sw정글에서 malloc lab 으로 malloc 함수를 구현하면서
공부했던 CSAPP 9-9장. 동적 메모리 할당에 대한 부분을 복습하고 이를 정리하고자 한다.
왜 동적 메모리 할당을 하는 것인가?
Programs do not know the sizes of certain data structures until the program actually runs.
프로그램은 프로그램이 실행되고 나서야 어떤 data 구조, data size를 알게 되는데,
run time 이전에 알 수 없으므로 미리 그 크기를 정해두는데 어려움이 있다. 실제 들어오게 되는 size보다 작다면 data를 받을 수 없을 것이고, 너무 크게 size를 잡아둔다면 그 차이만큼 메모리 낭비가 발생할 것 이다.
그래서 프로그램이 run, 실행되는 타임에 필요한 만큼 할당하여 사용되도록 하는 것이다.
동적 메모리 할당기
동적 메모리 할당기는 기본적으로 두 가지로 나눠 볼 수 있다.
누가(which entity) 할당된 영역을 free 시켜주냐에 따라 explict(명시적), implicit(묵시적) 할당기로 나눠볼 수 있다.
Explicit Allocator
- malloc package in C
c에서는 malloc 함수로 할당하고 free를 할때는 free() 함수를 이용한다.
Implicit Allocator
할당된 블럭, 부분이 더 이상 필요로 하지 않을 때 이를 프로그래머가 명시적으로 free()를 해주는 것이 아니라
allocator가 필요하지 않은 부분을 인지하고 free 시켜준다. 대표적인 implicit allocator로는 garbage collector 가 있다.
garbage collector 에 관해서는 공부한 부분이 조금밖에 되지 않음에도 불구하고.. 다른 글로 따로 작성해보겠다.
할당기의 요구사항과 목표
요구사항(requirements)
-
Handling arbitrary request sequences.
언제 할당 및 free request 가 요청될 지 정해진 바가 없시 임의의 순서로 들어오게 된다.
사실 이 부분은 내가 뭘 놓친건지 명확하게 와닿진 않는다. free 나 할당 요청이 언제 들어올지는 모르지만 이를 대비해서 무언가를 따로 처리를 해주거나 한게 없긴한데 너무도 당연하면서도 중요한 포인트여서 책에서 기술되어있는건지 내가 뭘 놓친건가..? -
Making immediate responses to requests
할당이나 free 요청이 들어왔을 때 이 요청들의 순서를 임의로 변경한다던가, buffer에 request를 넣는 짓은 하지말라고 한다. (성능 향상을 위해서) -
Using only the heap
동적 할당 할 때는 힙 영역만 사용할 것! -
Aligning blocks
어떤 데이터타입의 data object들도 저장 할 수 있게 하라.
이것도 사실 와닿지가 않긴한다.. 이를 위해 뭔가 처리해준 부분이 없는데 나중에 다른 부분을 공부하다가 다시 와서보면 알려나 싶어서 남겨둔다. -
Not modifying allocated blocks(할당된 블록을 수정하지 않기)
블록이 할당 되면 수정하거나 이동하지 않도록. 할당한 블록을 압축하거나 하는 기법들도 허용하지 않음.
할당기의 목표
- 목표 1. Maximizing throughput
- 목표 2. Maximizing memory utilization
처리량 (시간단위 당 얼마나 많은 할당, free 요청을 처리할 수 있는지) 와 이용률(메모리를 얼마나 꼼꼼하게 남는 부분 없이 잘 사용하는지)
재밌는 부분은 목표 1과 2를 적절한 지점에서 타협을 해야한다. 둘 다 취할 수는 없는 관계이기 때문이다.
예를 들어, 창고에 쌀주머니 혹은 포대의 사이즈가 다양한 사이즈별로 갖고 있다고 하자. 누군가 와서 쌀을 보관하고 싶다고
들고 온 10kg 의 쌀을 담을 주머니를 달라고 요청을 했다.
빠르게 요청을 응답하고자 주머니들을 찾아보다가 10kg 보다 큰 사이즈(예를 들어 15kg)를 발견했을 때, 더 찾아보면 10kg ~ 14kg 범위의 더 잘 맞는 주머니를 더 찾아볼 수도 있겠지만 빨리 요청한 사람의 요구를 들어주고자 15kg 짜리 사이즈 의 포대를 제공하기로 한다. 이런 식으로 일을 계속 처리하면 throughput, 처리량은 높아지겠지만 그만큼 주머니들의 빈 공간만큼씩 낭비될 수 있다.
그럼 이용률을 높이기 위해서는 10kg 주머니가 나올 때 까지 찾는 방법이 있을텐데 그럼 이용률은 높아질 수 있어도 그만큼 처리량은 떨어지는 관계에 놓이게 된다.
따라서 둘 사이에 적당한 선을 찾는 것이 중요하다고 한다.
그럼 이제 메모리가 할당 되는 것을 간단히 살펴보자.
