1. Snowflake 비용 구성 요소
1-1. Computing Resource
아래는 snowflake의 computing resource를 사용하는 case입니다.
- Virtual Warehouse
- 데이터 로딩, 쿼리 실행, DML 작업
- 유연한 확정 가능
- 초당 과금 청구되므로 실제로 소비한 credit에 대해서만 비용 발생
- Cloud Service
- 인증, 메타데이터 관리, 엑세스 제어와 같은 백그라운드 작업 수행시 크레딧 사용
- 일일 사용량이 warehouse 비용의 10% 이상 사용한 경우에만 요금 청구(거의 발생X)
- Serverless
- Virtual Warehouse가 아닌 snowflake 관리형 컴퓨팅 리소스를 사용하는 유형
- 자동 클러스터링, MView, Search Optimization, SnowPipe, 복제와 같은 기능이 있음
1-2. Storage
- 데이터 로딩, 언로딩을 하기 위해 스테이지된 파일 비용
- 테이블 데이터와 같은 DB 비용 포함
- 테이블 데이터는 매우 압축되어 저장되므로 전체 비용에서 아주 낮은 비율
1-3. Data Transfer & Egress
- 데이터 -> Snowflake 수신, Snowflake -> 외부 송신
- 동일 region내에서 Data 전송은 무료,
- Snowflake 계정에서 같은 cloud platform에 다른 region으로 데이터 전송 시, byte당 요금 청구
2. 비용 관리 프레임워크
비용 관리 프레임워크를 사용하면 Snowflake에서 발생하는 비용을 효과적으로 관리 가능합니다.
2-1. Visibility(시각화)
비용의 패턴을 이해할 수 있고 누가, 어떤 목적으로 비용을 발생시킨지 확인할 수 있습니다.
Snowflake dashboard > Admin > Cost Management 에서 확인 가능합니다.
2-2. Control(모니터링)
예산의 한도와 가드레일을 설정하고 모니터링 할 수 있습니다.
- Resource Monitor 구성
- 사용자 관리 가상 warehouse 및 cloud service계층 별 크레딧 사용 모니터링 가능
- 월별 한도 설정 및 사용자 지정 한도 설정하여 관리 가능
- 지정한 임계값이 도달하면 이메일 알림 또는 Warehouse를 선택적으로 일시 중지 기능 제공
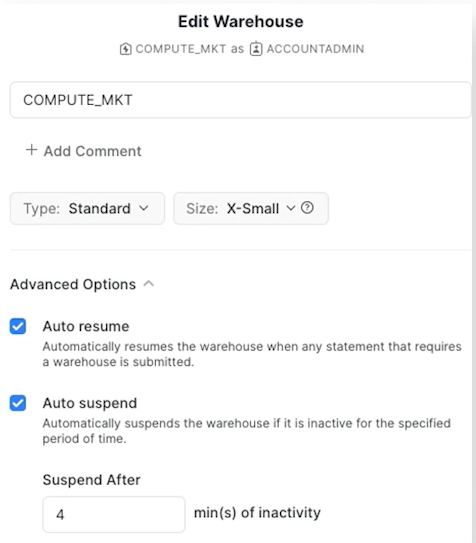
[ Auto-Suspend & Auto-Resume duration 가이드]
- snowflake는 모든 쿼리 결과 캐싱
- <반복적인 쿼리를 사용하는 워크로드의 경우> 캐시 사용시 성능 부분에 많은 혜택 제공
- <BI 및 select 쿼리 사용의 경우> Auto-Suspend 10분 이내로 설정 권장
- <DevOps, DataOps 및 DataScience 워크로드의 경우> 약 5분 이내로 설정 권장
[ Auto-Suspend & Auto-Resume Check Query 가이드]
-- Warehouse 목록 조회 SHOW WAREHOUSES;-- Resource Monitor를 사용하지 않는 웨어하우스 조회 SHOW WAREHOUSES; SELECT "name" AS WAREHOUSE_NAME, "size" AS WAREHOUSE_SIZE FROM TABLE(RESULT_SCAN(LAST_QUERY_ID())) WHERE "resource_monitor"=='null';-- Auto suspend(자동중단)가 1시간 이상인 웨어하우스 조회 SHOW WAREHOUSES; SELECT "name" AS WAREHOUSE_NAME, "size" AS WAREHOUSE_SIZE FROM TABLE(RESULT_SCAN(LAST_QUERY_ID())) WHERE "auto_suspend" >= 3600; // 3600seconds=1hour-- Auto resume값이 False인 웨어하우스 조회 SHOW WAREHOUSES; SELECT "name" AS WAREHOUSE_NAME, "size" AS WAREHOUSE_SIZE FROM TABLE(RESULT_SCAN(LAST_QUERY_ID())) WHERE "auto_resume" = 'false';
2-3. Optimization(최적화)
적절한 Warehouse type 선택, 크기 조정에 따라 최적화가 가능합니다.
