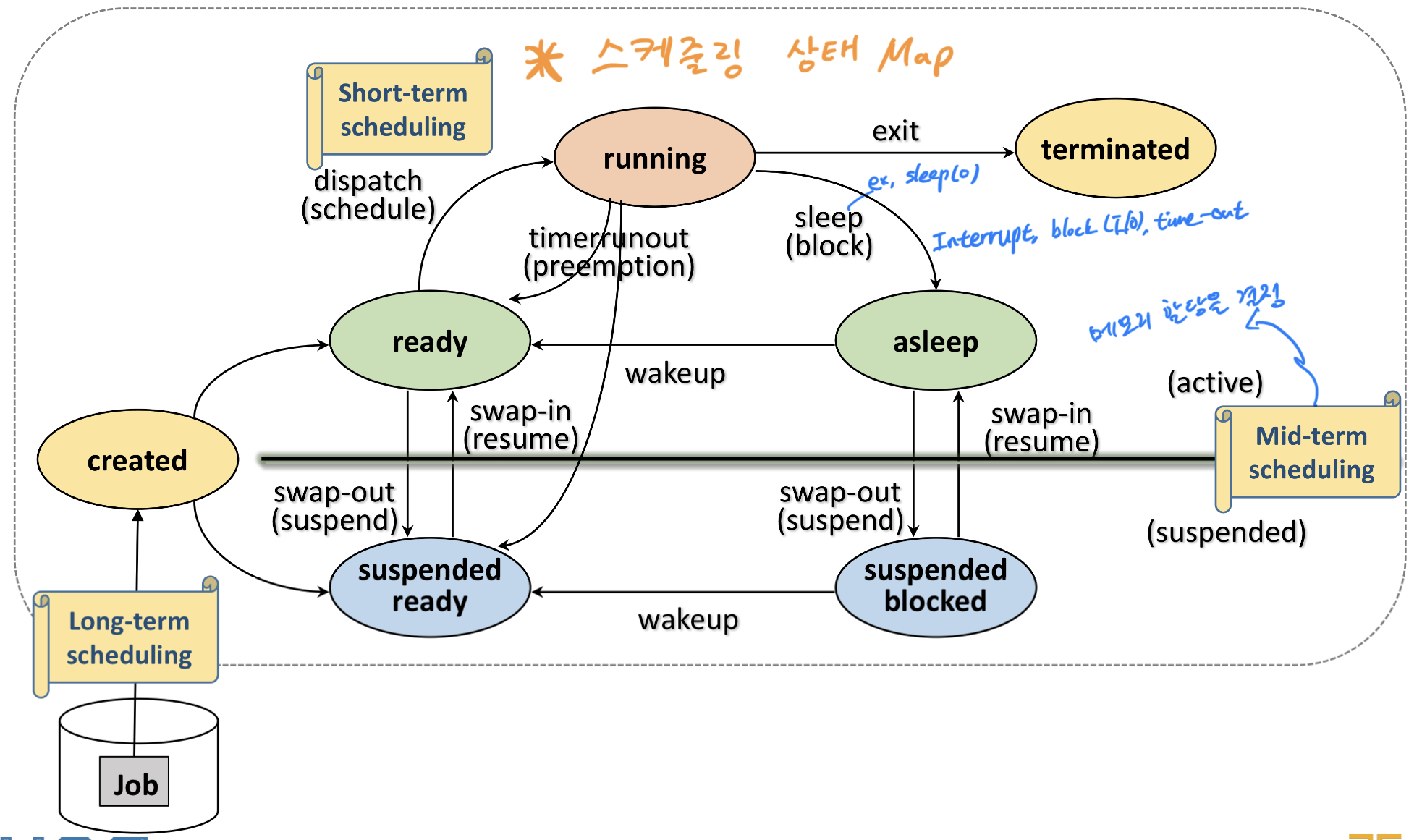
OS - Isolation & Protectoin(링크)
위 링크에서 cpu scheduling에 대해 얘기했었습니다.
오늘은 위에서 다뤘던 cpu scheduling에 대해 좀 더 자세히 얘기해봅니다.
CPU scheduling 이란?
