데이터 불균형 문제란?
대부분의 분류 알고리즘은 각 클래스의 표본 수가 비슷할 때 각 범주의 특징을 고르게 학습할 수 있다. 하지만 현실 세계의 데이터에서는 특정 클래스의 비중이 극단적으로 작은 경우가 매우 흔하다.
- 표본 수가 많은 클래스 → Majority class
- 표본 수가 적은 클래스 → Minority class
이러한 데이터 불균형 상황에서는 모델이 다수 클래스에 과적합되어,
중요한 소수 클래스에 대한 예측 성능이 크게 저하되는 문제가 발생한다.
현실 세계의 대표적인 불균형 문제
- 암 발생 여부 예측
- 제조업 불량품 탐지
- 신용카드 사기 탐지
- 이상 탐지(Anomaly Detection)
-> 대부분의 경우, ‘정상’보다 ‘이상’을 정확히 잡아내는 것이 핵심 목표가 된다.
데이터 불균형 상황에서 Accuracy의 문제점
EX) 제조업 불량품 탐지
- 정상: 95%
- 불량: 5%
이때 모델이 모든 샘플을 정상으로 예측하면,
- Accuracy = 95%
하지만, 불량을 하나도 탐지하지 못하는 실제로는 전혀 쓸모없는 모델이 된다.
따라서 Accuracy는 불균형 데이터에서 신뢰할 수 없는 지표가 된다.
데이터 불균형 상황에서 적절한 평가 지표
F1 Score
F1 Score = Precision과 Recall의 조화 평균
- Precision: 소수 클래스라고 예측한 것 중 실제로 맞은 비율
- Recall: 실제 소수 클래스 중에서 얼마나 맞췄는가
