Docker 설치
⇒ Windows나 Mac에서는 Docker Desktop을 다운로드 받아서 설치
⇒ Windows에 설치할 때는 WSL(Windows Subsystem for Linux - 윈도우즈 안에서 리눅스 환경을 직접 실행할 수 있게 해주는 도구)이 설치되어야 한다.
{ Docker desktop 다운로드 하고 로그인 한 후 wsl --update하면 끝 }
Kafka
⇒ 개요
- LinkedIn에서 파편화된 데이터 수집 및 분배 아키텍쳐를 운영하는데 큰 어려움을 겪어서 이를 해결하기 위해 만든 시스템
- 내부 데이터 흐름을 개선하기 위해 개발
- 카프카는 각각의 애플리케이션끼리 연결해서 데이터를 처리하는 것이 아니고 한곳에 모아 처리할 수 있는 중앙 집중화 방식을 사용하는 것이 가능
- 카프카를 통해 웹 사이트, 애플리케이션, 센서 등에서 취합한 데이터 스트림을 한 곳에서 실시간으로 관리할 수 있게 된 것
- 대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있게 만들어주는 일종의 중추 신경으로 동작
- 카프카를 중앙에 배치해서 소스 애플리케이션과 타켓 애플리케이션 사이의 의존도를 최소화해서 커플링을 완화
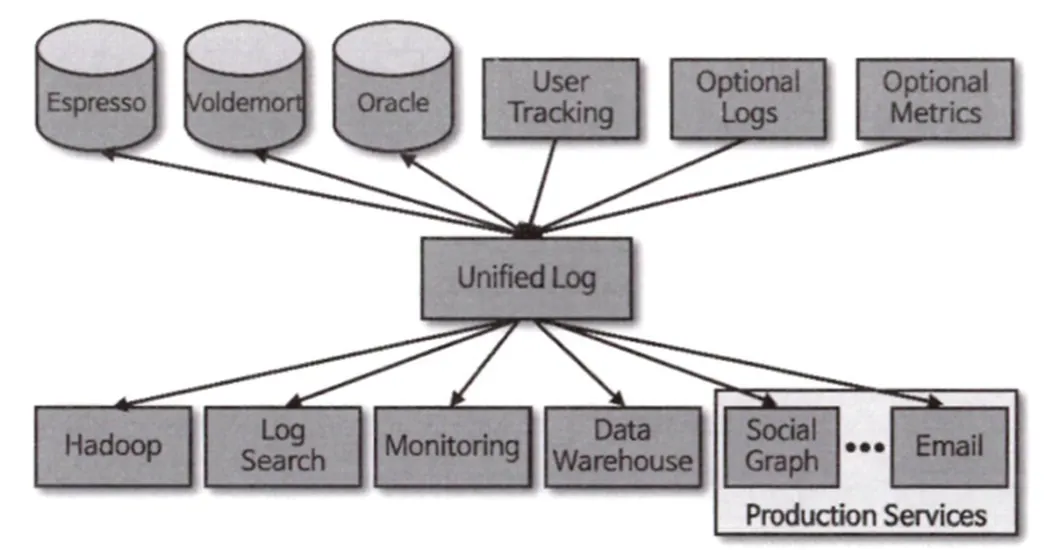
- 기존에 1:1 매칭으로 개발하고 운영하던 데이터 파이프 라인은 커플링으로 인해 한쪽의 이슈가 다른 한쪽의 애플리케이션에 영향을 미치곤 했지만 카프카는 이러한 의존도를 타파
- 소스 애플리케이션에서는 어떤 애플리케이션으로 데이터를 보낼지 고민하지 않고 카프카로 넣으면 카프카 내부에 데이터를 저장하고 타켓 애플리케이션은 이 데이터를 소비
- 데이터가 저장되는 자료구조는 Queue(FIFO) 방식
- 큐에 데이터를 보내는 것을 프로듀서라고 하고 큐에서 데이터를 가져가는 것이 컨슈머
- 카프카를 통해 전달받을 수 있는 데이터 포맷은 제한이 없다.