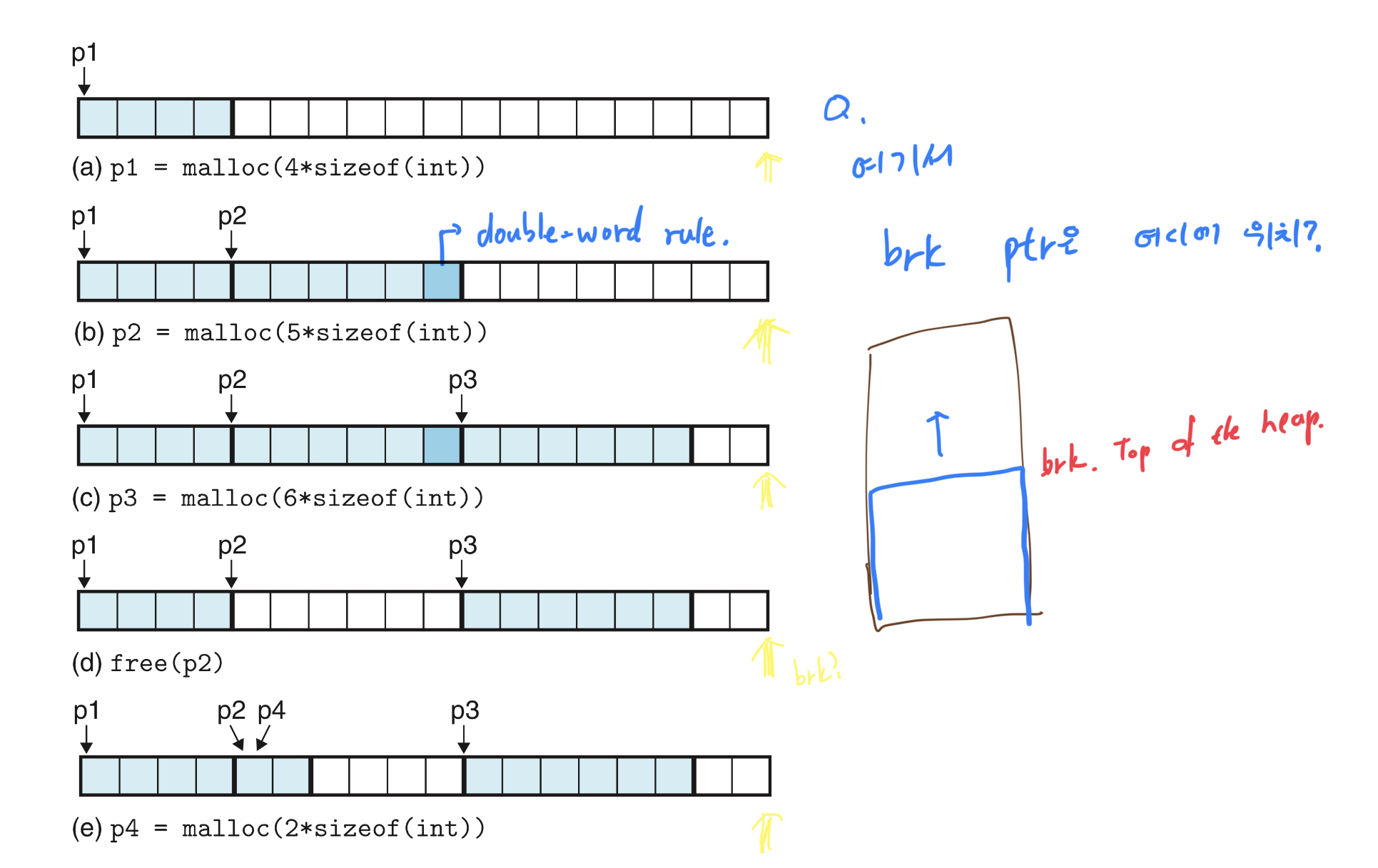
위의 네모 한 칸은 4byte, 1word 단위 이다.
메모리의 할당 범위는 2word 단위이기 때문에 8byte 보다 더 작은 사이즈의 할당을 요청 하더라도 2word(8byte) 단위로 할당하게 된다. (ex, 5 byte 를 할당을 요청해도 8 byte가 할당되며 3바이트는 놀게된다. 이를 내부단편화가 발생했다고 한다.)
오른쪽에 필기 부분은 위 그림을 보다가 궁금한 점을 적었던 것이다. 해당 그림의 영역들이 힙 영역일텐데
그럼 brk의 위치가 궁금했던 것 같다. 저 그림이 힙 영역의 일부이면 brk 가 생략된 걸 수 있지만
가장 오른쪽 네모까지가 힙에서 brk 값이 올라가고 있는 최상단이라면 brk는 저 위치가 맞다.
malloc lab에서 구현했던 것을 다시 들춰보자면, sbrk 함수가 실행되는 것을 보면,
int mm_init(void) // 메모리 처음 만들기
{
/*
* pdding hdr prev next ftr epilogue
* +------+------+------+------+------+-------+
* | 0 | 16/1 | NULL | NULL | 16/1 | 0/1 |
* +------+------+------+------+------+-------+
*
*/
if ((heap_listp = mem_sbrk(6 * WSIZE)) == (void *)-1) # 처음 초기화 시 최소 필요 영역만큼 brk 늘리며 할당함
return -1;
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(2 * DSIZE, 1));
PUT(heap_listp + (2 * WSIZE), NULL);
PUT(heap_listp + (3 * WSIZE), NULL);
PUT(heap_listp + (4 * WSIZE), PACK(2 * DSIZE, 1));
PUT(heap_listp + (5 * WSIZE), PACK(0, 1));
heap_listp += (2 * WSIZE);
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) //
return -1;
return 0;
}초기화 이후에 malloc 함수를 쓰면서 쓰이는 경우를 보자면,
void *mm_malloc(size_t size) // 메모리할당 malloc 함수
{
size_t asize;
size_t extendsize;
char *bp;
if (size == 0)
return NULL;
if (size <= DSIZE)
asize = 2 * DSIZE; // 2워드 이하 사이즈면 2워드로 할당됨
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); // 요청한 size를 word 단위로 변환함 짝수단위 할당은 place 나 extend_heap 에서 이루어짐
if ((bp = find_fit(asize)) != NULL) // 할당 할 수 있는 빈 영역을 찾음(find_fit)
{
place(bp, asize); // 찾게 되면 그 곳에 할당
return bp;
}
// 찾지 못했을 경우
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL) // sbrk 함수를 호출하여 brk를 2 word 단위로 늘려줌
return NULL;
place(bp, asize);
return bp;
}
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header / footer 인듯?*/
/* Coalesce if the previous block was free */
return coalesce(bp);
}implicit free list(묵시적 가용 리스트), explicit free List(명시적 가용 리스트)
이어서 implicit free list(묵시적 가용 리스트) 방식으로 위 그림을 보다 구체적으로 살펴보자.
explicit free List(명시적 가용 리스트) 는 사용할 수 있는 free 리스트를 따로 자료구조로 만들어 관리하는 것 이다.
