Loss Function
손실 함수(Loss Function)는 모델의 예측값이 실제 값과 얼마나 차이가 나는지를 수치적으로 나타내는 함수이다. 모델 학습의 목표는 이 손실 값을 최소화하는 방향으로 파라미터를 업데이트하는 것이다
따라서 어떤 손실 함수를 선택하느냐는 모델 성능에 매우 중요한 요소가 된다.
Cross-Entropy Loss의 한계
분류 문제에서 가장 널리 사용되는 손실 함수는 Cross-Entropy Loss이다.
Cross-Entropy는 모델이 예측한 확률 분포와 실제 정답 분포 사이의 차이를 측정한다.
그러나 Cross-Entropy Loss는 클래스 불균형(Class Imbalance)에 취약하다는 한계를 가진다.
Hard Example과 Easy Example을 구분하지 못함
- Easy example: 이미 잘 맞히는 샘플
- Hard example: 모델이 반복적으로 틀리는 샘플
Cross-Entropy는 이미 잘 맞히는 easy example에도 동일한 loss을 부여한다.
결과적으로 중요한 hard example에 충분히 분류하지 못하는 문제가 발생한다.
이를 보완하기 위해 class weight를 추가한 Balanced Cross-Entropy가 활용된다.
Balanced Cross-Entropy
Balanced Cross-Entropy는
각 클래스에 가중치(α)를 부여하여 클래스 불균형 문제를 완화한다.
- α는 클래스 빈도의 역수이거나 하이퍼파라미터로 설정 가능
하지만 이 방식 역시 hard / easy example을 구분하지는 못한다는 한계를 가진다.
→ 이 문제를 해결하기 위해 등장한 것이 Focal Loss이다.
Focal Loss
Focal Loss의 핵심 아이디어는 다음과 같다.
“잘 맞히는 샘플의 영향은 줄이고,
모델이 어려워하는 샘플에 더 집중하자.”
이를 위해 Cross-Entropy Loss에 modulating factor(조절 항) 를 추가한다.
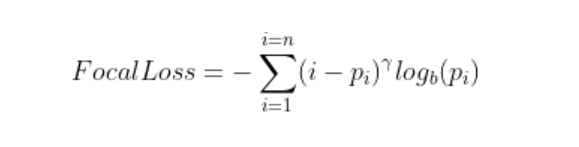
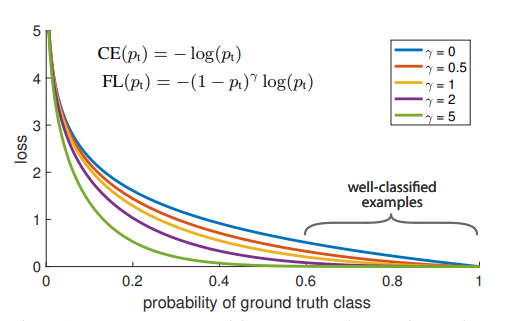
γ (Gamma)의 역할
-
gamma = 0
→ 일반적인 Cross-Entropy Loss와 동일 -
gamma > 0
- 예측 확률 𝑝𝑡가 큰 easy sample
→ loss 값이 크게 감소 - 예측 확률 𝑝𝑡가 작은 hard sample
→ loss 값이 거의 유지됨
- 예측 확률 𝑝𝑡가 큰 easy sample
즉, 모델이 이미 잘 맞히는 샘플보다, 틀리는 샘플에 집중하게 된다.
Cost-sensitive Learning 관점에서의 Focal Loss
Focal Loss는 본질적으로 Cost-sensitive Learning의 확장된 형태로 볼 수 있다.
- Cost-sensitive Learning
→ 소수 클래스의 오류에 더 큰 비용 부여 - Focal Loss
→ 소수 클래스 + hard example에 더 큰 비용 부여
특히 불균형 데이터에서는
- 다수 클래스 샘플 = easy example
- 소수 클래스 샘플 = hard example
인 경우가 많기 때문에, Focal Loss는 자연스럽게 클래스 불균형 문제까지 완화하는 효과를 가진다.
References
https://towardsdatascience.com/focal-loss-a-better-alternative-for-cross-entropy-1d073d92d075/