- 상용 환경에서는 최소 3대 이상의 서버에서 분산 운영하여 프로듀서를 통해 전송받은 데이터를 파일 시스템에 안전하게 기록
- 넷플릭스의 경우에는 36개 이상의 클러스터에 브로커가 4000개 이상으로 운영
⇒ 사용 이유
- 높은 처리량
- 확장성 : Scale In과 Scale Out이 쉽다.
카프카의 Scale In과 Scale Out은 무중단 서비스 { kubernetes와 마찬가지 } - 영속성 : 파일 시스템에 데이터 저장 가능
카프카에 문제가 생겨서 카프카가 재부팅 되더라도 카프카는 데이터를 소유하고 있다. - 고가용성
3개 이상의 서버로 하나의 클러스터를 구성하기 때문에 일부 서버에 장애가 발생해도 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있다.
docker-compose.yml 파일 생성
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181- docker-compose 실행
docker-compose up -d- 명령어로 확인
docker ps- 컨테이너 내부로 들어가서 설정을 수정
docker exec -it kafka /bin/bash# vi가 없으면 파일 복사로 해결
vi /opt/kafka/config/server.properties이 부분 주석을 해제
listeners=PLAINTEXT://:9092
이 부분은 추가
delete.topic.enable=true
auto.create.topics.enable=true
-
파일 복사
도커 컨테이너에서 호스트 컴퓨터로 파일 복사
docker cp [컨테이너이름]:[컨테이너 내부 경로][호스트 파일 경로]docker cp kafka:/opt/kafka/config/server.properties C:\Users\USER\Downloads\Cloud\Kafka호스트에서 도커 컨테이너로 파일을 복사
docker cp [호스트 파일 경로][컨테이너이름]:[컨테이너 내부 경로]docker cp C:\Users\USER\Downloads\Cloud\Kafka\server.properties kafka:/opt/kafka/config/server.properties
⇒ kafka 테스트
- 카프카 컨테이너 내부 접속
docker exec -it kafka /bin/bash- 카프카 명령어가 있는 디렉토리로 이동
cd /opt/kafka/bin- topic(데이터) 생성
kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic exam-topic- 토픽 리스트 조회
kafka-topics.sh --bootstrap-server localhost:9092 --list- topic(데이터) 삭제
kafka-topics.sh --delete --zookeeper zookeeper:2181 --topic exam-topic- 게시
kafka-console-producer.sh --topic exam-topic --broker-list localhost:9092- 구독 { producer가 게시한 것들을 처음부터 받는다.(구독한 모두에게) }
kafka-console-consumer.sh --topic exam-topic --bootstrap-server localhost:9092 --from-beginningCQRS
⇒ 개요
- Command and Query Responsibility Segregation의 약자로 데이터 저장소로부터 읽기와 업데이트 작업을 분리하는 패턴
- 애플리케이션의 퍼포먼스, 확장성, 보안성을 극대화할 수 있고 시스템의 유연성을 바탕으로 시간이 지나면서 지속적으로 시스템을 발전시켜 나갈 수 있고 여러 요청으로 들어온 복수의 업데이트 명령들에 대한 충돌도 방지할 수 있다.
⇒ 전통적인 방식의 문제점
- 전통적인 아키텍쳐는 데이터베이스에서 데이터를 조회하고 업데이트 하는데 동일한 데이터 모델을 사용한다.
- 간단한 CRUD 작업에 대해서라면 문제없이 동작하는데 애플리케이션은 데이터 조회 시 각기 다른 형태의 DTO들에 대해 객체 매핑을 하게 되는데 이로 인해 복잡성이 증가하고 데이터를 쓰거나 업데이트 할 때는 유효성 검사와 비즈니스 로직이 수행되어야 하는데 이 모든 걸 하나의 데이터 모델이 수행하면 너무 많은 것을 수행하는 복잡한 모델이 된다.