OS가 실행 중인 여러 프로세스들이 실행되기 위해 CPU를 effectively(효율적으로) 하게 프로세스들에게 assign(할당)하는 것을 말합니다.

프로세스들을 실행시키는 mechanism(매커니즘)에서 다양한 policy들이 존재합니다.
effectivly 의 기준이 실행되는 tasks들의 상황에 따라 다를 것이고 이에 따른 다양한 policy들이 존재하는데 이를 알아보도록 합시다!
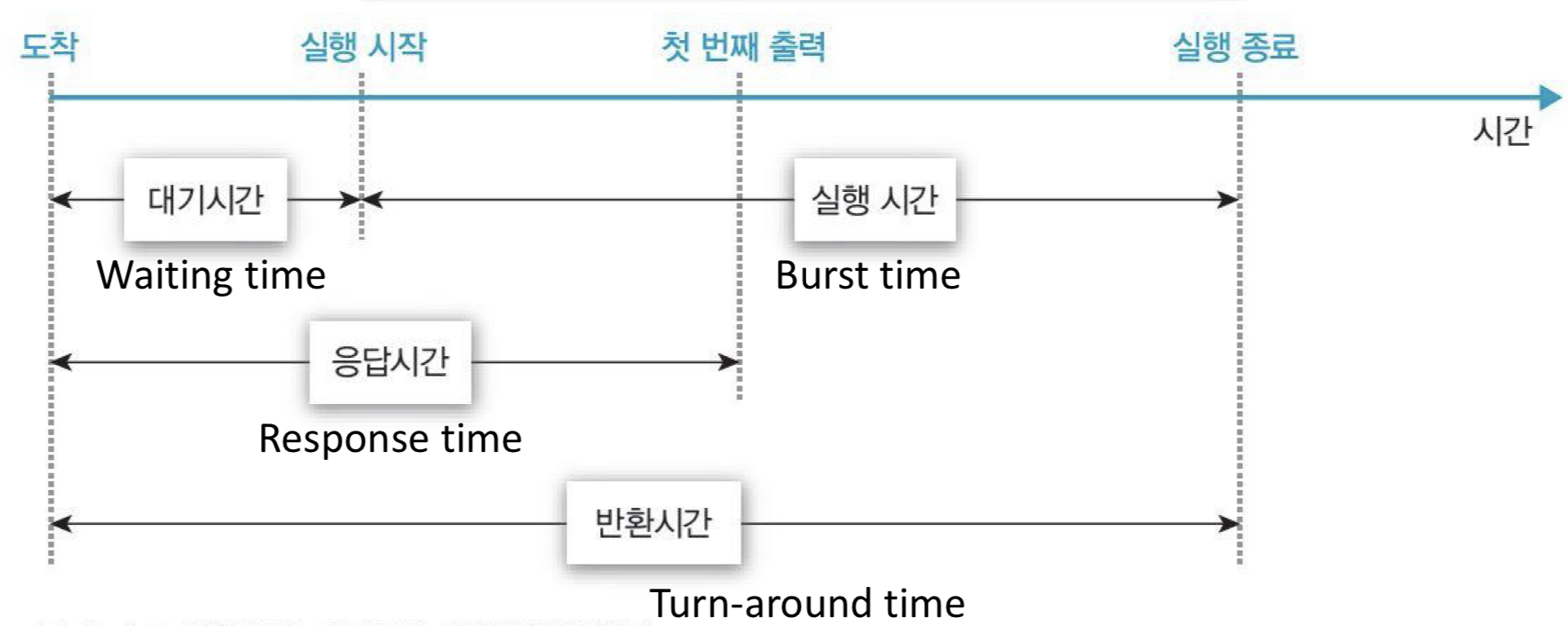
평가기준들
-
turn-around time: 시작하고 끝날 때 까지 시간
T(turnaround) = T(completion) - T(arrival)
or Burst time + Waiting time -
response time: task를 넣으면 어느 시점에 반환되는지. 작업 요청으로부터 응답을 받을때까지의 시간입니다.