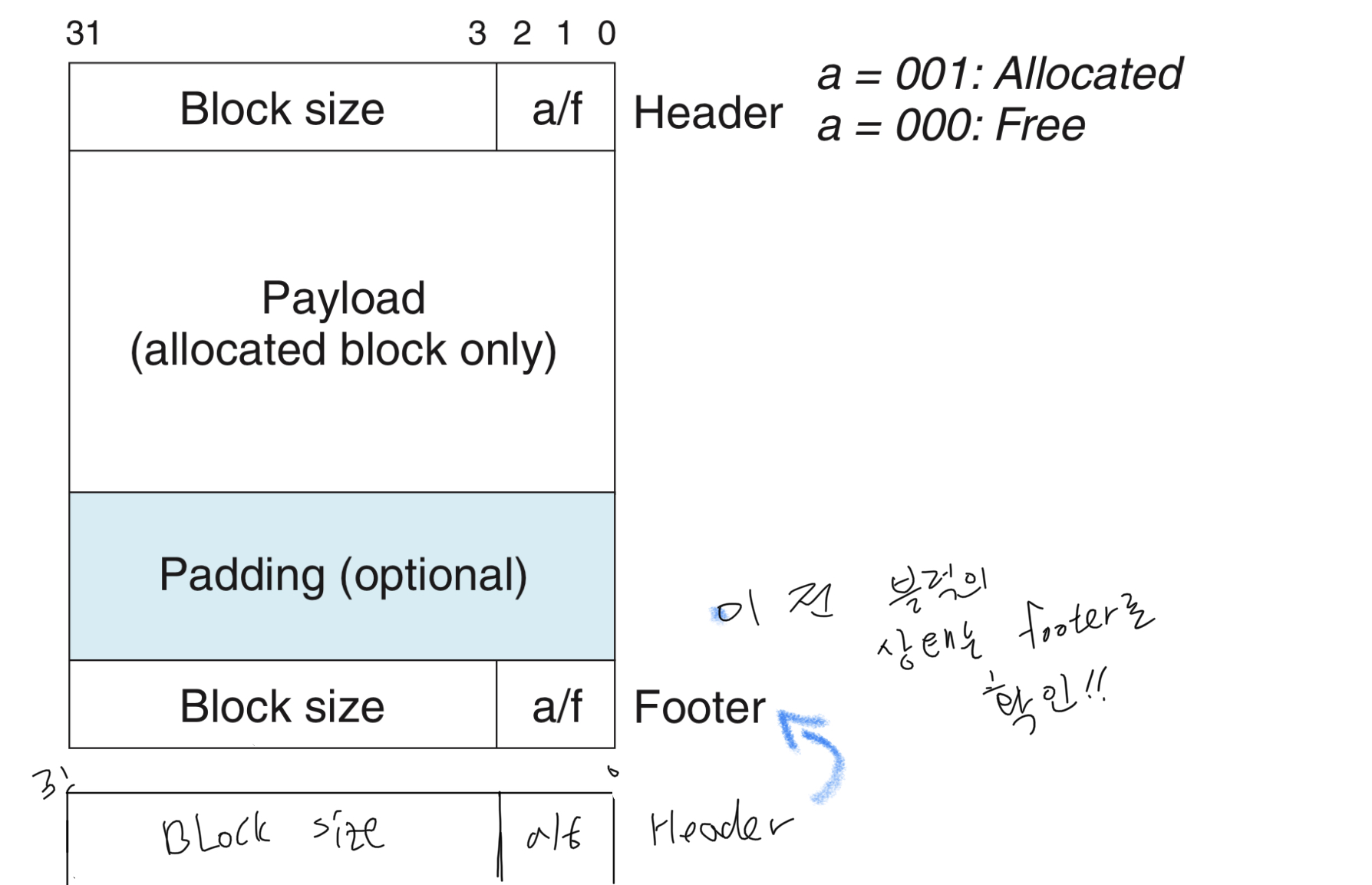
implicit free List 는 위 그림에서 할당되거나 free 상태인 블럭들에다 header 와 footer 라는 boundary 태그
의 값을 보고 해당 영역의 사이즈, 할당 여부를 확인한다.
