🔊 Udemy Hadoop 무료 강의를 정리한 내용입니다.
강의 내용에 이해가 더 필요한 내용을 덧붙여 정리하였습니다.
HDFS의 노드, 클러스터가 무엇인지에 대
언제나 피드백은 환영입니다. 제가 잘못 알고 있는 내용이 있다면 코멘트 부탁드립니다!_
1. Hadoop Distributed File System - 리눅스 기본 명령어
- Linux에서 사용하는 기본 명령어를 하둡에서도 지원한다.
- 하둡 파일 시스템에서 명령어를 시행하기 위해서는 3 가지 방법이 있다.
1) hadoop fs -ls /
- 하둡 파일 시스템에 존재하는 파일 조회
- 현재 디렉토리를 기준으로 존재하는 파일 모두 출력하기
- 노드 별로 같은 명령어를 적용하였을 때 결과가 다를 수 있다. 하둡 클러스터의 각 노드 별 현재 디렉토리에 다른 파일들이 존재할 수 있기 때문이다.
- 다음과 같은 결과를 확인할 수 있다.

2) hadoop fs -mkdir & hadoop fs -rm -r
- HDFS에 폴더를 만들고 삭제할 수 있다.
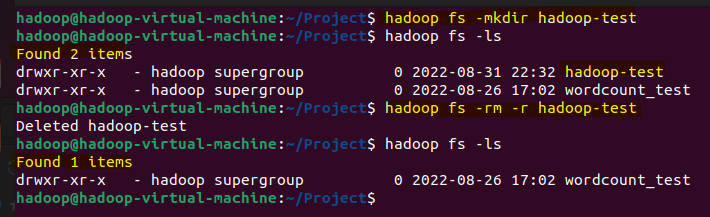
폴더가 생성되고, 삭제된 것을 확인할 수 있다.
3) 로컬에서 파일 복사하기 / 로컬로 파일 붙여넣기
- 로컬에 있는 파일을 복사하여 HDFS에 붙여넣기 할 수 있다.
~$ hadoop fs -copyFromLocal <Local에서 복사하고자 하는 파일> <HDFS에 붙여넣고자하는 위치>
- HDFS에 있는 파일을 복사하여 로컬에 붙여넣기 할 수 있다.
~$ hadoop fs -copyToLcoal <HDFS에서 복사하고자 하는 파일> <Local에 붙여넣으려고 하는 위치>
4) HDFS 내에서 파일 복사하기 / 붙여넣기
~$ hadoop fs -cp <복사하고자 하는 파일> <붙여넣고자 하는 위치>
5) HDFS 내에서 파일 이동하기
~$ hadoop fs -mv <이동시키고자 하는 파일> <이동하고자 하는 위치>
6) 권한 바꾸기
hadoop fs -chmod 777 <권한을 바꾸고자 하는 파일>
리눅스 권한
chmod u=rwx, g=rwx, o=rwx <fileName>
u: user, g: group, o: others
read = 4, write = 2, execute = 1, no permission = 0
~$ chmod 777이란 뜻은, user, group, others 읽기, 쓰기, 실행의 권한을 모두 허가한다는 뜻
2. HDFS 블록
HDFS에 블록에 대한 자세한 이해를 위해 HDFS - Architecture - Block을 참고하였습니다.
- 하둡은 각 클러스터가 네트워크로 연결되어 있고, 네트워크를 통해 많은 양의 데이터를 주고 받는다.
- 각 노드에서 찾고자하는 블럭을 빨리 찾으면서도 네트워크로 많은 양의 데이터를 찾아야 한다.
- 이때문에, 하둡의 블록 크기는 크다. (128MB)
1) 블록이란?
- 한 번 읽고 쓸 수 있는 데이터의 최대량
- HDFS 파일은 지정한 크기의 블록(128MB) 으로 나누어 진다.
- 각 독립된 Node (=local file system)을 가지기 때문에 블록 역시 독립적으로 저장된다.
- 단, 블록 크기보다 작은 크기의 파일은 단일 블록으로 저장된다. (= 실제 파일 크기로 저장)
hdfs fsck /-files-blocks로 각 로컬시스템의 블록을 관리할 수 있다.
2) 하둡이 블록으로 파일을 나누는 이유?
- 파일 하나의 크기가 파일을 저장하는 노드의 디스크 용량보다 커질 때, 블록 단위로 나누어 큰 파일을 저장할 수 있다.
- 하둡은 대용량 데이터처리를 위해 고안된 프레임워크다.
- 블록 단위로 파일을 추상화하였을 경우 시스템을 단순하게 만들어 파일 저장과 탐색 구현을 쉽게 할 수 있다.
- 하둡은 Fault Tolerance를 위해서 복제를 구현한다. 블록 단위로 복제를 구현하기 때문에 데이터 복제를 쉽게 처리하고 같은 노드에 같은 블록이 존재하지 않게끔 만들 수 있다.
- 블록지역성을 통해 (같은 파일의 블록은 같은 노드에 두려 하는 것) 대용량 데이터 확인을 위한 디스크 탐색 시간을 줄일 수 있다.
- 맵 리듀스 처리 시, 블록을 찾는 시간을 줄이고 블록을 처리하는 시간(즉, CPU 처리시간)을 늘릴 수 있다.
- NameNode에 경고를 보내어 실패한 노드의 복제본을 새 노드로 복제하는 데, 만약 두 번째 노드에서 복제할 수 없다면 다른 클러스터에서 해당 블록을 읽어올 수 있도록 한다.
❓❓ 왜 하둡은 복제 시, 블록 개수를 3개로 기본으로 할까?
- 하둡은 블록단위로 파일을 나누고, 해당 블록을 복사하여 다른 클러스터의 노드(파일시스템)에 전송한다.
- 이 때, 3개를 기본으로 복제하는데 일단, 복제를 하는 이유는 Fault Tolerance를 위해서다.
- Fault Tolerance: 하나의 복제본이 손상되어 액세스 할 수 없는 경우, 다른 복제본으로 부터 읽을 수 있다.
3) 블록 작업 순서
같은 노드에 있는 데이터 ▶ 같은 랙(Rack)의 노드에 있는 데이터 ▶ 다른 Rack에 있는 데이터
4) 클라우드 저장공간
- 클라우드 저장공간(i.e. S3)의 경우 HDFS를 이용할 때보다 네트워크를 통한 데이터 전송이 이루어지기 때문에 속도가 느리다는 단점이 있다.
- 그러나 클라우드 저장공간은 서비스를 통해 영구적인 데이터 보관 및 HDFS 관리비를 절감하도록 돕는다는 이점이 있다.
5) 블록 스캐너 및 블록 캐싱
-
블록 스캐너: 주기적으로 각 노드마다 블록 스캐너를 실행하여 블록의 체크섬을 확인하여 오류를 감지하고 처리한다.
-
블록 캐싱: 데이터 노드에 저장된 데이터 중 자주 읽는 블록을 캐시에 저장
- 자주 읽는 블록을 저장할 수도 있지만, 파일 단위 캐싱도 가능하다.
- 파일 단위 캐싱의 경우, 자주 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있다.

담대하게 도전하고 기꺼이 실패를 받아들이는 개발자