Linux health-check 검증
이 글은 2편 시리즈의 2편입니다.
- 1편: 도구 소개 — 왜 만들었는지, 어떻게 동작하는지
- 2편: 검증 — 직접 장애를 주입하고 탐지/판정/대응 루프 확인
들어가며
1편에서 헬스체크가 무엇을 하는지 설명했습니다.
이 글에서는 실제로 제대로 작동하는지 직접 서버에서 확인합니다. 도구가 "CRITICAL"을 출력한다고 해서 진짜로 탐지가 된 건지, 숫자만 보고 판단하는 건지를 검증하는 과정입니다.
검증 방법은 간단합니다. 의도적으로 문제 상황을 만들고, 도구가 올바르게 감지하는지 보는 것입니다.
총 4가지 시나리오로 진행합니다.
| 시나리오 | 주입하는 장애 | 기대하는 반응 |
|---|---|---|
| 1 | CPU 100% 부하 | SPIKE 탐지 + CRITICAL 판정 |
| 2 | I/O 집중 부하 | CPU는 낮은데 Load Average 상승 |
| 3 | 메모리 압박 반복 | TREND_UP 추세 감지 |
| 4 | 보안 설정 고의 변경 | CRITICAL 판정 + 조치 권고 출력 |
사전 준비
stress-ng 설치
# Ubuntu / Debian
sudo apt install -y stress-ng
# 설치 확인
stress-ng --version헬스체커 준비
cd ~/linux-health-checker
chmod +x health-check.sh이력 초기화 (중요)
테스트 전에 기존 이력을 지우는 걸 권장합니다.
SPIKE 감지는 "기존 평균 대비 얼마나 튀었나"로 판단합니다. 기존 이력에 이미 CPU가 높은 수치가 남아 있으면, 100% 부하를 줘도 큰 차이가 없어 SPIKE로 감지되지 않을 수 있습니다.
기존 이력: CPU 2%, 3%, 4% → 평균 3%
새 측정값: CPU 95% → 급등 감지 → SPIKE ✅
기존 이력: CPU 70%, 80%, 90% (이미 높은 이력)
새 측정값: CPU 95% → 큰 차이 없음 → SPIKE 미감지 ❌# 현재 이력 파일 확인
ls -lh reports/history/
# 이력 전부 삭제
rm -f reports/history/*.json
# 삭제 확인
ls reports/history/
# → (비어 있으면 정상)기준선 실행 (2회)
이력을 지웠으면 정상 상태에서 2회 먼저 실행합니다. 이력이 2개 이상 쌓여야 추세 비교가 시작됩니다.
# 1회 실행
./health-check.sh run
# 2회 실행
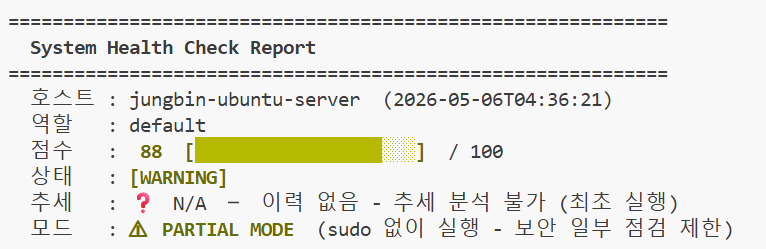
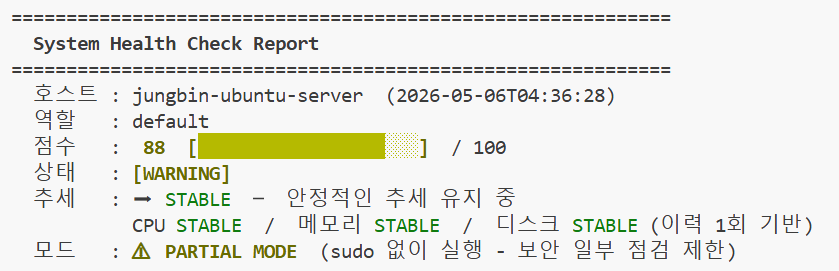
./health-check.sh run이 시점에서는 추세: ❓ N/A 또는 STABLE이 나와야 정상입니다. 이후 시나리오에서 부하를 주면 이 기준선과 비교해서 SPIKE/TREND_UP이 감지됩니다.
부하 없는 정상 상태에서의 기준 점수 (이 점수와 비교합니다)
로그 파일 확인 명령어
헬스체커가 생성하는 파일들을 미리 확인해 두세요.
# 감사 로그: 모든 실행 이력
cat logs/audit.log
tail -20 logs/audit.log # 최근 20줄만
# 이력 JSON 파일 목록 (실행할 때마다 하나씩 생김, 최근 5개 유지)
ls -lh reports/history/
# 가장 최근 이력 내용 확인
cat reports/history/$(ls -t reports/history/ | head -1) | python3 -m json.tool시나리오 1: CPU 100% 부하 → SPIKE 탐지
장애 주입
CPU를 모든 코어에서 100%로 올립니다.