_Response time is the time spent when the process is in the ready state and gets the CPU for the first time. -
throughput: 단위 시간 동안 완료된 작업의 수를 말합니다
이 외에도 꽤나 많은 지표들이 있던데 제가 남긴 기준들이 대표적으로 많이 언급되는 기준들입니다.
프로세스 특성, 긴급성(어느정도 real time 시스템인지), 프로세스 우선순위, 프로세스 총실행시간 등을 위 기준과 고려하여 효율적인 스케줄링 기법을 선택하여야함!!
preemtive vs non-preemptive
스케줄링 policy를 선점 vs 비선점으로 구분할 수 있다.
프로세스가 wait 상태에 있다가 깨어났을 때 이미 실행 중인 프로세스의 우선순위가 낮더라도 해당 프로세스를 block 시켜서 cpu 자원을 반납하게 하냐 안하냐의 두 종류로 나눠볼 수 있습니다.
non-preemptive scheduling
비선점 스케줄링은 할당 받았을 때 스스로 반납할 때 까지 사용하게 됩니다.
- 장점: context switching이 적게 발생해 오버헤드가 적게 발생한다는 점
- 단점: 우선 순위 역전현상이 발생함(우선 순위 높은 프로세스가 스케줄링 되어도 다른 우선순위 낮은 프로세스가 실행되고 있으면서 양보하지 않음), 평균 응답 시간 증가 (마찬가지의 이유)
sleep(0) 자발적으로 cpu 자원을 내려놓아서 우선순위가 높은 것이 있을 때 내려놓도록함.
non preemptive 방식에서는 필수적으로 보인다. while문 안에 보통 들어있다고 한다.
preemtive scheduling
할당 시간이 종료된다거나, 우선순위 높은 프로세스가 등장하는 경우 실행 중인 프로세스는 cpu 점유를 빼앗길 수 있음.
빼앗기는 시점도 바로 빼앗기느냐, 어느 시점까지 기다렸다가 그 이후에 preemptive할 것 인가 생각해보면,
공격적으로 프리엠션 할 수록 response는 더 빨라진다.
Scheduling algorithms
그럼 기본적인 스케줄링 알고리즘들에 대해 알아봅시다.
- FIFO(First In, First Out / non-preemptive)
ready queue로 도착한 시간을 기준으로 먼저 도착한 프로세스를 먼저 처리합니다.
실행 도중에 다른 프로세스가 들어오더라도 양보하지않고 해당 프로세스가 처리된 이후에 다음 도착한 프로세스가 처리 됩니다. 비효율적으로 보일지라도 convoy effect(특정 작업시간이 긴 프로세스로 인해 뒤에 프로세스가 실행시간에 비해 긴 대기시간이 발생하는 현상)가 발생하지 않거나 convoy effect가 큰 영향을 주지 않는 상황이라면
scheduling overhead가 적고 처리량도 우수합니다.
따라서 일괄처리(Batch system)에는 적합한 알고리즘입니다. 반대로 interactive system에는 써서는 안될 알고리즘입니다.
장점: Batch system에 적합, scheduling overhead 적음
단점: Convoy effect(very high response time)
- SJF (Shortest Job First, non-preemptive)

실행시간(burst time - cpu를 얼마나 쓸 건지)를 기준으로 실행시간이 가장 작은 프로세르를 먼저 처리하는 알고리즘
마트에 가보면 계산대는 먼저오는 사람 것을 먼저 처리해주는 FIFO 방식이지만 가끔 앞에 와계신분들이 있더라도 아이스크림 하나나 우유하나만 들고 서있으면 먼저 계산을 해주시는 경우가 간혹 가다 있는데 이 경우 SJF로 실행되었다고 볼 수 있을 것 같다.
위 그림은 소량 계산대사진을 들고 오긴하였으나 엄밀히 얘기하면 소량 계산대가 따로 있는 것은 아니고, 다 같은 계산대에서 계산되지만 사는 물건이 적어서 금방 끝날 사람부터 먼저 보내주는 것!
장점: 평균 대기시간을 최소화함, 시스템 내 프로세스 수 최소화(줄 서있는 사람의 수는 최소화됨!). 이에 따른 스케줄링 부하 감소, 메모리 절약됨! 그리고 good turn-around time!
