인공지능적 사고와 문제해결
이번 학기엔 다양한 과목들을 배웠다. 그 중에서 가장 마음에 드는 과목이었다. 하지만 잘하는가 묻는다면 딱히 잘하진 않고 그냥 열심히 따라가기만 했다. 그래서 잘하고 싶은 마음은 있지만 잘하긴 어려운 과목이었다.
후배들이 이 글을 보고 공부하는데 도움이 되었으면 좋겠다는 생각으로 글을 작성하는 것있고 내가 나중에 보고 참고할 만한 글이 되었으면 좋겠다는 생각이 있다.
머신 러닝 학습 및 예측
머신 러닝은 데이터를 주면 그 데이터를 통해서 스스로 학습하여 추론을 하는 기술이다.
크게 학습 단계와 예측 단계로 구분한다고 나와있는데 그림으로 보면 다음과 같다.
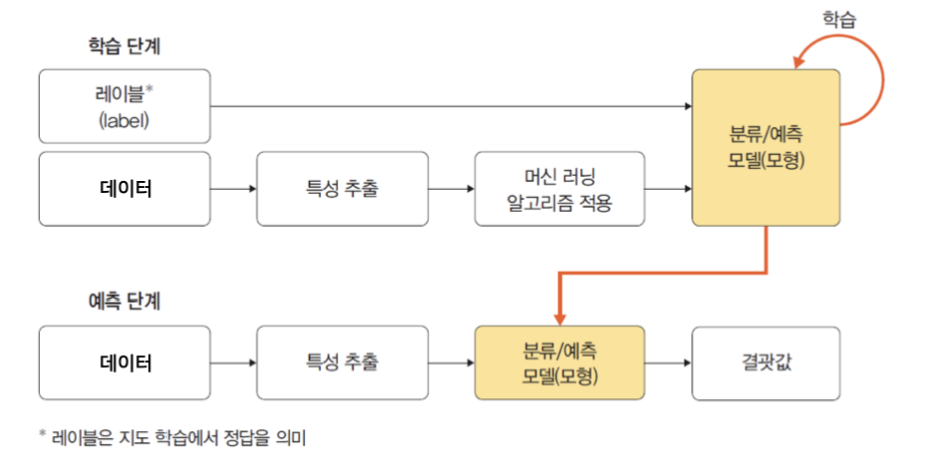
학습 단계에서 머신 러닝 알고리즘을 적용하여 학습하고 그 결과로 모델을 생성한다
예측은 이 모델을 토대로 테스트 데이터를 예측하는 것이다.
지도 학습과 비지도 학습
우리는 모델이 학습을 하게 할 때 데이터에 정답 값을 주느냐 안 주느냐에 따라서 지도 학습과 비지도 학습으로 나누게 된다.
또 레이블의 형태에 따라서 분류와 회귀로 구분하기도 한다. 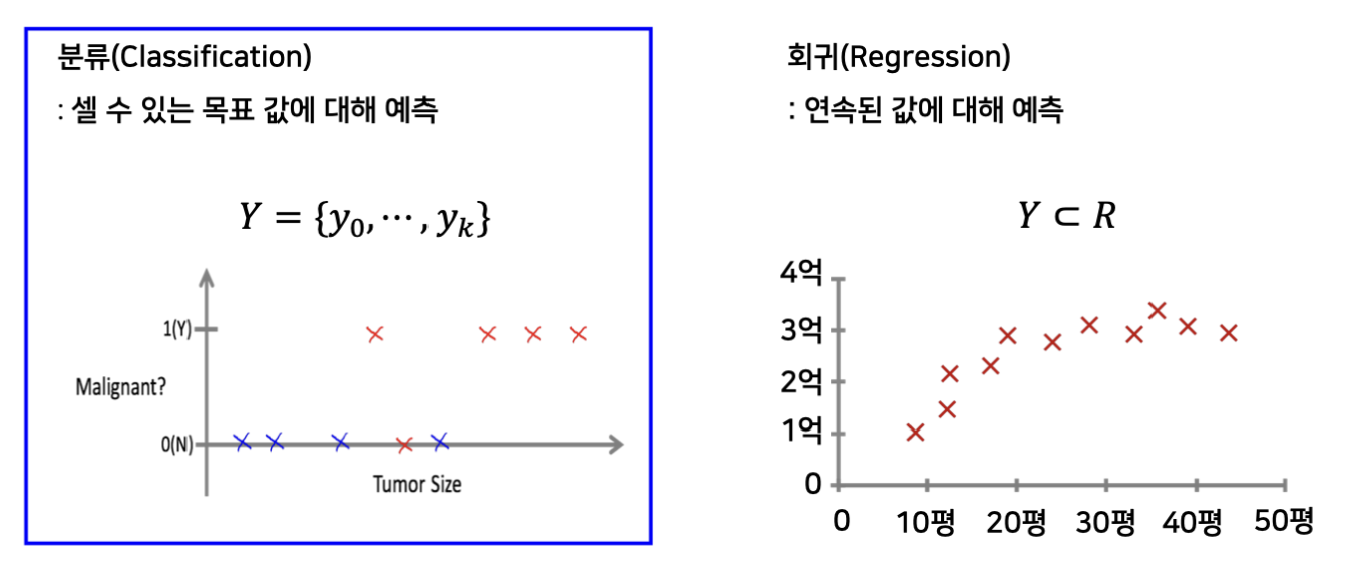
회귀 같은 것들은 집값을 예측한다거나 하는 문제이고, 분류는 맞냐 틀리냐에 대해서 혹은 셀 수 있는 목표 값에 대해서 예측하는 것이다.