# 터미널 1: CPU 부하 시작 (60초간 유지)
stress-ng --cpu $(nproc) --timeout 60s &
# 3초 후 헬스체커 실행
sleep 3 && ./health-check.sh run무슨 일이 벌어지는가
stress-ng --cpu $(nproc)은 서버의 모든 CPU 코어를 수학 연산으로 100% 점유시킵니다.
$(nproc)는 현재 서버의 CPU 코어 수를 자동으로 가져옵니다.
헬스체커의 resource.sh는 vmstat을 2회 샘플링해서 CPU 사용률을 수집합니다.
부하가 걸린 상태에서 실행하면 80% 이상이 잡히고, 임계치를 초과하면 CRITICAL 또는 WARNING으로 판정됩니다.
추세 분석은 이력이 2개 이상일 때 작동합니다. 이전에 CPU가 낮았는데 갑자기 높아졌다면 SPIKE로 표시됩니다.
예상 결과
CPU 사용률 95% ← 임계치(95%) 초과
상태 : [CRITICAL]
추세 : 🔺 SPIKE ← 평소 대비 급등 감지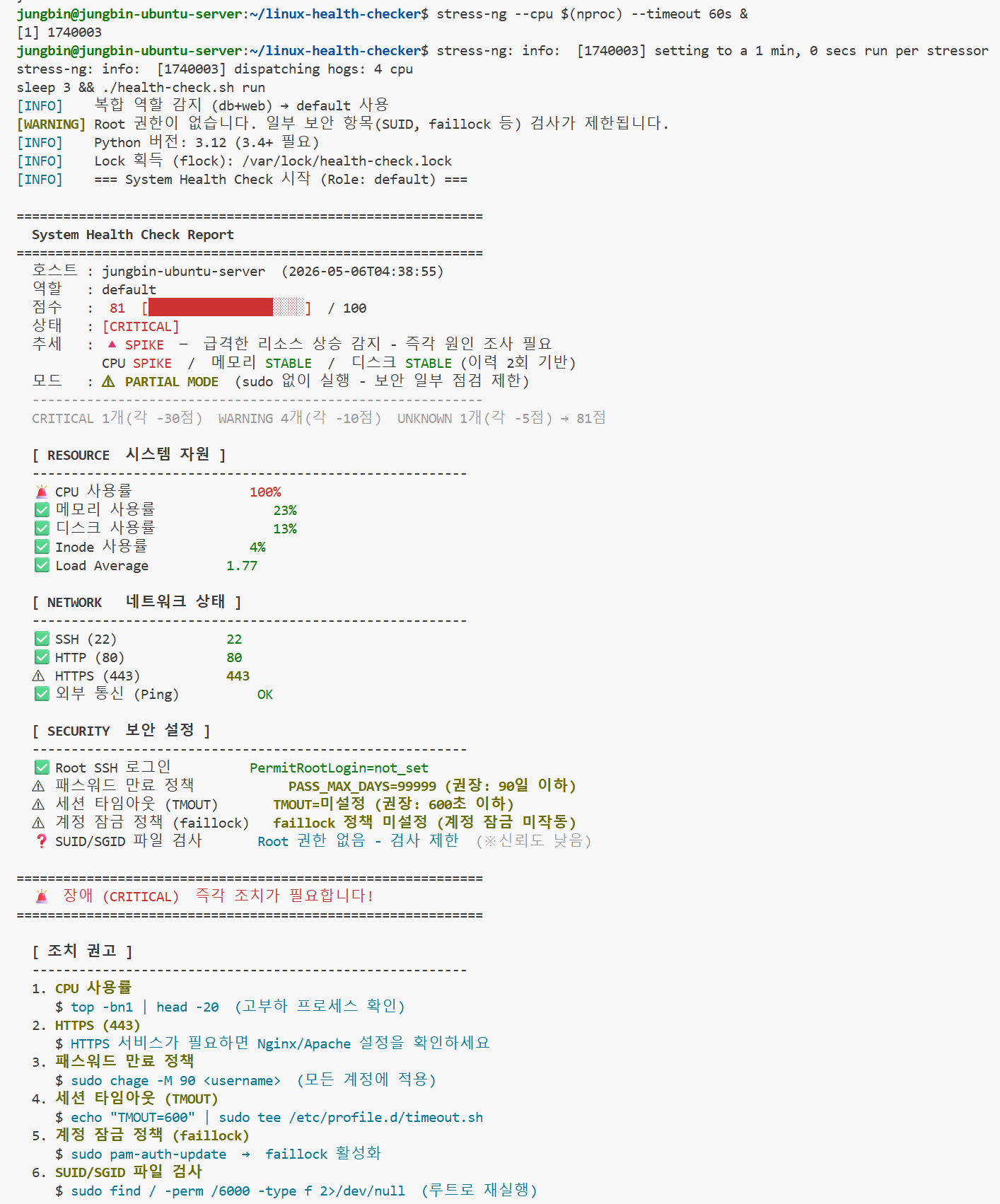
부하 해제
# stress-ng 종료
pkill stress-ng
# 정상 복귀 확인
./health-check.sh run시나리오 2: I/O 부하 → CPU는 낮은데 Load Average 상승
"top만 보면 CPU가 낮아서 정상처럼 보이지만 실제로는 서버가 느린 상황"을 재현합니다.
