제2정규형 (2NF): 부분 함수 종속성 제거
-
기본키가 여러 개 조합된 경우, 일부 키에만 엮여 있는 찌꺼기 데이터 제거하기
-
제2정규형의 핵심은 기본키가 여러개 합쳐진 복합키일 때,
복합키 전체가 아니라 일부에만 종속되는 데이터가 있으면 분리하라는 의미이다. -
복합키는 컬럼 하나로는 데이터 한 줄을 고유하게 식별하기 어려워서
(A 컬럼 + B 컬럼)을 묶어서 기본키로 사용하는 경우이다. -
부분 함수 종속은 (A + B)가 합쳐져야만 알 수 있는 정보가 아니라
A 하나만 알아도 알 수 있는 정보가 테이블에 섞여 있는 상태. -
문제 상황
대학교 수강 신청 데이터 관리 테이블
(한 학생이 여러 과목 들을 수 있고, 고유한 한 줄 찾으려면
[학번]과 [과목명]이 동시에 기본키(복합키)가 되어야 한다.학번 (PK) 과목명 (PK) 성적 강의실 101 자바 프로그래밍 A 301호 101 스프링 부트 B 402호 102 자바 프로그래밍 A+ 301호 -
성적은 누구(학번)의 어떤 과목(과목명)가 있어야 성적을 알 수가 있다. (정상)
-
강의실은 학번과 상관없이 (과목명)만 있으면 강의실이 어디인지 알 수 있다. (문제)
-
만약 '자바 프로그래밍' 듣는 학생이 1,000명으로 늘어나면 똑같은 과목의 '301호'
라는 정보가 똑같이 1,000번 반복해서 저장된다.
강의실이 '505호'로 바뀌는 경우에도 1,000줄을 다 수정해줘야 한다. -
해결책은 원인이 되는 부분 함수 종속을 제거하기 위해 테이블을 두 개로 분리한다.
수강 성적 테이블 (복합키와 복합키 전체가 필요한 데이터만 남김)
학번 (PK) 과목명 (PK) 성적 101 자바 프로그래밍 A 101 스프링 부트 B 102 자바 프로그래밍 A+ 과목 테이블 (과목명 하나로 결정되는 데이터만 따로 분리)
과목명 (PK) 강의실 자바 프로그래밍 301호 스프링 부트 402호
제3정규형 (3NF): 이행적 함수 종속 제거
-
기본키가 아닌 일반 컬럼들끼리 꼬리에 꼬리를 무는 종속 관계 제거하기
-
기본키가 아닌 일반 컬럼들끼리 서로 종속 관계를 가지면 안된다.
(다리를 건너서 이어지는 관계를 끊어라.) -
이행적 관계는 A -> B 이고, B -> C 이면, 결과적으로 A -> C가 성립되는 관계
-
DB에서는 [기본키 -> 일반 컬럼 1 -> 일반 컬럼 2] 형태의 종속이 일어나는 것.
-
문제 상황
사원 정보를 관리하는 테이블, [사원번호] 하나만 기본키(PK)이다.사원번호 (PK) 이름 부서명 부서 전화번호 202601 최준영 백엔드 개발팀 02-123-4567 202602 김철수 백엔드 개발팀 02-123-4567 202603 이지수 인사팀 02-987-6543 -
사원번호를 알면 그 사원의 부서명을 알 수 있다. (사원번호 -> 부서명)
-
부서명을 알면 그 부서의 부서 전화번호를 알 수 있다. (부서명 -> 부서 전화번호)
-
결과적으로 사원번호를 통해 부서 전화번호까지 알게 된다. (사원번호 -> 부서명 -> 전화번호)
-
백엔드 개발팀에 속한 사원이 100명이면 '02-123-4567'이라는 번호가
100번 중복 저장되고, 만약 새로운 부서가 신설되었는데
아직 소속된 사원이 한 명도 없으면 테이블에 사원번호가 없으므로
새로운 부서와 부서 전화번호 등록할 수조차 없다.
-
-
해결책은 중간 다리 역할을 하는 일반 컬럼(부서명)을 기준으로 테이블을 쪼갠다.