지도 학습의 경우는 시험지와 답지를 주는 것이고 비지도 학습은 시험지만 주고 답지는 제공하지 않는 것이다. 어느 것이 좋은 학습법인지는 상황에 따라서 다르다.
데이터 분할 [학습/검증/테스트]
모델을 학습 시킬 때 최대한 많은 데이터를 넣는 것이 좋지만 검증을 하기 위해서 테스트 데이터를 가지고 있어야 한다. 테스트 데이터는 흔히 모의고사의 역할이라고 한다.
이러한 테스트 데이터를 가지고 있어야 내 모델의 성능을 실전에 도입하기 전에 측정할 수 있다.
전체 데이터를 랜덤하게 분할 해 학습 데이터와 테스트 데이터로 나눈다.
또한 학습 데이터 중에서 일부를 다시 분할하여 검증 데이터 세트로 나눈다. 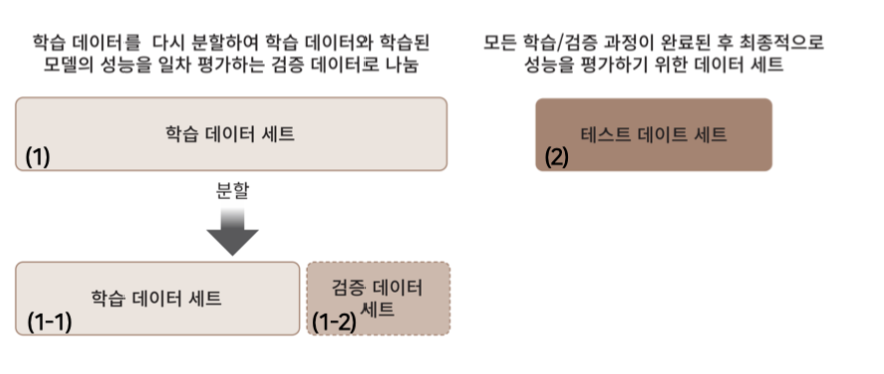
from sklearn.model_selection import train_test_split
def get_train_test_split(df):
df_copy = get_preprocessed_df(df)
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target,
test_size = 0.3, random_state=0,
stratify=y_target)이렇게 데이터를 분할 했으면 보통 k-fold 교차 검증이라는 것을 활용한다.
교차 검증 이라는 것은 학습데이터를 k개의 뭉치로 쪼개고 k-1개의 데이터로 학습 후 성능 측정을 k번 반복 하는 것이다.
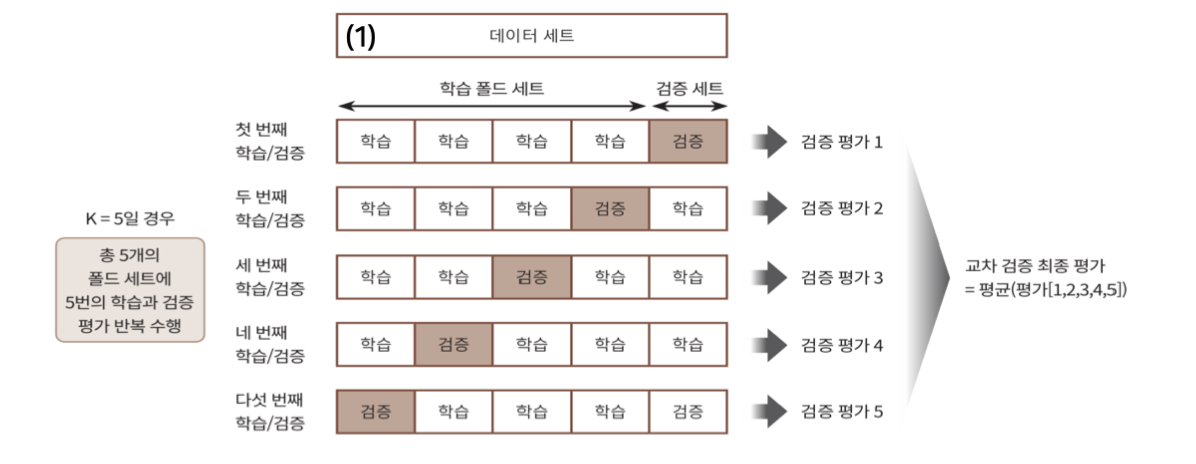
이렇게 해서 나온 평균 값을 모델의 성능이라고 생각할 수 있다. 데이터가 편향되어서 그저 우연히 잘 보았을 가능성을 줄여주는 테크닉이라고 볼 수 있다.
