1.Instroduction
- 모바일 AI의 필요성:
모바일 장치에서의 신경망은 빠르고 실시간으로 상호작용할 수 있는 경험을 제공해야 하며, 개인 데이터를 인터넷을 통해 전송하지 않고도 처리할 수 있는 능력이 필요합니다.
- 효율성과 정확성의 균형:
모바일 장치의 계산 제약으로 인해 정확성과 효율성 간의 균형을 맞추는 것이 큰 도전 과제가 됩니다. 이를 해결하기 위해 새로운 구조와 기법이 필요합니다.
2.UIB와 Mobile MQA의 도입
논문에서는 Universal Inverted Bottleneck (UIB)와 Mobile MQA라는 두 가지 혁신적인 블록을 소개합니다. UIB는 Inverted Bottleneck 구조를 개선하여 더 나은 성능을 제공하며, Mobile MQA는 모바일 가속기를 위한 주의 메커니즘을 최적화합니다.
Universal Inverted Bottleneck (UIB)
Universal Inverted Bottleneck (UIB)는 MobileNetV4 논문에서 제안된 새로운 구조로, 기존의 Inverted Bottleneck 구조를 개선하여 효율성과 성능을 동시에 향상시키기 위해 설계되었습니다. UIB에 대한 주요 특징은 다음과 같습니다
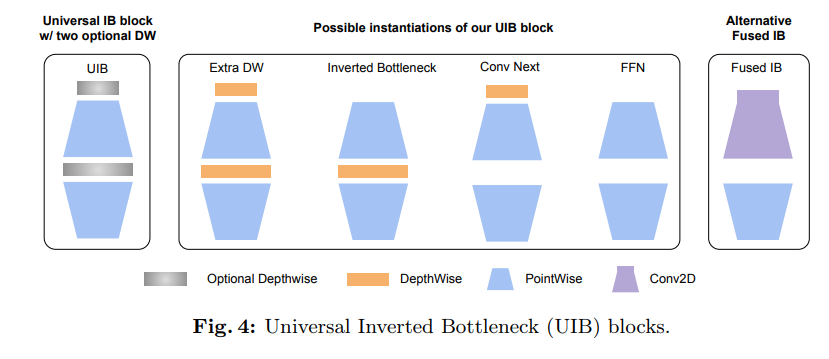
- 구조적 유연성:
UIB는 두 개의 선택적 Depthwise Convolution을 포함하여, 공간적 및 채널 혼합을 유연하게 조정할 수 있는 구조를 제공. 이러한 유연성은 다양한 아키텍처를 통합할 수 있게 하여, 모델의 용량을 증가시키면서도 계산 비용을 줄이는 데 기여.
- 기존 아키텍처 통합:
UIB는 Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN)와 같은 여러 기존 아키텍처를 통합. 이로 인해 UIB는 다양한 기능을 수행할 수 있으며, 각기 다른 요구 사항에 맞춰 최적화된 성능을 제공.
- Extra Depthwise (ExtraDW) 변형:
UIB는 새로운 변형인 ExtraDW를 도입하여, 네트워크의 깊이와 수용 영역을 증가시킬 수 있는 옵션을 제공. 이는 모델의 복잡성을 증가시키지 않으면서도 성능을 향상시킬 수 있는 방법이다.
- 효율적인 NAS:
UIB는 신경망 아키텍처 검색(NAS) 과정에서 최적화된다. 이 과정에서 UIB의 다양한 구성 요소가 자동으로 조정되어, 각 모델 크기에 맞는 최적의 구조를 찾을 수 있다. 이를 통해 모델의 파라미터 수를 줄이고, 계산 효율성을 높임.
- 높은 성능:
UIB는 MobileNetV4 모델이 다양한 모바일 플랫폼에서 높은 정확성과 효율성을 달성할 수 있도록 도운다. 예를 들어, UIB를 사용한 MNv4-Hybrid-L 모델은 87%의 ImageNet-1K 정확도를 기록하면서도 낮은 지연 시간을 유지한다.