F1 Score는 소수 클래스 탐지 성능을 균형 있게 평가할 수 있어
불균형 분류 문제에서 가장 널리 사용되는 평가 지표이다.
G-mean
- 양성 클래스 Recall × 음성 클래스 Recall의 기하평균
- 한쪽 클래스만 잘 맞추면 값이 낮아짐
- 두 클래스의 균형 잡힌 성능을 평가
-> 불균형 데이터에 비교적 강건한 지표
Sampling 기반 해결 방법
Undersampling
다수 클래스의 샘플을 제거하여 소수 클래스와 비율을 맞추는 방식
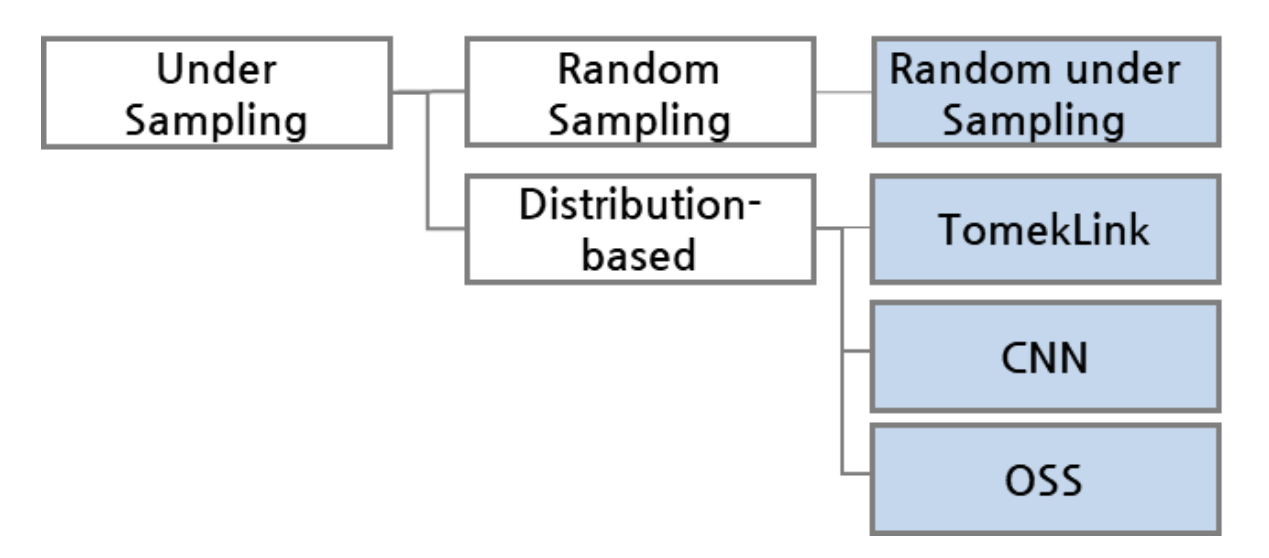
Random Undersampling
-
다수 클래스에서 무작위로 샘플 제거
-
장점: 계산 비용이 낮고 빠름
-
단점:
- 중요한 샘플이 제거될 가능성