from sklearn.model_selection import StratifiedKFold
def exec_kfold(clf, folds=5):
skfold = StratifiedKFold(n_splits=folds)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skfold.split(X_titanic_df, y_titanic_df):
X_train, X_test = X_titanic_df.iloc[train_index], X_titanic_df.iloc[test_index]
y_train, y_test = y_titanic_df[train_index], y_titanic_df[test_index]
dt_clf = DecisionTreeClassifier(random_state = 11)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
cv_accuracy.append(accuracy)
print("\n ## 교차 검증별 정확도:", np.round(cv_accuracy, 4))
print("## 평균 검증별 정확도:", np.mean(cv_accuracy))
dt_clf = DecisionTreeClassifier(random_state=11)
exec_kfold(dt_clf)검증 데이터 셋은 하이퍼 파라미터 튜닝을 위해서 사용한다.
하이퍼 파라미터는 학습 알고리즘에 의해 업데이트 되는 파라미터이며, 학습셋에 학습된 모델을 가지고 검증 셋에 성능을 측정해 최적값을 찾는다.
GridSearchCV를 활용하여 교차검증을 진행한다.
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[2, 3, 5, 10],
'min_samples_split':[2,3,5], 'min_samples_leaf':[1,5,8]}
dtree = DecisionTreeClassifier(random_state=11)
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv=3, refit=True)
grid_dtree.fit(X_train, y_train)
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score', \
'split0_test_score', 'split1_test_score', 'split2_test_score']]데이터 전처리
데이터 전처리는 매우 중요한 과정이고 꽤나 까다로운 작업이다. 이 전처리 과정에 따라서 모델의 성능이 바뀐다고 할 수 있다.
데이터 인코딩
데이터 인코딩은 레이블 인코딩이랑 원 핫 인코딩을 살펴 볼 것이다.
레이블 인코딩의 경우는 순서형 변수 또는 범주형 변수의 분류 값을 순서가 의미를 지니는 숫자 형태로 변환하는 것이다.
LabelEncoder 클래스를 사용한다. sklearn에서 제공하니 참고하자.

숫자로 카테고리를 표현하기 때문에 ML 알고리즘이 분류 코드로 사용된 숫자의 크기를 이용하려 할 수 있다. 따라서 순서형 변수에는 적합하다.
from sklearn.preprocessing import LabelEncoder
def encoded_features(df):
cols = ['Cabin', 'Sex', 'Embarked']
le = LabelEncoder()
for i in cols:
le = le.fit(df[i])
df[i] = le.fit_transform(df[i])
return df하지만 각 범주가 독립적인 의미를 지니는 범주형 변수에는 부적합하다고 한다.
왜냐면 순서가 생기기 때문이다.
원 핫 인코딩 은 순서형 변수에도 사용할 수 있다는 장점이 있는 인코딩이다.
from sklearn.preprocessing import OneHotEncoder
drop_enc = OneHotEncoder(drop='first').fit(X)
drop_enc.transform([['Female', 1], ['Male', 2]]).toarray()전체 카테고리 개수 크기의 벡터를 만들고, 각 카테고리에 해당하는 값을 1로, 나머지를 0으로 표기한다. 즉, 하나의 특징으로부터 카테고리 개수 만큼의 특징을 만든다고 이해할 수 있다.