Mobile MQA (Mobile Multi-Query Attention):
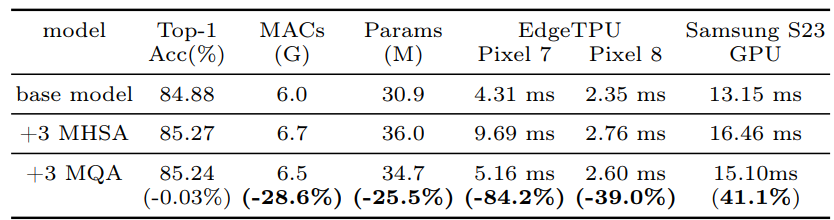
모바일 가속기를 위해 설계된 주의 메커니즘으로, Edge TPU 및 Samsung S23 GPU에서 39% 이상의 추론 속도 향상을 제공하는 새로운 attention block. 이 구조의 주요 특징은 다음과 같습니다.
-
공유된 키와 값: Mobile MQA는 여러 쿼리 헤드가 동일한 키와 값을 공유하는 방식으로 작동한다. 이는 메모리 접근을 줄이고, 계산 효율성을 높이는 데 기여한다. 특히, 배치된 토큰 수가 상대적으로 적을 때, 쿼리 헤드가 키와 값을 공유하는 것이 메모리 접근 요구를 크게 줄일 수 있다.
-
효율적인 연산: Mobile MQA는 Multi-Head Self-Attention (MHSA)와 비교하여 메모리 사용량과 계산량을 줄인다(MACs을 최소화). 이는 모바일 비전 모델에서 주의 메커니즘을 사용할 때, 높은 차원의 특징을 처리하면서도 연산 비용을 최소화할 수 있게 한다.
-
비교적 낮은 정확도 손실: Mobile MQA는 효율성을 높이기 위해 설계되었지만, 정확도 손실이 미미하다. 실험 결과에 따르면, Mobile MQA는 EdgeTPU 및 Samsung S23 GPU에서 39%의 가속을 달성하면서도 정확도 손실이 0.03%에 불과하다는 것을 보여준다.
-
비대칭 공간 다운샘플링: Mobile MQA는 공간적 다운샘플링을 통합하여 키와 값의 해상도를 낮추고, 쿼리는 높은 해상도를 유지한다. 이는 주의 메커니즘의 효율성을 더욱 향상시키며, 모델의 용량을 증가시키는 데 기여한다.
- Mobile MQA block 수식
- 여기서 SR은 spatial reduction, stride가 2인 DW 또는 spatial reduction이 사용되지 않을 경우
identity function을 나타냄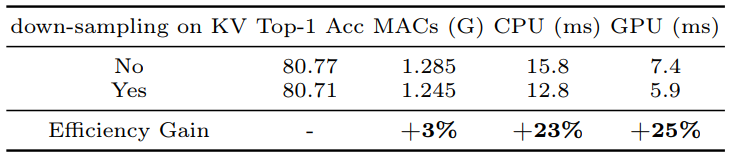
- 모바일 비전 모델에 최적화: Mobile MQA는 모바일 환경에서의 비전 작업에 최적화되어 있으며, 낮은 해상도의 입력에 대해 높은 차원의 특징을 효과적으로 처리할 수 있도록 설계됨. 이는 모바일 디바이스에서의 실시간 처리와 상호작용을 가능하게 한다.
