자바의 Collection FrameWork는 Deque 인터페이스를 제공한다.
대표적인 구현체로 ArrayDeque과 LinkedList가 있다.
위 문제는 덱에 최대 1000개의 풍선 정보(인덱스, 밸류 값)를 저장하여 풀 수 있는 간단한 문제인데, 메모리 제한은 4MB이다.
private static Deque<Integer> deque = new LinkedList<>(); //메모리 초과
private static Deque<Integer> deque = new ArrayDeque<>(); //통과
처음에 Deque의 구현체로 아무 생각없이 LinkedList를 선택했다가, 메모리 초과로 통과되지 못했다. 이후 구현체만 ArrayDeque로 변경했더니 통과되었다.
(근데 15Mb인데 왜 통과되지? 자바 어드밴티지인가)
ArrayDeque vs LinkedList
GPT 선생님께 차이점을 질문해보았다.

ArrayDeque는 내부적으로 배열로 저장을하고, 따라서 기존 할당된 크기를 넘어서는 삽입 요청 시 O(N)의 복사 비용이 발생한다. 배열 특성 상 연속적으로 저장되므로 메모리 오버헤드가 적다.
LinkedList는 이중연결리스트 형태이고, 각 원소 저장 시, 노드가 생성되며 이에 추가적인 메모리 오버헤드가 발생한다.
ArrayDeque
ArrayDeque은 초기에 크기를 얼만큼 할당하는가? 구현체 코드를 직접 뜯어보았다.
/**
* Constructs an empty array deque with an initial capacity
* sufficient to hold 16 elements.
*/
public ArrayDeque() {
elements = new Object[16];
}
/**
* Constructs an empty array deque with an initial capacity
* sufficient to hold the specified number of elements.
*
* @param numElements lower bound on initial capacity of the deque
*/
public ArrayDeque(int numElements) {
elements =
new Object[(numElements < 1) ? 1 :
(numElements == Integer.MAX_VALUE) ? Integer.MAX_VALUE :
numElements + 1];
}기본 생성자를 통해 객체를 생성할 시, 16개의 공간이 할당되는 것을 알 수 있고, 기본 생성자 외에도 매개변수를 통해 초기 할당 크기를 지정할 수 있었다.
또한 재미있게도 매개변수로 음수를 넣을 시, 1의 크기를 할당한다. (예외를 발생시키지 않도록 설계한 이유는 무엇일까?)
ArrayDeque에 삽입해야할 원소가 매우 많다면, 초기에 크기를 넉넉히 할당하는 것이 복사 비용을 줄일 수 있는 방법일 것이다.
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[tail] = e;
if (head == (tail = inc(tail, es.length)))
grow(1);
}
private void grow(int needed) {
// overflow-conscious code
final int oldCapacity = elements.length;
int newCapacity;
// Double capacity if small; else grow by 50%
int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);
if (jump < needed
|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)
newCapacity = newCapacity(needed, jump);
final Object[] es = elements = Arrays.copyOf(elements, newCapacity);
// Exceptionally, here tail == head needs to be disambiguated
if (tail < head || (tail == head && es[head] != null)) {
// wrap around; slide first leg forward to end of array
int newSpace = newCapacity - oldCapacity;
System.arraycopy(es, head,
es, head + newSpace,
oldCapacity - head);
for (int i = head, to = (head += newSpace); i < to; i++)
es[i] = null;
}
}ArrayDeque 내부에서 head와 tail 변수를 통해 인덱스 컨트롤을 하고 있다.
또한, 크기를 확장할 때, 기존 크기의 50% 씩 확장하도록 설계되었다.
