
들어가며
Spring Boot를 활용하며 항상 Layered Architecture를 활용하며 서버를 개발해왔다. 개발을 하면서 항상 어떤 일을 Controller에 주고, 어떤 일을 Service에게 주어야 할지, 어떻게 로직을 각 Layer에 맞게 적절하게 분배할 지, 도메인이 처리하도록 책임을 위임할 지, Service가 모두 처리하도록 할 지 등 여러 가지 고민을 해왔다. 이에 Controller, Service, Repository가 하는 일을 명확히 할 겸, Layered Architecture에 대해 공부해보았다. 이번 시간에는 Layered Architecture에 대한 개념과 Spring Boot에서 사용하는 사례를 살펴보고 내가 했던 고민과 해결방법을 공유하려 한다.
Layered Architecture에 대한 개념
Layered Architecture는 소프트웨어 시스템을 여러 개의 논리적인 계층으로 분리하는 방법이다. 계층을 분리하는 이유는 무엇일까? 이미 알고 있겠지만 관심사의 분리라고 생각한다. 각 계층은 특정한 역할과 책임을 가지며, 상위 계층은 하위 계층을 사용하여 기능을 수행한다. 이러한 계층 구조는 시스템의 복잡성을 줄이고 유지보수성을 향상시킨다. 어떻게 복잡성을 줄이고 유지보수성을 향상시키는 지는 장단점에서 살펴보자.
관심사의 분리는 한편으로는 비즈니스 로직의 크기에 따라 고민이 생기기도 한다. 예를 들어, 복잡하지 않은 api 같은 경우에는 controller는 단순히 service의 로직을 메소드로 wrapping하는 용도가 되고, 단순 layer에서 i/o 작업만 일어나기 때문에 이걸 제대로 활용하고 있는게 맞나? 하는 생각이 들기 때문이다. 자세한 내용은 추후 고민파트에서 살펴보자.
일반적으로 Layered Architecture는 다음과 같은 계층으로 구성된다. 계층의 개수에 따라 n-계층이라고 부르기도 한다. 다음은 4-계층 Layered Architecture이다.
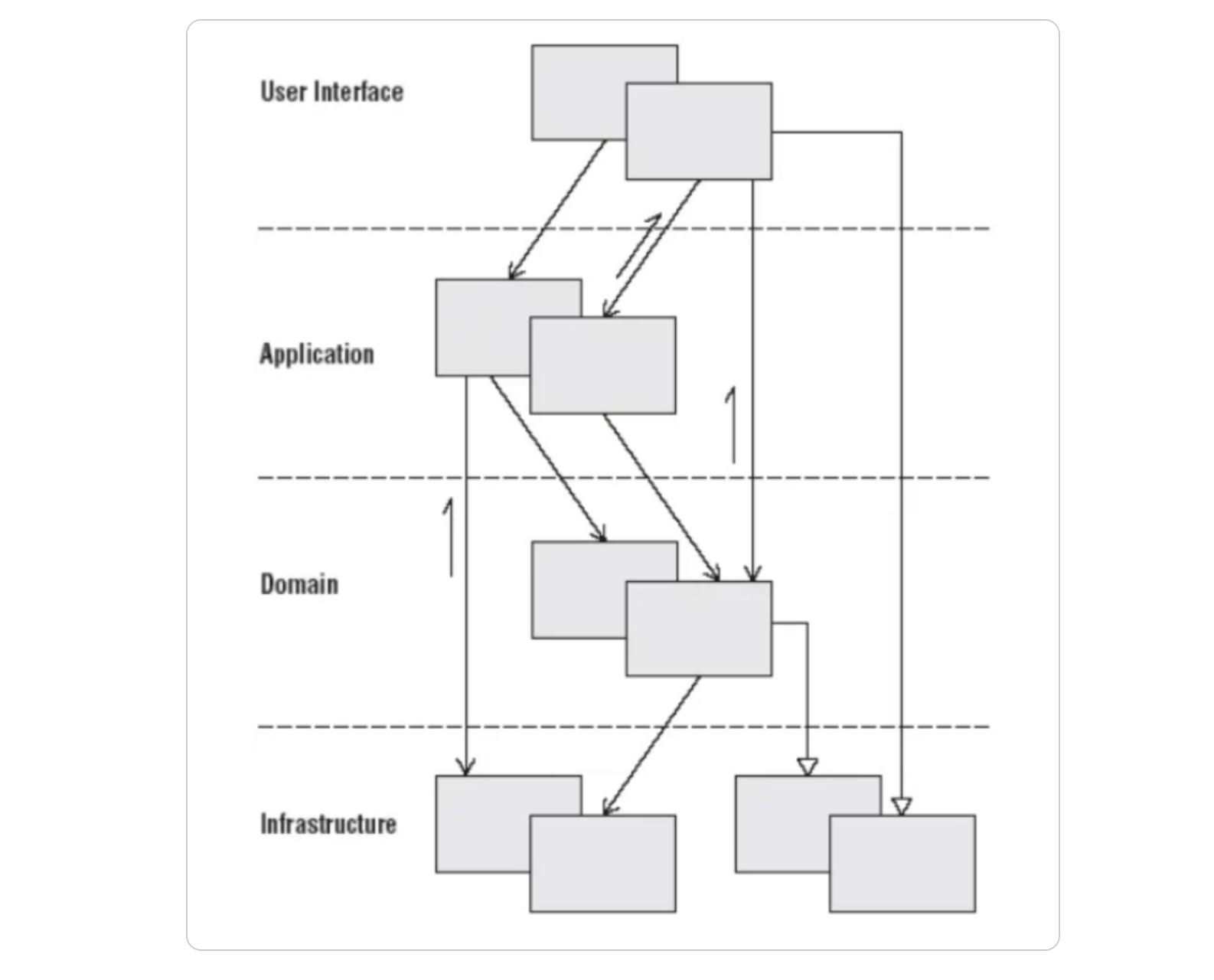
- Presentation Layer(User Interface Layer)
- 사용자와의 상호작용을 처리하고, 화면 표시 및 입력 처리 등과 같은 사용자 인터페이스 역할을 담당합니다.
