3월 15일에 시작한 포트폴리오 6주반이 벌써 5주차에 들어섰다. 2주차부터 본격적으로 시작한 개발과정은 이제 메인페이지까지 완성했지만, 진행과정과 정리한글이 없어서 뒤늦게 지난회차에 대한것을 적게 되었다. 개발에 집중하는것도 좋지만, 역시 이렇게 몰아서 할바엔, 평시에 일정시간은 글을 쓰는 시간을 잡아두는게 좋을것 같다..😂😂
2주차 진행
- 칸반보드 작성
- 네이버 지도 크롤링 작업
- firebase oAuth
2주차에서 주된 작업은 크롤링 이였고, 두번째는 oAuth, 마지막으로 칸반보드였다.
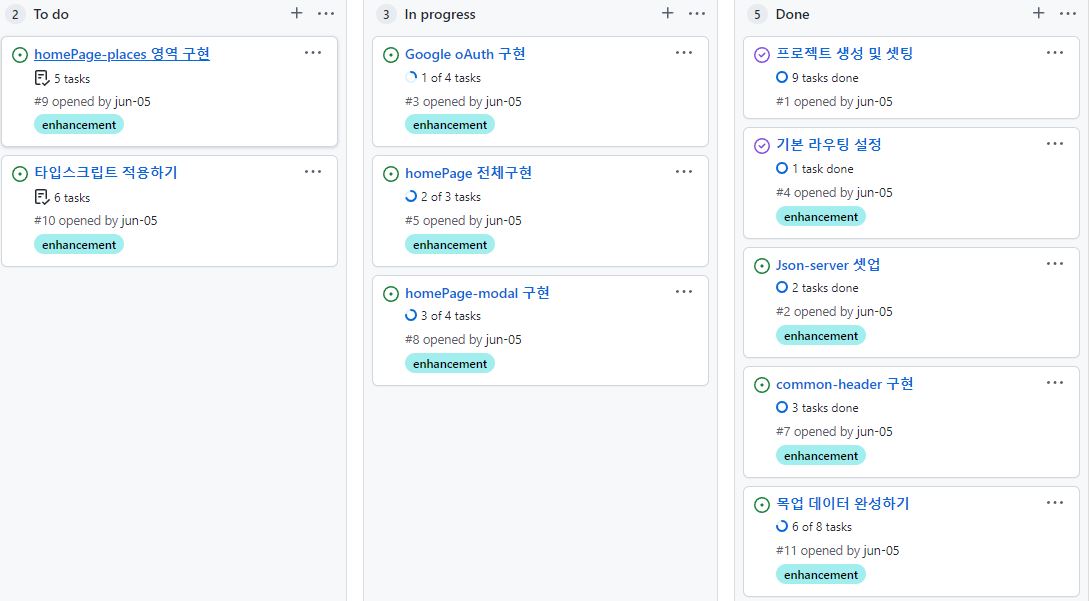
칸반보드
- 깃허브의 프로젝트 기능을 통해서 작성하였다.
- 개발기간과 전체적인 칸반은 작성하지 않았는데, 스스로에 대한 감이 없었기 때문이다. 하지만 적어두었다면 완성이후에 비교할 수 있었을테니 좋았을거란 후회가 남았다.
- 칸반을 작성하게되면 세부적인것까지 생각하게 되는 부분이 좋았던것 같다.
네이버 지도 크롤링
- 파이썬을 접해보았고, 기본적인 크롤링에 대해서 공부해보았다.
- 정보의 수와 질이 좋은 네이버지도 크롤링을 목표로 하였다.
- 네이버의 경우 cssSelector로 요소가 잘 안잡히는 이슈가 있었는데, switch_to.default_content를 통하여 frame을 바꿔줘야 잡을수 있었다.(벨로그에 올라온 toto9602님 글을 수정하여 사용하였다)
크롤링을 통하여 수집하고자 했던 것은
카테고리(박물관 등) - 광역시(서울,부산..) - 시군구(강서,강남..)를 조건으로 for문을 통해 돌리면서 네이버지도에잇는 모든 카테고리에 속하는 시설들을 수집하는것이였다.