그림으로 보면 이해가 빠르다.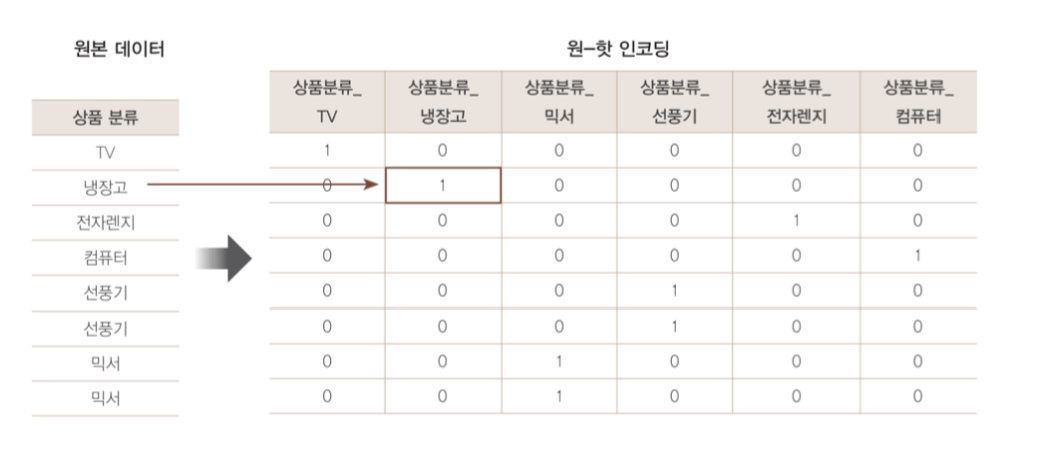
피쳐 스케일링
데이터가 한 피쳐만 너무 크면 그 데이터만 중요하다고 생각할 수도 있다. (성능 좋은 모델들은 그것 마저도 알아서 처리하는 것 같다.)
때문에 스케일링 작업을 해주는데 대표적으로 표준화와 정규화가 있다.
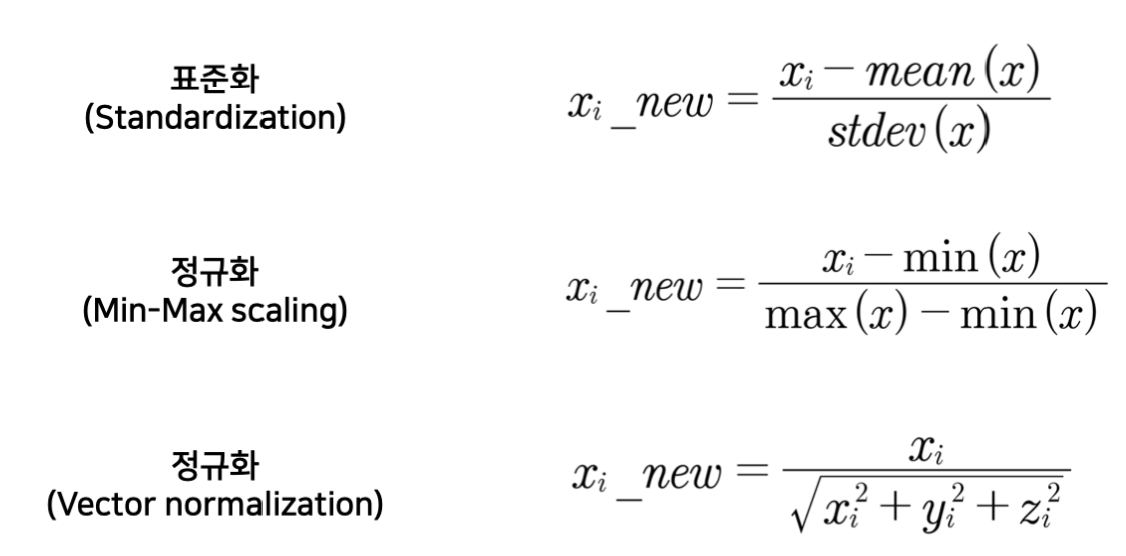
스케일링은 평균, 표준편차등의 파라미터를 추정하는 fit()이 있고, 실제 값을 변환하는 transform()으로 나뉜다.
학습데이터에 fit하여 파라미터를 찾고, 검증/테스트 데이터에 대해서는 tranform()으로 값 변환만 하며 파라미터 추정에 사용하지 않는다.
사실 좀 귀찮아서 개발자 들이 이를 줄여 놓은 것이 fit_transform()이다.
from sklearn.preprocessing import StandardScaler
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
scaler = StandardScaler()
print(scaler.fit(data))
print(scaler.mean_)
print(scaler.transform(data))
print(scaler.transform([[2, 2]]))이진 분류
분류 문제에서 쓰인다.
이건 프로젝트를 하면서 가장 도움을 많이 받은 개념이다. 모델을 학습하면 모델이 예측한 값에 대한 확률이 나오는데 pred_proba와 같은 형식이다. 기본적으로 저 확률에 0.5 기준으로 맞냐 틀리냐를 결정하는데 0.5가 최적의 확률이 아닐 수 있다. 때문에 이진 분류를 사용하여 그 기준을 변경시키면 성능을 올릴 수 있다.
>>> from sklearn.preprocessing import Binarizer
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> transformer = Binarizer().fit(X) # fit does nothing.