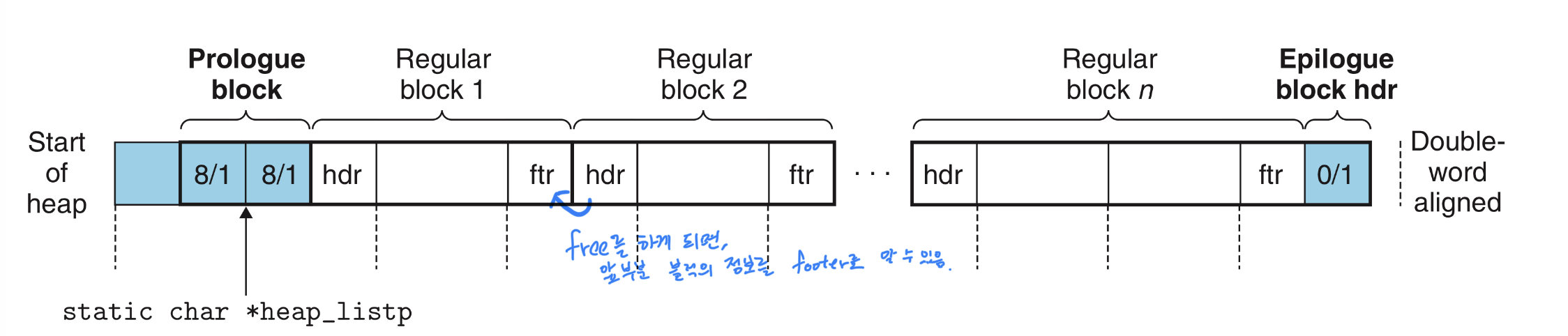
특정 영역이 free가 되었을 때는 그 다음에 위치한 영역이나 그 전에 영역이 free가 되어있는 상태인지를 확인해주고
이미 free가 되어있으면 해당 영역과 합쳐주게 되는데 (coalesce 라고 함)
다음 영역의 경우, 본인의 header에서 사이즈를 알고 있으니 그 다음 블럭의 header 위치를 쉽게 파악할 수 있지만
반대로 이전 블럭의 사이즈는 파악이 힘들다. 앞 블럭의 header 위치 파악이 어려우니, footer를 붙이게 되면 바로 직전 블럭은 footer가 위치하고 있을 것이고 footer를 통해 해당영역에 대한 정보를 파악할 수 있다.
그럼 명시적 가용 할당기는 어떻게 다를까?
지금 까지 본 묵시적 가용 할당기의 문제점은, 가용블럭을 찾는데 할당되어 있는 블럭들까지도 차례로 liner하게 탐색하게 된다.
그래서 따로 자료구조를 이용해서 free 블럭들만 모아놓고 관리를 하는 것이 명시적 가용 할당기의 개념이다.
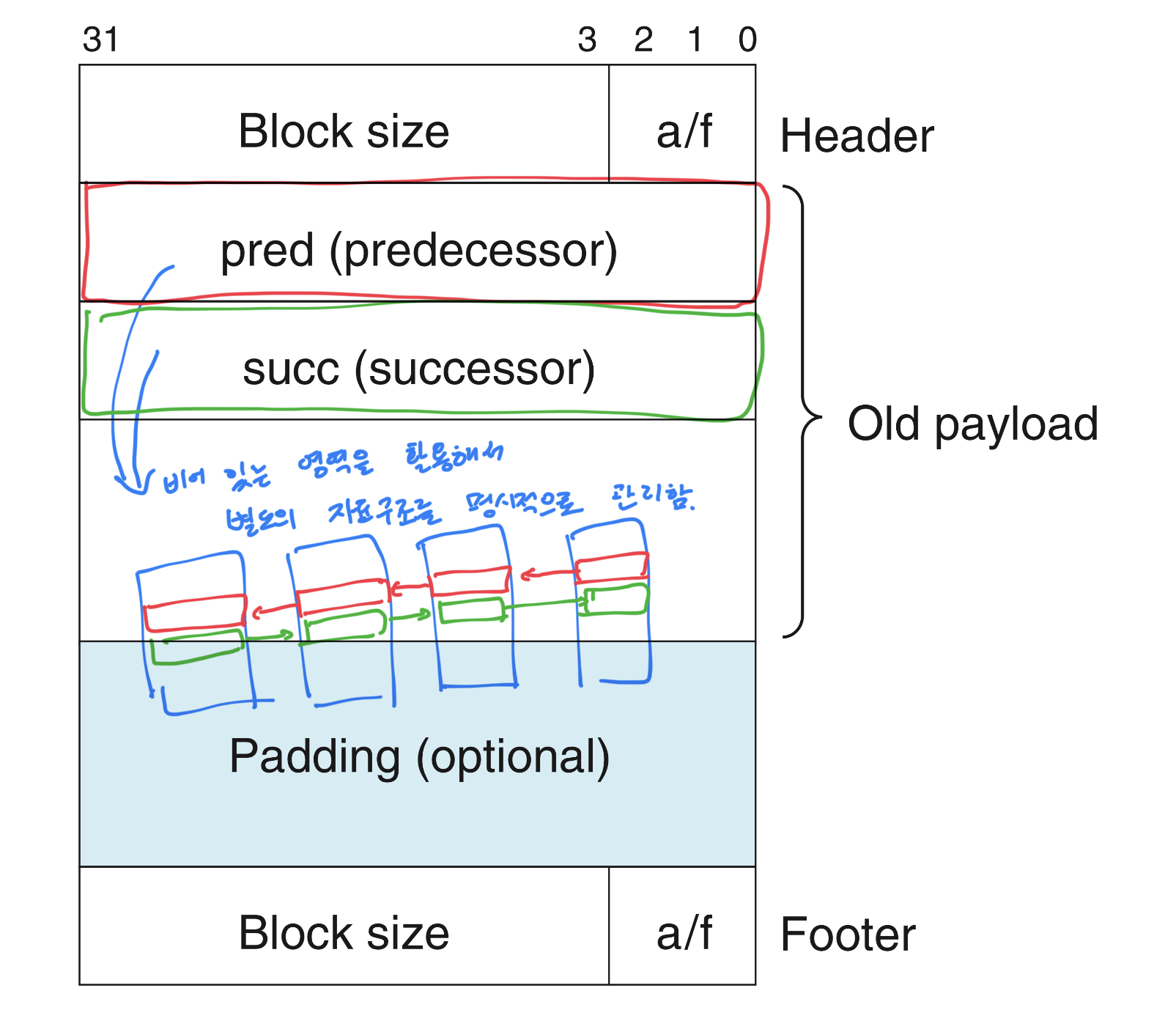
할당되어 있는 영역을 free하게 되었을 때 그 내부는 어차피 더이상 쓰이지 않으니,
거기에 특정 value, 여기서는 pred, succ 이전 이후 의 값을 이용하여 free 리스트들끼리 묶어서 관리하게 된다.