단점: Starvation. 실행 시간이 긴 프로세스들 입장에서는 대기 중에 실행시간이 짧은 프로세스들이 지속적으로 ready 상태로 들어온다면 계속 새치기를 당할 수 밖에 없고 결국 실행되지 못하게 될 수 있음
- STCF (Shortest Time-to-Completion First, preemptive)
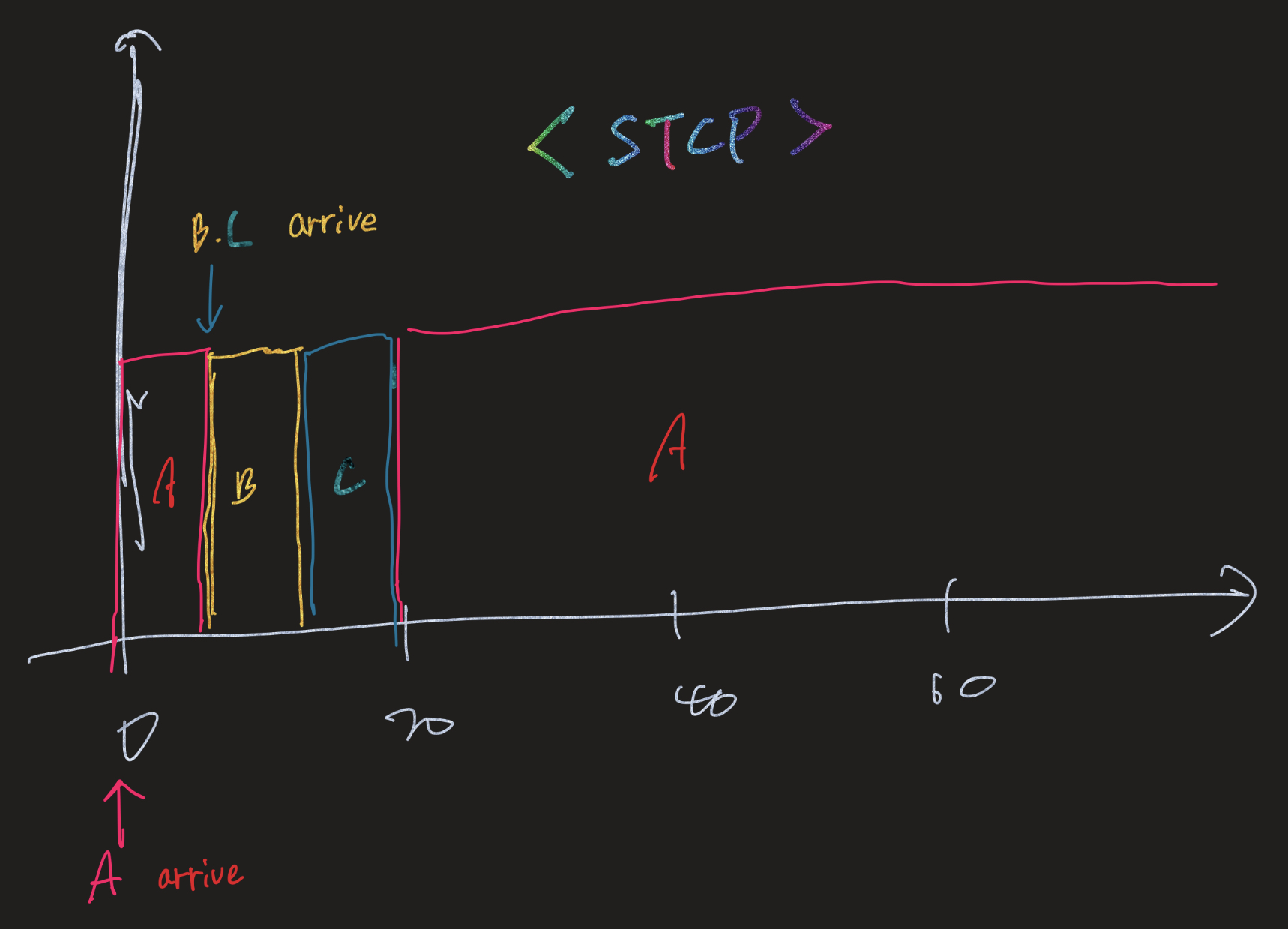
(그림의 허접함을 용서하세요..)