크롤링을 막상 실행하면서 접한 주된 애로사항은
1. 검색 결과에서 수집하고자 하는 class값이 각 검색결과마다 다르다는것
2. 검색 조건에 따라서 xpath값이 조금씩 다르다는것
3. 검색결과가 없을 수 있다는것
4. 검색결과가 하나일경우, 특정 조건에서 바로 장소리스트가 아닌 시설정보가 뜬다는것
5. 이미지가 1개일경우 수집하고자 하는 class값과 위치가 다르다는것
이였다. 이중 4번과 5번은 전체 검색결과에서 차지하는 비중이 크진 않아서 후순위로 두었고, 결국 별도의 처리는 하지 못한채 넘어가게되었다.
6. 검색 결과가 6개가 나왔다 가정하면, 1~3번은 카테고리와 지역이 맞지만, 4번에서 카테고리 또는 지역이 틀리고 5~6번은 맞는 검색결과가 나올수 있었다.
1~3번은 모두 비슷한 조건내에 있던것이라 한번에 처리 할수 있었다.
try:
scroll_div = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]")
places_box = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]/ul") # 해당 페이지에서 표시된 모든 가게 정보
places_box_className = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]/ul/li[1]").get_attribute('class').replace(
" ", ".") # 장소 정보가 들어있는 아이템(li) class명 수집
except:
try:
scroll_div = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]")
places_box = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]/ul")
places_box_className = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]/ul/li[1]").get_attribute('class').replace(
" ", ".")
except:
continue1번의 경우 xpath를 통하여 class값을 잡고, replace를 통하여 cssSelector에서 사용가능한 문자열로 바꿔주었다.
2번의 경우 검색결과들의 xpath들은 body아래 3번째 디브의 깊이가 1이냐 2냐 차이가 있었기에, try문을 통하여 만약 못 찾아서 에러가 날 경우 2를 찾도록 하였고.
3번의 경우도 비슷하게 두번째 try에서도 경로를 못 잡을경우(검색결과가 없는경우) error로 넘어오기때문에 cotinue를 통하여 다음검색을 하게 하였다.
finally:
# 다른 카테고리가 나오면 not_category +1 증가
s = category_
m = re.match(s, category)
if m == None:
not_category += 1
driver.switch_to.default_content()
driver.switch_to.frame(frame)
continue
try:
address = driver.find_element_by_css_selector(
"._1Gmk4>span._2yqUQ").text
except:
address = ''
# 주소 정보 확인
finally: # 일치하지 않는 주소가 나올경우 while문 종료
s = region_1 + " " + region_2
m = re.match(s, address)
if m == None:
break6번의 경우 notCategory라는 변수를 만들어 틀린 카테고리가 나올경우 숫자를 증가시켜 일정숫자 이상일 경우 반복문을 중단하고 다음 검색을 하되도록 하였다. 지역이 틀린 경우는 거의 대다수의 경우 이후값들도 지역이 틀리기 때문에 검색조건에 사용된 지역명과 다를경우 반복문을 중단하고 다음 검색을 하도록 하였다.
file = open((region_1+' '+category_ + '.csv'),
mode='w', newline='', encoding='UTF-8')최종적으로 csv에 넣을때 인코딩 오류가 있을 수 있어 인코딩 처리를 해주었다.
fireBase oAuth
- 초기엔 구글oAuth를 통하여 구현하였지만, 백엔드 쪽과 동일하게 fireBase로 통일하게 되었다.
- API키값은 env값을 통해 관리하는게 권장된다.
