
참여 후기
국제적인 기업답게 참여자가 어마어마하게 많았다. 하지만 국내 컨퍼런스처럼 솔루션 소개가 주를 이뤄서 적용 사례나 새로운 기능/솔루션/상품을 빼면 트랙에 남는게 거의 없었다. 부스에 생각보다 많은 기업들이 있었는데 상품도 굉장히 많았다. 나는 타이밍을 잘못 잡았던건지 간단한 상품들만 받아서 조금 슬펐다...
AWS에 관심이 있는 사람이 아니면 굳이 참여하지 않아도 될것 같았다.
노트
기조 연설
우아한 형제들
핀테크 업계 최초로 결제도 클라우드로 진행 (KEYCLOAK)
AI 고도화 진행
- 메뉴 분류, 메뉴 추천, 리뷰 필터링, 배차 효율화
FinOps
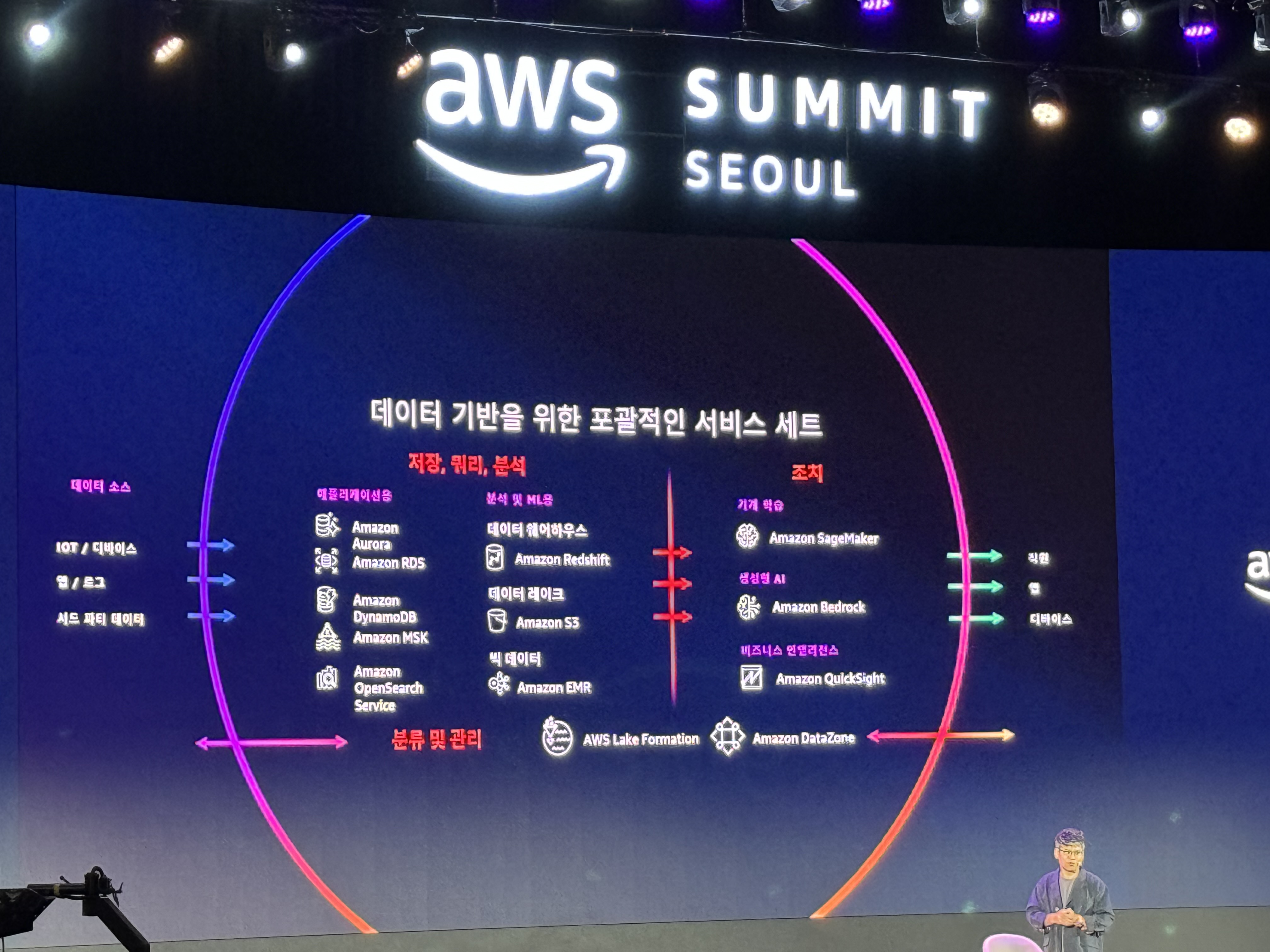
AWS
생성형 AI 스택
- 파운데이션 모델 및 거대 언어 모델 활용 도구
- Amazon Q, Amazon Q in Amazon QuickSight, Amazon Q in Amazon Connect
- 파운데이션 모델 및 거대 언어 모델 기반 개발 도구
- Amazon Bedrock (AGENTS 등 다양한 맞춤형 기능 제공)
- 파운데이션 모델 훈련 및 추론 인프라
- GPUs, Trainium, Inferentia, SageMaker
- UltraClusters, EFA, EC2 Capacity Blocks, Nitro, Neuron
Amazon Bedrock: 데이터를 내부에서 안전하게 사용 가능
- 고객의 데이터를 파운데이션 모델을 훈련하는데 사용하지 않음
- 모든 데이터를 전송 중 및 저장 중 암호화. 데이터는 고객 VPC를 통해 안전하게 전송
- GDPR, SOC, ISO, CSA, HIPAA 자격 등 국제 공인 규정 준수
참여한 강연
AWS와 생성형 AI로 비즈니스 혁신하기
후기
AI가 생각보다 많은 일자리를 대체할 수 있다는 것이 놀랐고, AI가 사내의 정보를 학습하여 다른 사용자가 이를 확인할 수 있는 문제가 있다는 뉴스를 많이 접헀었는데 이를 해결할 수 있도록 여러 플랫폼이 준비되어 있다는 점이 흥미로웠다. AI가 습득하면 안되는 정보를 습득해서 이를 해결하였는데 AI를 활용한 눈에 띄는 서비스도 아직까지는 많이 나오진 않았지만 앞으로 우리의 에상을 벗어나는 서비스들이 나올 것 같아 기대가 되었다.