-
아래처럼 바뀌게 되면 신설 부서도 등록이 가능하고,
전화번호가 바뀌어도 한 곳만 수정하면 된다.사원 기본 테이블
사원번호 (PK) 이름 부서명 202601 최준영 백엔드 개발팀 202602 김철수 백엔드 개발팀 202603 이영희 인사팀 부서 정보 테이블
부서명 (PK) 부서 전화번호 백엔드 개발팀 02-123-4567 인사팀 02-987-6543
트랜잭션의 지속성을 지키기 위한 기능들
- 지속성은 시스템에 어떤 장애(갑작스러운 전원 차단, 하드웨어 고장 등)가
발생해도 이미 성공적으로 커밋된 트랜잭션 결과에 한해서
데이터가 절대 유실되거나 변질되지 않고, 영구적으로 유지되어야 한다는 성질이다.
체크섬
-
데이터 오염 여부를 확인하는 디지털 지문
-
데이터가 디스크에 저장 or 네트워크 이동할 때
"이 데이터가 깨지지 않고, 안전한 상태인가?"를 검증하는 장치이다. -
데이터를 디스크에 저장하기 직전, 어떤 특정 수학적 계산 공식에
데이터를 집어넣고, 고유한 값(예:0x7A3F)을 만들어낸다.
이를 체크섬이라 부르고, 데이터 뒤에 꼬리표처럼 붙여서 함께 저장한다. -
나중에 디스크에서 데이터 읽을 때 읽어온 데이터를 똑같은 수학 공식에 대입하여
새로운 체크섬을 만들고, 처음 저장했던 체크섬과 비교하여 데이터 오염 여부를 판단한다. (오염되었다면 당연히 복구 절차를 밟아야 한다.)
저널링
-
DB에서 가장 무거운 작업은 디스크 임의의 위치에
실제 데이터를 직접 쓰는 물리적 행위이다. -
만약 데이터를 쓰는 도중 서버가 뻥나면 데이터가
제대로 기록되지 않아 복구가 불가능해진다.
이를 해결하기 위해
"데이터 바꾸기 전, 무엇을 바꿀지 미리 적어놓는다."의 개념이
저널링이다. -
트랜잭션 발생 -> 실제 데이터 건드리기 전에 저널 혹은 로그라 불리는
파일에 "X번 데이터를 Y로 바꿀 것이다."라는 내용을 순서대로 빠르게 기록한다.
이 기록은 단순히 뒤에 이어 붙이기만 하면 되므로 속도가 매우 빠르다. -
로그, 저널 기록이 안전하게 디스크에 저장(커밋)된 것이 확인되면
그제야 메모리에 있던 변경 사항을 실제 데이터 파일에 반영한다. -
로그와 실제 데이터 저장하는 공간은
저널 전용 공간으로 실제 데이터 공간과 다른 공간이다. -
지속성에 필요한 이유는 한창 실제 데이터 파일에 값을 바꾸고 있는데
갑자기 정전이 발생한 경우를 가정해보면
디스크를 다시 켜면 데이터 파일은 깨져있을 수 확률이 높다.
하지만 로그/저널 기록에는 어떤 데이터를 어떻게 바꾸겠다 라는 기록이 남아있다.
시스템은 이 기록을 처음부터 다시 읽으며 깨진 데이터 파일 위에 올바른 값을
다시 덮어씌워 트랜잭션 결과를 완벽하게 복구해낸다.
추가 기능
OS 버퍼를 뚫고 디스크로 밀어 넣기: fsync 시스템 콜
-
애플리케이션이 디스크에 저장하라고 명령해도 OS는 성능을 위해
곧바로 디스크에 쓰지 않고, 메모리(OS Buffer Cache)에 임시로 들고 있다.
당연히 이 상태에서 정전 되면 데이터는 다 날아가 버린다. -
해결책은 DB는 트랜잭션 완료되는 순간, OS에게
"동작 멈추고, 메모리에 있는 로그를 디스크 하드웨어에 물리적으로 정착시켜라" 라고,
강제적인 명령을 내린다. (fsync())
이 과정이 성공해야만 지속성을 챙길 수 있다.