장애 주입
# 터미널 1: I/O 집중 부하 (디스크 읽기/쓰기 반복)
stress-ng --io 4 --hdd 1 --timeout 60s &
# 3초 후 헬스체커 실행
sleep 3 && ./health-check.sh run무슨 일이 벌어지는가
--io 4는 I/O 시스템콜을 4개 프로세스로 집중적으로 호출합니다. --hdd 1은 디스크에 실제로 데이터를 쓰고 지우는 작업을 반복합니다.
이 상태에서 top을 보면 us(사용자 영역 CPU)는 낮습니다. 하지만 wa(I/O Wait)가 높아집니다. CPU가 I/O 작업 완료를 기다리느라 대기 상태이기 때문입니다.
Load Average도 올라갑니다. b(Blocked) 프로세스가 늘어나기 때문입니다.
헬스체커는 Load Average를 코어 수 × 1.5 기준으로 판정합니다. 4코어 서버라면 4 × 1.5 = 6.0이 임계치입니다.
I/O 집중 부하 상황에서는 D 상태(디스크 대기 중) 프로세스가 쌓여서 Load Average가 6.0을 훨씬 넘길 수 있습니다.
예상 결과
CPU 사용률 8% ← 낮음 (top만 보면 정상처럼 보임)
Load Average 7.42 ← 임계치(4코어 × 1.5 = 6.0) 초과 → WARNING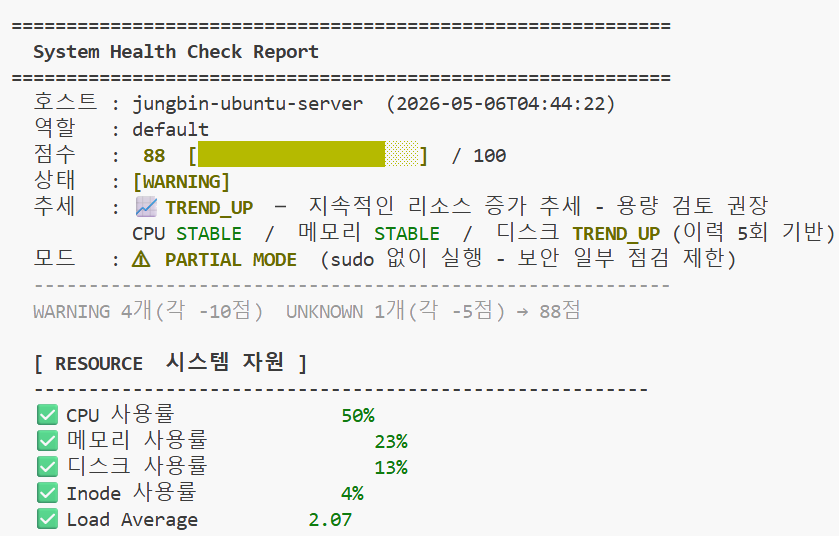
부하 해제
pkill stress-ng시나리오 3: 메모리 압박 반복 → TREND_UP 추세 감지
추세 분석 기능을 검증합니다. 메모리 사용량이 조금씩 올라가는 상황을 만들어서 TREND_UP이 뜨는지 확인합니다.
장애 주입
# 1회 실행 후 기록
./health-check.sh run
# 메모리 압박 (500MB 점유 후 해제, 이력만 남김)
stress-ng --vm 1 --vm-bytes 500M --timeout 5s
./health-check.sh run
# 조금 더 올려서 다시
stress-ng --vm 1 --vm-bytes 700M --timeout 5s
./health-check.sh run
# 한 번 더
stress-ng --vm 1 --vm-bytes 900M --timeout 5s
./health-check.sh run각 실행 사이에 메모리 사용량이 조금씩 올라가는 이력이 쌓입니다.
무슨 일이 벌어지는가
헬스체커는 실행할 때마다 reports/history/ 폴더에 JSON 파일을 저장합니다. 이력이 2개 이상 쌓이면 최근 값들의 방향을 계산합니다.
