회사에서 다른 분이 Django 서버에 흔히들 많이 사용하는 cachetools(
https://github.com/tkem/cachetools/ )로 로컬캐싱을 넣었다.
한 이틀 정도 지났을까. 에러가 점점 발생한다. 배포 직후에는 문제 없다가 한건, 두 건 Datadog에 에러가 찍히기 시작하더니 에러가 점점 더 발생한다. 발생 %가 계속 오르기 시작하더니 3%를 넘어갔다. 이 때 재배포를 하면 에러가 사라졌다가 하루 정도는 잠잠해지기에 재배포를 반복하고 있었다.
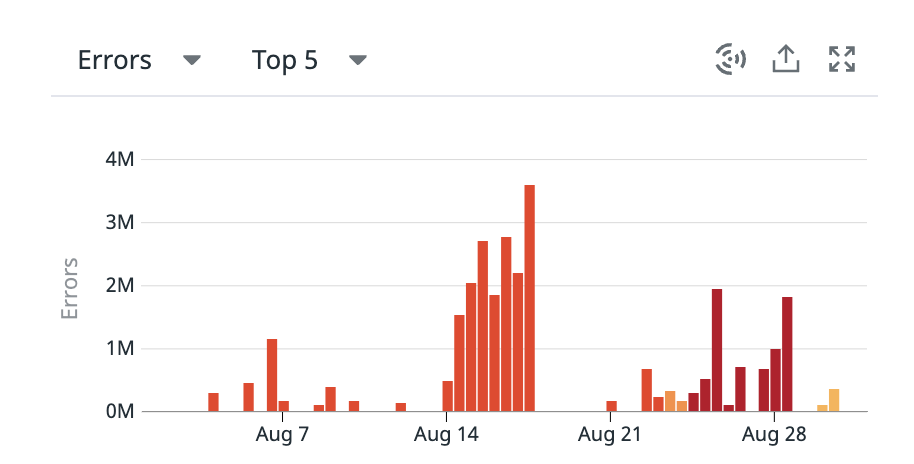
위 그림은 8월 한 달간의 error 발생 수를 보여준다. 한달 간 네 번 이상 배포하였는데 한달을 기준으로 표를 뽑았더니 수치가 더 작은 것은 나오질 않는다. 큼.. 에러 건 수가 3M이 넘어가는 것도 있는데 전체 트래픽은 100M이 찍히고 있어서 퍼센트로는 3% 정도 발생했다. 재배포하여 또 잠잠해지긴 했지만 가만 두면 지속적으로 증가한다.
재배포를 하면 에러가 발생하지 않다가, 한 두건씩 점점 발생하면서 계속 에러가 증가하는 이 현상은 왜 발생한걸까?
우선 error trace를 들여다보았다. 지금은 한 달이 지나서 datadog에서 error trace가 조회가 안된다 ㅜㅜ 그때 그때 작성해 둘껄..
주된 에러 trace에서 보이는 에러는
self.expire(key) , del self.dict[key] 로 주로 삭제와 관련된 에러였다.
처음 이 에러를 보고 드는 궁금점은 두 가지.
Q1. 왜 삭제하면서 이런 error가 발생하는걸까?
Q2. 왜 재배포만 하면 정상으로 돌아왔다가 한 두건씩 에러가발생하면서 점점 더 많은 에러, 빈도 수가 커지는걸까?
A1.
답은 특정 키로 저장한 부분들 다수의 스레드가 동시에 삭제하다보니 발생했다. (... 너무 조촐한가..?)
A2.
재밌는 부분은 여기다. A1에서 발생한 동시성으로 인한 문제가 왜 재배포 후에는 당분간 발생하지 않는 것이고, 왜 일정 시점이 지난 시점부터는 에러가 점점더 많이 발생하는 걸까?