내용
파운데이션 모델을 기반으로 하는 생성형 AI
- 방대한 양의 비정형 데이터로 사전 훈련
- 복잡한 개념을 학습할 수 있도록 많은 파라미터 포함
- 다양한 컨텍스트에 적용 가능
- 도메인별 작업을 위해 데이터를 사용하여 FM을 최적화
AI 적용을 통해 얻을 수 있는 것
- 고객 경험 향상
- Chatbots, 가상 어시스턴트, 대화 분석, 개인화
- 직원 생산성 및 창의성 강화
- 대화형 검색, 요약, 콘텐츠 작성, 코드 생성, 데이터를 인사이트로 전환
- 비즈니스 프로세스 최적화
- 문서 처리, 데이터 증강, 사이버 보안, 프로세스 최적화
AI를 적용할 수 있는 산업 예시
- 의료 서비스 및 생명 과학
- 엠비언트 디지털 스크라이브, 의료 영상, 신약 개발, 임상 시험 강화, 연구 보고
- 제조 산업
- 제품 설계, 운영 효율성, 유지 관리 어시스턴트, 공급망 최적화, 장비 진단
- 금융 서비스
- 포트폴리오 관리, 금융 문서, 지능형 자문, 사기 탐지, 규정 준수 어시스턴트
- 유통
- 가격 최적화, 가상 시착 리뷰, 마케팅 최적화, 제품 설명, 맞춤형 추천
- 미디어 및 엔터테인먼트
- 대규모 HQ 콘텐츠, 방송 콘텐츠 강화, 콘텐츠 태깅 자동화, 구독자 경험 최적화, 하이라이트 생성 자동화
2/3의 일자리가 생성형 AI에 위협받음
생성형 AI 스택
-
LLM 및 기타 FM을 황용하는 애플리케이션
Amazon Q: 비즈니스에 맞춤화된 작업을 위한 생성형 AI 기반 어시스턴트
Amazon Q in QuickSight: 생성형 대시보드 작성, 시각적으로 매력적인 데이터 스토리지, 새로워진 Q&A 경험 -
LLM 및 기타 FM을 사용하여 구축할 수 있는 도구
내 데이터를 비공개로 생성형 AI에 사용하는 것이 중요 -> Amazon Bedrock
ANTHROI\C
고유한 요구 사항에 최적화
- 파인튜닝, 검색 증강 생성 (RAG), 지속적인 사전 학습
FM(Foundation Model)을 사용하여 작업 수행
Amazon Bedrock 가드레일: 책임 있는 AI 정책으로 생성형 AI 애플리케이션 보호
- FM 훈련 및 추론을 위한 인프라
- GPU, Trainium, Inferentia, SageMaker
벡터와 데이터를 함께 저장
- 요구 사항을 충족하는 친숙한 도구 사용
- 추가 라이선싱 및 관리 불필요
- 최종 사용자에게 더 빠른 경험 제공
- 데이터 동기화 및 이동 필요성 감소
넥슨의 LLM 에이전트 길들이기: 인프라 모니터링 서비스 적용 사례
후기
처음에 나온 장표의 내용처럼 챗봇을 개선하는 과정에 대해서 재미있게 설명을 진행한 강연이었다. 처음 개선된 결과를 보았을 땐 실제 서비스에서 써먹기 힘들 정도인데? 라고 생각하였는데 마지막 개선 결과를 보았을 땐 서비스하는데 크게 지장은 없을 것 같다고 느겼다. 챗봇을 개발하면서 고민하였던 과정들이 강연에 잘 녹아있어서 상당히 만족스러웠다.