3. Design of MobilenetV4 Models
-
최신 MobileNets를 개발할 때 주요 목표는 다양한 mobile 플랫폼에서 Pareto optimality를 달성하는 것
-
이를 위해 기존 모델과 hardware에 대한 광범위한 상관 분석을 통해 비용 모델(latency 예측)과의 높은 상관관계를 보장하는 구성 요소와 매개 변수를 발견
-
Multi-path efficiency concerns
- Group convolutions 및 multi-path 설계는 낮은 FLOPs에도 불구하고 메모리 접근 복잡성으로 인해 덜 효율적일 수 있음 -
Hardware support matters
- Squeeze and Excite (SE)와 같은 고급 모듈은 DSP에서 잘 지원되지 않음. SE는 accelerator에서 느림 -
The Power of Simplicity
- Depthwise와 pointwise convolutions, ReLU, BatchNorm, 간단한 attention (예: MHSA)은 뛰어난 효율성과 hardware 호환성을 보여줌
Enhanced Search Strategy
-
UIB 블록을 효과적으로 구현하기 위해 TuNAS를 사용하여 성능을 향상
- Coarse-Grained Search
- 최적의 필터 크기를 결정하고 고정 매개 변수를 유지
- 기본 expansion factor가 4인 inverted bottleneck 블록과 3x3 depthwise 커널을 사용
- Coarse-Grained Search
-
Fine-Grained Search
- Initial search 결과를 바탕으로 UIB의 두 개의 depthwise 레이어(포함 여부 및 커널 크기 3x3 또는 5x5)를 search 하며 expansion factor는 4로 유지

- Two stage search를 통해 향상된 효율성과 모델 품질을 위 테이블에서 수치적으로 비교
- 이러한 search 전략을 통해 single stage search 보다 우수한 성능을 발휘함을 입증
- Initial search 결과를 바탕으로 UIB의 두 개의 depthwise 레이어(포함 여부 및 커널 크기 3x3 또는 5x5)를 search 하며 expansion factor는 4로 유지
Enhancing TuNAS with Robust Training
- ImageNet에서의 모델 성능은 data augmentation, normalization, hyperparameter tuning 등에 의해 크게 영향을 받음
- TuNAS [3] 의 진화하는 architecture sampling 때문에 안정적인 hyperparameter set를 찾는 것이 어려움

- JFT distillation dataset을 TuNAS의 training set으로 사용하여 위 테이블에서 보여주는 것처럼 성능 향상을 달성
- Depth-scaled 모델이 width-scaled 모델보다 extended training session에서 더 나은 성능을 발휘
- TuNAS training을 750 epoch으로 expansion하여 더 깊고 높은 품질의 모델을 생성
Optimization of MNv4 Models
- NAS-optimized UIB 블록에서 MNv4-Conv 모델을 구축하여 특정 리소스 제약에 맞춤화
