5장 사용자를 파악하기 위한 데이터 추출
- 사용자의 행동 패턴으로 속성을 정의하는 방법과 서비스 실태를 확인하는 지표를 알아보자
- 코드에서 중복 쿼리는 일부 생략함
11강 사용자 전체의 특징과 경향 찾기
벤 다이어그램으로 사용자 액션 집계하기
SQL SIGN함수, SUM함수, CASE식, CUBE구문
- 서비스 내부의 여러 기능을 모두 사용하는 사용자는 많지 않다.
따라서 각 기능의 사용 상황을 조사해야 한다.
SELECT *
FROM action_log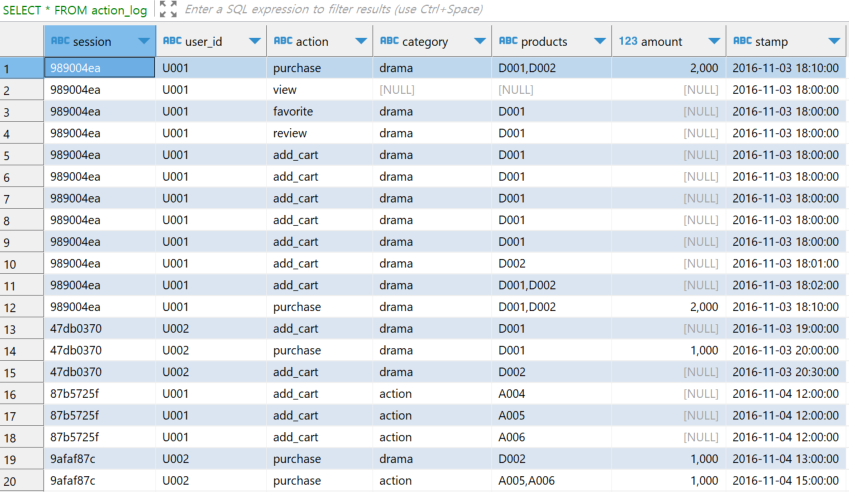
코드 11-11
WITH user_action_flag AS (
-- 사용자가 액션을 했으면 1, 안 했으면 0으로 플래그 붙이기
SELECT user_id
, SIGN(SUM(CASE WHEN ACTION = 'purchase' THEN 1 ELSE 0 END)) AS has_purchase
, SIGN(SUM(CASE WHEN ACTION = 'review' THEN 1 ELSE 0 END)) AS has_review
, SIGN(SUM(CASE WHEN ACTION = 'favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id
)
SELECT *
FROM user_action_flag| user_id | has_purchase | has_review | has_favorite |
|---|---|---|---|
| U002 | 1.0 | 0.0 | 0.0 |
| U001 | 1.0 | 1.0 | 1.0 |
SIGN( ) : 양수이면 1, 음수이면 -1을 반환한다.
이유는 나중에 RFM 분석에서 사용될 RFM 스코어를 계산할 때, 고객의 행동이 있는지 없는지 여부를 -1로 표시하여 더 나은 분석 결과를 얻기 위해서 (링크)
코드 11-12 (postgreSQL)
WITH action_venn_diagram AS (
-- 모든 액션 조합 구하기
SELECT has_purchase
, has_review
, has_favorite
, COUNT(1) AS users
FROM user_action_flag
GROUP BY CUBE(has_purchase, has_review, has_favorite)
)
SELECT *
FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite| has_purchase | has_review | has_favorite | users |
|---|---|---|---|
| 1.0 | 0.0 | 0.0 | 1 |
| 1.0 | 0.0 | 1 | |
| 1.0 | 1.0 | 1.0 | 1 |
| 1.0 | 1.0 | 1 | |
| 1.0 | 0.0 | 1 | |
| 1.0 | 1.0 | 1 | |
| 1.0 | 2 | ||
| 0.0 | 0.0 | 1 | |
| 0.0 | 1 | ||
| 1.0 | 1.0 | 1 | |
| 1.0 | 1 | ||
| 0.0 | 1 | ||
| 1.0 | 1 | ||
| 2 |
COUNT(1) : 해당 그룹의 행(row) 수를 세는 집계 함수. 1은 실제로 의미 없는 값이고, 열의 값이 NULL이 아닌 경우에만 해당 값의 개수를 계산
CUBE( ) : postgreSQL만 가능. 여러 그룹화 집합을 생성한다.