개발 과정에서 얻은 지식을 공유하는 것이 발표 목적
개선 사항: 백오피스 복잡성 증가
- 내부용 백오피스 서비스 다수 운영
- 서비스 별 담당자 정보와 메뉴얼 최신화 문제
- 이슈 발생 시 개별로 확인 -> 많은 시간 소요
개선 검토: LLM 활용과 AWS 지원 - AI 활용을 통한 업무 개선 사례 R&D
- LLM의 추론 능력에 주목
- 내부 LLM 챗봇 개발 경험의 한계
하고 싶은 것: LLM으로 다양한 서비스의 연관 답변 만들기 - 이상적 목표: Jarvis처럼 스스로 상황을 파악하고 최적의 답변을 내놓는 수준
- 현실적 목표: 복수의 서비스를 서로 연동하여 의미 있는 답변을 만들어 내는 것 (프로토타입)
- 구현 범위
- 서버의 Metric 데이터 중심: 차후의 확장성 고려, Metric 데이터는 서비스가 달라도 포맷 동일
- 서비스맵 활용: 서비스간 정보를 연동할 기준 데이터로 활용
- LLM 챗봇 형태: 사용자 접근성을 높이기 위한 자연어 처리
빠르고 정확한 챗봇 만들기
Enablement가 키 컨셉
1. 챗봇 준비사항
- 데이터간 연결고리를 자동으로 확보
- 연결고리 자동 식별 (AI): 엔지니어 - 서비스 - 호스트 - 메트릭
- 적합 기술 범위 설정
- Amazon Bedrock: 다양한 AI 모델을 손쉽게 사용 가능- LangChain: AI 어플리케이션 개발 편의성 증대
- 변경된 정보는 즉시 반영
- 응답형태가 자유로움

- reAct 프롬프팅
-
기본 동작 방식
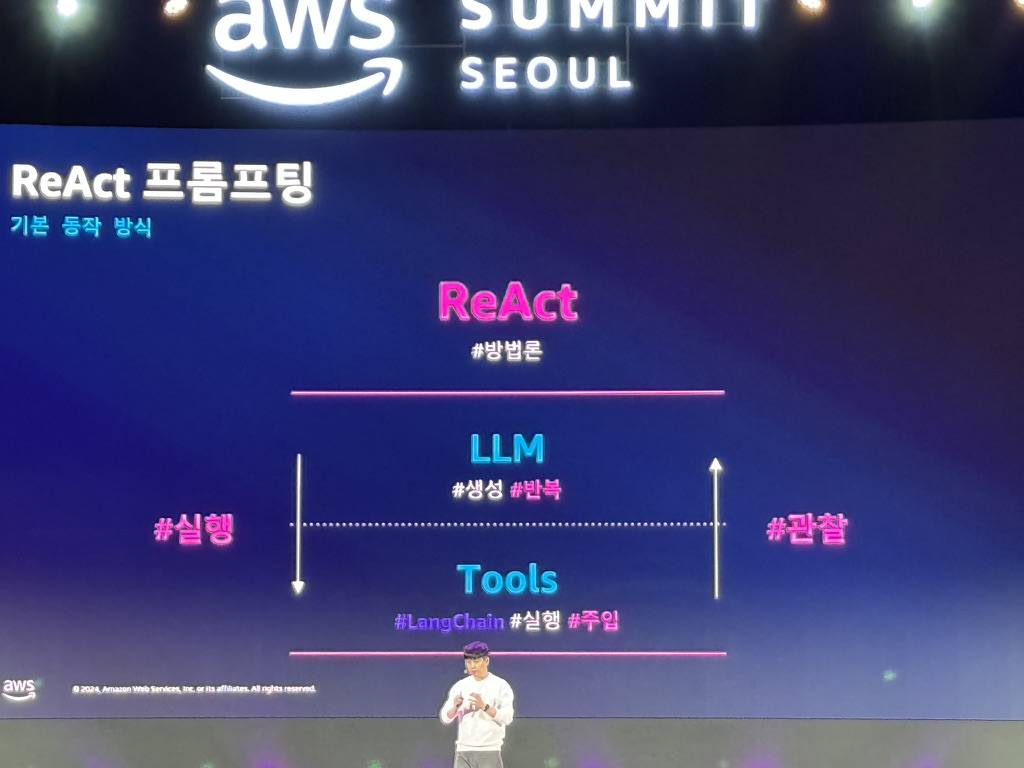
-
사용 예제

- 이슈 및 해결
-
반복 빈도 최소화: 응답 속도와 환각 위험 축소
-
모델 분리 검토: Claude 2.1 (10~15s), Claude Instant (3~5s)
-
MVP (Minimum Viable Product)
- 역할별 임무부여 (Multi-Agent)
- Multi-Agent 아키텍처

- Multi-Agent 팁

- 계획적 업무수행 (Plan and Execute)
- Plan and Execute 아키텍처

- Plan and Execute 주의사항 및 팁

- 작업 단위로 분할 (Task Tools)
- Task 업무 세분화

- 분할 작업도 LLM을 활용
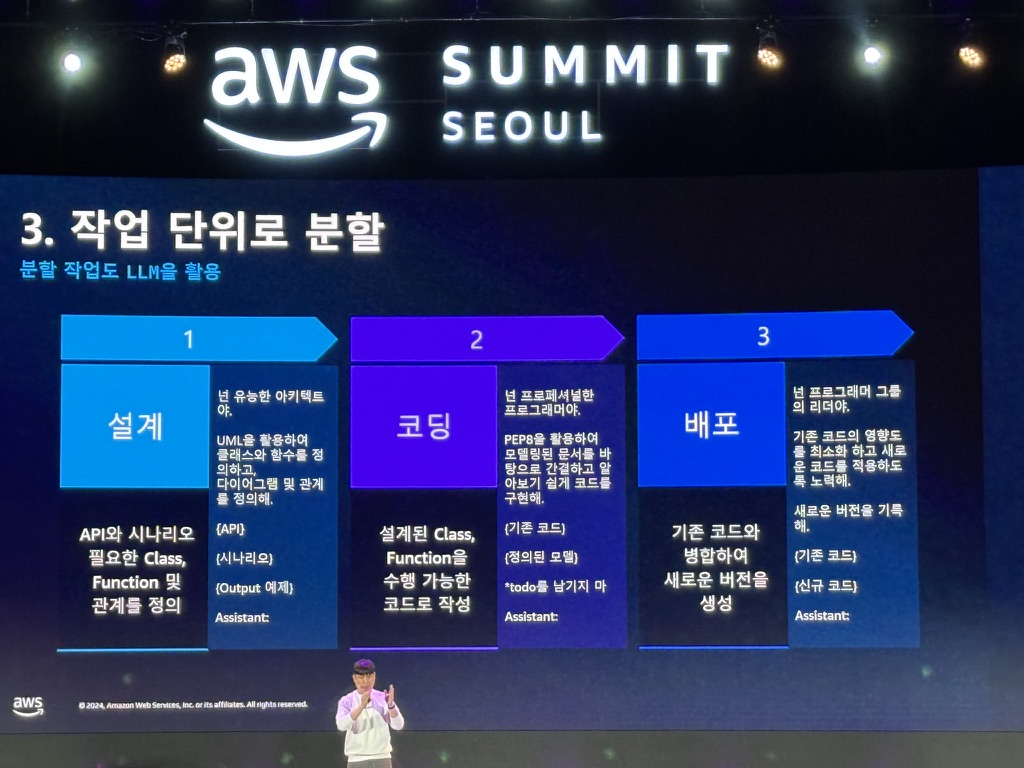
Langchain runmanager
4. 요약 및 결론
GS리테일 Amazon EKS의 모든 것: 무중단 운영부터 배포 자동화까지
후기
강연 제목 그대로 EKS에 대해서 많은 것을 배울 수 있었다. 타 강의는 AWS 홍보만 하거나 AWS 홍보를 끼워서 강연하였다면 이 강연은 거의 학습용 강연처럼 느껴졌다. 덕분에 EKS에 대해서 많은 것을 알 수 있었고 아키텍처나 적용 전후 장단점 등을 알 수 있어서 가장 유익한 강연이라고 생각한다.
EKS 운영에 어려움 점이 무엇일까요?
GitOps란?