- 읽기와 쓰기의 부하는 보통 같지 않기 때문에 각각 다른 성능이 요구된다.
- 읽기와 쓰기 작업에서 사용되는 데이터의 표현이 다를 수 있다.
- 병렬로 작업하면 데이터 경합이 발생
- 보안 관리도 복잡
⇒ 해결책
- CQRS는 읽기와 쓰기를 각각 다른 모델로 분리하는데 명령(Command)을 통해 데이터를 쓰고 Query를 이용해서 데이터를 읽는다.
- 명령은 데이터 중심적이 아니라 수행할 작업 중심이 되어야 한다.
- 명령은 보통 동기적으로 처리되기 보다는 비동기적으로 큐에 쌓인 후 수행
- 쿼리는 데이터베이스를 절대로 수정하지 않는데 쿼리는 어떠한 도메인 로직도 캡슐화하지 않은 DTO 만을 반환
- 읽기/쓰기 모델은 서로 격리될 수 있는데 이렇게 읽기/쓰기 모델을 분리하는 것은 애플리케이션 디자인과 구현을 더욱 간단하게 만들어주지만 CQRS 코드는 ORM 룰을 통해 DB 스키마로부터 자동으로 생성되도록 할 수 없다는 단점이 있다.
- 확실한 격리를 위해서 물리적으로 읽기와 쓰기를 분리할 수 있는데 읽기 DB의 경우 복잡한 조인문이나 ORM 매핑을 방지하기 위해서 materialized view를 가지는 조회에 최적화된 별도의 DB 스키마를 가질 수 있도록 만드는 것으로 단지 다른 DB 스키마가 아니라 아예 다른 타입의 데이터 저장소를 사용할 수도 있는데 쓰기는 RDBMS를 사용하고 읽기의 경우 MongoDB와 같은 NoSQL을 사용하는 것
- 별도의 읽기/쓰기 데이터 저장소가 사용된다면 반드시 동기화가 이루어져야 하는데 보통 이는 쓰기 모델이 DB에 수정사항이 발생할 때 마다 이벤트를 발행함으로써 이뤄지고 DB 업데이트와 이벤트 발행은 반드시 하나의 트랜잭션(하나의 메서드 안에서 수행하고 이벤트 발행이 안되면 데이터베이스 업데이트 작업도 취소되어야 한다) 안에서 이루어져야 한다.
- 읽기 저장소는 단순히 쓰기 저장소의 레플리카 일 수도 있고 완전히 다른 구조를 가질 수도 있는데 보통 읽기 저장소가 쓰기보다 훨씬 더 많은 부하를 받게 된다.
- CQRS의 장점 독립적인 스케일링 : 읽기와 쓰기 각각에 대해 독립적으로 스케일링이 가능해지고 훨씬 더 적은 Lock 경합이 발생하는 것을 가능하게 한다. 최적화된 데이터 스키마 : 읽기 저장소는 쿼리에 최적화된 스키마를 사용할 수 있고 쓰기 저장소는 쓰기에 최적화된 스키마를 사용할 수 있다. 보안 : 읽기와 쓰기를 분리함으로써 보안 관리가 용이 관심사 분리 : 읽기와 쓰기에 대한 관심사 분리는 시스템의 유지 보수를 더 쉽게 해주고 유연하게 해주는데 대부분의 복잡한 비즈니스 로직은 쓰기 모델에 들어가고 읽기 모델은 상대적으로 간단한 로직만 포함 간단한 쿼리 : 읽기 저장소의 materialized view(쿼리의 실행 결과를 실제 물리적인 테이블처럼 저장장치에 물리적으로 저장해놓은 데이터베이스 객체)를 통해서 복잡한 조인문을 사용하지 않을 수 있다.