일반적으로 CUBE( )에 지정된 열 수가 n개 이면 2^n개의 조합이 있다. (링크)CUBE(c1,c2,c3) -- 조합은 8개 GROUPING SETS ( (c1,c2,c3), (c1,c2), (c1,c3), (c2,c3), (c1), (c2), (c3), () )
코드 11-13(표준 SQL)
WITH user_action_flag AS (
-- 사용자가 액션을 했으면 1, 안 했으면 0으로 플래그 붙이기
SELECT user_id
, SIGN(SUM(CASE WHEN ACTION = 'purchase' THEN 1 ELSE 0 END)) AS has_purchase
, SIGN(SUM(CASE WHEN ACTION = 'review' THEN 1 ELSE 0 END)) AS has_review
, SIGN(SUM(CASE WHEN ACTION = 'favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id
)
, action_venn_diagram AS (
-- 모든 액션 조합을 개별적으로 구하고 UNION ALL 로 결합
-- 3개의 액션을 모두 한 경우 : 2row
SELECT has_purchase, has_review, has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review, has_favorite
-- 3개의 액션 중 2개의 액션을 한 경우 : 6
UNION ALL
SELECT NULL AS has_purchase, has_review, has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_review, has_favorite
UNION ALL
SELECT has_purchase, NULL AS has_review, has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_favorite
UNION ALL
SELECT has_purchase, has_review, NULL AS has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review
-- 3개의 액션 중 1개의 액션을 한 경우 : 5
UNION ALL
SELECT NULL AS has_purchase, NULL AS has_review, has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_favorite
UNION ALL
SELECT NULL AS has_purchase, has_review, NULL AS has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_review
UNION ALL
SELECT has_purchase, NULL AS has_review, NULL AS has_favorite, COUNT(1) AS users
FROM user_action_flag
GROUP BY has_purchase
-- 액션과 관계 없이 모든 사용자 집계 : 1
UNION ALL
SELECT NULL AS has_purchase, NULL AS has_review, NULL AS has_favorite, COUNT(1) AS users
FROM user_action_flag
)
SELECT *
FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite모든 미들웨어에서 동작하지만, UNION ALL 사용으로 성능은 좋지 않다.
UNION ALL을 연결할 때는 공백이 있는 줄이 있으면 에러 발생..
벤 다이어그램 만들기 위해 가독성 높게 결과를 가공하면..
코드 11-15
SELECT
-- 0, 1 플래그를 문자열로 가공하기
CASE has_purchase
WHEN 1 THEN 'purchase' WHEN 0 THEN 'not purchase' ELSE 'any'
END AS has_purchase
, CASE has_review
WHEN 1 THEN 'review' WHEN 0 THEN 'not review' ELSE 'any'
END AS has_review
, CASE has_favorite
WHEN 1 THEN 'favorite' WHEN 0 THEN 'not favorite' ELSE 'any'
END AS has_favorite
, users
-- 전체 사용자 수를 기반으로 비율 구하기
, 100.0 * users / NULLIF(
-- 모든 액션이 NULL인 사용자 수가 전체 사용자 수를 나타내므로
-- 해당 레코드의 사용자 수를 윈도우 함수로 구하기
SUM(CASE WHEN has_purchase IS NULL
AND has_review IS NULL
AND has_favorite IS NULL
THEN users ELSE 0 end) over()
, 0)
AS ratio
FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite| has_purchase | has_review | has_favorite | users | ratio |
|---|---|---|---|---|
| any | any | any | 2 | 100.0000000000000000 |
| any | any | favorite | 1 | 50.0000000000000000 |
| any | any | not favorite | 1 | 50.0000000000000000 |
| any | not review | any | 1 | 50.0000000000000000 |
| any | not review | not favorite | 1 | 50.0000000000000000 |
| any | review | any | 1 | 50.0000000000000000 |
| any | review | favorite | 1 | 50.0000000000000000 |
| purchase | any | any | 2 | 100.0000000000000000 |
| purchase | any | favorite | 1 | 50.0000000000000000 |
| purchase | any | not favorite | 1 | 50.0000000000000000 |
| purchase | not review | any | 1 | 50.0000000000000000 |
| purchase | not review | not favorite | 1 | 50.0000000000000000 |
| purchase | review | any | 1 | 50.0000000000000000 |
| purchase | review | favorite | 1 | 50.0000000000000000 |
NULLIF(expr1, expr2) : expr1 = expr2 이면 NULL, 그렇지 않으면 expr1을 반환한다.
이 함수는 보통 분모가 0일 때 오류를 방지하고자 할 때 많이 사용되어 expr1가 0인 경우 NULL로 반환
-
[그림 11-6] 처럼 사용자 형태를 벤다이어그램으로 나타낼 수 있다.
-
어떤 액션을 수행했을 때, 효과가 발생한 사용자가 얼마나 되는지 벤 다이어그램으로 확인하면, 액션을 제대로 세웠는지 확인할 수 있다.