- 화면을 직접 서비스하지 않는다면 클라이언트로부터 요청을 받고, 응답하는 API를 정의합니다.
- Application Layer
- 비즈니스 로직을 처리하고, 사용자 요청을 해석하여 하위 계층에 전달합니다.
- 실제 비즈니스 로직보단 고수준(high-level)에서 추상화 된 어플리케이션 기능을 표현합니다.
- Domain Layer
- 시스템의 핵심 비즈니스 규칙과 개념을 포함하며, 데이터 유효성 검증 및 엔터티 관리 등을 수행합니다.
- Infrastructure Layer
- 기술 종속성이 강한 구현체를 제공하는 계층입니다.
- 그 외에도 영속성 프레임워크, 데이터베이스, 외부 시스템과의 통합, 이벤트 리스너(listener) 등이 있습니다.
이러한 계층 구조를 통해 시스템은 상위 계층이 하위 계층에게 의존하며, 상위 계층은 하위 계층을 모르는 것이 원칙입니다. 이로써 각 계층은 독립적으로 개발하고 테스트할 수 있으며, 변경이 필요한 경우에도 다른 계층에 영향을 미치지 않을 가능성이 높습니다.
Layered Architecture의 장단점
1. 장점
- 추상화로 가독성 있게 코드를 작성할 수 있다.
- 하위 계층의 메소드 네이밍을 직관적으로 한다면, 상위 계층의 메소드에서는 하위 계층의 메소드까지 들어가보지 않아도 전체적인 흐름을 파악하여 이 메소드가 어떤 일을 하는 지 알 수 있다.
- 서로 다른 계층으로 분리하여 전체적인 시스템 결합도를 낮춥니다.
- 각 계층을 모듈(module)로 관리하기 때문에 해당 계층의 변경 사항을 최소화할 수 있습니다.
- 상위 계층에서 하위 계층을 사용할 때 구현체가 아닌 인터페이스를 사용하면 다형성을 높일 수 있다.
- 재사용성을 높입니다.
- 상위 계층에서 하위 계층에서 만들어진 여러 객체들의 메소드를 재사용함으로써 로직의 재사용성을 높일 수 있다.
- 주의점!
- 하위 계층에서 상위 계층의 메소드 하나만을 목적으로 구현하게 되면 재사용성이 떨어진다. 예를 들어, repository에서 jpql을 사용해 여러 조인을 사용해 dto를 반환하는 메소드가 있다고 치자. 해당 메소드는 ‘특정 용도’에 제한되어 있기 때문에 상위 계층의 다른 메소드에서 해당 메소드를 사용할 확률이 떨어진다.
