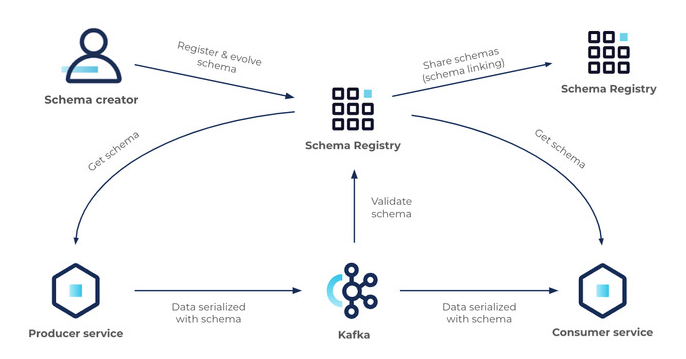
Schema 란?
The structured definition or blueprint used to describe the format and structure event messages
Schemas are used to validate the structure of data in event messages and ensures that producers and consumers are sending
and receiving data in the same format.스키마란 이벤트 메세지의 포멧과 구조를 정의한 것 이다. 데이터를 생산하는 쪽과 해당 데이터를 소비하는 양 측이 같은 데이터 포멧으로 데이터를 사용할 수 있게 한다. 사용하려는 데이터의 구조가 올바른 형식인지 체크하는 기능 또한 수행한다.
스키마는 데이터를 생산하는 쪽과 소비하는 양 측간에 계약이라고도 볼 수 있다.
왜 필요한가?
마이크로 서비스 환경에서 서비스(서버) 간 커뮤니케이션을 위해 가장 먼저 떠오르는건 Http API 통신이다. 허나 Http API로 서비스간에 통신을 하면 몇몇 단점이 존재한다.
다음 예시는 보험료 관련 마이크로서비스 환경에서 유저의 프로필을 관리하는 서비스와 보험료 책정을 담당하는 서버간 예시를 보여준다.

유저가 ui에서 프로필을 변경 시 Profile 서비스에서 이를 저장 후 Quote 서버에 이를 전달한다. Quote 서버 에서는 변경된 profile로 Quote 보험료를 산정한다.
여기서 어떤 문제가 있을까??
Profile service는 보험료 산정을 담당하는 서버임에도 불구하고 보험료 산정에 책임을 갖게 된다. Profile 서버에서 Quote 서버에 요청을 보내주지 않으면 해당 보험료 산정이 되지 않기 때문인다.
Profile 서비스에서는 보험료 산정을 위해서 Quote 서비스가 정상적으로 잘 동작하고 있는지 주기적으로 health check를 해줘야 할 것이고, Quote 서비스에서 정상적으로 요청을 처리하지 못한다면 해당 시간동안 변경된 프로필을 저장해두었다가, 보험료 정산을 위해서 추후 다시 요청을 보내줘야하는 등등의.. 작업이 필요하다.
Profile 을 활용하여 별개의 서비스들이 생겨나고, 해당 서비스들이 Profile을 필요로 한다면 더더욱 서비스간 의존성과 복잡성을 올라가게 된다.
Event Streaming Patterns
서비스간 API를 직접적으로 호출하는 것이 아닌, 약속된 schema를 기반으로 event straming 방식으로 동작하면 위에서 언급했던 문제로 부터 자유로워진다. Profile 서비스에서 Profile 관련 변경 사항이 있을 때, 해당 변경사항을 Publish 하는 것만 보장하면 된다.
Publish 된 데이터를 필요한 다른 서비스들에서 Subscribe 하여 각 팀 및 서비스 간에 의존도와 책임을 분리할 수 있다.
Schema Update(Evlove)
subject
subject 란?
schema는 변경 시 version과 ID가 할당되는데 이 subject는 schema의 version, ID를 포괄하며 해당 스키마를 식별하는 값이다.
subject name is unique identifier for schema. a reference to retrieve it from the storeSubject name Strategies
subject 명을 정하는 법. 이 중에서 택하는 것이다. 개발자 맘대로 정할 수 없다.