Decile 분석을 사용해 사용자를 10단계 그룹으로 나누기
SQL NTILE 윈도 함수
- 사용자 특징을 분석할 때 성별, 연령 같은 데모그래픽한 데이터가 존재하지 않는 경우, 사용자 액션으로 특징을 정의해보는 것도 방법
- 데이터를 10단계로 분할해서 중요도를 파악하는
Decile분석방법을 알아보자. - 사용자의 구매 금액에 따라 순위를 구분하고 중요도를 구분하는 단계는 다음과 같다.
- 사용자를 구매 금액이 많은 순으로 정렬
- 상위부터 10%씩 Decile1 ~ 10까지 그룹을 할당
- 그룹별 구매 금액 합계를 구함
- (각 Decile 그룹 / 전체 구매 금액) 으로 구매 금액 비율을 계산
- 상위에서 누적으로 어느 정도 비율을 차지하는지 구성비 누계를 집계
RFM 분석으로 사용자를 3가지 관점의 그룹으로 나누기
SQL CASE식, generate_series 함수
- 6절에서 사용자의 구매 금액 합계를 기반으로 10개 그룹으로 분석해봄
- Decile분석은 검색 기간에 따라 고객 분류가 달라질 수 있다.
RFM분석은 Decile분석보다 자세하게 사용자를 그룹으로 나누는 방법이다.
RFM 분석의 3가지 지표 집계하기
- Recency : 최근 구매일
Frequency : 구매 횟수
Monetary : 구매 금액 합계 - 즉, 사용자별로 얼마나 최근에, 얼마나 자주, 얼마나 많은 금액을 지출했는지에 따라
사용자들의 분포를 확인하거나 사용자 그룹(또는 등급)을 나누어 분류하는 분석 기법
코드 11-19
SELECT *
FROM action_log
WITH purchase_log AS (
SELECT user_id
, amount
-- 타임스탬프 기반으로 날짜 추출하기
, SUBSTRING(stamp, 1, 10) AS dt
FROM action_log
WHERE action = 'purchase'
)
, user_rfm AS (
SELECT user_id
, MAX(dt) AS recent_date
, CURRENT_DATE - MAX(dt::date) AS recency
FROM purchase_log
GROUP BY user_id
)
SELECT *
FROM user_rfm| user_id | recent_date | recency | frequency | monetary |
|---|---|---|---|---|
| U001 | 2016-11-03 | 2380 | 2 | 4000 |
| U002 | 2016-11-04 | 2379 | 3 | 3000 |
::는 PostgreSQL에서 타입 캐스팅(type casting) 연산자. 이 연산자로 다른 데이터 타입으로 변환할 수 있다.dt::date는 timestamp을 date 타입으로 캐스팅하여 날짜 정보만 추출한다.
CURRENT_DATE : 2023-05-11 이다.
RFM 랭크 정의하기
- RFM분석에서는 3개 지표를 각 5개 그룹으로 나누는 것이 일반적이고 사용자를 125개의 그룹으로 파악할 수 있다.
[표 11-4] 테이블 참고
코드 11-20
WITH user_rfm_rank AS (
SELECT user_id
, recent_date
, recency
, frequency
, monetary
, CASE
WHEN recency < 14 THEN 5
WHEN recency < 28 THEN 4
WHEN recency < 60 THEN 3
WHEN recency < 90 THEN 2
ELSE 1
END AS r
, CASE
WHEN 20 <= frequency THEN 5
WHEN 10 <= frequency THEN 4
WHEN 5 <= frequency THEN 3
WHEN 2 <= frequency THEN 2
WHEN 1 = frequency THEN 1
END AS f
, CASE
WHEN 300000 <= monetary THEN 5
WHEN 100000 <= monetary THEN 4
WHEN 30000 <= monetary THEN 3
WHEN 5000 <= monetary THEN 2
ELSE 1
END AS m
FROM user_rfm
)
SELECT *
FROM user_rfm_rank| user_id | recent_date | recency | frequency | monetary | r | f | m |
|---|---|---|---|---|---|---|---|
| U001 | 2016-11-03 | 2380 | 2 | 4000 | 1 | 2 | 1 |
| U002 | 2016-11-04 | 2379 | 3 | 3000 | 1 | 2 | 1 |
코드 11-21
WITH mst_rfm_index AS (
-- 1부터 5까지의 숫자를 가지는 테이블 만들기
SELECT 1 AS rfm_index
UNION ALL SELECT 2 AS rfm_index
UNION ALL SELECT 3 AS rfm_index
UNION ALL SELECT 4 AS rfm_index
UNION ALL SELECT 5 AS rfm_index
)
, rfm_flag AS (
SELECT mst.rfm_index
, CASE WHEN mst.rfm_index = rnk.r THEN 1 ELSE 0 END AS r_flag