- 이는, 인프라스트럭처 계층에서 view까지 신경을 썼기 때문이다. 이렇게 되면 dto 내용이 바뀔 때마다 쿼리가 바뀌어야 한다. (select 하는 값이 바뀔테니까)
- 쿼리 최적화 등을 위해 특수한 목적의 쿼리를 작성할 수 있겠지만, 재사용성을 고려하며 작성해야 한다.
- 테스트 용이성
- 각 계층에서 필요한 다른 계층의 의존성은 테스트 더블을 사용함으로써 독립적으로 테스트할 수 있다.
- 계층별로 테스트할 수 있기 때문에 시스템의 일부를 테스트하거나 디버깅하기가 쉽다.
2. 단점
- 모듈성과 성능의 trade-off
- 계층별로 결합도를 낮추기 위해 모듈성을 신경쓰게 되면 계층끼리 매개변수를 통해 데이터를 교환할 때 캐스팅하거나 dto로 변환하거나 등 부가적인 처리 과정이 추가될 수 있다.
- 데이터의 크기가 크고 복잡해지면 이러한 처리 과정이 시스템에 오버헤드가 될 수도 있다.
- 유연성 제한
- 하위 계층의 변경이 상위 계층에 영향을 최소화해야 한다고 했지만, 메소드의 매개변수가 바뀐다거나 등 어쩔 수 없이 상위 계층에서도 수정해야하는 사항이 발생할 수 있다. 즉, 해당계층의 위 아래 계층은 강한 의존성이 있을 수 있다.
- 열린 계층을 사용하게 되면 하위 계층의 수정에 대한 영향이 더 커지므로, 대부분 닫힌 계층을 사용한다.
Spring Boot에서 흔히 사용하는 Layered Architecture
보통 우리는 3-계층을 사용한다. Controller Layer, Service Layer, Repository Layer이다.
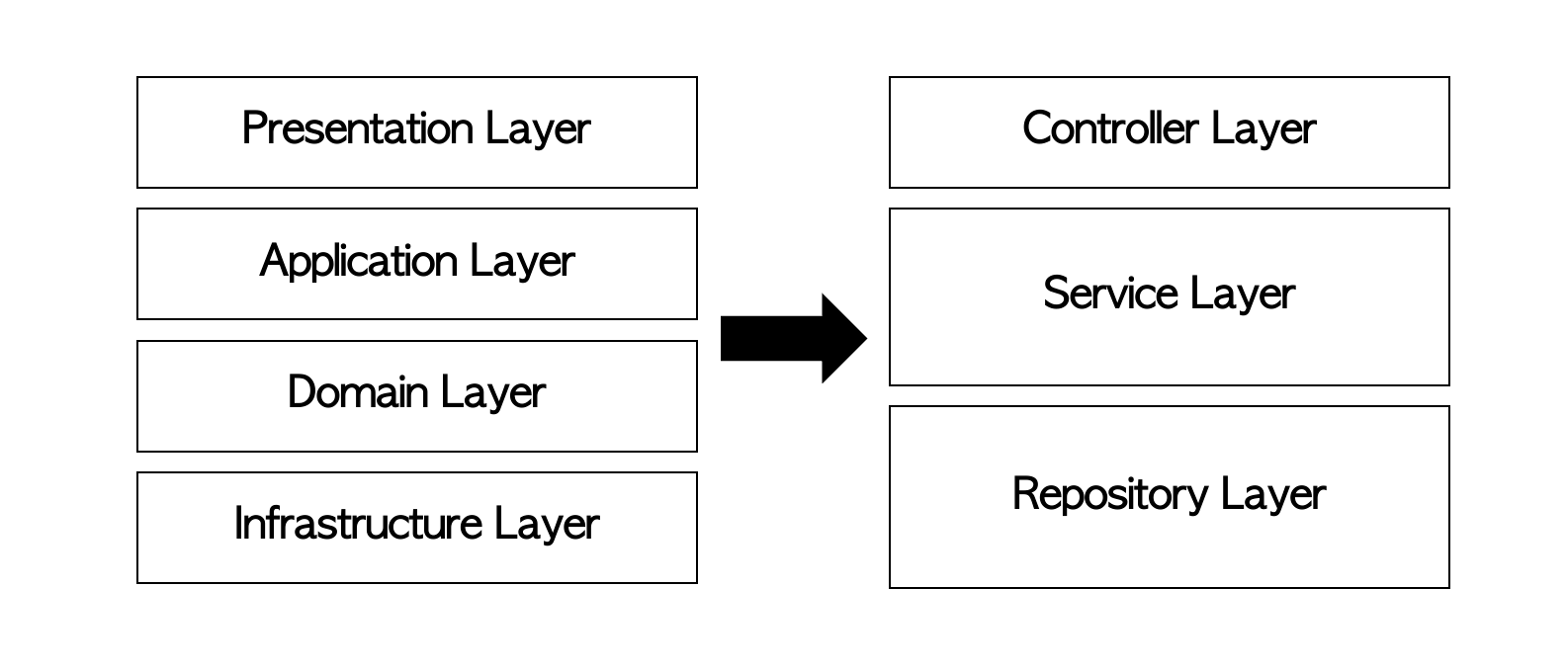
이전의 4-계층을 Spring Boot에서 흔히 사용하는 패턴을 보면 이런 식인 것 같다.
