Two Phase commit 이란? (2PC)
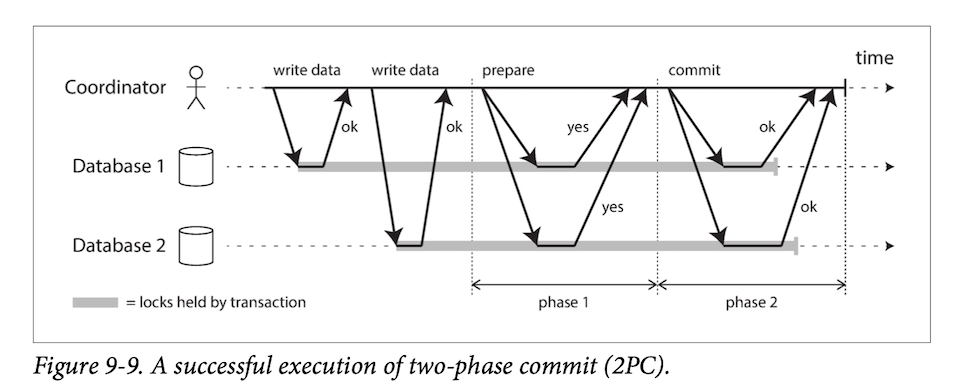
Two-phase commit is an algorithm for achieving atomic transaction commit across multiple nodes—i.e., to ensure that either all nodes commit or all nodes abort.
Two phase commit 은 분산되어 있는 DB들 간에 atomic한 transaction commit 처리를 위해 사용되는 알고리즘이다.
단일 DB에 transaction 처리의 경우에는 DBMS에 구현되어 있는 방식으로 처리가 되겠지만, 복수의 DB에 같은 transaction 처리를 실행 할 경우에, 어떻게 atomic한 처리를 할 수 있을까?
간단하게 얘기하면, 위의 그림대로 transaction을 각 db에 실행되도록 한다. 해당 transaction이 read, write, lock, unlock등의 operation을 수행할 것이고, 최종적으로 이를 commit 할지 말지를 Coordinator가 결정하도록 한다.
Coordinator가 각 DB에 해당 transaction이 문제 없이 commit이 가능한 상태인지 확인하고(각 DB는 해당 transaction을 commit 만 남겨놓고 수행했으므로), 모든 DB로 부터 성공응답을 받게 되면 Coordinatior 가 commit 처리하도록 DB에 요청하고, 어느 하나의 DB라도 commit 할 수 없는 상태이면, 모든 db에서 rollback되도록 한다.
즉, 복수의 각 db에 해당 transaction을 수행하고, 모든 db에서 성공적으로 실행되었는지 체크하는 phase1, 이를 최종적으로 적용되게 하는 phase2. Two Phase Commit이라 할 수 있다.
-
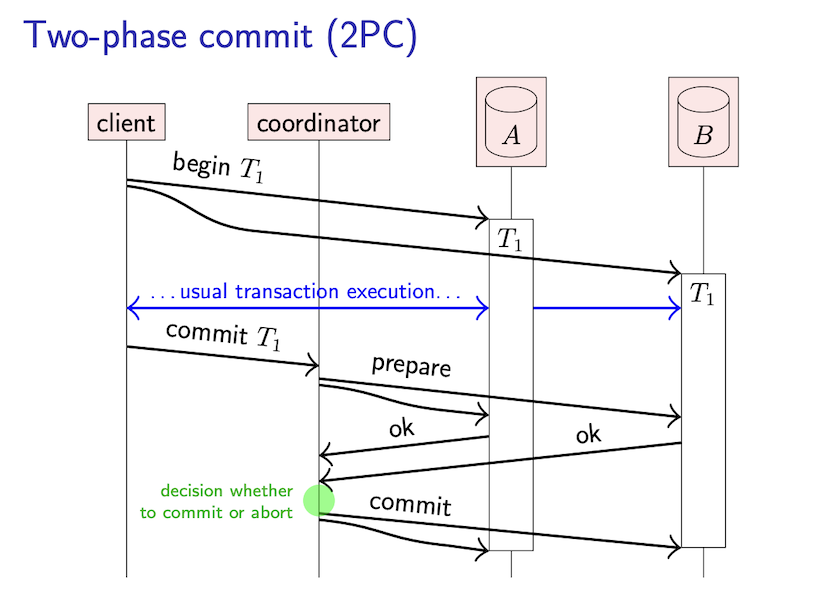
client가 각 DB에 transaction을 수행할 때, 해당 transaction에 고유한 unique ID를 coordinator로부터 발급받는다.