PostgreSQL
PostgreSQL 스토리지 엔진 아키텍처
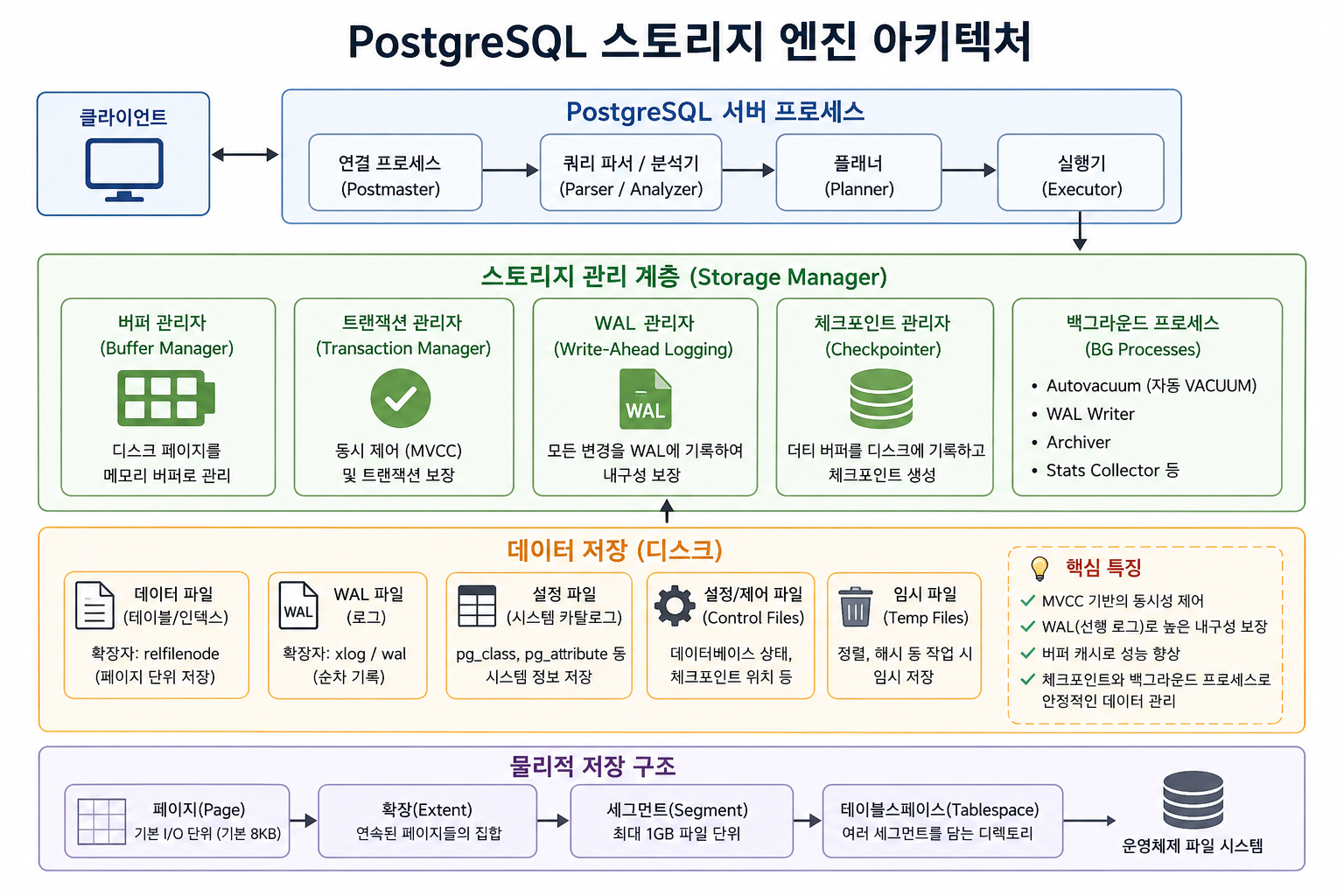
-
위 그림은 요청 처리 -> 메모리 관리 -> 디스크 저장을 설명해준다.