1. Controller
Controller Layer에서 사용자의 요청을 받아들이고 Service Layer를 호출하여 비즈니스 로직을 처리 후, 프론트에게 보내줄 response dto를 적절히 만들어서 보낸다.
@PostMapping
public ResponseEntity<ApiResponse<RecipeResponse>> createRecipe(@CurrentUser User user, @RequestBody RecipeCreateRequest recipeCreateRequest){
recipeService.deleteCancelledFiles(recipeCreateRequest);
RecipeResponse response = recipeService.createRecipe(user, recipeCreateRequest);
ApiResponse apiResponse = ApiResponse.builder()
.message("레시피 생성 성공")
.status(HttpStatus.CREATED.value())
.data(response)
.build();
return ResponseEntity.ok()
.body(apiResponse);
}2. Service
Service Layer는 비즈니스 로직을 처리하는 역할을 한다. Repository Layer를 호출하여 데이터베이스와 상호작용한다. 하지만 비즈니스 로직이 커질 경우 다른 Service를 호출하기도 한다. 또한, 도메인 객체를 직접 생성하고 도메인 로직을 호출하기 때문에 Service Layer는 4-계층에서 Domain Layer의 일부라고 볼 수 있다.
@Transactional
public RecipeResponse createRecipe(User user, RecipeCreateRequest request) {
Util.validateDuplication(request.getIngredients(), request.getOptionalIngredients());
List<Ingredient> requiredIngredients = ingredientSimpleService.getIngredientsByIds(request.getIngredients());
List<Ingredient> optionalIngredients = ingredientSimpleService.getIngredientsByIds(request.getOptionalIngredients());
Recipe recipe = recipeRepository.save(createRecipeEntity(user, request));
saveNecessaryIngredientsOfRecipe(recipe, requiredIngredients);
saveOptionalIngredientsOfRecipe(recipe, optionalIngredients);
stepService.saveStepsForRecipe(recipe, request.getSteps());
return RecipeResponse.builder()
.recipeId(recipe.getId())
.build();
}3. Repository
Repository Layer는 데이터베이스나 외부 시스템과의 상호작용을 담당한다. Repository는 도메인 객체를 영속화하며, 쿼리를 통해 데이터 조작을 수행한다. 이 때문에 주로 infrastructure layer에 해당한다고 볼 수 있지만, 도메인 객체를 조회하고 db에 저장하는 기능을 제공하므로, domain layer에도 일부 속한다고 볼 수 있다.
엄연히 보면 우리가 만든 repository interface 자체는 domain layer에 속하고, spring boot에서 이를 구현한 클래스가 infrasturcutre layer에 해당하여 repository는 domain layer와 infrastructure layer의 매개체라고 볼 수 있다. 하지만 개발자 입장에서 봤을 때 repository layer에서 db 상호작용을 주로 맡으니 infrastruture layer에 해당한다고 봐도 무리가 없을 것 같다.
public interface RecipeRepository extends JpaRepository<Recipe, Long> {
@EntityGraph(
attributePaths = {"author", "steps"}, type = EntityGraphType.FETCH
)
Optional<Recipe> findAllElementsById(Long id);
boolean existsById(Long recipeId);
@Query(value = "select distinct r from Recipe r join fetch r.author ",
countQuery = "select count(r) from Recipe r")
Page<Recipe> findRecipes(Pageable pageable);
}Layered Architecture를 사용하면서 했던 고민
1. Validation은 어느 Layer에서 하는 것이 적합한가?
데이터 입장에서 보면 Validation은 많이 하면 할수록 좋다. 하지만 모든 layer에서 Validation하게 된다면, 이미 validation을 통과한 데이터임에도 불구하고, 하위 계층에서 같은 로직을 반복하게 된다. 이는 성능 저하로 이어질 수 있다. 또한, 중복 코드가 발생하여 code smell이 난다.