>>> transformer
Binarizer()
>>> transformer.transform(X)
array([[1., 0., 1.],
[1., 0., 0.],
[0., 1., 0.]])성능 측정
성능을 측정할 때 정확도를 생각하는 사람들이 많다. 정확도도 상황에 따라서 굉장히 중요한 수치이지만 종합적으로 봤을 때는 크게 의미가 없을 수도 있다.
이진 분류기가 예측을 그냥 다 아니라고 했을 때, 아닌 것이 많으면 정확도가 올라간다.
정확도를 예측 결과가 맞는 데이터 건수 / 전체 데이터 건수 이다.
때문에 100개 중에 맞는게 1개이고 99개가 아니 값일 때 다 아니라고 하면 정확도를 99이다.
여기서 오차행렬을 보여주면 다음과 같다.
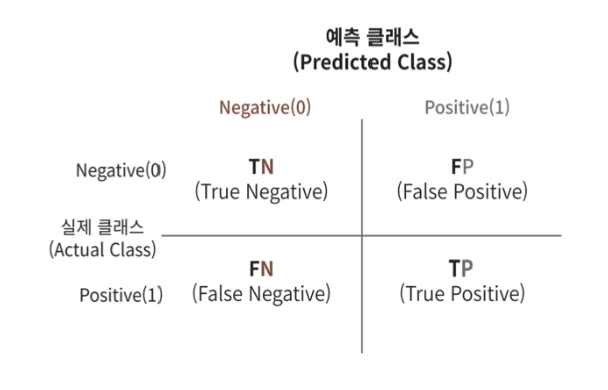
위의 예시에서 FP와 TP는 0이다. 또한 FN은 99이고, TN은 1이다.
정밀도는 TP / (FP + TP)이고, 재현율은 TP / (FN + TP)이다.
때문에 정밀도와 재현율은 0이다.
정밀도는 1로 예측했을 떄 얼마나 잘 맞췄냐 인데, 1로 예측을 안 했는데 맞는게 있을리 없다.
재현율은 정답이 1인 데이터를 얼마나 잘 찾았냐인데, 하나도 못 찾았으니 없다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, f1_score, roc_auc_score
# 평가지표 출력하는 함수 설정
def get_clf_eval(y_test, y_pred, y_pred_proba):
confusion = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred_proba)
print('오차행렬')
print(confusion)
print('정확도: {:.4f}, 정밀도: {:.4f}, 재현율: {:.4f}, f1: {:.4f}, AUC: {:.4f}'
.format(accuracy, precision, recall, f1, roc_auc))정밀도와 재현율 조정하기
아까 말했듯이 이진 분류 모델은 positive 클래스에 속할 확률로 계산한다고 했다.
정밀도가 높아지면 재현율이 떨어지고 재현율이 높아지면 정밀도가 떨어진다.
이러한 관계를 정밀도-재현율 트레이드 오프라고 한다.
임계값에 따라 달라지는 이러한 값들을 곡선으로 나타 낸 것을 ROC 곡선이라고 한다. AUC는 ROC 커브로 만들어지는 면적 값이라고 한다. 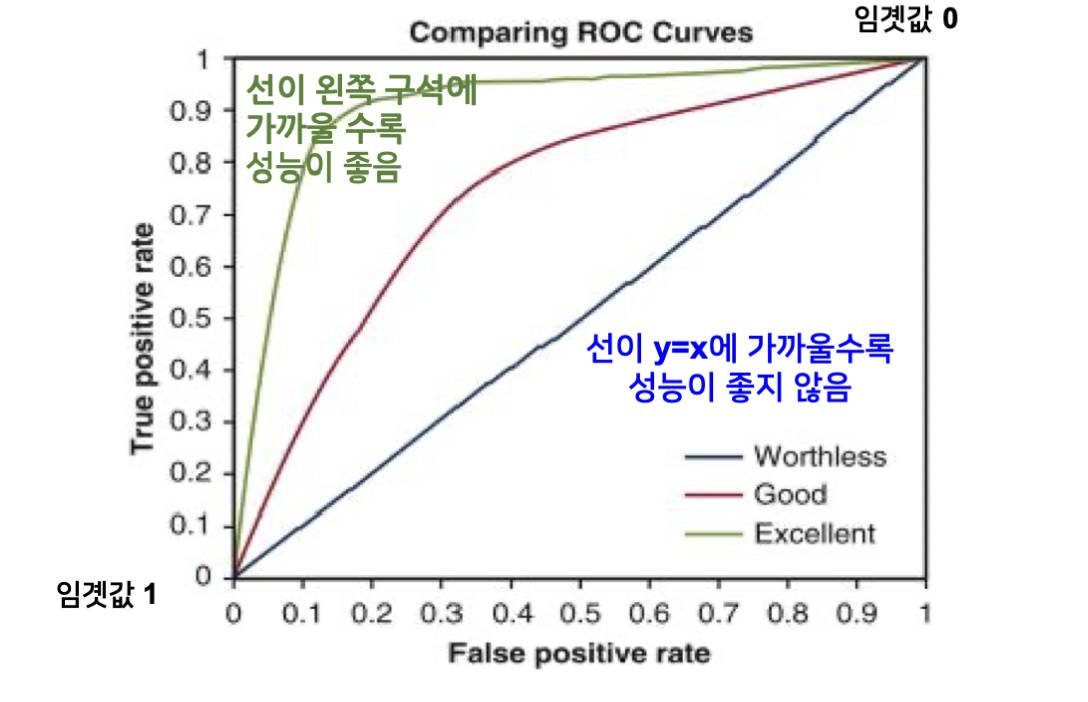
코드를 입력하세요또한 이러한 것들과 함께 균형 잡힌 성능을 측정하는 방법으로 f1 score가 있다.