-
PostgreSQL 서버 프로세스 (요청 처리반, 맨 위 계층)
-
클라이언트(앱)가 SQL 쿼리 보냈을 때 이를 해석하고, 실행 계획 짜는 곳
-
연결 프로세스에서 클라이언트 접속 요청을 받고, (쿼리 파서 / 분석기)가
들어온 SQL 문법이 맞는지 검사하고, 분석한다. -
플래너가 "이 데이터 어떻게 찾아야 가장 빠르게 찾을까?" 고민하며
가장 효율적인 실행 계획을 짠다. -
실행기는 플래너가 짠 계획대로 실제 데이터 가져오기 or 수정하라고
아래 계층에 명령을 내린다.
-
-
스토리지 관리 계층 (메모리 및 작업 반장, 중간 계층)
-
실제 데이터 처리를 조율하는 핵심 계층
(성능 위해 대부분 메모리에서 작업된다.) -
버퍼 관리자는 디스크에 있는 데이터 페이지를 메모리(버퍼 캐시)로 올려서
들고 있는 관리자이고, 모든 읽기/쓰기는 이 메모리를 거쳐야 빨라진다. -
트랜잭션 관리자는 격리 수준 유지하고, 여러 사람이 동시에
데이터 붙어도 꼬이지 않도록 동시성(MVCC) 보장한다. -
WAL 관리자: 위에 작성한 저널링을 담당한다.
데이터가 바뀌면 무조건 디스크의 WAL 파일에
그 기록을 먼저 저장하여 지속성을 보장한다. -
체크포인트 관리자는 메모리에만 머물고 있는 변경된 데이터들을
주기적으로 모아서 실제 디스크 파일로 안전하게 밀어 넣는 타이밍을 잡는다. -
백그라운드 프로세스는 뒤에서 묵묵히 찌꺼기 데이터를
청소하는Autovacuum이나 로그를 백업하는Archiver등이 있다.
-
-
데이터 저장 및 물리적 구조 (최종 디스크 저장소, 아래 계층)
-
컴퓨터가 꺼져도 데이터가 영원히 보존되는 물리적인 디스크 영역
-
데이터 파일(테이블/인덱스)은 실제 테이블 데이터가 8KB 크기의 조각(페이지)
단위로 쪼개져서 저장되는 곳이다. -
WAL 파일 (로그): 변경 이력이 순서대로 적히는 공간이다.
정전이 나면 이 파일을 보고 복구하는 것이다. -