- TopicNameStartegy (default)
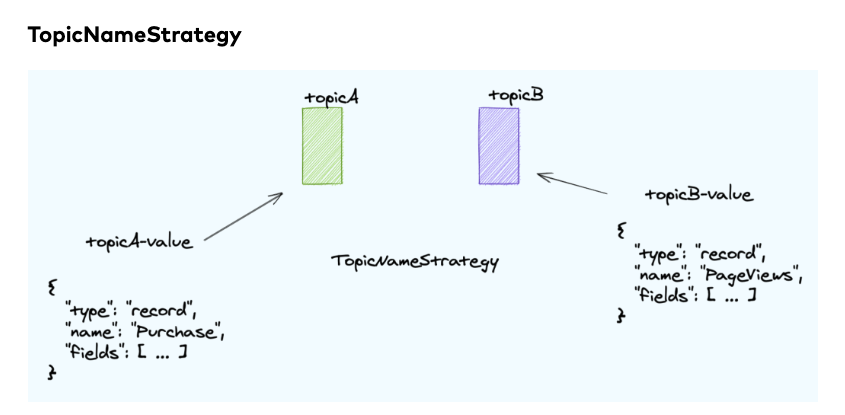
해당 토픽명 뒤에 + -value를 사용한다.(default) -key를 붙이는 것도 있는데 이건 나중에 알아보도록 한다.
effectively limits the topic to one record type.
Since all records in type in the topic must adhere to the same schema. 하나의 토픽에 하나의 record type schema 가 매핑되는 방식이다.
-
RecordNameStrategy
하나의 토픽에 여러 record type schema를 사용할 수 있는 방식 -
TopicRecordNameStrategy
<topic-name>-<fully qualified record anme>으로 위 두가지를 혼합하여 사용하는 방식
Schema scoped to the topic level
Schema Compatibility
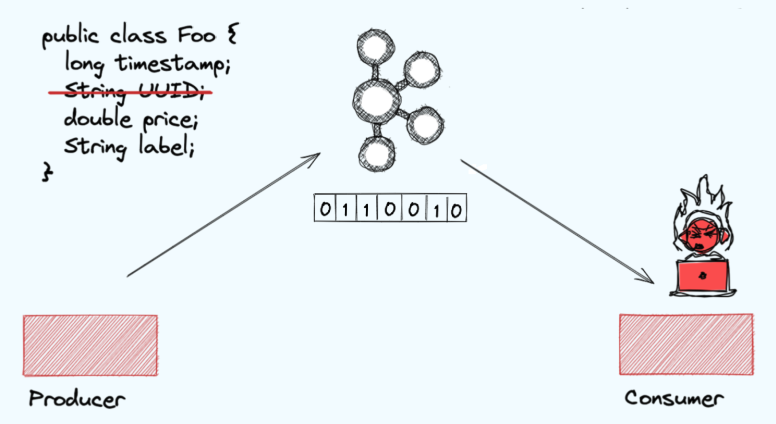
카프카에서 Schema는 Schema Registry에 관리된다. Schema Registry에서 호환성 체크를 하게 되며 호환성 규칙을 지키지 않으면 새로운 스키마 등록, 변경이 불가능하다.
호환성 체크는 위에서 나온 subject 기반으로 이뤄진다.
호환성이 지켜져야 하는 이유:
위 예를 간단히 보자면, data를 produce 하는 쪽에서 특정 필드 값을 삭제한다면 해당 data를 consume하는 쪽에서는 해당 데이터가 없어서 장애가 발생할 것 이다.
schema는 produce 하는 쪽과 consume하는 양 측간에 계약이지만, 변경은 가능해야한다. 양 측 데이터가 실시간으로 공유되는 상황에서, 호환성은 서로 변경 가능한 구조 내에서 안전하게 변경하게 하는 역할을 한다.