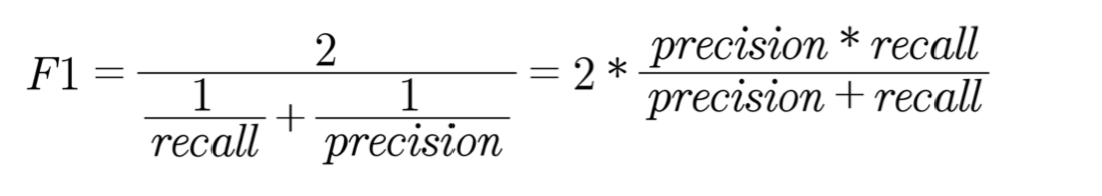
결정 트리
결정 트리는 가장 기본적은 분류 모델이지만 상당히 강력한 모델이다. if/else 기반의 연속된 규칙을 학습을 통해서 찾아낸다. 트리 형태로 표현해서 결정 트리이다.
일상생활에 적용하면 다음과 같은 형식으로 나올 것이다.
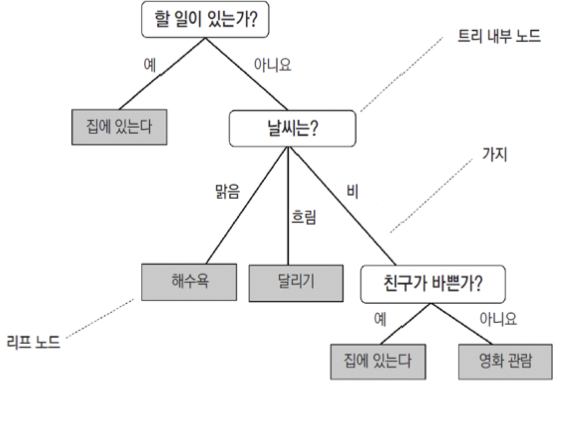
가장 좋은 분할을 만드는 특징을 선택해 데이터를 분할하는 규칙 노드를 만드는 과정을 반복한다.
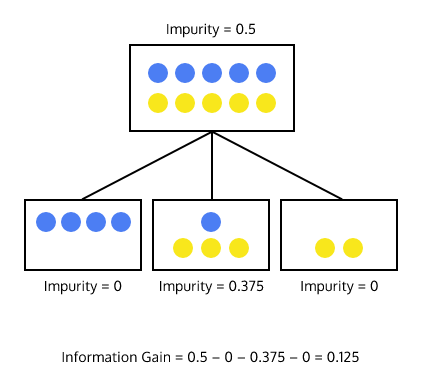
코드를 입력하세요학습 알고리즘에서 최적의 분할은 정보 이득이라는 개념을 사용한다. 공식으로 보면 다음과 같다. 
좀 더 편한 그림으로 보면 다음과 같고, 불순도가 작아야 즉, 한쪽으로 잘 몰려야 한다.
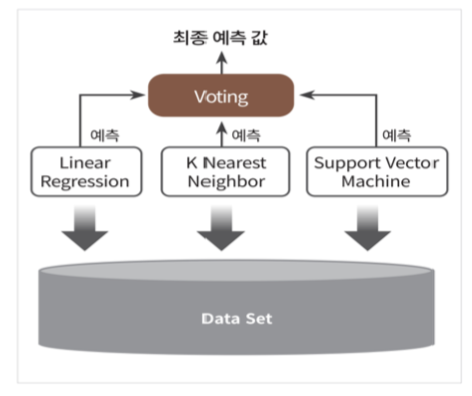
앙상블 학습
사람과 마찬가지로 집단 지성을 이용한 방법이다. 똑똑한 모델들에게 투표를 시켜서 최종적으로 예측을 하게 만드는 것이다. 사실 사용해보니 그렇게 드라마틱한 결과가 나오지는 않는다.