값이 계속 올라가고 있으면 TREND_UP, 갑자기 튄 경우는 SPIKE, 안정적이면 STABLE로 표시됩니다.
예상 결과
추세 : 📈 TREND_UP ← 메모리 지속 상승 감지
메모리 TREND_UP / CPU STABLE / 디스크 STABLE (이력 5회 기반)
실행 후
TREND_UP경고가 뜨는 화면 (이력 몇 회 기반인지 표시됨)
현재 이력 5회 기반
이력 파일 확인:
ls -lh reports/history/
# 실행할 때마다 파일이 하나씩 쌓임 (최근 5개만 유지)
시나리오 4: 보안 설정 수정 → WARNING → 조치 → OK 확인
앞선 세 가지는 인위적으로 부하를 주는 테스트였습니다. 이 시나리오는 이미 서버에 존재하는 보안 문제를 발견하고, 고치고, 다시 확인하는 탐지/판정/대응 루프 전체를 확인합니다.
Ubuntu를 설치하면 패스워드 만료 정책이 기본값 99999일로 설정됩니다. 사실상 만료 없음과 같습니다. 이 상태로 서버를 운영하는 경우가 많습니다.
현재 상태 확인 (탐지)
# 현재 패스워드 만료 정책 확인
grep PASS_MAX_DAYS /etc/login.defs
# → PASS_MAX_DAYS 99999이미 문제가 있는 상태입니다. 헬스체커를 실행하면 이걸 잡아냅니다.
sudo ./health-check.sh run무슨 일이 벌어지는가
security.sh는 /etc/login.defs에서 PASS_MAX_DAYS 값을 읽습니다. 90일을 초과하면 WARNING으로 판정합니다.
리포트 하단에는 어떻게 고치면 되는지 명령어가 같이 출력됩니다.
예상 결과 (판정)
[ SECURITY 보안 설정 ]
⚠ 패스워드 만료 정책 PASS_MAX_DAYS=99999 ← WARNING
상태 : [WARNING]
[ 조치 권고 ]
1. 패스워드 만료 정책
$ sudo chage -M 90 <username>설정 수정 (대응)
# 90일로 변경
sudo sed -i 's/^PASS_MAX_DAYS.*/PASS_MAX_DAYS 90/' /etc/login.defs
# 변경 확인
grep PASS_MAX_DAYS /etc/login.defs
# → PASS_MAX_DAYS 90수정 후 재점검 (검증)
sudo ./health-check.sh run [ SECURITY 보안 설정 ]
✅ 패스워드 만료 정책 PASS_MAX_DAYS=90 ← OK
상태 : [OK] ← WARNING이 사라졌습니다
이것뿐만 아니라 보안 설정에 나오는 다른 것들도 직접 수정하면서 확인해볼 수 있습니다.
탐지/판정/대응 루프 요약
시나리오 4에서 루프 전체가 한 번에 작동했습니다.
1. 탐지 (Detection)
security.sh → /etc/login.defs 읽음
PASS_MAX_DAYS=99999 확인 (90일 초과)
2. 판정 (Decision)
score.py → 보안 항목 WARNING 판정
WARNING 항목 누적 → 최종 상태 WARNING (Exit 1)
3. 대응 (Response)
reporter.py → 하단에 조치 명령어 출력
수정 후 재실행 → OK로 변경 확인스크립트가 숫자만 보여주는 게 아니라, 무엇이 문제이고 어떻게 고치면 되는지까지 하나로 확인할 수 있습니다.
검증 결과 정리
| 시나리오 | 탐지 | 판정 | 대응 |
|---|---|---|---|
| CPU 100% 부하 | ✅ SPIKE 감지 | ✅ CRITICAL/WARNING | ✅ 조치 권고 |
| I/O 집중 부하 | ✅ Load Average 상승 감지 | ✅ WARNING | ✅ 조치 권고 |
| 메모리 압박 반복 | ✅ TREND_UP 감지 | ✅ WARNING | ✅ 조치 권고 |
| 보안 설정 변경 | ✅ PermitRootLogin yes 감지 | ✅ CRITICAL | ✅ 복구 명령어 출력 |
마무리
네트워크 지연이나 패킷 손실 같은 외부 연결 문제는 이 로컬 헬스체크만으로는 한계가 있습니다. 이런 부분은 mtr이나 prometheus-node-exporter 등 외부 모니터링 도구와 함께 사용해야 온전한 관측이 가능합니다.
stress-ng로 만든 장애는 실제 운영 환경과 완전히 같지는 않습니다. 실제로는 배포 잘못 나간 서비스가 CPU를 잡아먹거나, 로그 로테이션을 빠뜨리거나, 신규 서버 보안 설정을 기본값으로 올리는 경우가 더 흔합니다.