⇒ 구현 이슈
- 복잡성 : 이벤트 소싱 패턴을 포함할 경우 복잡해질 수 있다.
- 메시징 : CQRS의 필수 요소는 아니지만 명령을 수행하고 업데이트 이벤트를 발행하는 것이 보편적인 사용법인데 이 경우 애플리케이션은 반드시 메시지 실패나 중복 메세지와 같은 것들에 대한 처리를 해야 한다.
- 데이터 일관성 : 읽기와 쓰기가 분리된다면 읽기 데이터가 최신의 데이터가 아닐 수도 있는데 읽기 저장소에는 쓰기 저장소의 변경 사항들이 반영되어야 하는데 이에는 딜레이가 발생하게 된다.
⇒ CQRS를 사용해야 하는 경우
- 많은 사용자가 동일한 데이터에 대해 병렬적으로 엑세스하는 도메인
- 복잡한 프로세스나 도메인 모델을 통해 가이드되는 작업 기반 사용자 인터페이스 : 쓰기 모델은 비즈니스 로직, 유효성 검사 등을 가진 완전한 명령 처리 기능을 가지며 관련된 객체들의 집합을 하나의 단위로 다룰 수 있도록 만들어야 한다.
- 테이터 읽기의 성능이 데이터 쓰기의 성능과 별도로 조정이 가능해야 할 때
- 한팀은 쓰기 모델에 대한 도메인 모델에만 집중해야 하고 다른 한 팀은 사용자 인터페이스에 대한 읽기 모델에만 집중해야 할 때
- 시스템이 시간이 지남에 따라 계속해서 진화하고 여러 버전을 가질 수 있으며 정기적으로 바뀔 수 있는 경우
- 다른 시스템과의 통합
⇒ CQRS 사용이 권장되지 않는 경우
- 도메인과 비즈니스 로직이 간단한 경우
- 단순한 CRUD 작업일 때
⇒ 이벤트 소싱과 CQRS 패턴
- 이벤트가 실행되어 저장소가 수정되기 전 약간의 딜레이가 있을 수 있다.
- 읽기 모델에서 오랜 기간 동안의 데이터 합계나 분석 자료와 같은 것들이 필요할 때 오랜 시간이 걸릴 수 있는데 이런 경우에는 일정 간격으로 데이터의 스냅샷을 만들어서 시간을 단축할 수 있다.
CQRS 구현
⇒ 애플리케이션은 파이썬의 Django와 React를 이용해서 개발하고 데이터베이스는 MySQL과 MongoDB 사용
⇒ 준비 작업
-
MySQL이나 Maria DB 같은 RDBMS를 설치하고 접속 확인
-
데이터 읽기에 사용할 MongoDB 설치하고 접속 확인
-
Kafka 설치하고 접속 확인
-
PostgreSQL을 설치
my-postgres는 컨테이너 이름 변경 가능
1234 도 postgres 사용자의 비밀번호
docker run --name my-postgres -e POSTGRES_PASSWORD=1234 -p 5432:5432 -d postgres⇒ 데이터 기록 프로젝트
- 가상환경 생성
python -m venv myvenv - 가상환경 활성화
Linux & Mac : source myvenv/bin/activatemyvenv\Scripts\activate
- MySQL을 사용할 거라면 python 버전을 12이하로 낮춰서 사용
- 필요한 패키지 설치
pip install django pip install djangorestframework pip install psycopg2-binary # postgresql을 사용 시 - 장고 프로젝트 생성과 앱 생성
django-admin startproject writebook
cd writebook
python manage.py startapp writeapp- settings.py 파일 수정
from pathlib import Path
import pymysql
pymysql.install_as_MySQLdb
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"rest_framework",
"writeapp"
]
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'postgres',
'USER': 'postgres',
'PASSWORD': '1234',
'HOST': '127.0.0.1',
'PORT': '5432'
}
}
TIME_ZONE = 'Asia/Seoul'- URL 처리(Controller에서 수행하는 부분)
프로젝트의 urls.py 파일을 수정
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('cqrs/', include("writeapp.urls")) # cqrs/로 시작하는 url은 writeapp의 urls.py 파일이 처리
]- writeapp 앱에 urls.py 파일을 추가로 작성하고 작성
from django.urls import path
from .views import helloAPI
urlpatterns = [
path("hello/", helloAPI)
]- writeapp의 views.py 파일에 helloPAI라는 함수를 작성
from rest_framework.response import Response
from rest_framework.decorators import api_view
@api_view(['GET'])
def helloAPI(request):
return Response('hello world')- 프로젝트 실행
python manage.py runserver 127.0.0.1:7000- 확인은 브라우저에서 수행
http://127.0.0.1:7000/cqrs/hello- 데이터베이스 연동에 사용할 모델 생성 : writeapp에 models.py 파일을 생성하고 작성
