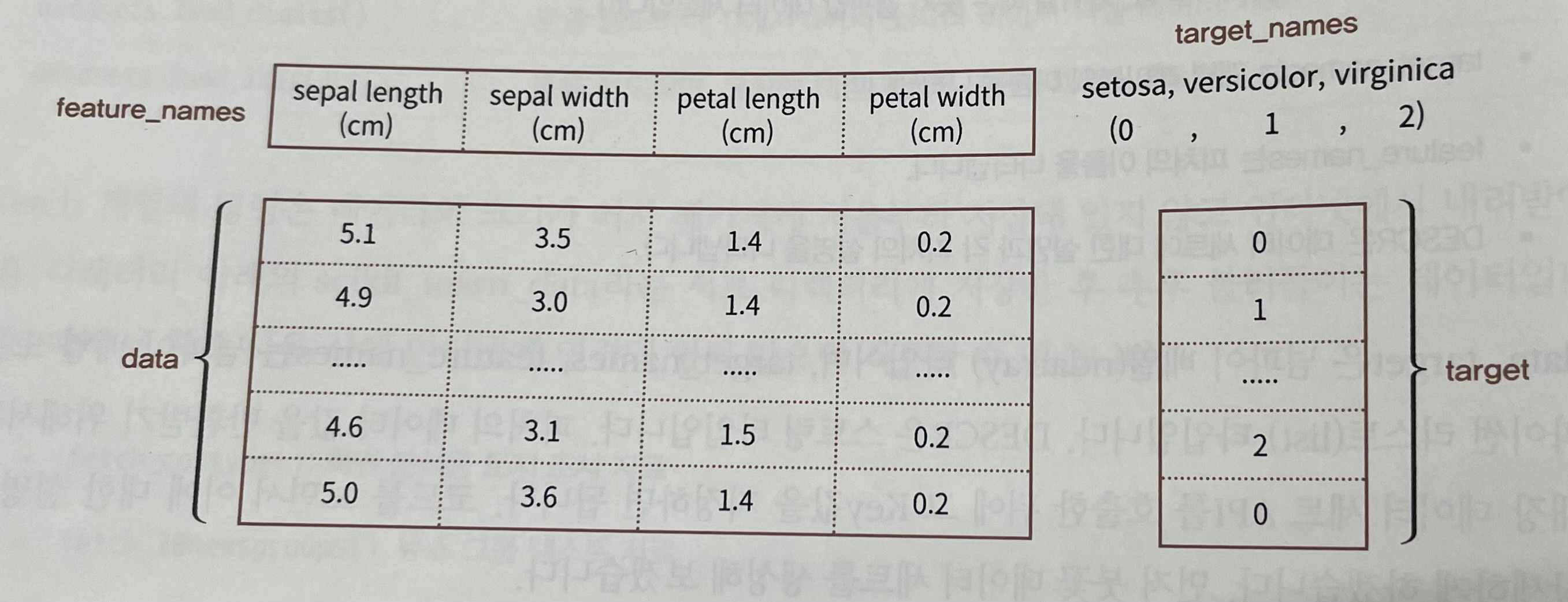
data : 피처의 데이터 세트 (넘파이 배열)
target : 분류레이블 값, 회귀숫자 결과값 데이터 세트 (넘파이 배열)
target_names : 개별 레이블의 이름 (넘파이 배열 또는 파이썬 리스트)
feature_names : 피처의 이름 (넘파이 배열 또는 파이썬 리스트)
DESCR : 데이터 세트에 대한 설명과 각 피처의 설명 (스트링)
ex 붓꽃 데이터 세트
생성
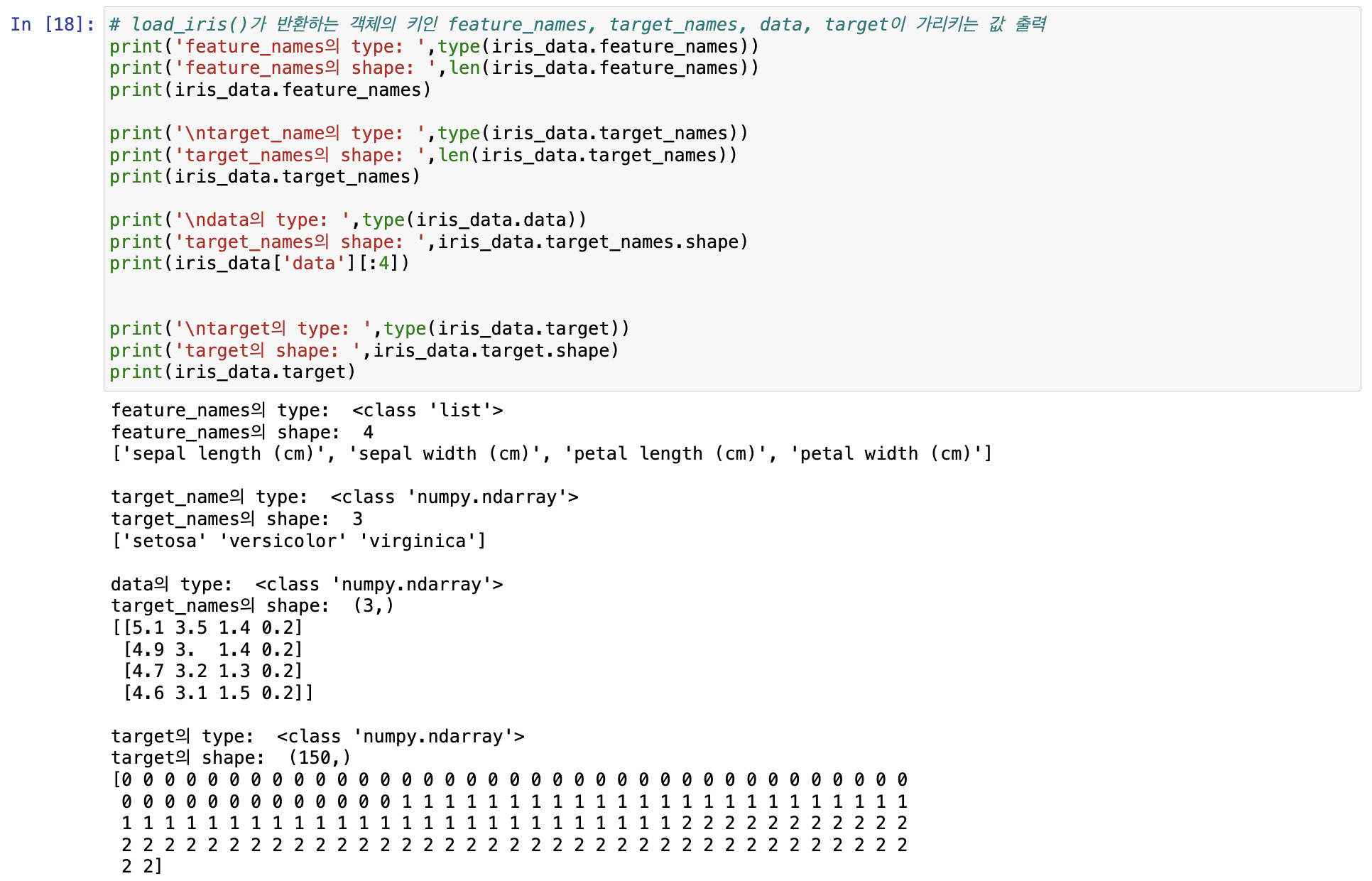
Bunch: 파이썬 딕셔너리 자료형과 유사

key값 확인
데이터 키(=피처들의 데이터값)
데이터 세트.data or 데이터 세트['data']
(다른 구성요소들도 동일)
비지도 학습 (분류와 클러스터링)을 위한 표본 데이터 생성기
datasets.make_classifications() # 분류를 위한 데이터 세트
# 특히 높은 상관도, 불필요한 속성 등의 노이즈 효과를 위한 데이터를 무작위로 생성
datasets.make_blobs() # 클러스터링을 위한 데이터 세트를 무작위로 생성
# 군집 지정 개수에 따라 여러 가지 클러스터링을 위한 데이터 세트를 쉽게 생성