- oAuth의 경우 oAuth환경의 ui환경을 기본 제공해주고, 로그인 성공시 사용자의 기본 정보를 모두 제공해준다.(닉네임 사진 등)
- 이중 accessToken값만을 받아서 백엔드 쪽에 넘겨주고, 백엔드쪽에서 별도의 확인 처리후 jwt토큰값을 프론트쪽에 넘겨주게 된다.
export const auth = getAuth();
export const signInGoogle = () => {
const provider = new GoogleAuthProvider();
return signInWithPopup(auth, provider)
.then((result) => {
const credential = GoogleAuthProvider.credentialFromResult(result);
const token = credential.accessToken;
return token;
})
.catch((error) => {
console.log(error.message);
throw new Error(error.code);
});
};컴포넌트에서 signInGoogle을 호출하여 로그인을 시도하고 성공시에 token값만을 return값으로 넘겨주도록 하였다.
fireBase oAuth도 기본 문서나, 정보들이 잘 나와서 구현이 어렵진 않았지만, react의 구글로그인 라이브러리를 사용하면 fireBase보다 더 간단하게 구현이 가능하였다.
마무리
2주차에는 사이트 구현을 위해 정보수집을 어떤것을, 어떻게 해야하나가 가장 주된 관심사였고, 또한 크롤링을 공부하고 작동시키는게 가장 큰 임무였던것 같다.
그래도 이런저런 고생은 하였지만, 5000개의 자료를 팀원분들과 분담을 하며 할때도 무리없이 돌아가는걸 보고 보람을 느꼈던것 같다.
네이버지도 크롤링 전체 코드 (클래스명은 주기적으로 바뀔수있음)
from distutils.log import error
from pydoc import classname
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import StaleElementReferenceException
import time
import re
import csv
categorys = ["박물관", "테마파크", "식물원"
]
region1 = ["서울", "부산", "대구", "인천", "광주", "대전", "울산",
"경기", "강원", "충북", "충남", "경북", "경남", "전북", "전남", "제주"]
region2 = [["강남구", "도봉구", "동대문구", "동작구", "마포구", "서대문구", "서초구", "성동구", "성북구", "송파구", "양천구", "강동구", "영등포구", "용산구", "은평구", "종로구", "중구", "중랑구", "강북구", "강서구", "관악구", "광진구", "구로구", "금천구", "노원구"],
["강서구", "사하구", "서구", "수영구", "연제구", "영도구", "중구", "해운대구",
"금정구", "기장군", "남구", "동구", "동래구", "부산진구", "북구", "사상구"],
["남구", "달서구", "달성군", "동구", "북구", "서구", "수성구", "중구"],
["강화군", "중구", "계양구", "미추홀구", "남동구", "동구", "부평구", "서구", "연수구", "옹진군"],
["광산구", "남구", "동구", "북구", "서구"],
["대덕구", "동구", "서구", "유성구", "중구"],
["중구", "남구", "동구", "북구", "울주군"],
["가평군", "동두천시", "부천시", "성남시", "수원시", "시흥시", "안산시", "안성시", "안양시", "양주시", "양평군", "고양시", "여주시", "연천군", "오산시", "용인시",
"의왕시", "의정부시", "이천시", "파주시", "평택시", "포천시", "과천시", "하남시", "화성시", "광명시", "광주시", "구리시", "군포시", "김포시", "남양주시"],
["강릉시", "인제군", "정선군", "철원군", "춘천시", "태백시", "평창군", "홍천군", "화천군",
"횡성군", "고성군", "동해시", "삼척시", "속초시", "양구군", "양양군", "영월군", "원주시"],
["괴산군", "청주시", "충주시", "증평군", "단양군", "보은군",
"영동군", "옥천군", "음성군", "제천시", "진천군"],
["공주시", "예산군", "천안시", "청양군", "태안군", "홍성군", "계룡시", "금산군",
"논산시", "당진시", "보령시", "부여군", "서산시", "서천군", "아산시"],
["경산시", "성주군", "안동시", "영덕군", "영양군", "영주시", "영천시", "예천군", "울릉군", "울진군", "의성군", "경주시",
"청도군", "청송군", "칠곡군", "포항시", "고령군", "구미시", "군위군", "김천시", "문경시", "봉화군", "상주시"],
["거제시", "양산시", "의령군", "진주시", "창녕군", "창원시", "통영시", "하동군", "함안군",
"거창군", "함양군", "합천군", "고성군", "김해시", "남해군", "밀양시", "사천시", "산청군"],
["고창군", "임실군", "장수군", "전주시", "정읍시", "진안군", "군산시",
"김제시", "남원시", "무주군", "부안군", "순창군", "완주군", "익산시"],
["강진군", "보성군", "순천시", "신안군", "여수시", "영광군", "영암군", "완도군", "장성군", "고흥군", "장흥군",
"진도군", "함평군", "해남군", "화순군", "곡성군", "광양시", "구례군", "나주시", "담양군", "목포시", "무안군"],
["서귀포시", "제주시"],
]
for category_ in categorys:
for i, region_1 in enumerate(region1):
file = open((region_1+' '+category_ + '.csv'),
mode='w', newline='', encoding='UTF-8')
writer = csv.writer(file)
writer.writerow(["placeName", "category", "region_1", "region_2", "address", "contact", "placeInfo",
"openHours", "cost ", "tag", "wayInfo", "img_src", "link_url"])
final_result = []
for region_2 in region2[i]:
driver = webdriver.Chrome("C:/chromedriver.exe")
driver.get("https://map.naver.com/v5/")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.CLASS_NAME, "input_search"))
)
finally:
pass
search_box = driver.find_element_by_class_name("input_search")
search_box.send_keys(region_1 + " " + region_2 + " " + category_)
search_box.send_keys(Keys.ENTER)
time.sleep(3)
frame = driver.find_element_by_css_selector("iframe#searchIframe")
driver.switch_to.frame(frame)
time.sleep(1)
try:
scroll_div = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]")
places_box = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]/ul") # 해당 페이지에서 표시된 모든 가게 정보
places_box_className = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[2]/div[1]/ul/li[1]").get_attribute('class').replace(
" ", ".") # 장소 정보가 들어있는 아이템(li) class명 수집
except:
try:
scroll_div = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]")
places_box = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]/ul")
places_box_className = driver.find_element_by_xpath(
"/html/body/div[3]/div/div[1]/div[1]/ul/li[1]").get_attribute('class').replace(
" ", ".")
except:
continue
driver.execute_script("arguments[0].scrollBy(0,2000)", scroll_div)
time.sleep(1)
places = driver.find_elements_by_css_selector(
"li."+places_box_className)
# 카테고리와 맞지 않는 결과수
not_category = 0
for place in places:
# 카테고리와 맞지 않는 검색결과가 2개이상 나올경우 반복문 중단
if not_category > 1:
break
placeName = place.find_element_by_css_selector(
"div>span").text #가게 이름
try:
click_name = place.find_element_by_css_selector(
"div>span").click() ##상세 정보창으로 이동, 오류시 반복문 종료
except:
break
driver.switch_to.default_content()
time.sleep(1)
frame_in = driver.find_element_by_xpath(
'/html/body/app/layout/div[3]/div[2]/shrinkable-layout/div/app-base/search-layout/div[2]/entry-layout/entry-place-bridge/div/nm-external-frame-bridge/nm-iframe/iframe')
driver.switch_to.frame(frame_in)
time.sleep(1)
try:
img_src = re.search('url[(]"([\S]+)"', driver.find_element_by_css_selector(
"._3eHVS.W3koY>div:first-child div div").get_attribute('style')).groups()[0]
except:
img_src = ''
# 이미지 정보 확인
try:
category = driver.find_element_by_css_selector(
"span._3ocDE").text
except:
category = ''
# 카테고리 정보 확인
finally:
# 다른 카테고리가 나오면 not_category +1 증가
s = category_
m = re.match(s, category)
if m == None:
not_category += 1
driver.switch_to.default_content()
driver.switch_to.frame(frame)
continue
try:
address = driver.find_element_by_css_selector(
"._1Gmk4>span._2yqUQ").text
except:
address = ''
# 주소 정보 확인
finally: # 일치하지 않는 주소가 나올경우 반복문 종료