from django.db import models
# Create your models here.
class Book(models.Model):
bid = models.AutoField(primary_key=True)
title = models.CharField(max_length=50)
author = models.CharField(max_length=50)
category = models.CharField(max_length=50)
pages = models.IntegerField()
price = models.IntegerField()
published_date = models.DateField()
description = models.TextField()- 데이터베이스에 반영
python manage.py makemigrations writeapp
python manage.py migrate- 직렬화에 사용할 클래스를 생성 : writeapp에 serializers.py 파일을 생성하고 작성
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = ['bid', 'title', 'category', 'pages', 'price', 'published_date', 'description']- views.py 내용 추가
from rest_framework.response import Response
from rest_framework.decorators import api_view
from .models import Book
from .serializers import BookSerializer
from rest_framework import status
@api_view(['GET'])
def helloAPI(request):
return Response('hello world')
# POST 방식의 요청이 온 경우 처리
@api_view(['POST'])
def bookAPI(request):
# 클라이너트에서 넘겨준 데이터를 가져오기
data = request.data
# 웹에서 넘어온 데이터는 문자열이므로 숫자로 변환
data['pages'] = int(data['pages'])
data['price'] = int(data['price'])
# 데이터베이스에 삽입 가능하도록 변환
serializer = BookSerializer(data=data)
# 삽입
if(serializer.is_valid()):
serializer.save()
return Response(serializer.data, status = status.HTTP_201_CREATED)
return Response(serializer.errors, status = status.HTTP_400_BAD_REQUEST)- url 연결 : writeapp의 urls.py에 추가
from django.urls import path
from .views import helloAPI, bookAPI
urlpatterns = [
path("hello/", helloAPI),
path("book/", bookAPI)
]⇒ Client 프로젝트
- node.js가 설치되지 않았으면 설치 한 후 수행
- 리액트 프로젝트 생성 : npx create-react-app react_cqrs
- 디렉토리 이동
cd react_cqrs - 패키지 설치
npm install --save --legacy-peer-deps @material-ui/core
npm install --save --legacy-peer-deps @material-ui/icons
npm install -g yarn
yarn add axios- 화면 디자인 : 프로젝트 src 디렉토리에 AddBook.jsx 추가
import React , { useState }from "react"
import { TextField, Paper, Button, Grid } from "@material-ui/core";
function AddToDo(props) {
const [title, setTitle] = useState("");
const [author, setAuthor] = useState("");
const [category, setCategory] = useState("");
const [pages, setPages] = useState("");
const [price, setPrice] = useState("");
const [published_date, setPublished_date] = useState("");
const [description, setDescription] = useState("");
const onTitleChange = (event) => {
setTitle(event.target.value);
};
const onAuthorChange = (event) => {
setAuthor(event.target.value);
};
const onCategoryChange = (event) => {
setCategory(event.target.value);
};
const onPagesChange = (event) => {
setPages(event.target.value);
};
const onPriceChange = (event) => {
setPrice(event.target.value);
};
const onPublished_dateChange = (event) => {
setPublished_date(event.target.value);
};
const onDescriptionChange = (event) => {
setDescription(event.target.value);
};
const onSubmit = (event) => {
event.preventDefault();
const book = {}
book.title=title
book.author = author
book.category = category