가장 직관적인 예는 위의 그림처럼 양방향 Linked List로 구성하여 free 영역들을 관리해주는 것 이다.
이제 할당을 위한 비어있는 블록을 찾을 때 해당 Linked 리스트에 가서 가용블럭을 가져올 수 있다.
그럼 할당된 블럭을 free를 해줄 때는 어떻게 할까?
free 를 해 줄 때는 해당 LinkedList의 가장 앞에 넣어주게 된다. 시간복잡도가 O(1)이기도 하고
Locality(지역성) 개념을 조금 넣어보자면, 가장 최근에 할당하고 free 한 사이즈 만큼 또 같은 사이즈를 할당할 확률이 높다. 그럼 해당 사이즈의 free 블럭이 LinkedList로 가장 앞 부분에 들어가있을 것이고
가장 앞부분부터 free block을 찾는 First fit 방식으로도 좋은 performance 가 나오게 된다.
그럼 linkedList 에서 가장 앞부분 부터 찾는 FirstFit 얘기가 나온 김에
First Fit, Next Fit, Best Fit 이란 개념도 조금 다뤄보겠다.
first fit, next fit, best fit
이름들은 꽤나 직관적인 듯 하다.
free 리스트들을 찾을 때 first fit은 처음부터 찾아보고, next fit은 이전에 free 리스트의 그 다음부터 찾을 것 인가.
best fit은 가장 잘 맞는걸 찾겠다! 라며 직관적이지만 best fit 의 경우 이름과는 다른 함정(?) 이 존재한다.
first fit
static void *find_fit(size_t asize)
{
/* First-fit search */
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) // heap_listp - 첫 부분부터 for문을 돌면서 그 다음 포인트로 이동하며 찾는다.
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL; /* No fit */
}first fit은 첫 부분부터 for문을 돌면서 그 다음 포인트로 이동하며 찾는다.
next fit
static void *next_fit(size_t asize)
{
void *bp;
// first fit 과는 달리 찾는 시작 지점이 last_listp 이다.
for (bp = last_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
// * (heap_listp - startpoint)------------- * (last_listp) -------------- * (end)
// 중간 지점에서부터 끝에서 위 반복문에서 찾지 못했다면 아래 반복문으로 first fit처럼 처음부터 중간시작점이었던 부분까지 찾으러 간다.
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0 && last_listp > bp; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL; /* No fit */
}
first fit과 next fit의 구현에 있어서는 큰 차이가 없다.
처음 찾는 시작 포인트가 처음(heap_list)이냐, 아니면 가장 최근 할당되었던(last_listp) 이냐에서 차이가 있고 해당 지점에서 마지막까지 찾지 못했다면,
next fit 도 결국 처음 포인트부터 찾아야 하는 경우가 발생한다.
Best fit
best fit의 경우 앞선 두 개와는 차이가 존재한다.
first, next fit 의 경우와 할당할 영역보다 큰 사이즈를 찾았을 경우 해당 영역에 필요한 만큼을 할당하고 남은 영역은 분리한다.
예를들어, 8byte 를 할당하려고 free list 들을 순회한다고 하자.
그러다 40 byte 사이즈를 찾은 경우, first/next fit은 해당 40byte에서 8byte를 할당하고, 32byte의 free 리스트로 분리시키는 반면에
best fit 의 경우는 8byte 보다 더 큰 free 블럭을 찾더라도 할당하지 않고 8byte 의 free리스트를 찾아 순회를 계속한다.
best fit까지는 시간상 구현하지 못해서 코드 첨부는 없다 ㅠ
그래서.. 뭐가 제일 좋아요?
세 방식을 비교하기 위해 각 장단점과 특징을 좀 더 생각해보자. 그러기 위해선 단편화 개념이 필요한데 짧고 간단하게 단편화(Fragment) 에 대해 알아보고 넘어가자.
내부 단편화
내부단편화란 실재로 payload(적재) 싣는 데이터의 크기보다 더 많은 영역을 할당할 때 발생한다. 앞서서도 살짝 설명하였듯이, 10바이트의 데이터를 할당하고 싶어도 할당기는 2word(8바이트) 단위로 할당하기에 16바이트를 할당하게 될 것이고 6바이트만큼 내부 단편화가 발생한다.
외부 단편화
외부 단편화란 free block들 중 할당하고자 하는 사이즈의 크기를 충족하는 free block이 없을 경우에 발생한다.
내부단편화의 경우 어느정도 예측이 가능하다. 이미 기술하였듯이, 내가 어떤 크기의 데이터를 할당하냐에 따라 얼마만큼의 내부단편화가 발생할지 예측 및 계산이 가능하다. 허나 외부단편화의 경우 언제, 어떤 크기의 외부단편화가 발생할 지 예측이 어렵기 때문에
보다 외부단편화 현상을 방지하고자 크기가 큰 가용블럭들을 보장하고자 한다고 한다. malloc 함수를 구현할 때도 해당 영역을 free()해줄 때는 반듯이 앞 뒤 메모리 영역을 확인하고 free 상태면 해당 영역을 합칠 수 있으면 바로 합칠 수 있도록 꼼꼼하게 coalesce(free 영역끼리 합치는 함수)를 해주었다.
