1. 개요
- 데이터 파이프 라인 모듈 중 데이터 수집에 사용되는 DFM(Data Flow Management)인 Apache Nifi 시스템
- 기본적으로 대규모 시스템에서 원천 DB로부터 필요한 데이터만 가져와서 사용할 DB에 저장할때 활용
- 모든 서비스가 원천 DB를 바라보고 있으면 부하가 쌓일 수 있기 때문에 사용 목적에 따라 가공해서 가져온다면 시스템 부하 줄일 수 있음.
2. 구성요소
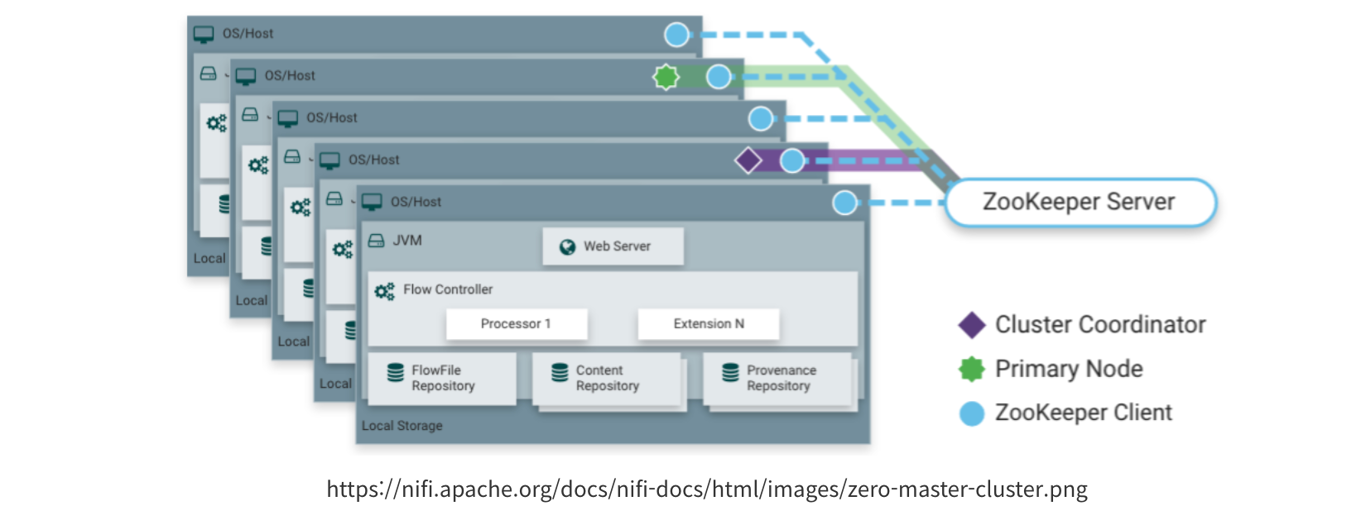 (위의 사진은 하나의 클러스터이다.)
(위의 사진은 하나의 클러스터이다.)
- 클러스터 코디네이터 : 각 Nifi 서버들(Node들) 정보(가동여부, 상태)를 관리, 데이터 플로우의 변경을 클러스터에 등록된 Nifi 노드들에 복제
- Primary Node : 실행되고 있는 대표 노드
- Node : 실제로 데이터를 프로세싱하는 노드(구동되고 있는 서버의 단위)
- 클러스터의 각 노드들은 같은 DataFrlow를 가지고 있으며, 각 노드에서 중복되지 않는 서로 다른 데이터를 처리
- 각 노드 당(서버 당) Zookeeper & Nifi로 구성
- 각각의 Zookeper는 클러스터에서 자동으로 Primary Node를 선출하는 역할을 함(즉, 모든 클러스터는 하나의 Primary Node를 가짐)
- Primary Node가 죽으면 다른 노드가 새로운 Primary Node로 산출
3. config 파일

- conf : 설정 파일 디렉토리
- logs : 로그 저장
- content_repository : flowfile의 컨텐츠 저장
- flowfile_repository : flowfile의 상태와 속성값 저장
- provenance_repository : 데이터 처리 단계별 flowfile의 변화(원천) 데이터 저장
flowfile : 프로세서에 의해 생성된 데이터
4. Nifi에서 실행중인 node 확인
1) 오른쪽 상단 메뉴바에서 cluster 클릭
2) 클러스터 안에 설정했던 노드가 잘 떠있는지 확인
nifi가 클러스터로 묶여 있는 경우, 1대는 primary node로 지정되어 나머지 node들에 일들을 분배하게 되는데,
primary node 서버가 내려가면 살아있는 나머지 node들 중에 하나로 primary node를 자동으로 변경해주게 된다.
5. Nifi Cron

- 지정 시간마다 sql을 실행하는 cron driven 표기
- 데이터 들어올 때마다 자동으로 실행되는 경우는 timer driven 사용
ex) 15 1/1 * * *?
-> 1분에 시작해서 1분 마다 매 15초에 진행
(10:01:15, 10:02:15, 10:03:15)

Data Engineer