내가 주로 활용하는 방법은 Controller에서는 null인지 아닌지 등 간단한 validation을 bean validation을 통해 진행하고, Service에서 repository를 활용한 validation과 비즈니스 로직과 관련된 추가적인 validation을 진행하는 것이다. 예를 들어, userId를 매개변수로 받아 이 userId가 db에 존재하는 id인지 아닌지를 service에서 검사하게 한다. 그 외에 비즈니스 로직과 관련된 validation은 모두 service가 담당하도록 했다.
- 그렇게 한 이유는?
- null 검사는 단순한 데이터 검증이지만 기타 validation들은 비즈니스 로직의 일부라고 판단했기 때문이다.
- 또한, 유효한 userId인지 검사하는 메소드를 service에서 만들어서(ex. getUserById) controller에서 이를 호출하게 한 후, 다시 메소드의 매개변수로 넘기는 방법이 있는데 이는 entity가 presentation layer에 드러나기 때문에 적합하지 않다고 생각했다.
- entity가 presentation layer에 드러나는 것 자체가 entity에 대한 조작 가능성을 열어두는 것이고(open-in-view=false이더라도) 이는 해당 계층의 책임을 위반하는 행위라고 보았다.
- 또한, entity가 presentation layer에 드러나면 entity 수정의 영향이 presentation layer까지 미칠 것이다. request와 response를 관리하는 controller에 entity가 있다는 것 자체가 presentation layer와 거리가 멀다.
- 무엇보다, controller 입장에서 validation은 관심이 없다. controller는 로직의 흐름을 보는 곳이지, 방법을 보는 곳이 아니라고 판단했다. validation은 비즈니스 로직을 구현하기 위해 필요한 데이터 검증 방법이기 때문이다.
2. 어디까지 숨기고 어디까지 드러낼거야
그렇게 비즈니스 로직을 service layer에 숨기고 개발하다보면, controller는 여러 서비스를 조합해서 흐름을 나타내는 곳인데, 이를 망각하고 하나의 api를 위한, 하나의 api에 의한 service 메소드를 우후죽순 만들어낼 때가 있다. 즉, 너무 많은 내용을 wrapping하는 경우다. 이러면 해당 service 메소드의 재사용성이 떨어질 수도 있고, 책임을 벗어난 다른 일까지 담당하는 것일 수도 있다. Layered Architecture의 장점으로 재사용성이 있는데, 재사용성이 높으려면 적절하게 숨기고 적절하게 드러내야 하는 것 같다.
3. 간단한 Service 메소드의 재사용성을 늘리고 싶다.
@Transactional(readOnly = true)
public User getUserById(Long userId) {
return userRepository.findByIdAndIsQuit(userId, false).orElseThrow(() -> new NotFoundException(USER_NOT_FOUND));
}굉장히 기본적인 UserService의 메소드다. userId를 검증하는 것은 다른 domain에서도 많이 사용된다. 그렇기 때문에 ‘userRepository.findByIdAndIsQuit(userId, false).orElseThrow(() -> new NotFoundException(USER_NOT_FOUND));’ 이 코드가 많은 도메인에서 중복이 될 것이다. 나는 getUserById라는 메소드를 이미 만들놨다면 해당 메소드를 재사용하는 것이 맞지 않을까 생각하게 되었다. 또한, 이렇게 내용이 간단한 메소드야 말로 재사용에 최적화된 메소드가 아닌가하는 생각이 들었다. (메소드 크기가 커질수록 해당 로직에 특화되었다는 것이니 재사용되기가 어렵지 않겠는가)
그럼 이 메소드를 다른 도메인에서 사용하고 싶다면 UserService를 의존성 주입해야 한다. 이 메소드를 사용하고 싶어 UserService를 DI 받게 될 때 발생하는 문제는 두 가지다.
- 배보다 배꼽이 커진다.