- 원하는 상태를 선언적으로 표현
- 원하는 상태를 불편/버전 관리 방식으로 저장
- 에이전트가 원하는 상태를 자동배포
- 에이전트는 원하는 상태를 지속적 관찰/동기화
- 클러스터 관리: 클러스터 전반에 보안 표준 및 모범 사레를 적용하여 배포 자동화
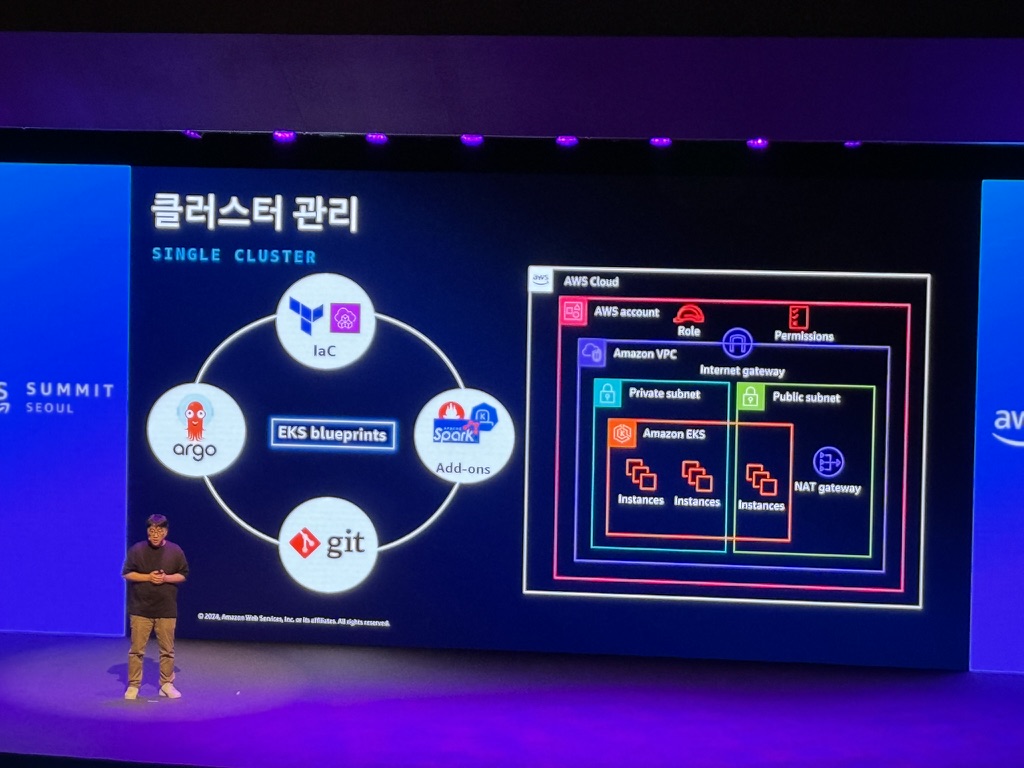
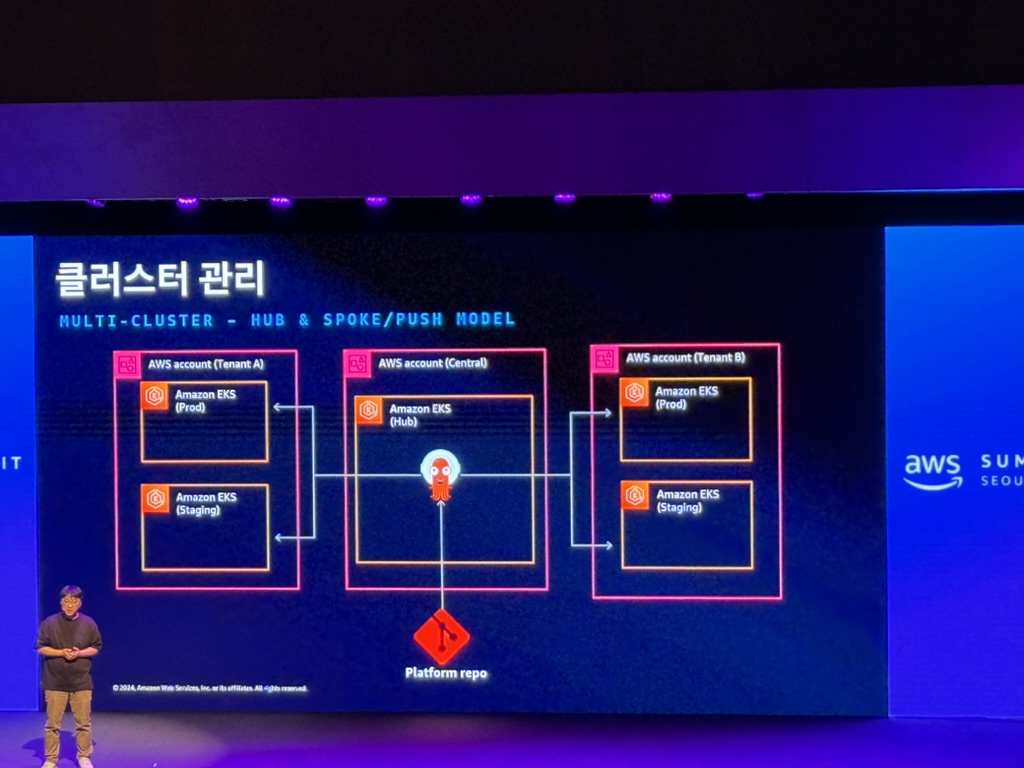
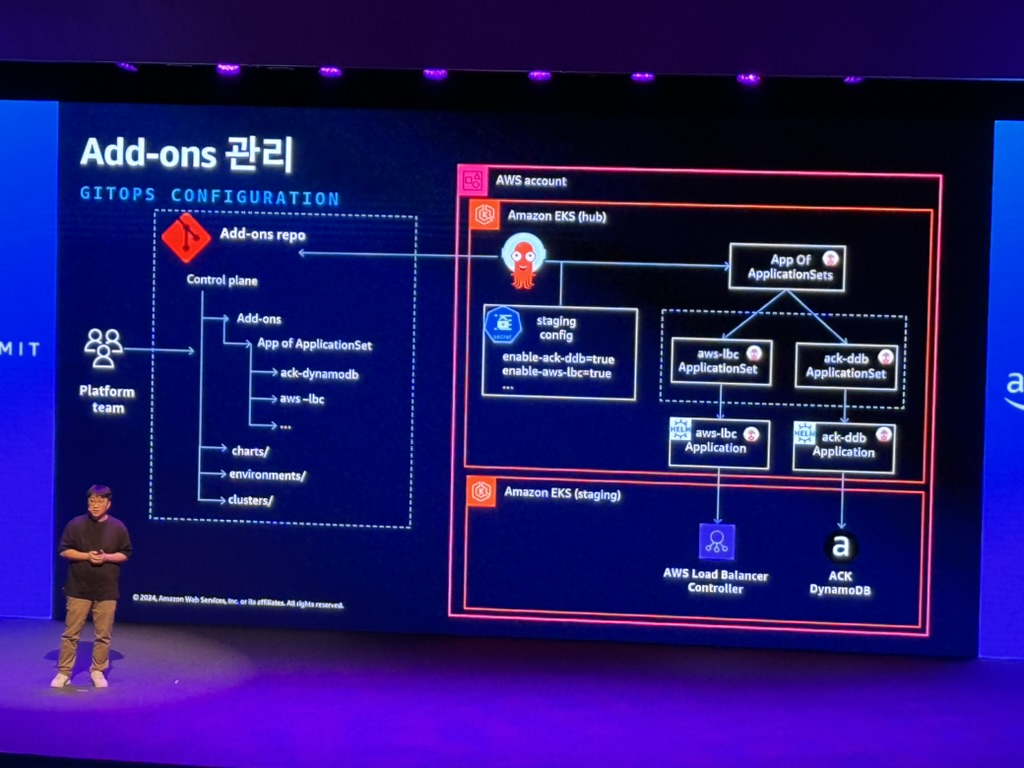
- Add-on 관리: Add-on 및 해당 dependencies 설치
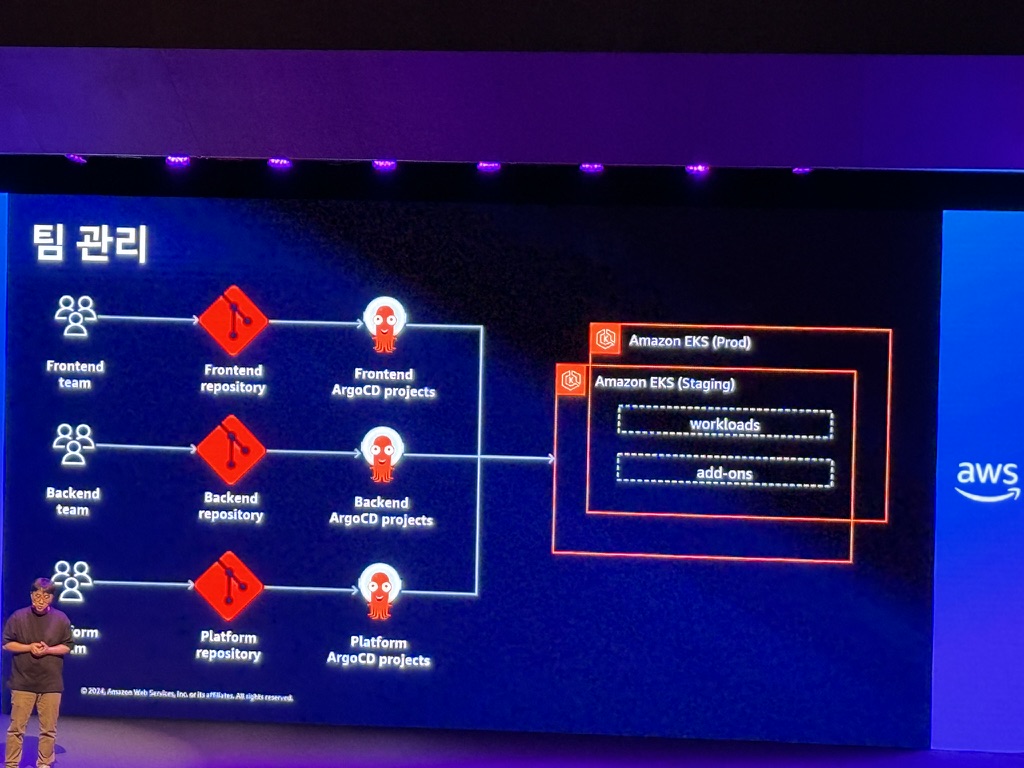
- 팀 관리: 여러 팀 간 R&R 경계 정의
- Configuration 관리: 수십 ~ 수천개의 설정파일. 단일 저장소 구성 및 수행 주기 자동화
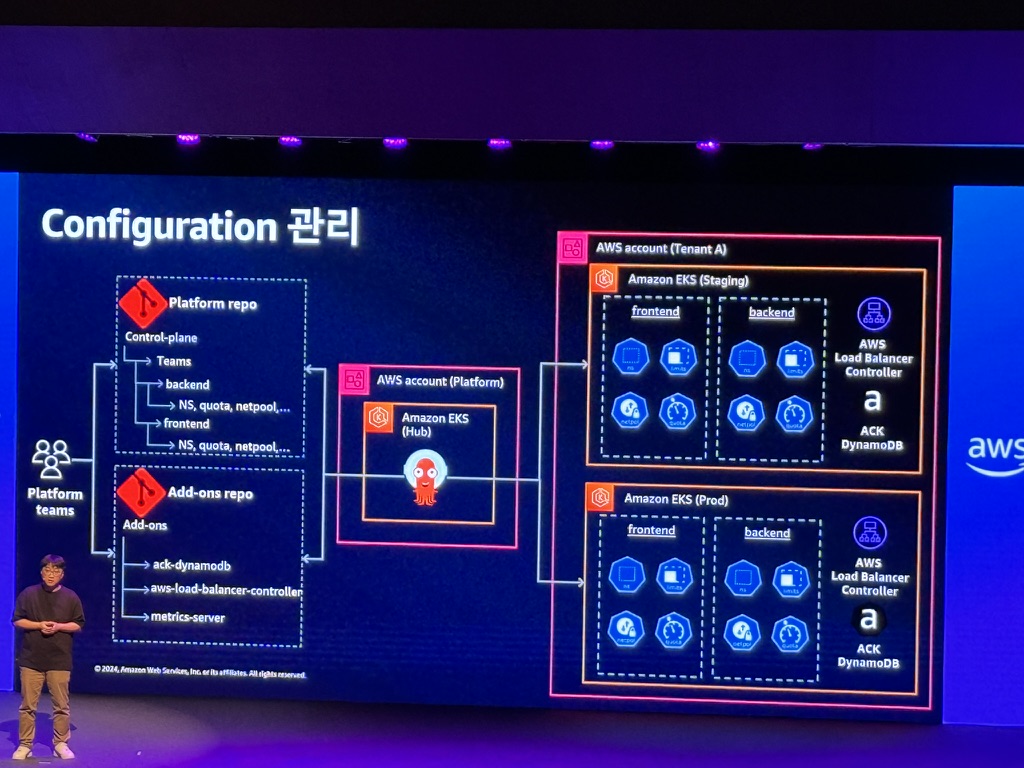