설정/제어/임시 파일은 DB의 현재 상태, 정렬할 때 쓰는 임시 공간 등
시스템 운영에 필요한 기능들을 모아놓은 곳이다.
-
B-트리
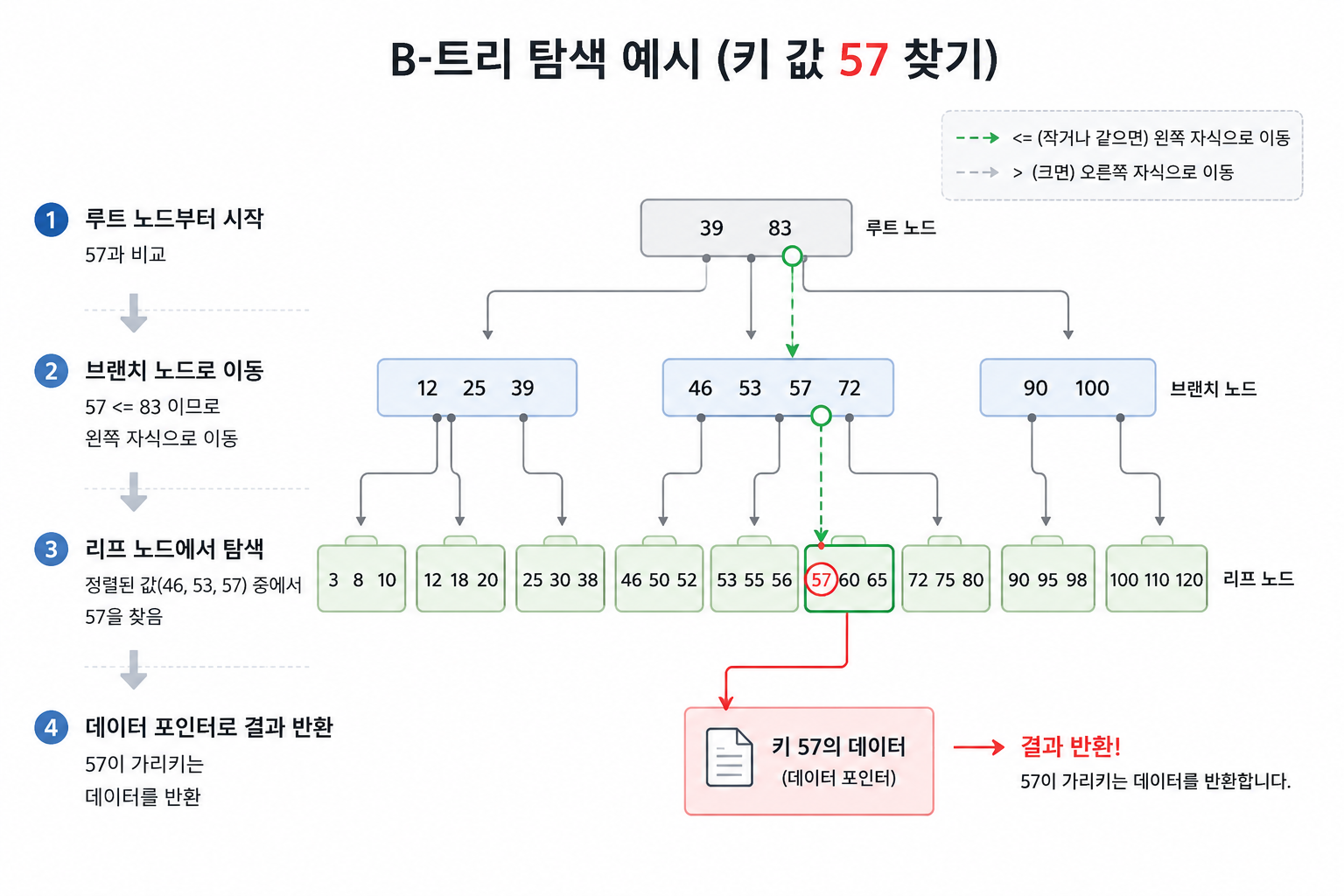
-
B-트리의 각 노드에는 숫자가 정렬되어 들어있고, 그 숫자들은
"내 왼쪽 길은 나보다 작은 숫자들이 있고, 내 오른쪽 길은 나보다 큰 숫자가 있는 곳이다."
라는 이정표 역할을 한다. -
처음에 루트 노드에서 시작하고, 상자에는 [39, 83]이 있다.
기준점 두 개가 있으니 길은 세 갈래로 나뉜다.-
39보다 작거나 같은 동네로 가는 길
-
39보다 크고, 83보다 작거나 같은 동네로 가는 길
-
83보다 큰 동네로 가는 길
-
내가 찾는 57은 39와 83 사이에 있겠네 그럼 가운데 길로 가자
(이렇게 판단한다.)
-
-
가운데 길(브랜치 노드)로 내려왔더니 [46, 53, 57, 72]가 있고,
이번에는 숫자가 4개 있으니 길은 다섯 갈래로 나뉜다.
규칙은 <= (작거나 같으면) 왼쪽 자식으로 이동이기에
이정표의 숫자들을 하나씩 비교해 본다.-
46보다 큰가? Yes
-
53보다 큰가? Yes
-
57보다 작거나 같은가? Yes! (정확히 57과 같다.)
-
57를 찾았네 그럼 규칙에 따라 57 바로 밑에 있는 왼쪽 자식 길로
이동하자! 하면서 리프 노드 쪽으로 내려간다.
-
-
최종 목적지인 리프 노드에 도착했고, 여기에는 57이란 값이 들어있다.
-
리프 노드에 적힌 57은 단순한 숫자가 아닌 진짜 회원 정보 or 게시글 데이터가
디스크 어딘가에 저장되어 있는지 알려주는 데이터 포인터랑 연결되어 있다.
그래서 57이 가리키는 실제 데이터를 디스크에서 뽑아와서 사용자에게 전달한다. -
만약 이런 B-트리 구조가 없다면 데이터가 무작위로 100만 개 있다고 가정하면
57 찾기 위해서 앞에서부터 100만 번을 다 뒤져야 한다.