book.pages = pages
book.price = price
book.published_date = published_date
book.description = description
props.add(book)
setTitle("")
setAuthor("")
setCategory("")
setPages("")
setPrice("")
setPublished_date("")
setDescription("")
};
return(
<Paper style={{ margin: 16, padding: 16 }}>
<Grid container>
<Grid xs={6} md={6} item style={{ paddingRight: 16 }}>
<TextField
onChange={onTitleChange}
value = {title}
placeholder="Add Book Title"
fullWidth
/>
</Grid>
<Grid xs={6} md={6} item style={{ paddingRight: 16 }}>
<TextField
onChange={onAuthorChange}
value = {author}
placeholder="Add Book Author"
fullWidth
/>
</Grid>
<Grid xs={3} md={3} item style={{ paddingRight: 16 }}>
<TextField
onChange={onCategoryChange}
value = {category}
placeholder="Add Book Category"
fullWidth
/>
</Grid>
<Grid xs={3} md={3} item style={{ paddingRight: 16 }}>
<TextField
onChange={onPagesChange}
value = {pages}
placeholder="Add Book Pages"
fullWidth
/>
</Grid>
<Grid xs={3} md={3} item style={{ paddingRight: 16 }}>
<TextField
onChange={onPriceChange}
value = {price}
placeholder="Add Book Price"
fullWidth
/>
</Grid>
<Grid xs={3} md={3} item style={{ paddingRight: 16 }}>
<TextField
onChange={onPublished_dateChange}
value = {published_date}
placeholder="Add Book Published_Date"
fullWidth
/>
</Grid>
<Grid xs={11} md={11} item style={{ paddingRight: 16 }}>
<TextField
onChange={onDescriptionChange}
value = {description}
placeholder="Add Book Description"
fullWidth
/>
</Grid>
<Grid xs={1} md={1} item>
<Button
fullWidth
color="secondary"
variant="outlined"
onClick={onSubmit}
>
+
</Button>
</Grid>
</Grid>
</Paper>
);
}
export default AddToDo;- App.js 파일에 처리를 위한 코드 추가
import './App.css';
import { Paper } from '@material-ui/core';
import AddToDo from './AddBook';
import Axios from "axios"
function App() {
const add = (book) => {
Axios.post("http://127.0.0.1:7000/cqrs/book/", book).then(response) => {
if(response.data.bid) {
alert("삽입에 성공")
} else {
alert("삽입 실패")
}
}
}
return (
<div className="App">
<Paper style={{ margin: 16 }}>
<AddBook add = {add}/>
</Paper>
</div>
);
}
export default App;
⇒ 몽고 데이터베이스에서 데이터를 읽어오는 프로젝트
- 가상 환경 생성 및 활성화
python -m venv myvenv
myvenv\Scripts\activate- 필요한 패키지 설치
pip install django
pip install djangorestframework
pip install psycopg2-binary # postgresql을 사용 시
pip install pymongo
pip install django-cors-headers # 자바스크립트 프로젝트에서 서버의 데이터를 ajax로 사용하도록 하기 위해서- 프로젝트 생성
django-admin startproject readbook- 앱 생성
cd readbook
python manage.py startapp readapp- settings.py 수정
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"rest_framework",
"readapp",
"corsheaders"
]
MIDDLEWARE = [
"corsheaders.middleware.CorsMiddleware",
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
CORS_ORIGIN_WHITELIST=['http://127.0.0.1:3000','http://localhost:3000']
CORS_ALLOW_CREDENTIALS=True
- 실행 및 확인
python manage.py runserver 127.0.0.1:8000
http://127.0.0.1:8000- 앱이 시작하자 마자 postgresql과 mongodb 데이터를 일치시키는 작업