s = region_1 + " " + region_2
m = re.match(s, address)
if m == None:
break
try:
contact = driver.find_element_by_css_selector(
"span._3ZA0S").text
except:
contact = ''
# 연락처 정보 확인
try:
link_url = driver.find_element_by_css_selector(
"a._2ruNn").text
except:
link_url = ''
# 홈페이지 url 확인
try:
driver.find_element_by_css_selector(
"._1M_Iz ._1h3B_ >.M_704").click()
placeInfo = driver.find_element_by_css_selector(
"._1M_Iz ._1h3B_ >.M_704 .WoYOw").text
except:
placeInfo = ''
# 장소 정보 확인
try:
tag = driver.find_element_by_css_selector(
"ul .kzZ_D").text
except:
tag = ''
# 장소 태그확인
try:
driver.find_element_by_css_selector(
"div ._2ZP3j").click()
openHoursEl = driver.find_elements_by_css_selector(
"._2ZP3j._2vK84 ~div") # 펼쳐보기 탭의 형제요소들
openHours = ''
# elements로 받은 list값의 text 더해주기
for openHoursItem in openHoursEl:
openHours += openHoursItem.text + '\n'
# 마지막 span에 접기가 포함되있기 때문에 replace 처리
openHours = openHours.replace('접기', '')
#
if openHours == '':
openHours = driver.find_element_by_css_selector(
"div ._2ZP3j").text
# 펼쳐보기 영역이 없거나.영업시간이 없을시 예외처리
except:
try:
openHours = driver.find_element_by_css_selector(
"div ._2ZP3j").text # 영업시간이 1개만 존재
except:
openHours = '' # 영업시간이 없을경우
# 운영시간 정보 확인
try:
cost = driver.find_element_by_css_selector(
"ul ._1WK4L").text
except:
cost = ''
# 비용 확인
try:
wayInfo = driver.find_element_by_css_selector(
"._1M_Iz ._1h3B_ div .M_704").click()
wayInfo = driver.find_element_by_css_selector(
"._1M_Iz ._1h3B_ div .M_704 .WoYOw").text
except:
wayInfo = ''
# 가는 길 확인
# 크롤링한 정보들을 place_info에 담고 출력해서 확인
place_info = {
"placeName": placeName, "category": category, "region_1": region_1, "region_2": region_2, "address": address, "contact": contact, "placeInfo": placeInfo,
"openHours": openHours, "cost": cost, "tag": tag, "wayInfo": wayInfo, "img_src": img_src, "link_url": link_url,
}
print("*" * 50)
print("placeName : " + placeName, "\n", "category :" + category, "\n", "region_1 :" + region_1, "\n", "region_2 :" + region_2, "\n", "address :" + address, "\n",
"contact : " + contact, "\n", "placeInfo :" + placeInfo, "\n",
"openHours :" + openHours, "\n", "cost :" +
cost, "\n", "tag :" + tag, "\n", "img_src :" + img_src,
"\n",
"link_url :" + link_url, "\n", "wayInfo :" + wayInfo)
final_result.append(place_info)
driver.switch_to.default_content()
driver.switch_to.frame(frame)
driver.close()
# 검색 완료시 final_result에 저장
for result in final_result: # 크롤링한 가게 정보에 순차적으로 접근 & csv 파일 작성
row = []
row.append(result['placeName'])
row.append(result['category'])
row.append(result['region_1'])
row.append(result['region_2'])
row.append(result['address'])
row.append(result['contact'])
row.append(result['placeInfo'])
row.append(result['openHours'])
row.append(result['cost'])
row.append(result['tag'])
row.append(result['wayInfo'])
row.append(result['img_src'])
row.append(result['link_url'])
writer.writerow(row)
print(region_1 + " " + category_+"검색 종료")
print("전체 검색 종료")