- 샘플링마다 분류 경계가 달라질 수 있음
Tomek Links
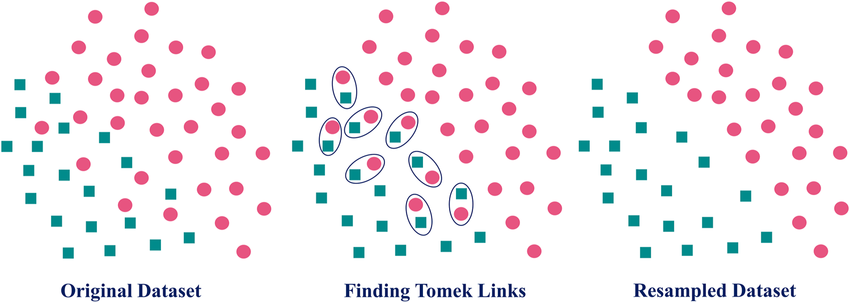
Tomek Link 정의
어떤 관측치 에 대해
를 만족하는 관측치 가 존재하지 않는 경우두 샘플 ( x_i, x_j ) 는 Tomek link를 형성한다.
- 두 샘플 서로가 서로의 최근접 이웃(Nearest Neighbor) 이다.
- 서로 다른 클래스 샘플이 서로의 가장 가까운 이웃이면 → Tomek link 형성
- 이 중 다수 클래스 샘플을 제거한다.
-> 결정 경계를 더 명확하게 만드는 효과
CNN (Condensed Nearest Neighbor Rule)
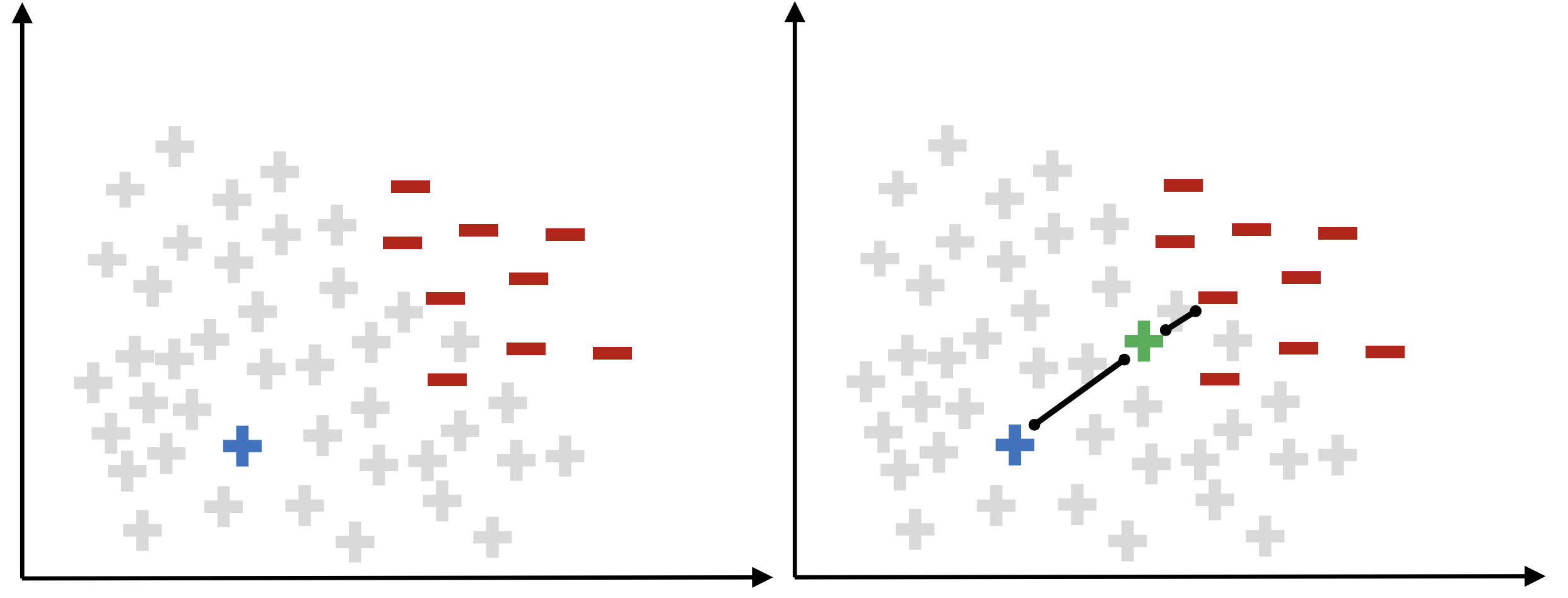