- 주로 hybrid model에서 마지막 단계의 convolution 모델에 attention을 추가하는 것이 가장 효과적
- MNv4-Hybrid 모델에서는 Mobile MQA 블록과 UIB 블록을 결합하여 성능을 향상
4. Results
ImageNet classification
-
ImageNet-1K dataset을 사용하여 모델 아키텍처 성능을 평가
-
다양한 mobile hardware에서 Top-1 accuracy를 측정
-
Experimental Setup
- ARM Cortex CPUs, Qualcomm Hexagon DSP, ARM Mali GPU, Qualcomm Snapdragon, Apple Neural Engine, Google EdgeTPU 등의 hardware에서 테스트
-
Results
- MobileNetv4 모델은 다양한 정확도 목표와 hardware platform에서 대부분 Pareto-optimal 성능을 달성
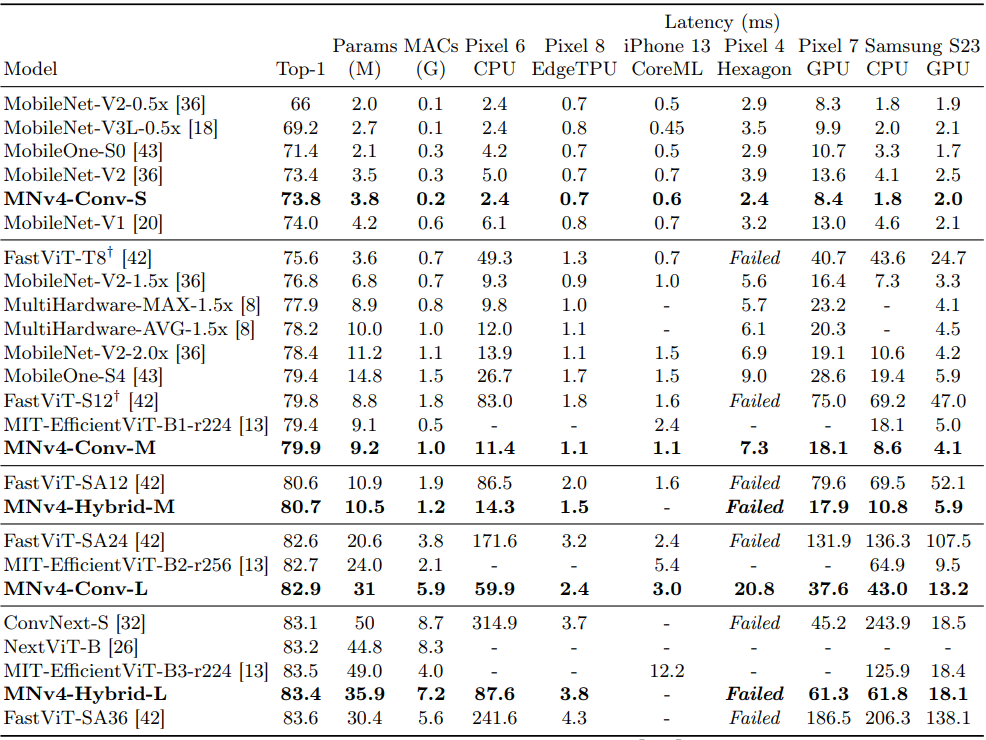
- 특히 CPU에서 MNv4 모델은 MobileNetV3보다 두 배 빠르고, 동일한 정확도 목표에서 다른 모델보다 여러 배 빠름
- EdgeTPUs에서는 MNv4 모델이 동일 정확도 수준에서 MobileNet V3의 두 배 성능을 보여줌
-
COCO Object Detection
- COCO 17 dataset을 사용하여 MNv4 backbone의 object detection 성능을 평가
- Experimental Setup
- RetinaNet framework를 사용하여 object detector를 구축하고, FPN과 convolutional layers를 포함
- 600 epoch 동안 모든 모델을 훈련
- 모든 이미지 크기를 384px로 조정하고 다양한 augmentation을 사용
- Results
- 중간 크기의 convolution-only MNv4-Conv-M detector는 32.6% AP를 달성하며, MobileNet Multi-AVG 및 MobileNet v2와 유사한 성능을 보임
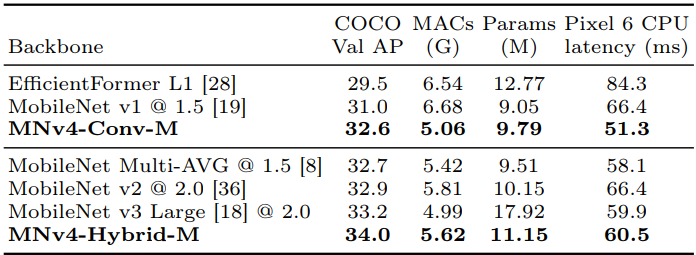
- Pixel 6 CPU latency는 MobileNet Multi-AVG보다 12%, MobileNet v2보다 23% 낮음
- Mobile MQA 블록을 추가하면 AP가 1.6% 증가하여 MNv4의 효율성을 입증
- 중간 크기의 convolution-only MNv4-Conv-M detector는 32.6% AP를 달성하며, MobileNet Multi-AVG 및 MobileNet v2와 유사한 성능을 보임
5.Conclusion
MobileNetV4 series
- MobileNetV4는 다양한 mobile 환경에서 효율적으로 작동하도록 tuning 된 고효율 모델 시리즈
- 여러 가지 발전을 통해 MobileNetV4를 모든 mobile CPU, GPU, DSP, 특수 accelerator에서 대부분 Pareto-optimal하게 만듦
Main contributions
- 새로운 Universal Inverted Bottleneck과 Mobile MQA 레이어를 도입하고 개선된 NAS 레시피와 결합