-
가상 warehouse type:
standard(일반형),snowpark optimized warehouse(대량메모리)2가지 type -
작업 실행 -> 중간 결과값 저장하기 위해 가상 warehouse 메모리가 사용 -> 메모리 부족시 warehouse의 local disk로 데이터 spill -> local disk가 부족시 remote storage로 data spill
==>> data 얻기까지의 시간 및 비용 증가-- 최근 45일간 Disk Spilled Query Top-10 use warehouse compute_s; select query_id, substr(query_text, 1, 50) partial_query_text, user_name, warehouse_name, warehouse_size, BYTES_SPILLED_TO_REMOTE_STORAGE, start_time, end_time, total_elapsed_time/1000, total_elapsed_time from snowflake.account_usage.query_history where BYTES_SPILLED_TO_REMOTE_STORAGE > 0 and start_time::date > dateadd('days', -45, current_date) order by BYTES_SPILLED_TO_REMOTE_STORAGE desc limit 10;- 해당 query에서 만약 결과값이 있다면 query_id값을 가지고 추적한 후 최적화 필요 여부 결정
-- 최근 45일 웨어하우스 캐시에서 스캔된 데이터 비율 SELECT WAREHOUSE_NAME , COUND(*) AS QUERY_COUNT , SUM(BYTES_SCANNED) AS BYTES_SCANNED , SUM(BYTES_SCANNED*PERCENTAGE_SCANNED_FROM_CACHE) AS BYTES_SCANNED_FROM_CACHE , SUM(BYTES_SCANNED*PERCENTAGE_SCANNED_FROM_CACHE) / SUM(BYTES_SCANNED) AS PERCENT_SCANNED_FROM_CACHE FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY" WHERE