- 다수 클래스에서는 무작위로 일부 샘플 선택
- 소수 클래스에서는 모든 샘플 유지
- 1-NN으로 원본 데이터를 분류
- 정상적으로 분류된 다수 클래스 샘플 제거
-> 경계에 중요한 샘플만 남기는 방식
One-Sided Selection (OSS)
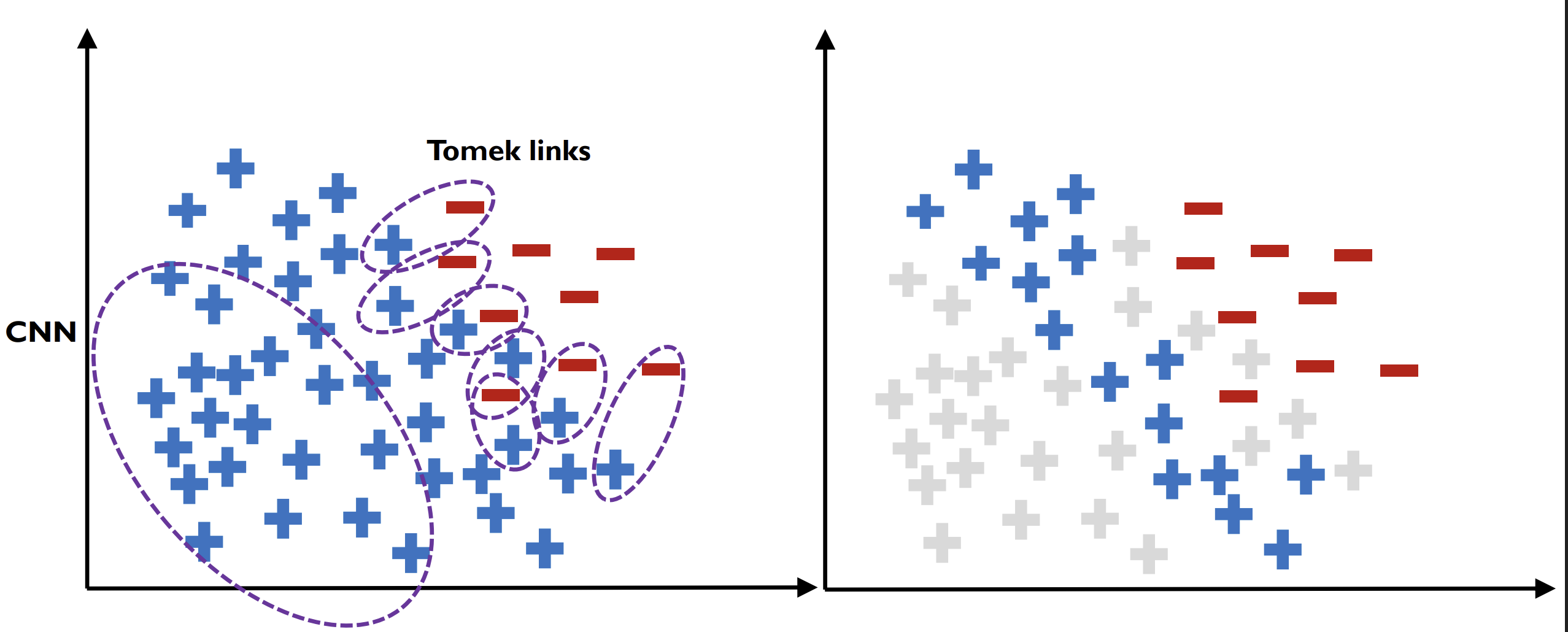
Tomek Links + CNN 결합 방식
- Tomek Links → 경계 근처 noisy 데이터 제거
- CNN → 경계에서 멀리 떨어진 다수 클래스 제거
-> 불필요한 다수 클래스 샘플을 효율적으로 제거
Oversampling
소수 클래스의 샘플 수를 증가시키는 방법
Random Over-Sampling
소수 클래스 샘플을 단순 복제