EKS 클러스터 구성 전략
- 대규모 공유 클러스터 전략: 워크로드를 Namespace 별로 구분
- 장점: 관리가 쉬움
- 단점: 단일 실패 지점
- 서비스별 클러스터 전략: 워크로드를 클러스터 별로 구분
- 장점: 장애 영향도 감소
- 단점: 관리가 복잡함
안프라 Challenge
1. 멀티 클러스터 관리의 어려움
2. CI/CD 파이프라인 관리의 어려움
3. 쿠버네티스 진입장벽
4. 대규모 메니패스트 관리의 어려움
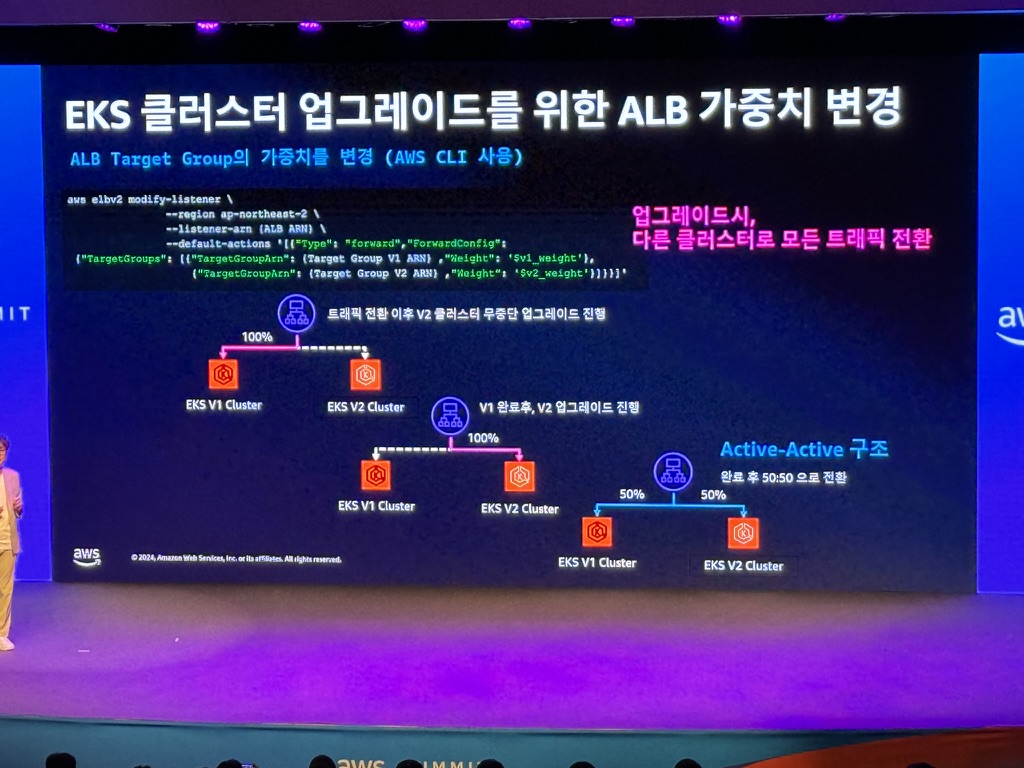
일반적으로 EKS 업그레이드를 하려면?
1. 클러스터와 Worker Node를 (순차/강제) 업데이트
- 서비스 중단 발생
- 이슈 발생시 롤백 불가능
- Blue-Green 방식으로 업그레이드
- Blue-Green 방식의 경우, 안정적 업데이트 가능
- ALB가 변경됨에 따라(Ingress 재배포) WAF, CloudFront origin 재 등록 작업 필요