결론은. A1에서 얘기하였던 동시에 삭제하는 이슈 외에도 캐시 사이즈도 (에러에는 찍히지 않지만) 동시성 이슈가 발생하여 사이즈가 점점 줄어들고, 이로 인해 삭제에서 발생하는 동시성 이슈도 점점 증가한다.
우선 cachetools가 구현된 부분을 설명을 해야한다.
cachetools의 TTL cache는 해쉬테이블와 연결리스트로 구성되어 있다. 특정 함수의 return 값을 캐싱하기에 함수의 parameter를 해싱하여 키 값으로 저장 후, return 값은 연결리스트에다 해당 데이터를 저장해둔다.
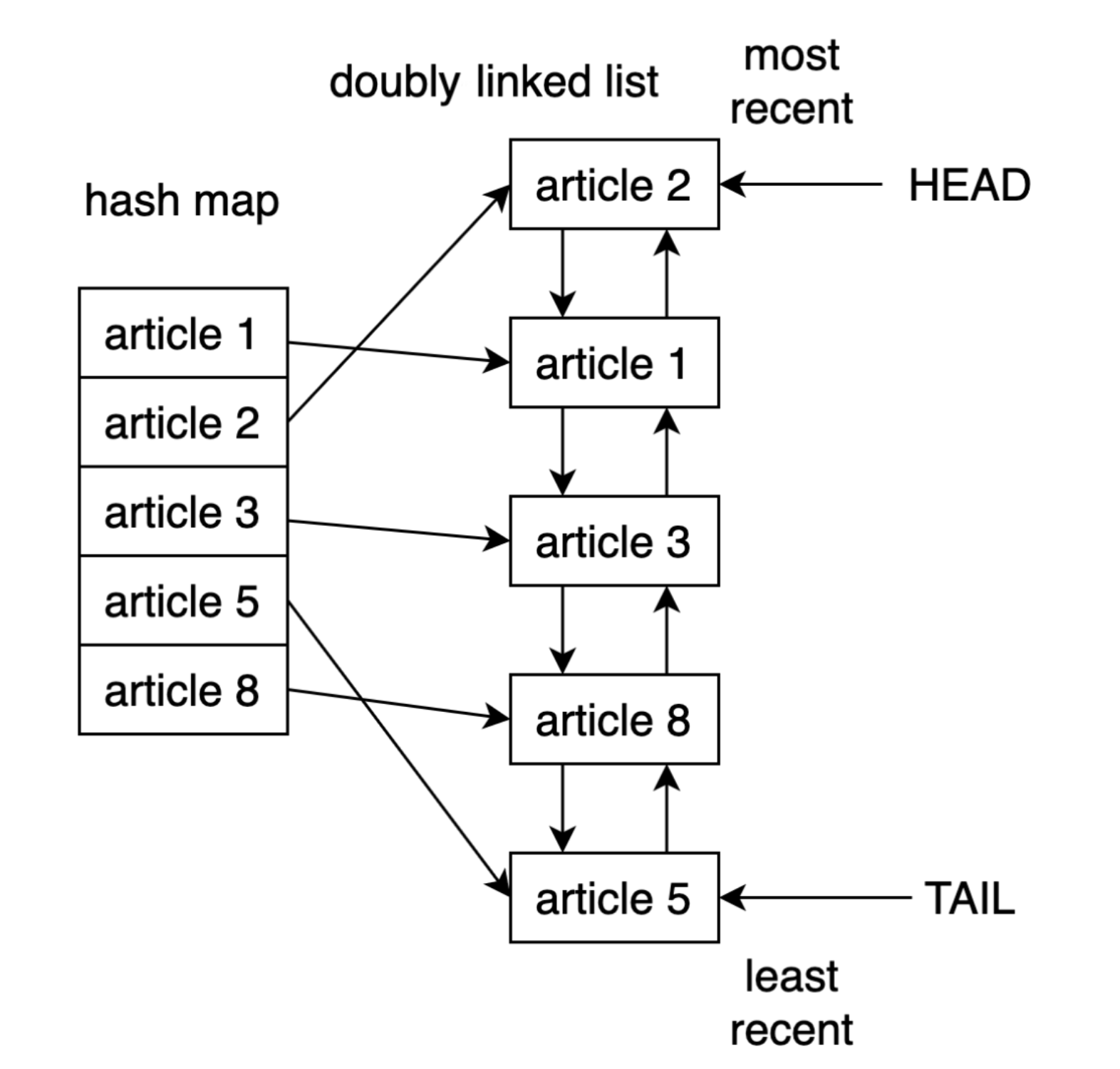
(이와 관련된 이미지를 찾으려고 구글링을 했더니 이전에 내가 작성한 글이 구글링 결과로 떳다.. ㄷㄷ python lru cache 코드 살펴보기)
위 코드 살펴보기 링크에도 작성을 해두었지만, cachetools의 경우 캐싱하는 아이템의 만료될 시간, 캐시 size를 인자로 넣어준다.