단점: 소수 클래스에 대한 과적합 위험
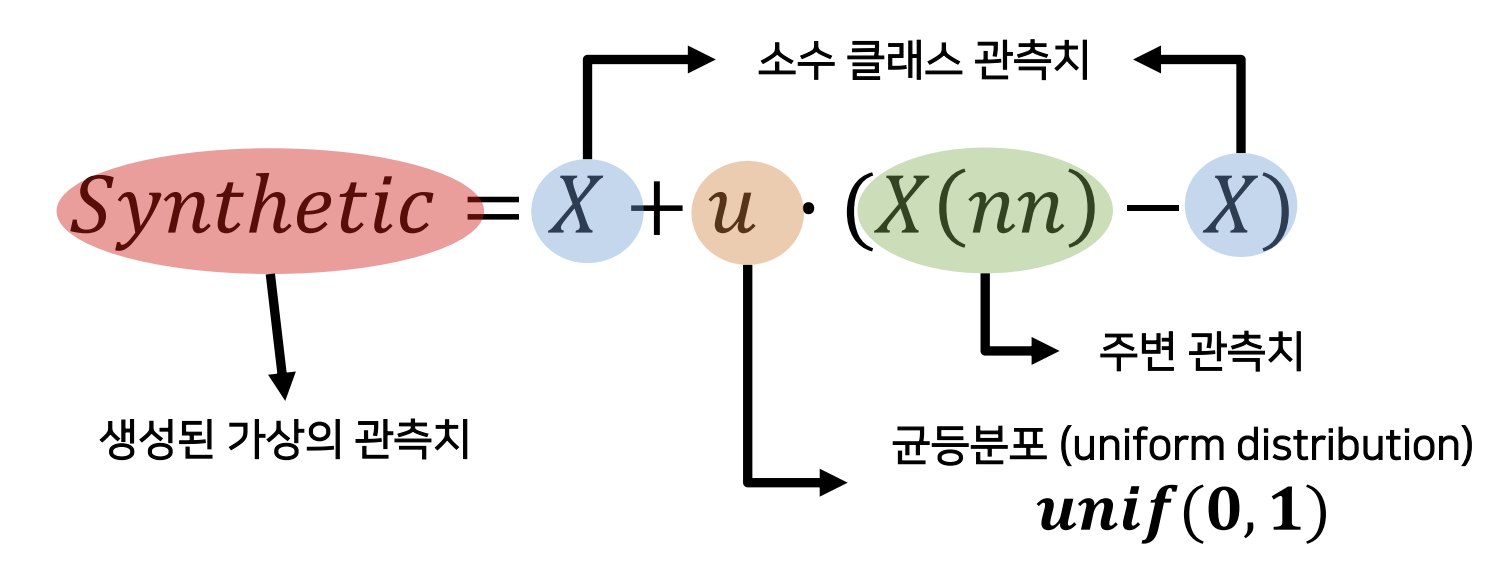
SMOTE
(Synthetic Minority Oversampling Technique)
소수 클래스에서 가상의 새로운 샘플 생성
절차
- 소수 클래스 샘플 하나 선택
- K개의 최근접 이웃 선택 (예: K=5)
- 이웃 중 하나를 무작위로 선택
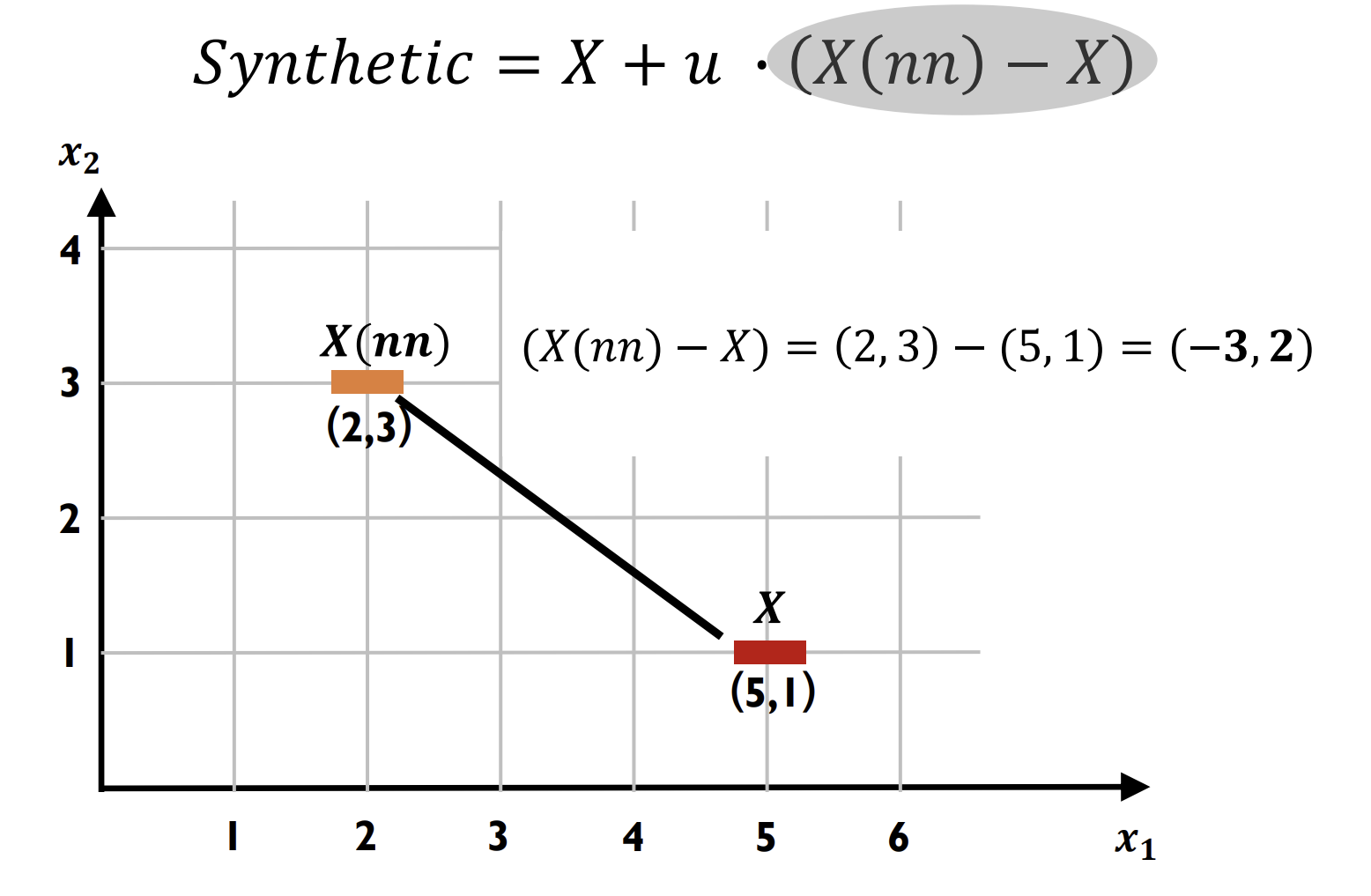
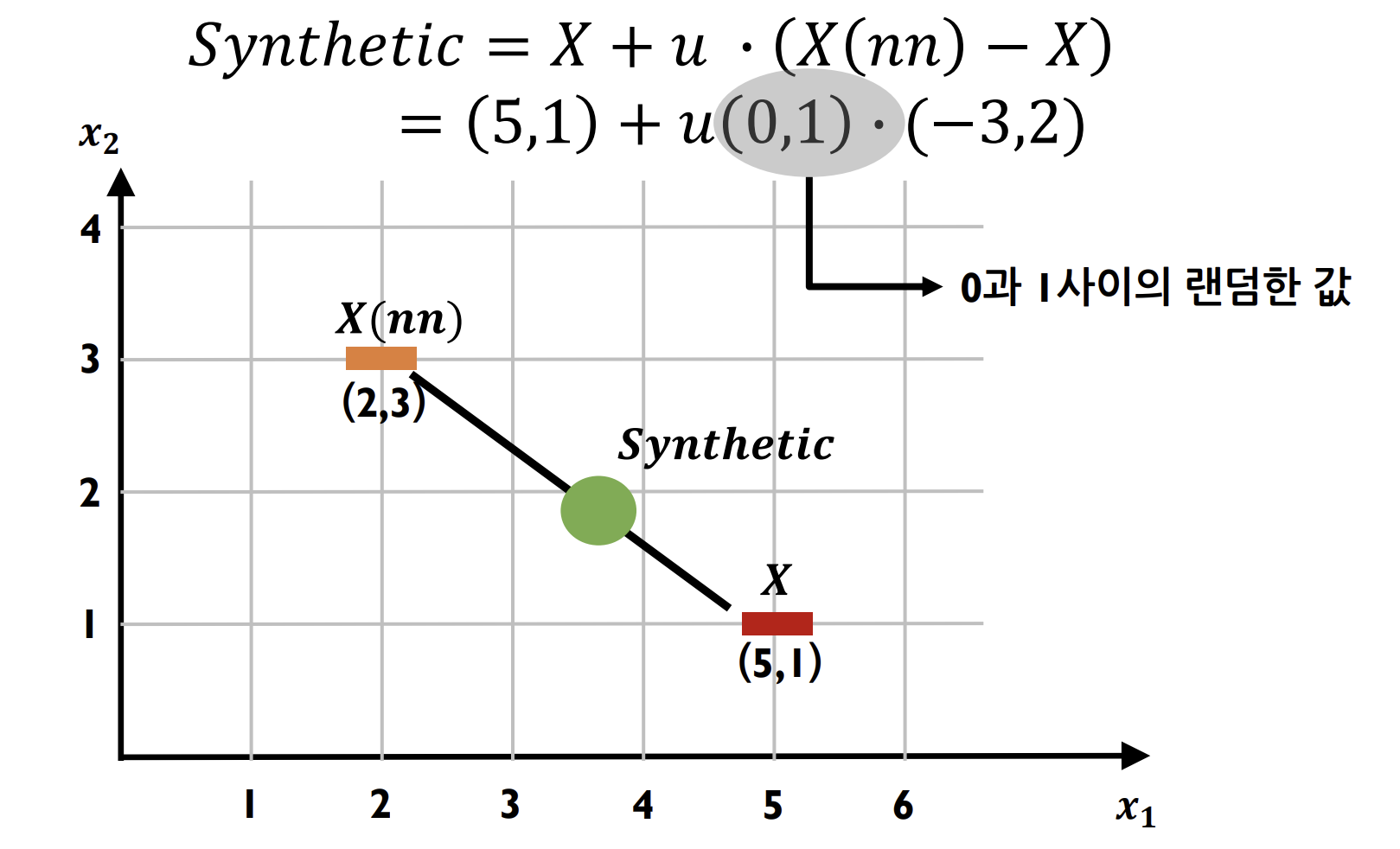
- 두 점 사이에서 새로운 샘플 생성
두 점 간 차이 계산
새로운 관측치 생성
모든 소수 클래스에 대해 반복