과반 투표 분류기
서로 다른 모델로 주어진 샘플의 예측 레이블 값을 얻어서 다수결의 방식으로 결과를 낸다.

주어진 샘플 x 에대해, 개별 분류기들의 예측 레이블을 모아, 가장 많은 표를 받은 레이블을 선택하는 방식이다.
하드 보팅 : 개별 분류기 예측 레이블 값들의 최빈값이다.
소프트 보팅 : 개별 분류기 예측 확률 값들의 평균값이다.
개인적으로 소프트 보팅이 성능이 좋은 것 같다.
vo_soft_clf_xl = VotingClassifier(estimators= [('xgb', model_xgb),
('lgb', model_lgb)
],
voting="soft")여기서 각 개별 분류기의 중요도로 가중치를 매길 수도 있다. 똑똑한 애를 좀 더 믿는 것이다.
배깅
같은 알고리즘으로 서로 다른 학습 데이터를 이용해 여러 개의 분류기를 만들고, 보팅 방법으로 예측 결과를 합치는 앙상블 방법이다.
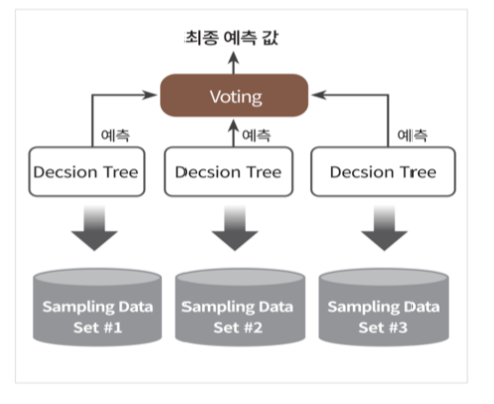
과반수 분류기는 같은 데이터를 다른 알고리즘에 사용해 결과를 합치는 것이고, 배깅은 데이터를 나누어서 다른 데이터로 학습한 다음에 예측 결과를 합치는 방법이다.
코드를 입력하세요결국 대상은 같지만, 서로 다른 관점을 갖도록 각 모델을 학습하여 결과를 합치는 것이다.
부스팅
부스팅은 약한 분류기라고 부르는 매우 간단한 분류기를 학습하고 앙상블로 결합한 것이다.
배깅 앙상블은 복잡한 모델을 개별 모델로 사용하고, 부스팅 앙상블은 간단한 모델을 개별 모델로 사용한다는 차이가 있다.
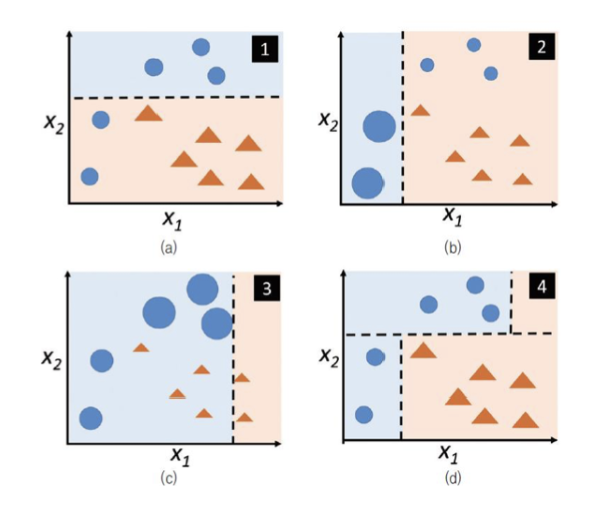
에이다 부스트 알고리즘은 주어진 학습 데이터에 깊이가 1인 결정 트리를 학습한다. 직선 형태의 결정 경계를 가지는 약한 학습기이다. 샘플 가중치 기반 분류기 학습을 한다.
잘못 분류된 샘플에 가중치 부여, 옳게 분류된 샘플의 가중치는 낮춘다. 각 단계에 학습된 분류기를 과반수 투표 방식으로 결합한다.
각 단계에 학습된 분류기를 과반수 투표 방식으로 결합, 세 개의 직선을 연결한 형태의 결정 경계를 갖는 분류기이다.
import xgboost as xgb
def get_model_train_eval(model, ftr_train=None, ftr_test=None,
tgt_train=None, tgt_test = None):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:, 1]
get_clf_eval(tgt_test, pred, pred_proba)
model_xgb = xgb.XGBClassifier() 주의 사항
학습 속도 : 연산량 많고 병렬처리가 안돼서 학습 시간이 오래 걸린다.