apps.py 파일에 함수를 수정(애플리케이션이 시작하자마자 동작하는 함수)
from django.apps import AppConfig
import psycopg2
from pymongo import MongoClient
from datetime import datetime
class ReadappConfig(AppConfig):
default_auto_field = "django.db.models.BigAutoField"
name = 'readapp'
def ready(self):
print("시작하자마자 실행")
# postgresql에 접속
con = psycopg2.connect(
host = "localhost",
database = "postgres",
user="postgres",
password="1234",
port="5432"
)
# mongoDB 연결
conn = MongoClient('mongodb://localhost:27017')
# 기존 데이터 삭제
db = conn.cqrs
collect = db.books
collect.delete_many({})
# postgresql에서 데이터 읽어오기
cursor = con.cursor()
cursor.execute("select * from writeapp_book")
data = cursor.fetchall()
# print(data)
# 데이터를 읽어서 MongoDB에 삽입
for imsi in data:
date = imsi[6].strftime("%Y-%m-%d")
doc = {'bid':imsi[0], 'title':imsi[1], 'author':imsi[2],
'category':imsi[3], 'pages':imsi[4], 'price':imsi[5],
'published_date':date, 'description':imsi[7]}
collect.insert_one(doc)
con.close- settings.py 파일 수정
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"rest_framework",
"corsheaders",
"readapp.apps.ReadappConfig"
]- 읽기를 처리할 URL을 생성
프로젝트의 urls.py 파일을 수정
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('cqrs/', include('readapp.urls'))
]- 애플리케이션에 urls.py 파일을 생성하고 url과 처리할 함수를 매핑
from django.urls import path
from .views import bookAPI
urlpatterns = [
path("books/", bookAPI)
]- 애플리케이션의 views.py 파일에 bookAPI 함수를 작성
from django.shortcuts import render
from rest_framework.response import Response
from rest_framework.decorators import api_view
from rest_framework import status
from pymongo import MongoClient
from bson import json_util
import json
@api_view(['GET'])
def bookAPI(request):
conn = MongoClient('127.0.0.1')
db = conn.cqrs
collect = db.books
result = collect.find()
data = []
for r in result:
data.append(r)
return Response(json.loads(json_util.dumps(data)),
status=status.HTTP_201_CREATED)- 서버를 구동하고 /cqrs/books를 요청
python manage.py runserver 127.0.0.1:8000
http://127.0.0.1:8000/cqrs/books⇒ 쓰기 프로젝트에서 Kafka를 연동해서 데이터 쓰기를 할 떄 kafka에 토픽을 전달
- Kafka
pip install kafka-python - writeapp의 views.py 수정
from rest_framework.response import Response
from rest_framework.decorators import api_view
from .models import Book
from .serializers import BookSerializer
from rest_framework import status
# 카프카에 게시를 하기 위한 라이브러리
from kafka import KafkaProducer
import json
# Producer 클래스
class MessageProducer:
def __init__(self, broker, topic):
self.broker = broker
self.topic = topic
self.producer = KafkaProducer(
bootstrap_servers=self.broker,
value_serializer=lambda x: json.dumps(x).encode("utf-8"),
acks=0,
api_version=(2, 5, 0),
key_serializer=str.encode,
retries=3,
)
def send_message(self, msg, auto_close=True):
try:
future = self.producer.send(self.topic, value=msg, key="key")
self.producer.flush()
if auto_close:
self.producer.close()
future.get(timeout=2)
return {"status_code":200, "error":None}
except Exception as exc:
raise exc
@api_view(['GET'])
def helloAPI(request):
