머신 러닝
머신 러닝에서 배우는 내용은 방대하며 코드를 다 기억하기 어렵다. 때문에 지금까지 내가 한 학기동안 배웠던 내용을 정리하고자 한다.
미리보기
내가 정리하고 싶은 내용들의 개념을 한번 보자.
성능 측정
머신러니에서 성능을 측정하는 것은 좋은 모델을 만드는 것 만큼 중요하다. 때문에 성능을 어떻게 측정할 것인지 볼 것이다.
결정 트리
구체적인 모델 하나를 공부해보자. 결정 트리란 무엇이고 어떻게 활용하는지 살펴보자.
앙상블
모델을 하나만 쓰기보다는 다양한 모델을 사용해서 모델을 만들기도 한다. 어떤 식을 모델을 같이 활용하는지 살펴보도록 하자.
성능 평가
성능을 평가하는 지표들이 있다. 우리가 흔히 생각했을 때 정확도가 있다. 모델이 전체 예측한 건수에서 결과와 예측이 실제로 맞을 확률이다. 하지만 정확도가 모든 것을 대변해주지 않는다.
예를 들어 생각해보자. 시험문제가 10문제 있다. 나는 10문제를 모두 정답이 1이 아니라고 말한다. 그러면 대충 10 개중에 8개는 내 대답이 맞을 것이다. 그러면 나는 시험 점수가 80점인가?
뭔가 이상하다. 때문에 성능평가를 하는 것이다.
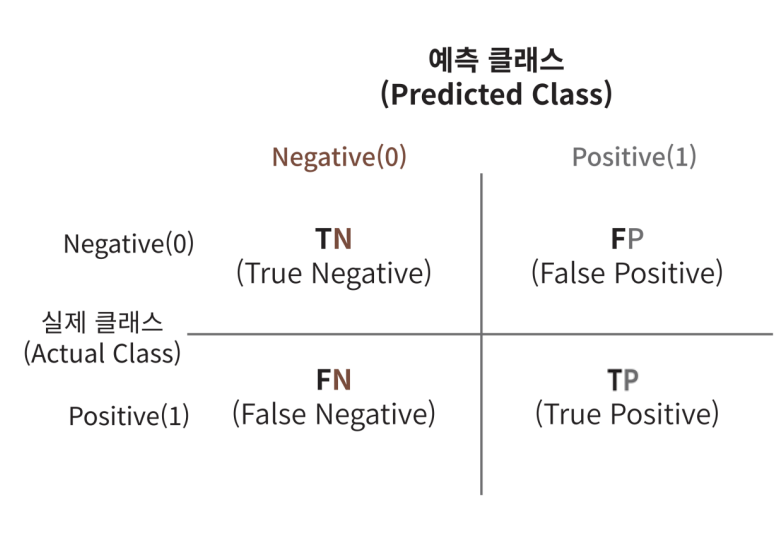
우리는 이것을 좀 더 체계화 해서 오차 행렬이라는 것을 만들었다. 오차행렬 에서 정확도는 (TN + TP) / (TN + FP + FN + FP)가 된다.
우리는 정확도 외에도 정밀도와 재현율이하는 수치를 쓴다. 정밀도 = TP / (FP + TP) 이고, 재현율 = TP / (FN + TP) 이다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, f1_score, roc_auc_score
# 평가지표 출력하는 함수 설정
def get_clf_eval(y_test, y_pred, y_pred_proba):
confusion = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred_proba)
print('오차행렬')
print(confusion)
print('정확도: {:.4f}, 정밀도: {:.4f}, 재현율: {:.4f}, f1: {:.4f}, AUC: {:.4f}'
.format(accuracy, precision, recall, f1, roc_auc))
#return accuracy, precision, recall, f1, roc_auc다음과 같은 코드(함수)를 사용해서 이들을 구할 수 있다.
또한, 임계값을 조절해서 정밀도와 재현율을 조절할 수 있다.
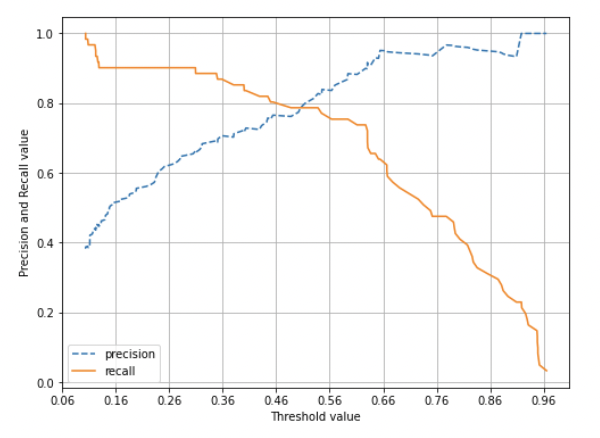
다음과 같이 정밀도와 재현율은 반비례 관계를 가지고 있다. 때문에 둘을 결합한 종합적인 성능 지표가 필요해서 F1 스코어를 사용한다.
결정 트리
결정 트리는 각 규칙 노드가 하나의 특징을 이용해서 분기를 만들어 나가면서 트리 형태를 만든다.
코드로 보면 다음과 같다.
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, stratify=y)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
tree_model = DecisionTreeClassifier(criterion='gini',
max_depth = 4, random_state=1)
tree_model.fit(X_train, y_train)
tree.plot_tree(tree_model)
plt.show()다음과 같이 작성하면 트리 구조를 볼 수 있다.
결정 경계와 과대 적합
결정 경계를 깔끔하게 만들어주기 위해서 파라미터를 조정해주어서 다음과 같이 할 수 있다.
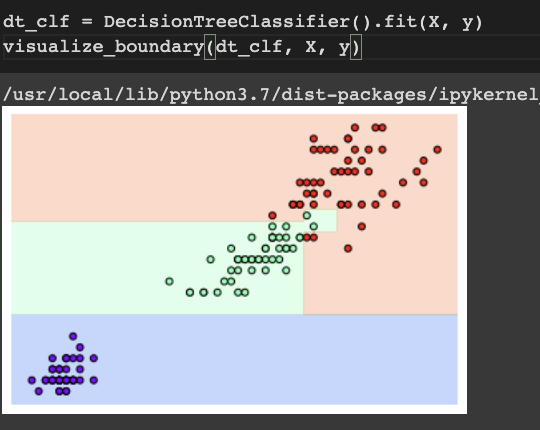

경계가 조금 깔끔해진다.
