File Organization(파일 구성)
-
A file is organized logically as a sequence of records.
파일은 논리적으로 일련의 레코드로서 구성됨 -
Each file is also logically partitioned into fixed-length storage units called blocks, which are the units of both storage allocation and data transfer.
각 파일은 블록 이라는 고정 사이즈로 분할 된다. 블록은 스토리지 할당과 전송 단위이다. -
블록은 여러 레코드를 포함한다. 이 책에서는 현실적으로 블록보다 더 큰 레코드는 없으며 단일 블록은 각 레코드를 완전히 포함한다고 가정한다. 블록사이즈 보다 큰 것은 DBMS에서 블록단위로 저장하는 것이 아닌 파일 시스템에서 저장하는 방식 등 별도로 다룬다.
데이터베이스에서 데이터를 저장하는 방법은 여러 파일을 사용하면서 주어진 파일 내에서는 고정된 길이 레코드만 저장하거나 가변 길이의 레코드로 저장하는 방법이 있다.
13.2.1 Fixed-Length Records
다음과 같은 instructor record 파일을 예가 나온다.
type instructor = record
ID varchar (5);
name varchar(20);
dept_name varchar (20);
salary numeric (8,2);
end(record 3) 도 있다고 우선 가정하에, ID에 5바이트, name에 20바이트, dept_name에 20바이트, salary에 8바이트 = 총 53바이트다.
위 그림에서 각 레코드당 53바이트씩 고정된 크기로 저장한 것 이다.

이 방식의 두 가지 문제점이 나오는데,
1. 블록 크기가 53바이트를 초과할 경우. 이런 경우 이런 레코드를 읽고 쓰기 위해서 두 블록에 모두 접근해야한다고 한다.
여기서 드는 생각은.. 그러게 초기 설정을 잘하시지그러셨.. ㅋㅋㅋ 위 그림과 다르게 고정블럭 크기를 초과하는 데이터를 허용한다면 이를 트래킹이나 컨트롤하기 위한 overhead 가 발생할 것 같다.
2. 이 구조에서는 레코드를 삭제하기 어렵다. 위 캡쳐한 그림의 경우 빨간색에 record3를 지우고, 빈 공백을 메우기 위에 그 밑에 데이터들을 위로 옮겨준 것을 보여준다. 데이터의 전체크기가 클수록 더 많은 비용이 소모될 것 이다. 이를 피하는 방법은 추가되는 데이터를 비어있는 자리에 넣는 방법이다.
이 경우 비어있는 리스트를 관리하고 있어야하는데 그림과 같이 빈 리스트들을 LinkedList로 묶어놓고 레코드가 추가될 때 해당 자리에 할당하면 된다. malloc 함수 구현하는 코드에서 할당 방법 중 할당 가능한 블럭들을 LinkedList들로 묶어두는 방식이 있었는데 그와 동일한 원리다.
이 방식의 단점은 record들 간에 삽입 순서를 보장하지 못하고 섞이게 된다. 그럼 삭제 후 데이터를 당겨주는 방식에 비해 insert된 순으로 가져올 때 더 시간이 소요될 것으로 보인다.
13.2.2 Variable-Length Records
strings, arrays, multisets 와 같은 데이터로 인해 가변적 길이의 레코드가 필요한 상황이 있다. 가변적인 길이의 레코드를 구현 하기 위해서는 두 가지가 고려되어야 한다.
- 가변적인 길이인 경우에도 개별 데이터를 쉽게 추출할 수 있는 방식으로 레코드를 표현 할 수 있어야 한다.
(How to represent a single record in such a way that individual attributes can be extracted easily) - 블록 내에서 레코드를 쉽게 추출할 수 있도록 저장하는 방법
(How to store variable-length records within a block)
책에서 두 가지라하여 쓰긴했는데 둘 다 결국 같은 의미 아닌가? 고정길이 방식에서는 고정된 사이즈 별로 바이트 수 계산하면서 원하는 위치에 접근할 수 있지만 가변길이에서는 다른 방법이 필요하다.

가변길이의 속성을 지닌 레코드 표현은 두 부분으로 구성된다. 고정영역과 가변영역. 가변 길이를 얘기하다가 왜 고정이 나올까?