본 문단에서부터는 내 생각인데, 내부단편화의 경우 내부단편화를 발생 시킨 특정 a라는 instruction의 관점에서 생각을 해보자면, a라는 instruction은 내부단편화로 인해 a 의 처리에 있어 그 속도에 문제가 생기지는 않겠지만 a라는 instruction을 수행함에 있어 외부단편화 현생이 발생한다면, 그만큼 크기의 가용블럭을 만들어주기 위해 sbrk 함수를 실행한다던가, mmap함수로 새로 할당 영역을 만들어 주는 등의 처리가 필요할텐데 그럼 a라는 instruction 처리에 소요되는 시간을 상당히 잡아먹을 듯 하다. 물론 내부단편화 현상이 축적되면 결국 이후 외부단편화 현상들도 발생하게 되어 내부 단편화, 외부 단편화가 별개의 문제는 아니지만 외부단편화 현상에 보다 신경쓸 수 밖에 없다.
그럼 다시 first, next, best fit을 살펴보자.
- first fit
first fit의 경우 블럭들의 앞 쪽에는 크기가 작은 블럭들을 계속 만들어내게 된다. 만든다기 보다 크기가 작은 블럭들이 할당 될 때마다 앞 부분부터 작은 블럭들을 할당하고 큰 블럭들도 first fit 방식에 의해 작은 블럭들로 분할, 세분화되기 때문에 큰 영역을 할당하고자 할 때는 다른 fit 방식 보다 시간이 더 소요된다. (큰 영역들은 뒤쪽에 배포될 것이기에)
cpu scheduling 방식에서 FIFO 방식에서 convoy effect가 아니면 FIFO 방식이 처리량에서 좋은 성능을 보여주었던 것 처럼, 큰 데이터, 큰 크기의 블럭들이 할당되지 않고 일관적으로 작은 영역들만 지속적으로 할당한다면 first fit 방식도 나쁘진 않을 것 같다.
- Next fit
Next fit 방식은 first Fit 방식에 비해 free 가용 블럭을 더 빠르게 찾는다. 매번 앞 부분부터 처음부터 순회하는 것이 아니라 이전에 할당했던 영역에 그 다음부터 찾게 되면 보다 필요한 할당영역을 찾는 경우의 수가 많다고 한다.
malloc 랩에서 테스트 케이스에서 first fit과 next fit 을 비교해보면,
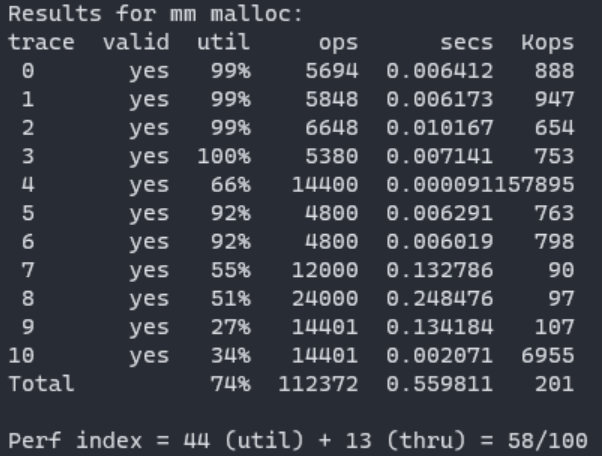
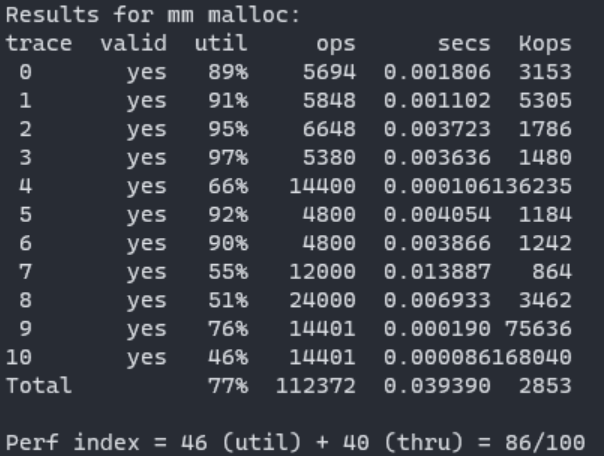
next fit 방식이 first fit 방식보다 처리량이 개선되는걸 확인할 수 있다.
- Best fit
Best fit 방식의 단점은 first/next fit에 비해 상당히 느리다는 점이다. 충분히 할당할 수 있는 free 블럭들을 찾아도 모든 가용블럭들 중 가장 적합한 영역을 찾기위해 순회한다.
하드웨어 메모리 크기가 커질 수록 더 많은 가용블럭들이 있을텐데 그럼 더 많은 블럭을 순회해야하고 속도가 더 느려질 것 같다. 대신 내부 단편화를 최소화하고 가장 맞는 사이즈에 할당함으로서 메모리 이용률은 더 좋은 장점을 가진다. 라는 점이 이론적으로나 할당하는 특정 시점에서는 그렇긴 한데 실전에서나 프로그램이 막상 지속적으로 할당하기 시작하면 그렇지 못하다는게 함정이다. 다음 예시를 보자.