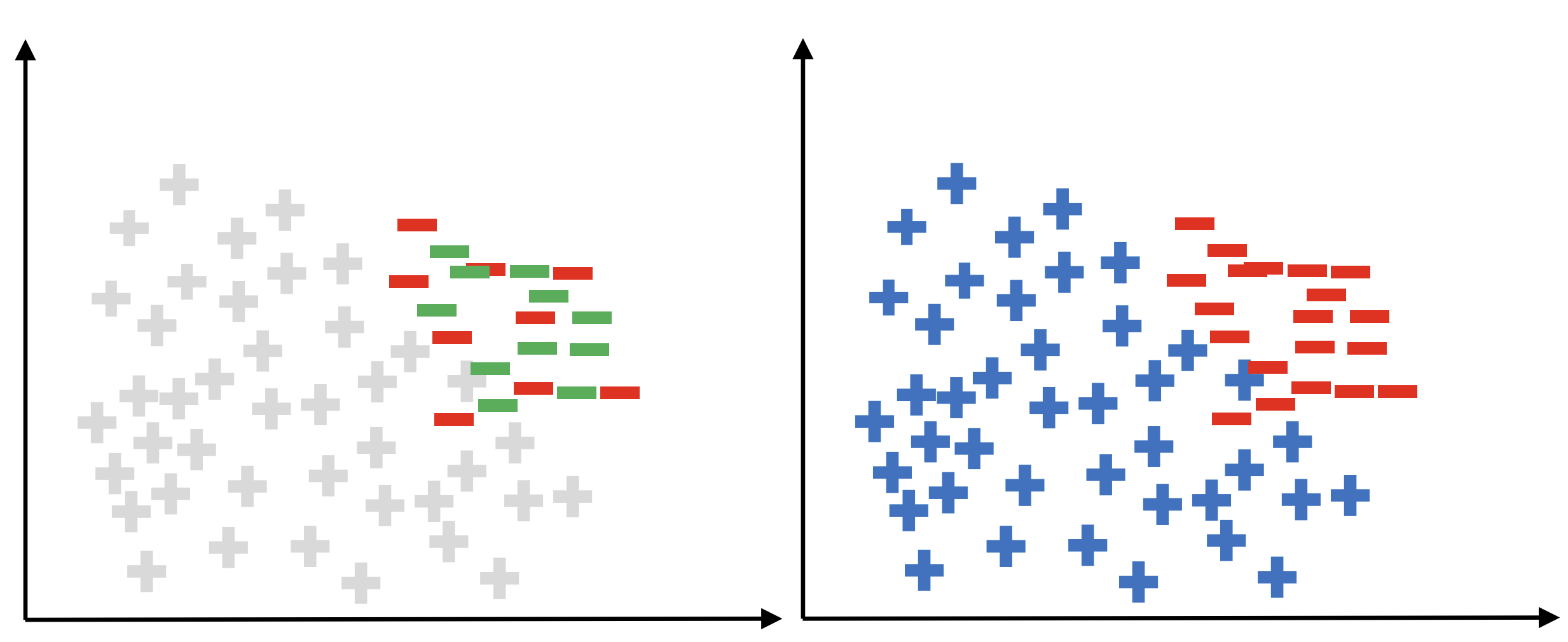
장점
- 단순 복제보다 일반화 성능 우수
단점
- 클래스 경계가 겹치는 경우 노이즈 생성 가능
Borderline-SMOTE
- 분류 경계 근처의 샘플에 집중
핵심 개념
-
소수 클래스 샘플을 다음과 같이 구분
- Safe
- Borderline
- Noise
-
이 중 Borderline 샘플에 대해서만 Oversampling 수행
ADASYN
(Adaptive Synthetic Sampling)
Borderline-SMOTE보다 한 단계 더 나아간 방식
-
다수 클래스 이웃이 많은 샘플일수록 더 많은 synthetic sample 생성
-
자동(adaptive)으로 생성 비율 조절
-
학습이 어려운 영역에 집중