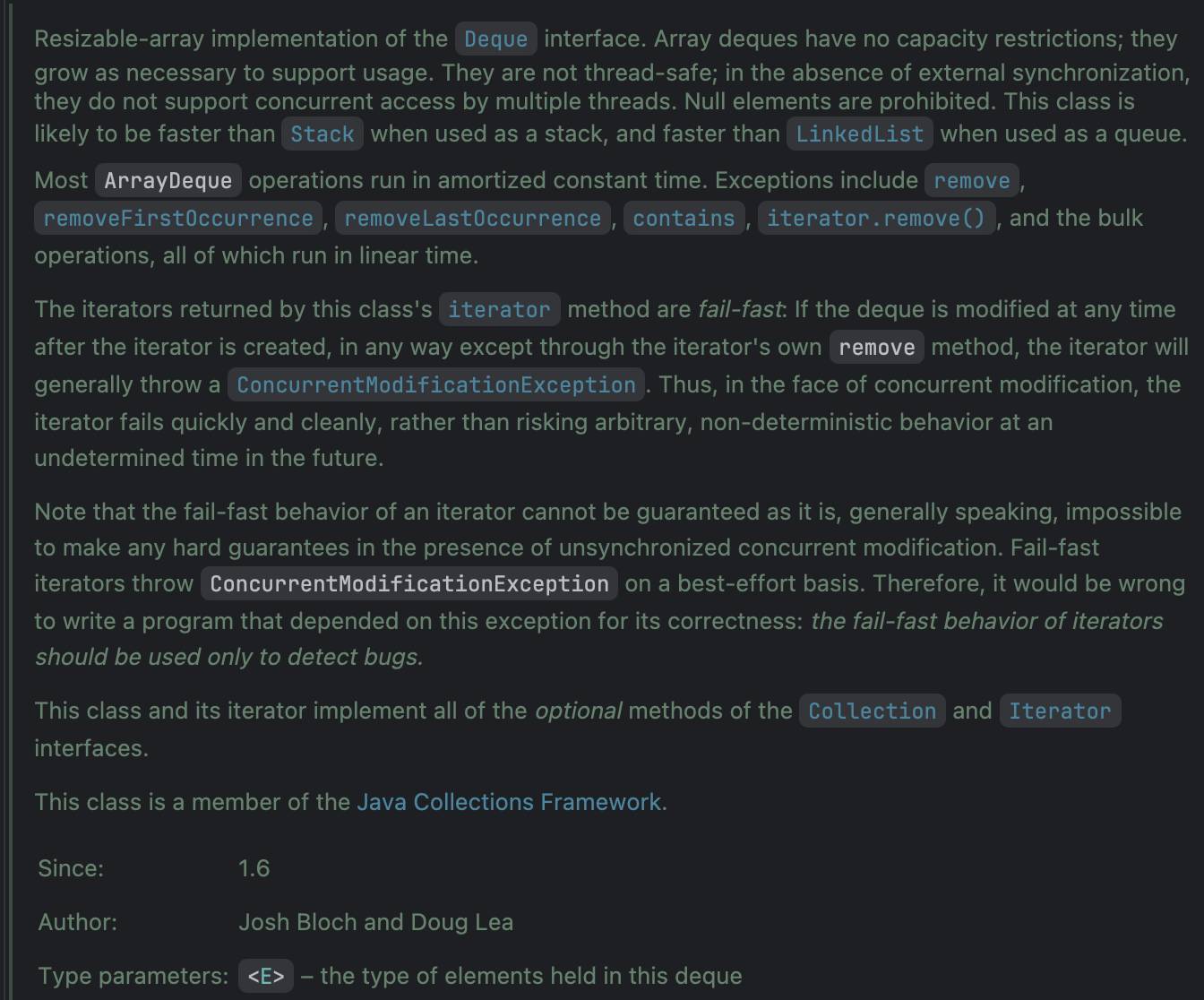
공식 문서를 읽는 것은 참 재밌다.
ArrayDeque을 직접 구현한 선생님들의 주석을 정리하자면,
-
Not thread-safety (내부에 배열 형태로 저장, 접근하므로)
-
스택으로 사용할 때 Stack 구현체보다 대체로 더 빠르며(likely to be faster), queue로 사용할 때 LinkedList 보다 더 빠르다(faster).
-
대부분의 연산은 Amortized O(1)
-
remove, removeFirstOccurrence, contains, iterator.remove()는 O(N)
: 각 메서드의 매개변수는 Object를 넘겨주며, Object.equals()를 통해 true가 나온 값들을 처리한다. 즉, 주소 값이 같은 객체를 다루는 메서드. -
iterator() 메서드를 통해 반환받는 iterators는 fail-fast로 설계됨.
: Fail-fast는 시스템이 문제를 최대한 빨리 감지하고 실패하는 것을 목표로 하는 설계 철학. 만약 한 스레드가 Iterator를 통해 컬렉션을 순회하는 동안, 다른 스레드가 그 컬렉션을 수정하면,ConcurrentModificationException이 즉시 발생하여 프로그램이 더 큰 문제로 이어지지 않도록 방지한다. (하지만 fail-fast는 동시성 문제가 아예 발생하지 않았음을 강력히 보장하는 것이 아니다)