- getUserById를 사용하고 싶은 다른 도메인을 예를 들어 OrderService라고 하자. OrderService에서 UserService를 DI 받게 되면, 단순히 getUserById만 사용하고 싶었던건데 다른 메소드들에 대한 접근 권한이 생기는 것이다.
- 이런 식으로 getUserById를 위해 다른 도메인에서 UserService를 DI 받게 되면, 모든 다른 도메인에서 UserService의 다른 메소드들에 접근할 수 있게 될 것이다.
- 객체지향관점에서 OrderService가 UserService가 있어야 만들어질 수 있다는 것인데 말이 되지 않는다.
- Order는 User가 있어야 만들어질 수 있는게 맞는데요? (Domain말고 Service를 이야기 하고 있는 것이다.)
- 순환 참조가 생길 수도!
- UserService에서 OrderService를 이용하는 비즈니스 로직이 기존에 존재한다고 하자. 예를 들어 회원가입하면 특정 무료 상품을 제공하기 위해 무료 상품 주문을 OrderService로 진행할 수가 있겠다. 이럴 때, 순환참조가 발생할 수 있다.
- 물론, OrderService를 회원가입 Controller가 DI 받으면 해결되지만, 요지는 기존에 존재하는 비즈니스 로직에 영향을 미칠 수 있다는 것이다. (일반적으로 Controller가 Service를 조합하여 사용하지만, 비즈니스 로직이 커지면 Service에서 다른 Service를 DI 받는 것은 불가피하다.)
- UserService에서 OrderService를 이용하는 비즈니스 로직이 기존에 존재한다고 하자. 예를 들어 회원가입하면 특정 무료 상품을 제공하기 위해 무료 상품 주문을 OrderService로 진행할 수가 있겠다. 이럴 때, 순환참조가 발생할 수 있다.
자, 그렇다면 ‘userRepository.findByIdAndIsQuit(userId, false).orElseThrow(() -> new NotFoundException(USER_NOT_FOUND));’를 쓰지 않고 getUserById를 재사용할 수 있는 방법은 없을까?
재사용이 많이 되는 메소드들만 따로 모아두는 것은 어떨까? 필자는 해당 도메인 서비스에서 다른 도메인 서비스로 재사용이 많이 되는 메소드들을 모아 [도메인 이름]SimpleService로 분리했다.
계층을 하나 더 만든 셈이지
1. SimpleService
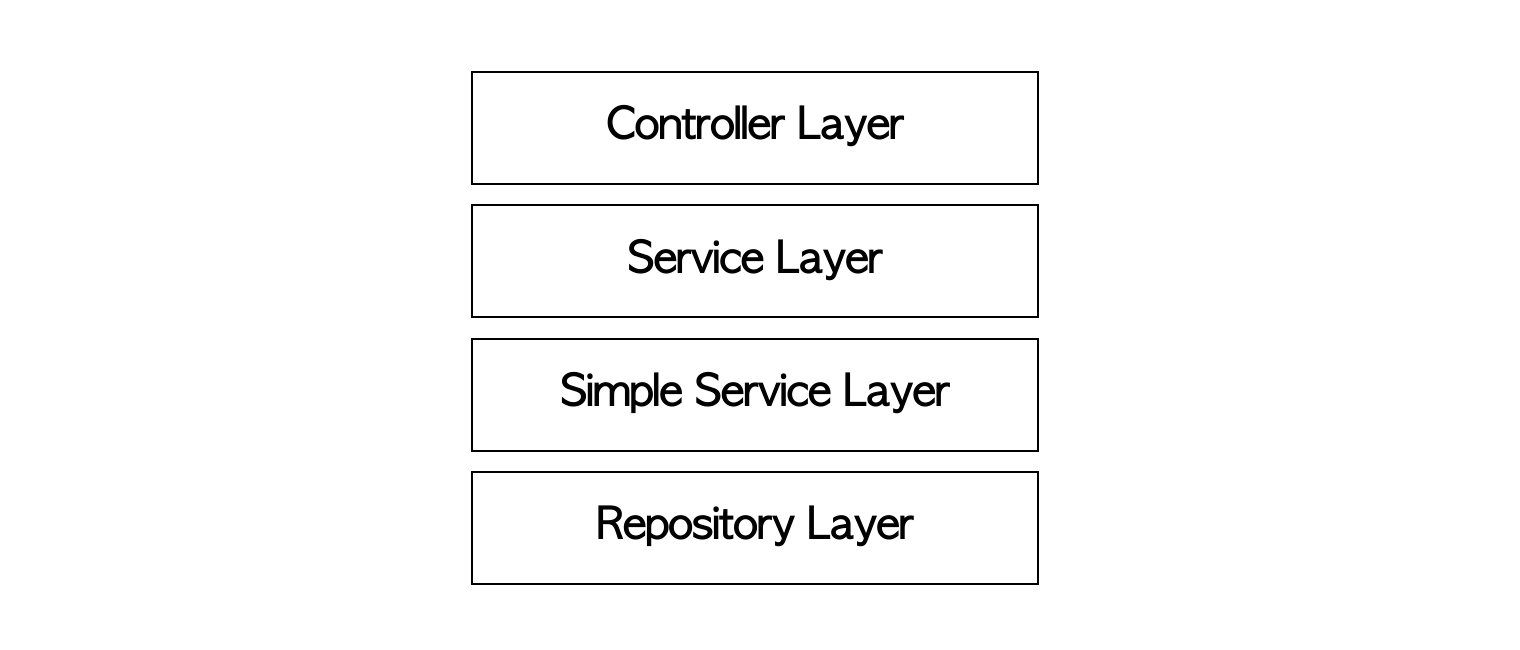
getUserById를 UserSimpleService에 정의하고, 다른 Service에서는 UserSimpleService를 DI 받는 것이다. getUserById 뿐만 아니라 checkExistByName 등 다른 도메인에서 자주 사용되는 메소드들이면 여기에 정의하는 것이다.