캐싱데이터를 삽입, 삭제하면서 이 cache size도 tracking을 하는데, (모니터링툴에서 에러로 찍히진 않지만) 동시성 문제가 발생한다. 데이터를 캐싱(set)할 때는 여유 캐싱 count가 줄어들고(-), 캐싱이 만료됨에 따라 삭제 시에는 다시 캐싱할 수 있는 count를 늘려주어야한다. (+)
cache가 만료될 때는 초단위로 만료가 되는데, 데이터를 캐싱(set) 할때는 초 단위가 아닌 cpu 실행에 따라 캐싱 된다. 즉 캐시 만료가 될 때 더 많은 동시성 이슈가 발생함.
삽입, 삭제 둘 다 동시성 이슈가 발생하지만 삭제에서 더 많은 동시성 문제가 발생하고, 이에 따라 시간이 지날 수록 캐싱할 수 있는 count수는 줄어든다. 이에 따라 캐싱에서 데이터가 set, del 되면서 동시성 이슈가 발생하는 빈도수는 특정 임계점을 지나기 시작하면서 점점 크게 증가하는 것 이다.
cachetool에서는 예제로 제공하는 코드들에서는 lock을 보여주고 있진 않고, 글들을 보면 굳이 lock 을 넣어주진 않은 상태로도 많이들 사용하고 있는 것 같다. PR에서 lock 을 걸어주면서 문제는 해결되었다!
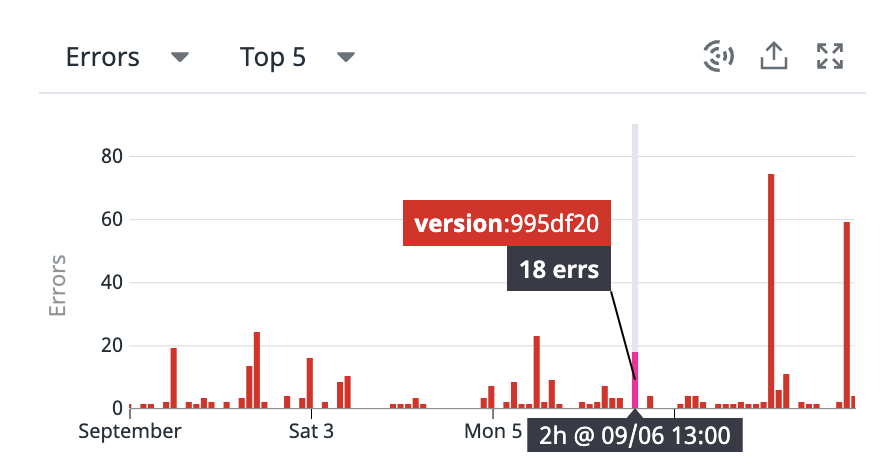
밀리언 단위로 뜨던 에러는 해결되었고 지금 찍히는 에러는 다른에러다!