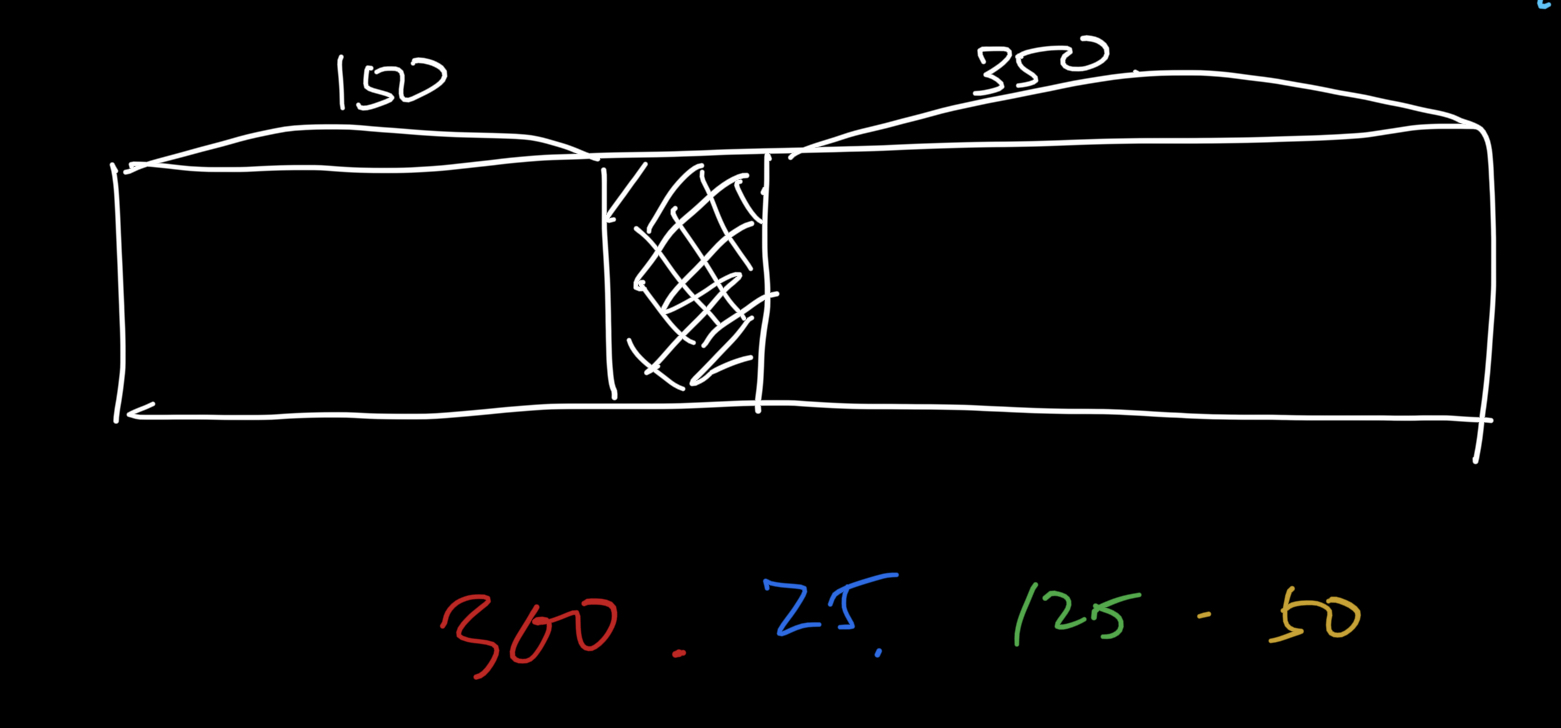
150, 350 만큼의 가용 블럭이 있다. 가운데는 다른 할당된 영역이 있다고 가정한다. 저기도 비어있다면 애초에 전체를 합쳐서 큰 가용블럭으로 관리하는 게 맞을 것 같아서 가운데에 할당 블럭을 하나 채워넣었다.
[300, 25, 125, 50] 크기의 할당 요청이 들어온다고 가정한다.
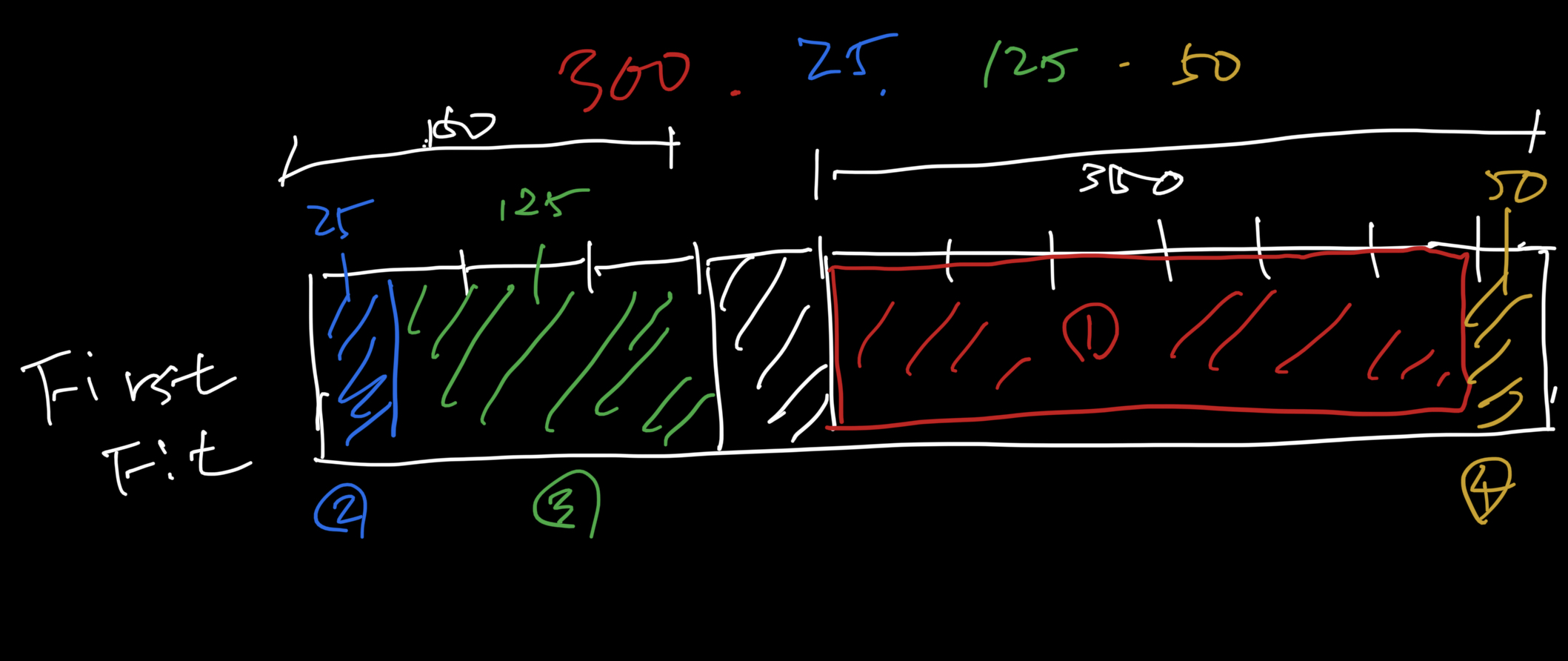
First fit 방식으로는 순서대로 앞 부분부터 할당할 수 있는 영역을 찾아가면서 모든 할당 요청들을 처리해주었다.