위 SJF 방식의 특성을 더 살린 알고리즘. SJF 방식은 non-preemptive 방식이기에 위 그림과 같이 A 도착후 B, C가 도착했다면 그래도 먼저 도착한 A 먼저 실행되는 것에 비해 STCF는 실행되는 프로세스 조차도 선점으로 cpu 자원을 가져가버린다.
- 장점: SPN의 장점을 극대화함
- 단점: 프로세스 생성 시 총 실행시간 예측이 필요, context switching에 따른 overhead, 잔여 실행시간 추적에 따른 overhead 발생
- Round robin
도착시간을 기준으로 먼저 도착한 프로세스를 먼저 처리하지만 사용시간제한(time quantum)이 있습니다. 사용 시간이 지나면 자원을 반납함. time quantum을 어떻게 정하냐가 시스템의 성능을 결정하는 요소임. 너무 짧으면 context switching 비용 증가, 너무 길면 respose time의 감소
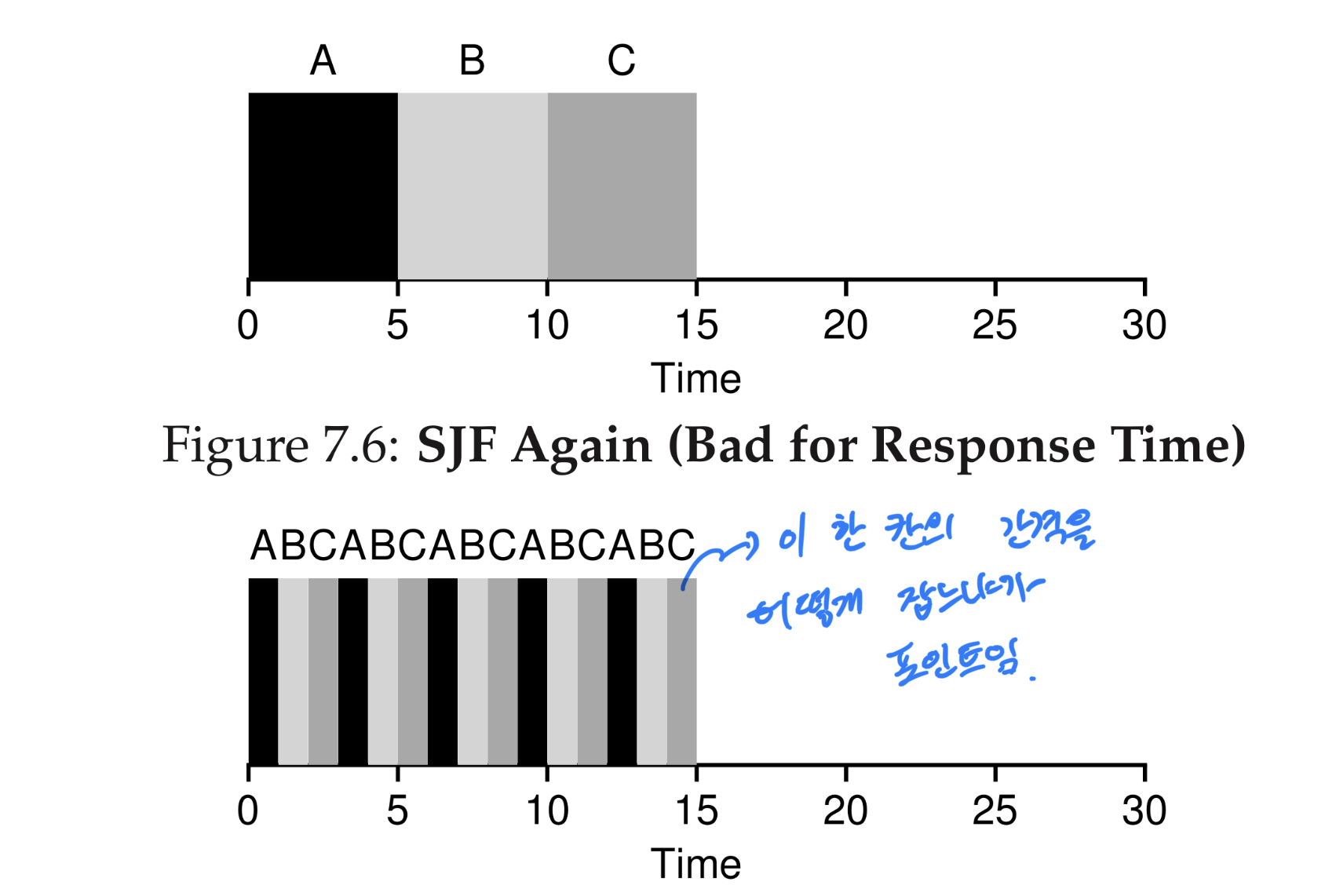
장점: No starvation, good response time
단점: bad turnaround time
SJF 의 starvation 현상이 발생하지 않고 respose time도 뛰어나다.