START_TIME >= dateadd('DAYS', -45, current_timestamp()) AND BYTES_SCANNED > 0 GROUP BY 1 ORDER BY 5;- 해당 query 결과값에서 PERCENT_SCANNED_FROM_CACHE 비율이 낮다면,
cache를 태울 수 있도록 query tuning 고려 필요
-- 최근 45일 웨어하우스 부하 확인 SELECT TO_DATE(START_TIME) AS DATE, WAREHOUSE_NAME, SUM(AVG_RUNNING) AS SUM_RUNNING, SUM(AVG_QUEUED_LOAD) AS SUM_QUEUED FROM "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_LOAD_HISTORY" WHERE TO_DATE(START_TIME) >= DATEADD('DAUS', -45, CURRENT_TIMESTAMP()) GROUP BY 1,2 HAVING SUM(AVG_QUEUED_LOAD) > 0;- warehouse 부하는 쿼리가 수행될 때 queue에 얼마만큼 작업이 쌓여있는지 확인 가능
- SUM_QUEUED>=1 경우, warehouse size 확장을 고려
-- 최근 한달 Full table scan을 가장 많이 한 사용자 SELECT USER_NAME , COUNT(*) as COUNT_of_queries FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY" WHERE START_TIME >= dateadd(month, -1, current_timestamp()) AND PARTITIONS_SCANNED > (PARTITIONS_TOTAL*0.95) AND QUERY_TYPE NOT LIKE 'CREATE%' GROUP BY 1 ORDER BY 2 DESC;
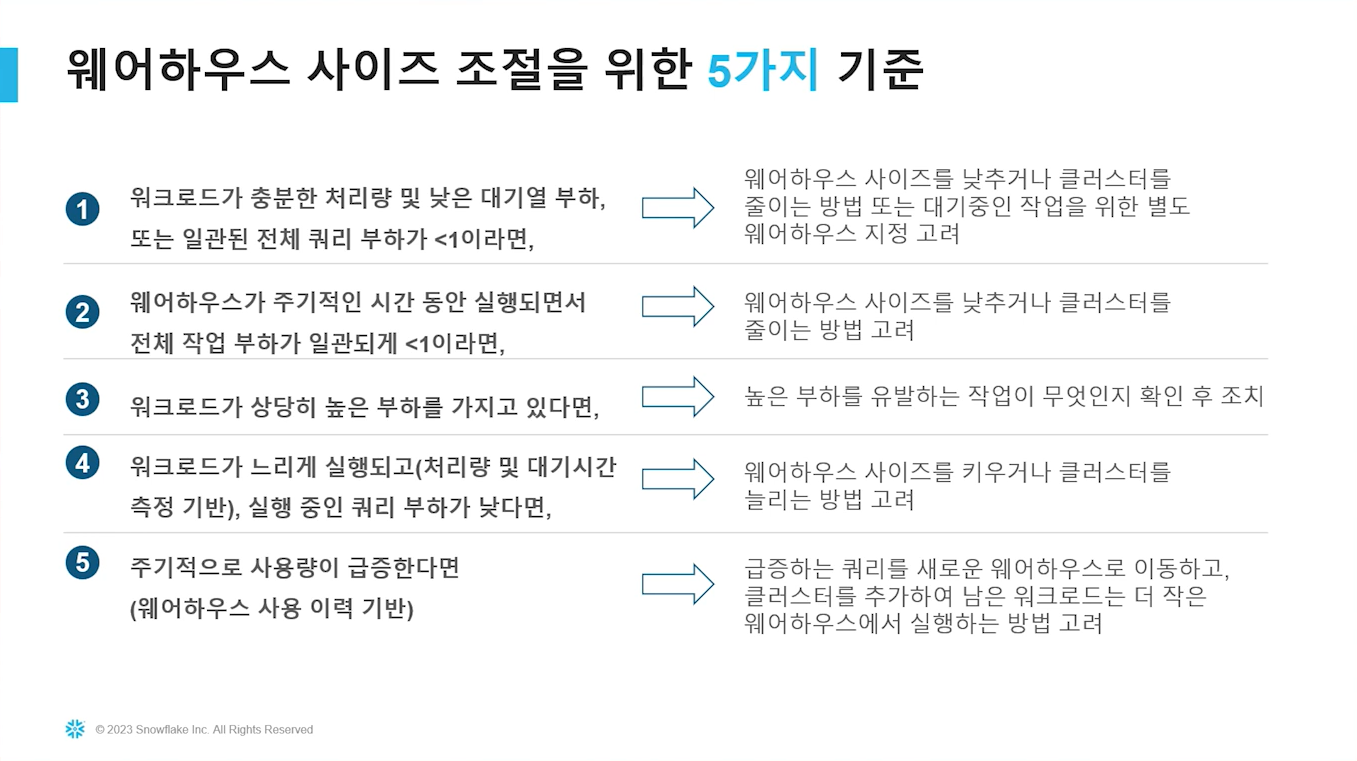
2-4. 웨어하우스 사이즈 조절을 위한 기준
ETC. (용어)
object 종류 : Database, Warehouse
Auto suspend : 자동 중단
Auto resume : 자동 재개

Data Engineer