로드밸런서를 사용자가 관리하는 방식으로 변경
- k8s 제어 없이 클러스터 외부에서 로드밸런서 생성 및 유지 관리
- ALB, Target Group, DNS 설정은 Terraform에 의해 관리
- TargetGroupBinding을 이용. POD - Traget Group 직접 바인딩
- Ingress의 라우팅 기능. ALB에서만 처리
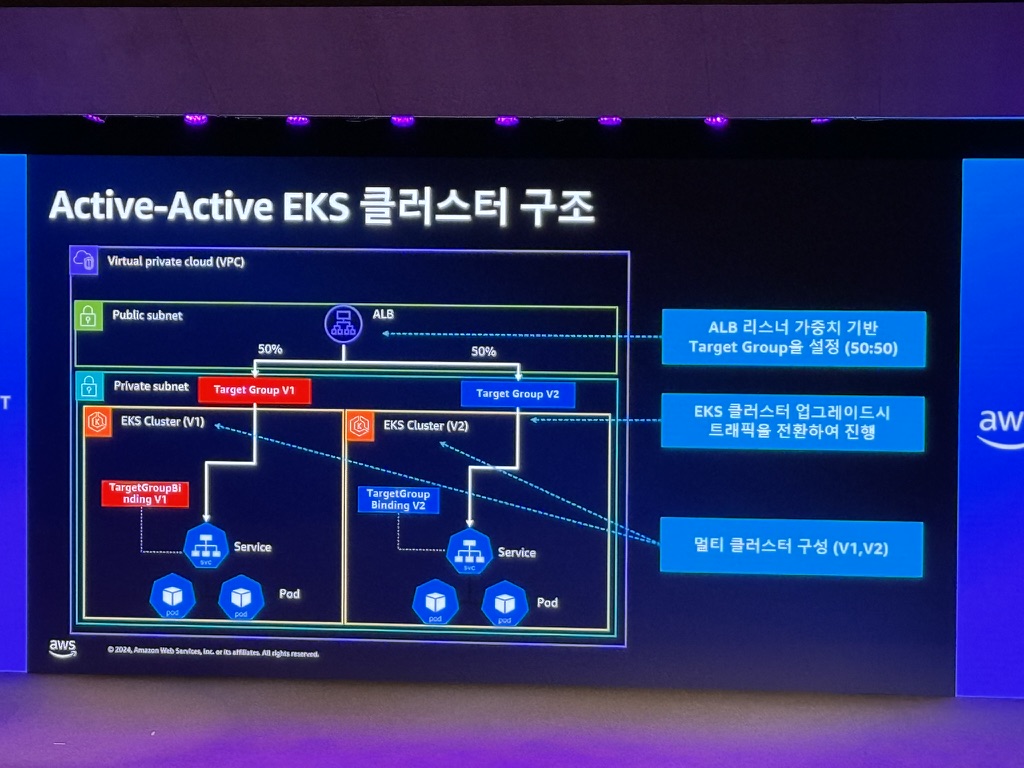
쿠버네티스 무중단 Active-Active 클러스터 운영

Active-Active EKS 클러스터 구조
EKS 클러스터 업그레이드를 위한 ALB 가중치 변경
EKS 아키텍처
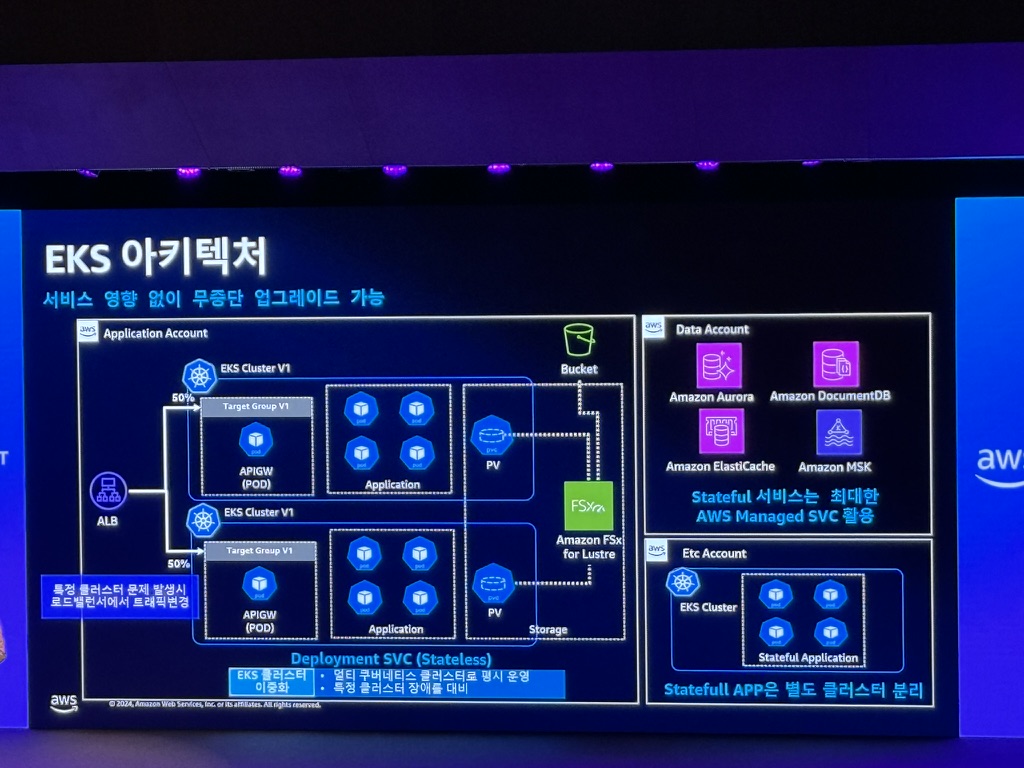
Active-Active 클러스터 구조 장점
- 업그레이드, 기술 테스트가 용이함