context switching 비용이 높다. 이를 낮추려고 time 간격을 늘리면 respose 타임이 길어진다.
=> 그래서 처음에는 짧게 주고 나중에는 길게 주는 MLFQ 방식을 사용함!
MLFQ(Multi-Level Feedback Queue
MLFQ는 우선순위가 다른 여러개의 큐를 만들어놓고, 처음 스케줄링 되었을 때는 가장 높은 우선순위 큐로 들어갔다가 일정시간 이상 cpu를 점유할 경우 우선순위가 한단계 낮은 큐로 떨어지게 된다. 각 우선순위의 큐는 RoundRobin 방식으로 돌아간다.
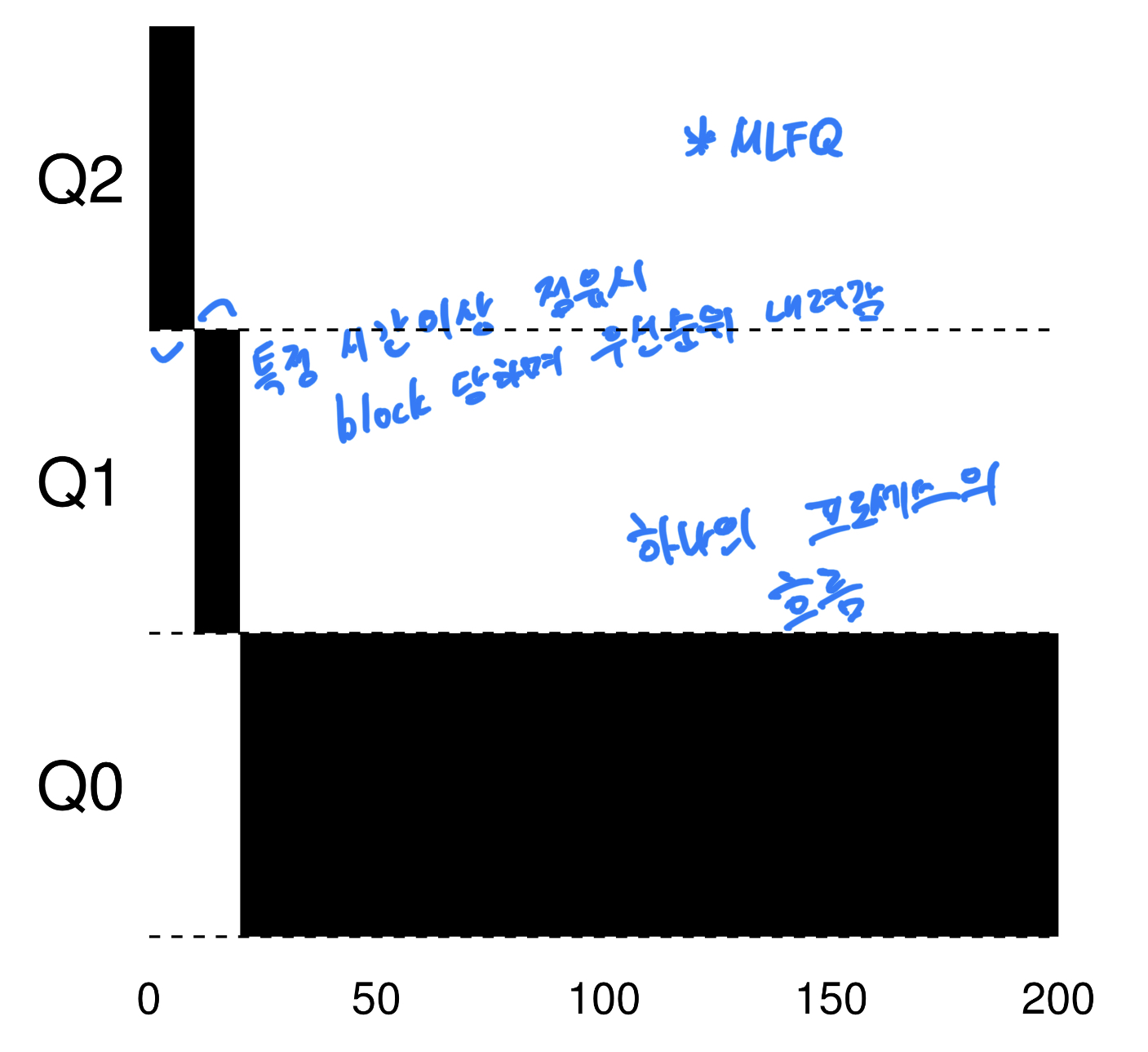
그림과 같이 하나의 process가 들어왔을 때만 생각해보면 처음에는 가장 높은 우선순위큐에서 돌아가다가 일정 시간 후에는 한칸씩 우선순위가 내려감을 알 수 있다.
SJF, SCTP 방식은 turn-around time은 좋지만 starvation 현상이 발생했고,
FIFO 방식은 convoy effect만 아니면 긴 running time을 가진 "cpu-bound" 한 프로세스들에 좋은 알고리즘 이었는데 위에 언급된 알고리즘들의 단점을 보완하면서 장점은 챙긴 알고리즘이라고 할 수 있다.
처음 우선순위가 높을 때 실행시간을 짧게 하고 우선순위가 낮아질 수록 실행시간은 길게해주기 때문이다.
핀토스에서는 해당 스레드의 우선순위는 다음 식으로 변경되었다.
priority = PRI_MAX - (recent_cpu / 4) - (nice * 2)
처음에는 PRI_MAX, 즉 우선순위 최대치로 주고 recent_cpu 사용시간이 증가할 수록 우선순위가 내려간다.
본래 cpu 스케줄링은 OS의 스케줄러프로세스의 몫이지만 nice란 변수는 유저가 해당 프로세스의 우선순위를 어느정도 개입할 수 있는 부분이다. nice 변수를 유저가 낮게 줄 수록 해당 프로세스의 우선순위가 높아져 다른 프로세스에게 cpu점유권을 잃지 않는다. nice함이 낮을 수록 욕심쟁이 프로세스이기에 cpu를 우선점유한다!