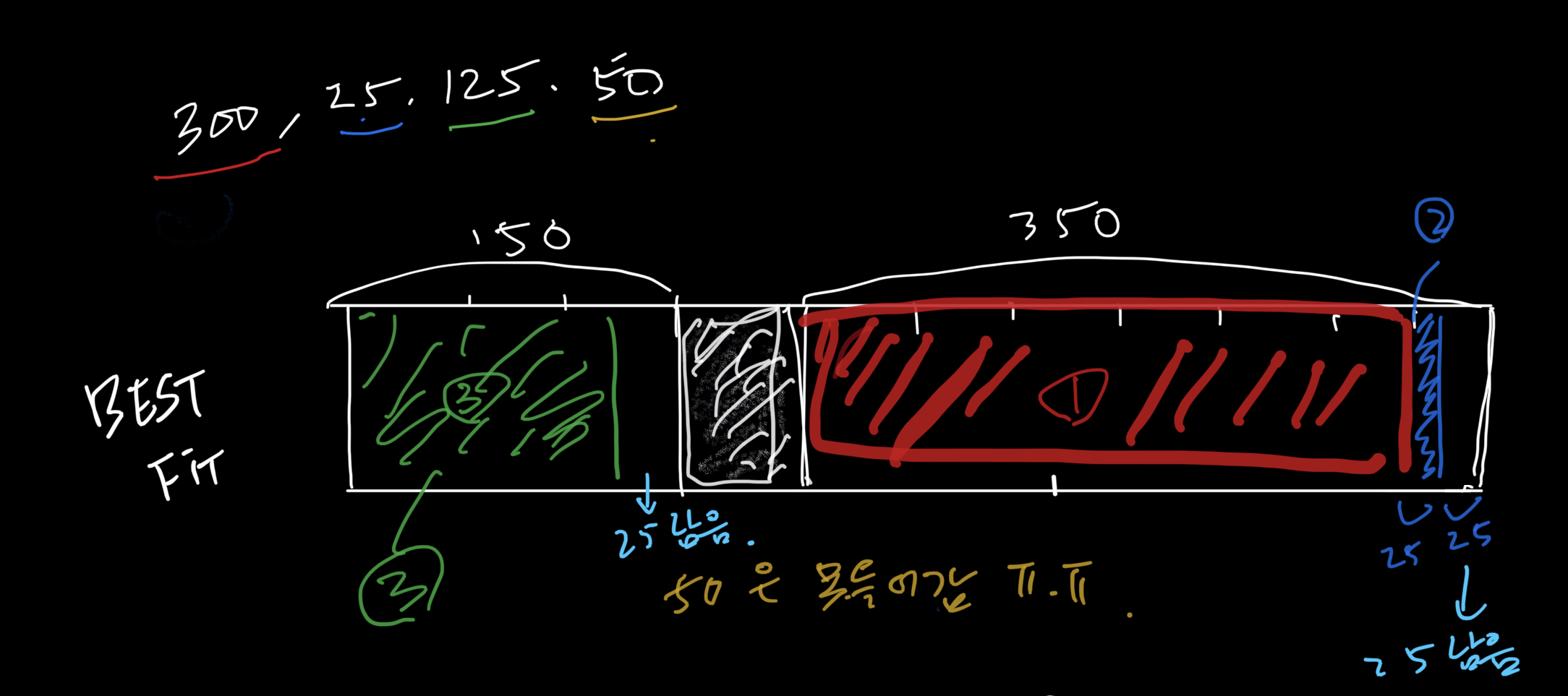
허나 best fit 방식을 보면,
1번 300을 할당 한 이후 가용 블럭이
[150, 50] 이 남게 되고 그 다음 25 할당 요청에 있어서 더 작은 가용 블럭인 50을 분할하여 할당하고 [150, 25] 가용 블럭을 남기게 되는데 그럼 마지막 50 영역을 할당해 주지 못하게 된다. [25, 25] 가용 블럭이 남아 있음에도 불구하고 외부단편화 현생이 발생하였다.
이렇듯 메모리 이용률을 높이기 위한 best fit 방식이었지만 가장 적합한 영역에 할당하면서도 오히려 단편화 현상을 발생시킬 수 있다.
즉, best fit은 처리량이 느리고 쓸 수 없는 가용 블럭들을 중간 중간에 만들어낸다. (단점)
따라서 일반적으로 first, next fit 방식이 best 보다 좋은 효율을 가진다.