, CASE WHEN mst.rfm_index = rnk.f THEN 1 ELSE 0 END AS f_flag
, CASE WHEN mst.rfm_index = rnk.m THEN 1 ELSE 0 END AS m_flag
FROM mst_rfm_index AS mst
CROSS JOIN user_rfm_rank AS rnk
)
SELECT rfm_index
, SUM(r_flag) AS r
, SUM(f_flag) AS f
, SUM(m_flag) AS m
FROM rfm_flag
GROUP BY rfm_index
ORDER BY rfm_index DESC| rfm_index | r | f | m |
|---|---|---|---|
| 5 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 |
| 2 | 0 | 2 | 0 |
| 1 | 2 | 0 | 2 |
SELECT n AS rfm_index : rfm_index 컬럼에 n 값을 가진 레코드를 생성
CROSS JOIN : 한 쪽 테이블의 모든 행들과 다른 테이블의 모든 행을 조인
여기서 125개 그룹은 관리하기 어려워서 적은 그룹 수로 관리하는 방법을 알아보자
사용자를 1차원으로 구분하기
- RFM 각 랭크 합계를 기반으로 13개 그룹(3~15)으로 나누어 관리하는 방법
코드 11-22
WITH user_rfm AS (
SELECT user_id
, MAX(dt) AS recent_date
, CURRENT_DATE - MAX(dt::date) AS recency
, COUNT(dt) AS frequency
, SUM(amount) AS monetary
FROM purchase_log
GROUP BY user_id
)
, user_rfm_rank AS (
SELECT user_id
, recent_date
, recency
, frequency
, monetary
, CASE
WHEN recency < 14 THEN 5
WHEN recency < 28 THEN 4
WHEN recency < 60 THEN 3
WHEN recency < 90 THEN 2
ELSE 1
END AS r
, CASE
WHEN 20 <= frequency THEN 5
WHEN 10 <= frequency THEN 4
WHEN 5 <= frequency THEN 3
WHEN 2 <= frequency THEN 2
WHEN 1 = frequency THEN 1
END AS f
, CASE
WHEN 300000 <= monetary THEN 5
WHEN 100000 <= monetary THEN 4
WHEN 30000 <= monetary THEN 3
WHEN 5000 <= monetary THEN 2
ELSE 1
END AS m
FROM user_rfm
)
SELECT r + f + m AS total_rank
, r, f, m
, COUNT(user_id)
FROM user_rfm_rank
GROUP BY r, f, m
ORDER BY total_rank DESC, r DESC, f DESC, m DESC| total_rank | r | f | m | count |
|---|---|---|---|---|
| 4 | 1 | 2 | 1 | 2 |
이어서 종합 랭크별 사용자 수를 집계
코드 11-23
SELECT r + f + m AS total_rank
, COUNT(user_id)
FROM user_rfm_rank
GROUP BY total_rank
ORDER BY total_rank DESC| total_rank | count |
|---|---|
| 4 | 2 |
2차원으로 사용자 인식하기
- RFM 지표 2개를 사용해서 사용자 층을 정의하는 방법
이번에는 R과 F를 예를 들어 집계해본다.
각 셀에 사용자 수를 집계했다면, 높은 랭크로 사용자를 이동시키려면 어떤 액션이 필요할지 생각해보자.
SELECT *
FROM user_rfm_rank
코드 11-24
SELECT CONCAT('r_', r) AS r_rank
, COUNT(CASE WHEN f = 5 THEN 1 END) AS f_5
, COUNT(CASE WHEN f = 4 THEN 1 END) AS f_4
, COUNT(CASE WHEN f = 3 THEN 1 END) AS f_3
, COUNT(CASE WHEN f = 2 THEN 1 END) AS f_2
, COUNT(CASE WHEN f = 1 THEN 1 END) AS f_1
FROM user_rfm_rank
GROUP BY r
ORDER BY r_rank DESC| r_rank | f_5 | f_4 | f_3 | f_2 | f_1 |
|---|---|---|---|---|---|
| r_1 | 0 | 0 | 0 | 2 | 0 |
CONCAT( ) : 여러 문자열을 이어 붙여 하나의 문자열로 만드는 함수
-
[그림 11-11] 을 보면서 2차원으로 인식한 사용자층을 어떤 액션을 실시할지 생각해보자.
-
RFM 분석의 각 지표에 따라 사용자의 속성을 정의하고 3차원 -> 1차원 -> 2차원으로 표현하는 방법을 살펴봄.
서비스 개선 검토, 사용자에 따른 메일 최적화 등 용도로 활용해보자.