return Response('hello world')
# POST 방식의 요청이 온 경우 처리
@api_view(['POST'])
def bookAPI(request):
# 클라이너트에서 넘겨준 데이터를 가져오기
data = request.data
# 웹에서 넘어온 데이터는 문자열이므로 숫자로 변환
data['pages'] = int(data['pages'])
data['price'] = int(data['price'])
# 데이터베이스에 삽입 가능하도록 변환
serializer = BookSerializer(data=data)
# 삽입
if(serializer.is_valid()):
# 데이터 삽입
serializer.save()
#카프카에 이벤트를 발행
broker = ["localhost:9092"]
topic = "cqrstopic"
pd = MessageProducer(broker, topic)
# 데이터와 작업 내역을 한꺼번에 전송
msg ={"task":"insert","data":serializer.data}
res = pd.send_message(msg)
print(res)
return Response(serializer.data, status = status.HTTP_201_CREATED)
return Response(serializer.errors, status = status.HTTP_400_BAD_REQUEST)- 확인
서버를 구동하고 데이터를 1개 삽입하고 카프카에 접속해서 토픽이 생성되는지 확인
⇒ 테이터 읽기 프로젝트에서 카프카 토픽 추가
- 패키지 다운로드
pip install kafka-python - app.py를 수정 { kafka에 cqrstopic 추가 필요 }
from django.apps import AppConfig
import psycopg2
from pymongo import MongoClient
from datetime import datetime
from kafka import KafkaConsumer
import json
import threading
# 카프카 컨슈머 클래스
class MessageConsumer:
def __init__(self, broker, topic):
self.broker = broker
self.consumer = KafkaConsumer(
topic, bootstrap_server=self.broker,
value_deserializer=lambda x: x.decode("utf-8"),
group_id="my-group", auto_offset_reset="earlist",
enable_auto_commit=True,)
def receive_message(self):
try:
for message in self.consumer:
# 카프카로부터 가져온 데이터를 JSON 파싱을 수행해서 딕셔너리로 변환
result = json.loads(message.value)
# data 부분만 추출
imsi = result["data"]
# data를 MongoDB에 삽입할 수 있는 구조로 변경
doc = {'bid':imsi['bid'],
'title':imsi['title'],
'author':imsi['author'],
'category':imsi['category'],
'pages':imsi['pages'],
'price':imsi['price'],
'published_date':imsi['published_date'],
'description':imsi['description']}
# mongo db에 데이터 삽입
conn = MongoClient('mongodb://localhost:27017')
db = conn.cqrs
collect = db.books
# 실제로는 task를 확인해서 작업해야 한다.
collect.insert_one(doc)
conn.close()
except Exception as exc:
raise exc
class ReadappConfig(AppConfig):
default_auto_field = "django.db.models.BigAutoField"
name = 'readapp'
def ready(self):
print("시작하자마자 실행")
# postgresql에 접속
con = psycopg2.connect(
host = "localhost",
database = "postgres",
user="postgres",
password="1234",
port="5432"
)
# mongoDB 연결
conn = MongoClient('mongodb://localhost:27017')
# 기존 데이터 삭제
db = conn.cqrs
collect = db.books
collect.delete_many({})
# postgresql에서 데이터 읽어오기
cursor = con.cursor()
cursor.execute("select * from writeapp_book")
data = cursor.fetchall()
# print(data)
# 데이터를 읽어서 MongoDB에 삽입
for imsi in data:
date = imsi[6].strftime("%Y-%m-%d")
doc = {'bid':imsi[0], 'title':imsi[1], 'author':imsi[2],
'category':imsi[3], 'pages':imsi[4], 'price':imsi[5],
'published_date':date, 'description':imsi[7]}
collect.insert_one(doc)
con.close
broker = ["localhost:9092"]
topic = "cqrstopic"
# broker와 topic 정보를 이용해서 컨슈머를 생성
consumer = MessageConsumer(broker,topic)
# 메시지를 받는 메서드를 스레드로 등록해서 실행
t = threading.Thread(traget=consumer.receive_message)
t.start()