가변 길이의 레코드 안에는 여러 attributes들이 있을 수 있는데 이 attribute 들 중에는 가변적인 길이를 갖는 속성과 가변길이를 갖는 속성이 있기 때문이다. 전부 고정길이라면 위 고정길이 방식으로 레코드를 저장하면 되겠지만 하나의 attibute가 가변길이라면 가변 길이의 레코드를 택해야하는 것 이다.
고정 영역에는 가변길이의 attribute 값이 블록 내에 어디에 있는지를 offset, length로 표시해놓고, 고정길이 attribute를 넣는다. 오른쪽 영역에는 가변 attribute 데이터가 들어간다.
가운데는 null 을 체크하는 bit가 들어가게 되고 attr중 null인 부분을 bit 로 체크한다. 이 null bit를 가장 앞에 두는 방식도 있다고 한다.
Slotted-page structure
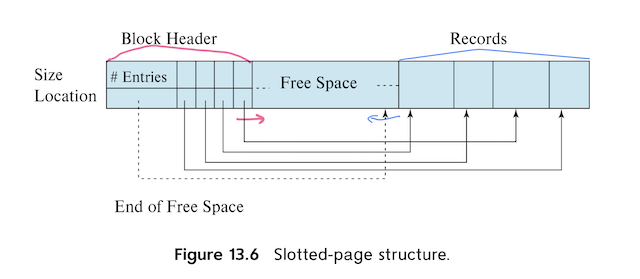
가변 길이 레코드가 어떻게 구성되었는지 살펴보았으니 그 레코드들을 블럭 내에 어떻게 저장하는지 설명한다. slotted-page structure는 흔히 사용되는 방법이다. 각 블록 시작지점에 다음과 같은 정보를 담아준다.
- 헤더에 있는 레코드 엔트리 수 (현재 블록 내에 레코드가 몇 개 있는지)
- 블록에서 free space의 끝이 어디인지 (그래야 거기서부터 새로 insert된 것을 채움)
- 각 레코드의 위치와 크기를 포함하고 있는 엔트리 배열 (각 레코드를 짚어낼 수 있어야하기 때문)
가변길이 레코드는 블럭내에서 freespace를 비워두고 헤더와 레코드를 채우게 되는데, 문제는 삭제시에 발생한다. 레코드들 중에 중간에 삭제되는게 생기면 해당 부분을 비워두지 않고 삭제된 부분에서 freespace 사이에 있는 레코드들을 옮겨줘야하는데 여기서 발생하는 cost가 상당히 높다고 한다. 따라서 아무리 가변길이의 레코드에 적합할지라도 삭제가 빈번하게 발생하면 이 부분을 고려해야한다.
13.2.3 Storing Large Objects
이미지, 오디오와 같은 큰 사이즈의 객체를 저장하는 방법을 설명한다.
대부분의 관계형 데이터베이스는 내부적으로 한 레코드의 크기가 블록 크기를 넘지 않도록 제한한다.따라서 데이터베이스는 Large Object들은 다른 레코들과는 달리 별도로 저장한 다음 포인터를 레코드에 저장한다.
두 가지 선택지가 있는데, 파일로서 파일시스템에 저장하여 관리하는 방식과 데이터베이스가 저장하고 관리하는 파일 구성으로 저장할 수 있다.
첫 번째 방식은 파일 그대로 파일시스템에 저장해두고 db에서는 이를 인지하고 포인터로 가리키는 것 같고, 후자는 DBMS에서 사용하는 B+트리로 구성하여 DBMS 내에 저장하는 방식 같다.
후자의 경우 B+트리로 파일을 구성해서 저장할 수 있다. 이는 효과적으로 파일의 특정 부분에 access, insert, delete할 수 있게 한다. 단점은 매우 큰 사이즈로 저장하는 부분에서 성능 이슈가 발생할 수 있다. (얘를 B+로 쪼개서 만들어야하기 때문인가 싶다)
또 다른 문제는 실제 기업에서 사용하는 디비는 주기적으로 dump, 백업 복사본을 만드는데 그럼 덤프의 크기도 매우 증가할 수 있다.