-
client 는 각 db에 transaction이 수행되도록 한다.
-
client 는 coordinator에게 해당 transaction이 commit되도록 요청한다.
-
coordinator는 해당 transaction이 commit 가능한 상태인지 각 db에 체크함
-
각 db는 해당 transaction을 disk에 update하고 lock을 hold하고 있는 상태에서 integraity constraint 체크등을 하고 해당 prepare request에 응답함
-
모든 db가 ok 시 commit 되도록 하며 하나의 db라도 commit이 불가능하거나 응답이 없으면 전부 abort되도록 함
주의해야할 부분
여기서 발생할 수 있는 문제는, 해당 transaction의 commit, abort 여부를 coordinator가 혼자 담당하는데 이 coordinator에 장애가 발생하거나 failure되면 어떻게 될까?
해당 transaction에 대한 commit/abort 여부를 disk에 안전하게 write해두더라도, 각 db 에 commit/abort 응답을 주지 않는다면 각 db입장에서는 lock을 걸어둔 상태에서 coordinator가 정상동작할 때 까지 대기하여하는 상황이 발생한다.
이런 상황을 피하기 위해 consensus algorithm, total order broadcast protocol 이 사용된다. 디테일이나 정확하게 파악하고 있지 않지만, 각 db들이 coordinator에게 commit 가능 여부를 보내는 것이 아니라 각 db들 간에 이 정보를 주고 받는 것 이다.
A, B, C 각 db가 특정 transaction 의 commit 가능 여부를 주고 받는다. 헌데 한가지 유념해야할 부분은 이 경우에는 race condition 이 발생할 수 있다. A는 B, C에게 commit이 가능하다고 전달하였지만 network timeout으로 인해 B는 전달받지 못하면 B 입장에서는 Abort되어야한다고 판단. C는 A의 요청에 정상적으로 commit 이 가능하다고 전달 받은 경우가 발생한다.
따라서 A->B->C 순으로 order을 정해서 broadcast하는 방법 등이 있는 것 같다. 이 order broadcast부분은 자세히 알아본게 아니기에 추후에 다뤄봐야겠다.
언제 사용하게 되나?
2PC은 단일 db에 비해서 (Mysql)로 비교하면 10배가량의 performance 차이가 난다고 한다. 해당 commit의 가능 여부를 network io를 이용하여 판단하기에 io로 인한 퍼포먼스 저하라고 생각하였으나 crash recovery를 위해서 추가적인 fsync()도 퍼포먼스 저하중 하나의 원인이라고 한다.
그럼에도 불구하고 언제 사용하나?
-
two(or more) databases from diffrent vendors
서버에서 작업하다보면 특정 처리의 결과를 두개의 db에다 관련 데이터를 write하는 경우가 발생한다. 허나 2PC의 경우 performance나 구현에 들어가는 리소스를 생각했을 때, 상황에 따라서 uow 디자인 패턴을 이용하는 경우도 있다. -
Exactly-once message processing
메세지큐와 해당 메세지를 처리하는 분산된 node에서 둘 다 제대로 처리되었다는 commit이 필요하다. 메세지 큐에서는 해당 메세지를 가져갔다고 commit이 되었는데 메세지를 처리하는 쪽에서는 받아서 처리되었다는 commit이 되지 않을 경우에는 메세지가 분실된다.
따라서 둘 다 처리되었다고 commit 하거나, 둘 다 처리되지 않게 처리하여 메세지가 다시 처리될 수 있도록 해야한다.
헌데 이 메세지 처리결과가 외부 회사에서 진행이 되는 경우, 외부 회사와 2PC를 구현하는 것은 운영 cost가 높기에 현실적으로 구현이 불가능할 수 있다. 이럴 경우 Exactly-once 가 아닌 at-least-most 방식으로 처리를 하게 되며 이 경우 메세지 중복현상이 발생한다.
이걸로 끝일까?
복수의 각 db에 transaction을 실행 시에 전부 commit 이 되거나 abort처리 되는 것을 2PC로 진행하는 방법을 알아보았다.
허나 특정 하나의 db에서 transaction에서 read, write skew나 phantom 현상이 발생했을 경우 각 db에 다른 데이터가 심어지게 되는데 이는 어떻게 해결할 수 있을까? 이건 추후에 알아봐야겠다.