- EKS 업그레이드, Add-on 신규 추가에 따른 중단 시간: 0 Hour
- 쿠버네티스 버전, Add-On, SW를 최신 버전으로 유지하여 장기적인 관점에서의 유지 관리 비용을 낮춤: 기술적 부채 감소
- 쿠버네티스는 지속적으로 신규 기능 출시, 기존 기능 개선으로 더 나은 관리, 보다 효율적인 자원 사용, 더 나은 스케쥴링을 위해서 유연한 업그레이드 구조가 필요함
커스텀 배포 API를 통한 배포 자동화 구현
과거의 CI/CD 파이프라인
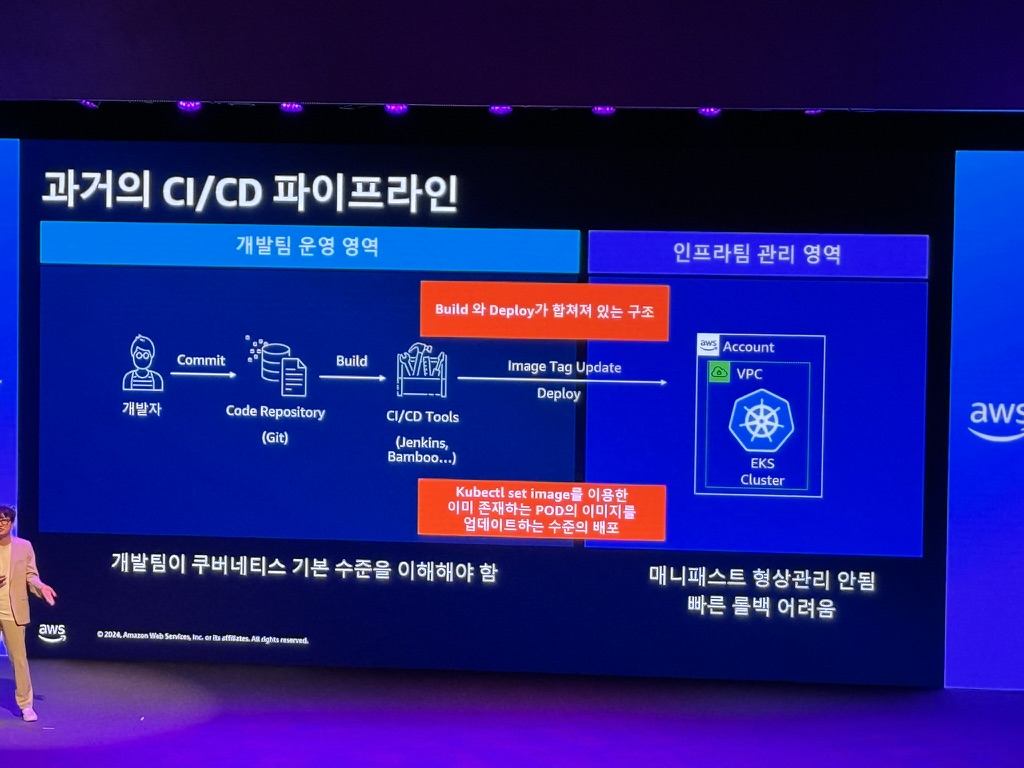
CI/CD 이슈
- R&R: 빌드와 배포는 개발팀. 배포된 인프라의 운영은 인프라팀이 담당하여 책임 소재가 모호
- 복잡성: 인프라와 CI/CD 도구가 팀별로 다르고 복잡하여 배포 방식 상이함 (매니페스트 파일)
- 진입장벽: 개발팀이 CI/CD와 배포 모니터링을 위해서 쿠버네티스 이해 필요 (진입장벽 존재)
어떻게 문제를 해결할까?