물론 프로젝트 초기 단계부터 SimpleService를 만드는 것은 비추이다. 어찌보면 관리 포인트가 하나 더 생기는 것이니 Service에 만들어도 문제되지 않으면 Service에 만들고, 이후에 개발을 진행하며 Service 안에서 메소드 별로 사용되는 빈도가 현저히 차이나면 다른 도메인에서 재사용이 많이 되는 메소드를 이처럼 따로 분리하는 것도 좋은 방법이라고 생각된다.
사실 이름이 SimpleService인게 직관적이지는 않아서 맘에 들지는 않지만 적절한 게 생각나지 않아 이렇게 지었다. 처음에는 UtilService였는데 Util과 Service용도는 다르기 때문에 올바르지 않다고 생각되어 SimpleService라고 지었다. (SpringBoot 내부에서도 Simple은 많이 쓰니까..)
2. Sinkhole Anti Pattern?
보통 별다른 로직 없이 i/o 작업만 하는 친구들이 다른 도메인에서 많이 사용되기 때문에 모아두고 보면 Sinkhole Anti Pattern에 해당되는 것 아닐까 고민할 수 있다. 하지만 단순 I/O 작업이라서 Sinkhole Anti Pattern인 것은 아니다. Sinkhole Anti Pattern은 요청의 20% 이상이 단순 통과 처리일 때부터 의심해도 된다. 모든 어플리케이션은 단순 통과처리 api가 있을 수 밖에 없기 때문이다.
코딩을 하는 자세
사실 Layered Architecture를 가지고 개발을 하면 계층을 활용하여 어떻게 관심사를 적절하게 분리하고, 재사용을 극대화할 수 있는지에 대해서 끊임없이 고민하게 되는 것 같다. 그럴 때마다 나는 다음 두 가지 원칙을 최우선으로 생각한다.
- 메소드를 작성할 때 흐름과 방법을 분리하자
- 서비스 메소드에서도 흐름을 담당하는 메소드가 있고 방법을 담당하는 메소드가 있다. 서비스의 비즈니스 로직이 커지면 해당 서비스의 메소드도 점차 흐름을 나타낼 수 밖에 없는데, 흐름과 방법이 섞여 있다면 방법을 나타내는 로직을 메소드로 추출해서 흐름만 나타내도록 리팩토링하면 가독성이 좋아진다.
- 하나의 메소드에서 추상화 정도를 일정하게 유지하자
- 추상화 정도를 일정하게 유지하는 것에 신경을 쓰면 어디까지 숨기고 어디까지 드러내야 할 지를 결정하는데 큰 도움이 되는 것 같다.
참고 문헌
https://junhyunny.github.io/architecture/pattern/layered-architecture/
https://github.com/ajou-swef/cookcode-backend
해당 깃헙은 최근 캡스톤 디자인 졸업 작품으로 진행 중인 프로젝트다.