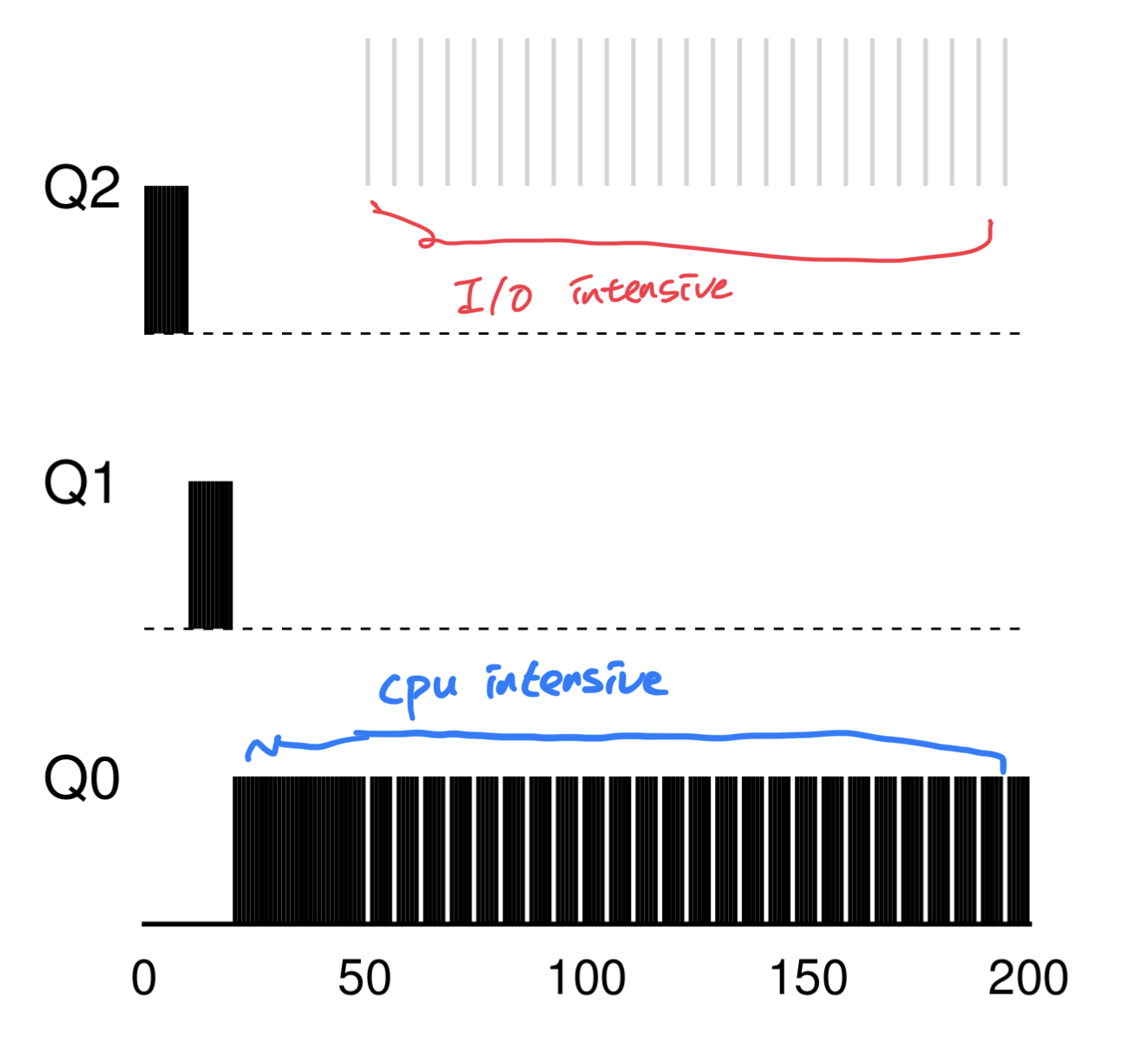
SJF, SCTP 방식은 실행시간을 측정해야하는데 이 예측이 어렵고 이에 따른 부하도 발생하는 점도 사라진다.
지금까지 언급한 부분에서는 여전히 mlfq같은 방식도 starvation 현상이 발생 할 수 있다. 짧은 I/O가 많이 발생할 경우 여전히 우선순위가 낮은 프로세스는 실행이 안될 수 있기 때문이다. 이를 막고자 일정 시간에 모든 프로세스를 다시 우선순위가 가장 높은 큐로 올려줘서 아래에 있는 프로세스도 다시 cpu를 점유할 수 있게끔 한다.
pintos를 구현할 때는 64개의 우선순위 큐가 있었는데 몇개의 우선순위 큐를 둘 것인지, 각 큐에서 실행되는 시간은 얼마로 할 것인지, 또한 boost 는 어느 간격으로 실행할 것인지에 따라 성능이 나뉘게 된다.
본 게시글은 권영진교수님 OS수업, OSTEP, 유튜브 강의 와 저의 아이패드를 참고하여 작성되었습니다

공부하다 나온 모르는 개념:
context-switching으로 인해서 발생하는 비용에 영향을 주는 부분을 cache, TLB 만 알고있었는데 branch predictors and other on-chip hardware 라는 부분도 있음