- 배포 진입장벽 해소: 개발자는 개발에만 집중하고 어플리케이션 배포는 손쉽게할 수 있어야함 (쿠버네티스 러닝커브 최소)
- 빌드와 배포 분리: 간단하게 배포에 필요한 정보를 요청받고, 템플릿 변환 엔진을 이용하여 복잡한 쿠버네티스 매니페스트 Yaml 생성
- Gitops: 쿠버네티스 매니패스트 파일 형상관리 ArgoCD를 통한 자동화된 배포 적용
커스텀 배포 API
- 쉽고 표준화된 배포에 필요한 정보를 수신 후 복잡한 쿠버네티스 매니페스트로 변환 (요청정보를 Yaml로 변환)
변경 후, 빌드/배포 프로세스

무엇이 좋아졌나요?
- R&R 정리: 개발자는 개발만! 배포와 클러스터 운영은 인프라 엔지니어가 관리!
- 복잡성 해소: 매니페스트 중앙 집중 관리에 따른 일관성있는 k8s 리소스 관리
- 진입장벽 해소: 클라우드 및 쿠버네티스 지식이 없어도 쉬운 배포 가능
- 개발자는 복잡한 쿠버네티스, 인프라 운영 이해 없이 어플리케이션 개발에만 집중
템플릿 변환 엔진을 활용한 리소스 파일 관리
점점 늘어나는 매니페스트 Yaml
- 어플리케이션 현대화(MSA)에 따라 리소스가 많아지고 있음
템플릿 관리도구
- 관리의 편의성을 위해 정적인 템플릿 설정 값을 동적으로 반영하여 k8s 리소스를 생성해주는 도구 필요
- Helm vs. Kustomize
- 하지만, 정적 템플릿 구조 변경 시 수십~수백개의 다수 템플릿 수정을 수작업으로 하나씩 해줘야 하는 문제
대규모 정적 템플릿 변경 사례

대규모 매니페스트 관리를 위한 아키텍처
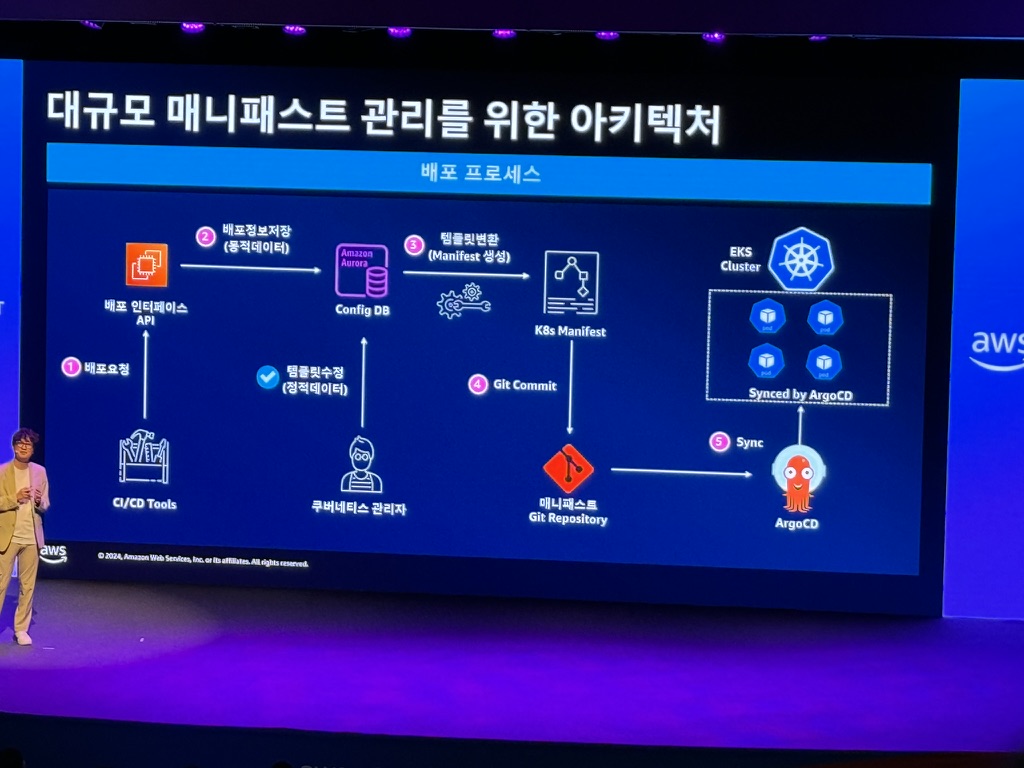
마무리
- 안정성과 생산성 향상을 위해서
- EKS 무중단 업그레이드
- EKS 무중단 업그레이드 및 새로운 Add-on 적용을 비지니스 중단 없이 하기위해 Active-Active 클러스터 구조로 운영 하고 있음
- 배포 진입장벽 감소
- 배포 진입장벽을 낮추기 위하여 커스텀 배포 API를 구성하여 빌드와 배포를 분리 간단한 배포정보만 요청으로 복잡한 매니패스트로 자동변환 템플릿 엔진을 자체 개발/운영
- 대규모 매니패스트 통합 관리
- 대규모 매니패스트 수정을 일괄적으로 하기 위해 정적 템플릿 정보들 테이블 기반으로 관리하고 Query기반으로 처리