Schema Compatibility Modes
- Backward (default)
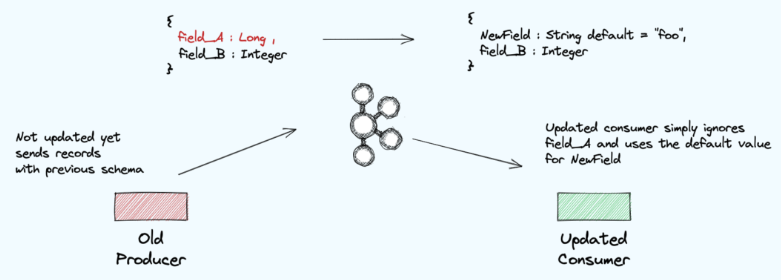
Schema evolve 시 Consumer 쪽을 먼저 update 한다. 아직 produce 하는 쪽에서는 이전 버전의 데이터를 produce 하고 있기에 변경 전 버전과 consumer에서 update 한 두 버전의 data를 읽을 수 있다.
필드를 삭제할 수 있지만 추가하는건 default 값이 있어야한다. 먼저 produce 쪽에서 변경할 때 필드값을 삭제하면, 읽는 쪽에서는 이 값이 없다고 처리하면 된다. 헌데 추가하는건 default값이 없는 경우 consume 하는 쪽에서는 해당 값을 handling 할 수 없기 때문이다.
같은 원리로 Backword에서는 default 설정되어 있는걸 필수값으로 변경할 수 없다.
- Forward
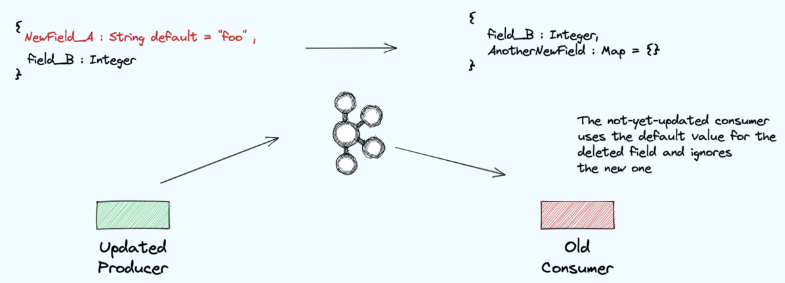
Backword의 반대. Produce 하는 쪽에서 스키마를 먼저 변경한다. 호환성이 동작방식의 포인트는 default 다. 어느쪽에서 먼저 변경하여 특정 필드 값을 생성, 삭제하건 늦게 반영되는 쪽에서는 해당 변경 값을 default로 처리한다.
Consume하는 쪽에서 먼저 값을 변경 할 경우 default 없이도 값을 추가할 수 있다. 변경 후 Produce 하는 쪽에서 어차피 값을 보내고 있지 않기 때문이다. 헌데 default가 설정되어 있지 않는 field값을 삭제할 수 없다. 삭제한다 한들 produce하는 쪽에서는 계속 해당 데이터를 보내고 있기 때문이다.
default필드는 필수값으로 변경할 수 있다.
- Full compatibility
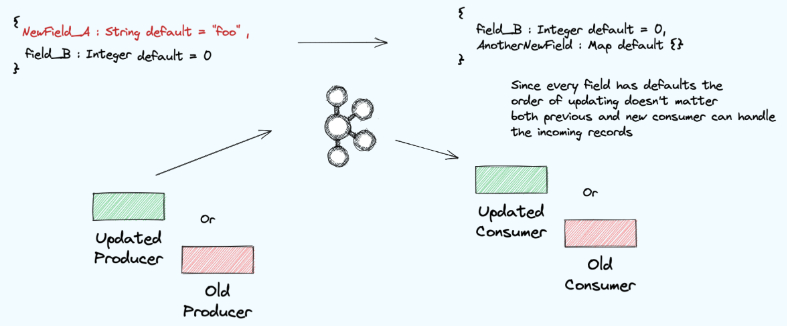
양쪽 어느 곳부터 변경이 가능한 대신에 모든 필드가 optional default 여야한다.
참고자료
https://www.confluent.io/blog/schemas-contracts-compatibility/
{kind=link}