(여기서 드는 생각은, B+로 구성하기 위한 space overhead가 발생하는데 저장하는 데이터 size도 크다보니 이로 인해 발생한 문제일 수 있을 것 같다.)
그래서 동영상 데이터와 같은 매우 큰 객체는 데이터 외부에 파일시스템을 이용한다고 한다. (이미지도 부분적으로 access, insert, delete할 일이 없기에 파일시스템을 이용하지 않을까 싶다.) 이 때 발생할 수 있는 문제점은 데이터베이스 authorization controls 의 범위 밖으로 벗어난다는 것 이다. db 상에서는 해당 파일을 가리키는 pointer가 존재하는데 실제로는 해당 파일이 삭제되는 현상이 발생할 수 있다. 몇몇 데이터 베이스, 예를 들어 오라클은 이러한 문제를 방지하고자 데이터베이스와 파일시스템 간에 integration을 지원한다고 한다.
Organization of Records in Files
레코드가 내부적으로 어떻게 저장 되는지 살펴봤다면, 여기서는 어떻게 파일 안에 레코드들을 저장하는지를 다룬다.
-
Heap file organization
a record may be stored anywhre in the file. 레코드들 간에 순서 없이 비어있는 공간에 저장한다.
레코드들이 insert될 때, 파일의 마지막 부분에 insert를 해주면 되지만, 삭제되는 레코드들이 발생하고 그 공간에도 insert 해주기 위해서 free영역을 잘 관리해주어야한다. -
Sequential File Organization
A sequential file is designed for efficient processing of records in sorted order based on some search key.
레코드들을 키값 기준으로 포인터로 묶어놓는데,가능한 실제 레코드들도 순서를 보장하게끔 저장한다.그러나 레코드들이 포인터가 아닌 물리적으로 저장 자체를 순서를 보장하기는 어렵다. delete, insert가 발생할 때 cost가 높기 때문.
키 순으로 저장하고자 할 때, 순서상 인접 레코드가 같은 블록 내에 빈 자리가 있다면 거기 넣지만 그게 아닐 경우에는 다른 블럭에 넣는다. 어느 블럭에 넣든 포인터로 연결하는건 동일하다.
레코드가 삭제가 되지 않더라도, insert만으로도 실제 record의 정렬순서가 섞이게 된다. insert가 키값기준으로 뒤에 추가만 되는게 아니라 중간 중간 값이 들어온다면 실제 물리적으로는 뒤에 저장되지만 포인터로 가운데로 엮어준다.
그럼 실제 키값 정렬이랑 레코드의 물리적 저장순서가 뒤섞이게 되니 system이 low 할 때 reorganize해주는 것이 좋다. 헌데, B+tree file organization 은 이런 expensive한 reorganization 이 필요가 없다. 14.4.1 에 나옴. -
Multitable Clustering File
Most relational database systems store each relation in a separate file, or a separate set of files. However, in some cases it can be useful to store records of more than one relation in a single block.select department_name, building, budget, ID, name, salary from department natural join instructor위와 같은 쿼리문이 있을 때, 대부분 department, instructor는 별개의 파일셋에 저장되어 있겟지만 두 relation을 한 블록 내에 함께 저장함으로서 join 쿼리문의 효율을 높일 수 있다. mysql을 쓰면서 적용시켜볼 테이블이 하나 생각났는데 mysql - django ORM으로는 지원하지 않는 것 같다. Oracle 은 지원한다고 함.
13.3.4 Partitioning
attribute value 값을 기준으로 table을 분할함. 예를 들어, 데이터를 년도별로 구분하여 분할하는 것이 대표적. relation의 크기를 줄일 수 있어서 해당 relation free space를 찾는 cost도 줄일 수 있음. 또한 년도 별로 예전 데이터는 HDD, 최신 년도 데이터는 SDD 에 저장할 수도 있음
책에는 없지만 각 file oragnization 의 cost를 비교해놓은 글 : https://wkdtjsgur100.github.io/db-summary/
- 본 문서에서 틀린 부분이 있다면 댓글 주시면 감사합니다. (_ _)