높은 분산 : 부스팅 기법은 편향은 낮지만 분산이 높아서 과대적합 되는 경향이 있다. 하지만 잘 조절하면 성능이 좋다.
데이터 셋에 따라 모델마다 성능이 다르다.
비용 함수
비용 함수는 결정 경계가 얼마나 두 클래스를 잘 나누는 지를 측정한다.
비용함수는 정답과 예측 값 사이의 차이 즉 오차를 계산해서 측정한다.
클래스가 불균형하다면?
(+) 가 6개고 (-) 2개이면 2개 짜리가 오차를 기여하는건 6개 짜리보다 적기 때문에 효과적인 학습을 이루지 못할 수도 있다.
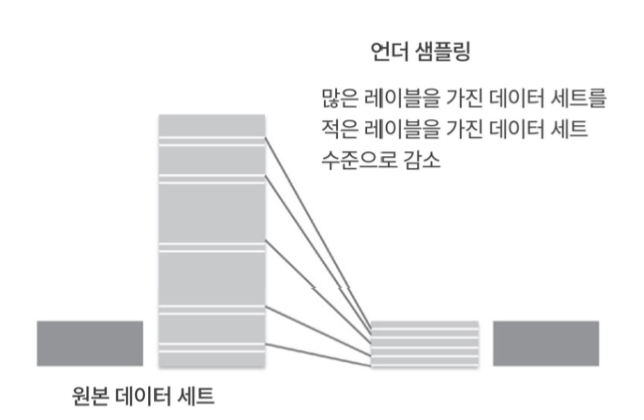
언더 샘플링
다수 라벨의 일부만을 활용해 데이터 수의 균형을 맞추는 방식이다.
데이터가 지나치게 줄어들 수 있다는 문제가 있다. 또한 선택 과정에서 본래 데이터를 대표하지 못할 수도 있다.
오버 샘플링
소수의 클래스의 데이터를 반복사용해서, 다수 클래스 데이터와 수를 맞추는 방법이다. 당연하게도 소수 클래스 데이터에만 민감해지고 과적합 되는 문제가 생길 수 있다.
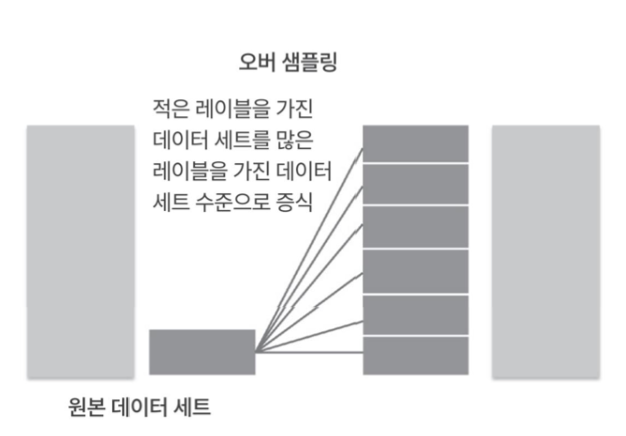
오버 샘플링으로 균형을 맞춘 모습이다.
스태킹 앙상블
스택킹은 앙상블 기법의 하나로 개별 모데링 예측한 겨로가를 입력으로 받는 모델을 두어 최종 예측을 하는 것이다.
개별 모델은 base learner 라고 불리며, 개별 모델의 예측 결과를 병합하는 알고리즘은 meta learner라고 불린다.
meta learner 도 학습이 이루어진다는 점에서 투표방법과 구분된다. 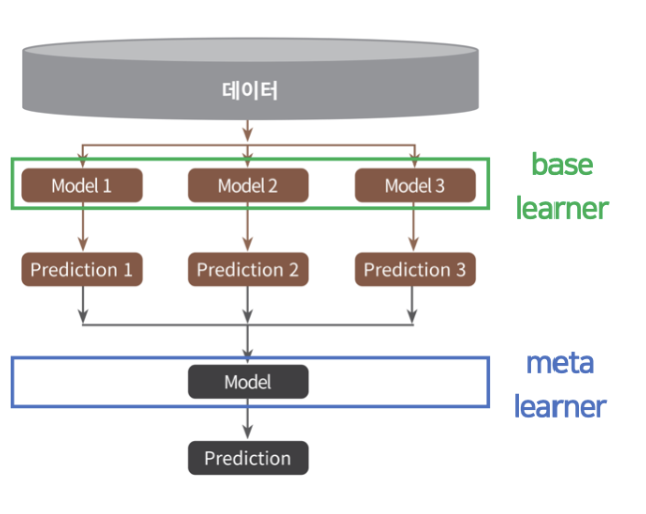
코드를 입력하세요