🤔 왜 Selenium을 하게 되었는가?
학습 시킬 이미지를 모으기 위해 적어도 만장가량의 이미지 수집이 필요했다.
이전에 드라마 평가 사이트 만드는 프로젝트를 할때에도 크롤링을 했었는데
이는 정적 페이지를 크롤링 하는 것이라 Requests 라이버리를 이용하였다.
근데 네이버와 구글사이트가 업데이트 되면서 크롤링이 되지 않았다.
그리하여 사용하게 된 selenium 라이버리!
selenium은 동적 크롤링을 할때 사용했는데,
실제로 우리가 브라우저를 사용하는 것과 똑같이 동작하게 된다.
1.Selenium 라이브러리 설치
pip install selenium
2.Chrome Driver 설치
(https://chromedriver.chromium.org/downloads)
에서 자신의 크롬 브라우져 버전과 맞는 chromedriver를 다운 받습니다
3.Selenium 실행
드라이버를 열고 검색창에 자신이 검색할 검색어를 쳐보자.
driver = webdriver.Chrome() # 크롬드라이버 설치한 경로 작성 필요 driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") # 구글 이미지 검색 url elem = driver.find_element_by_name("q") #구글 검색창 선택 elem.send_keys(name) # 검색창에 검색할 내용(name)넣기 elem.send_keys(Keys.RETURN) # 검색할 내용을 넣고 enter를 치는것!
"에스파 윈터"를 검색하였고
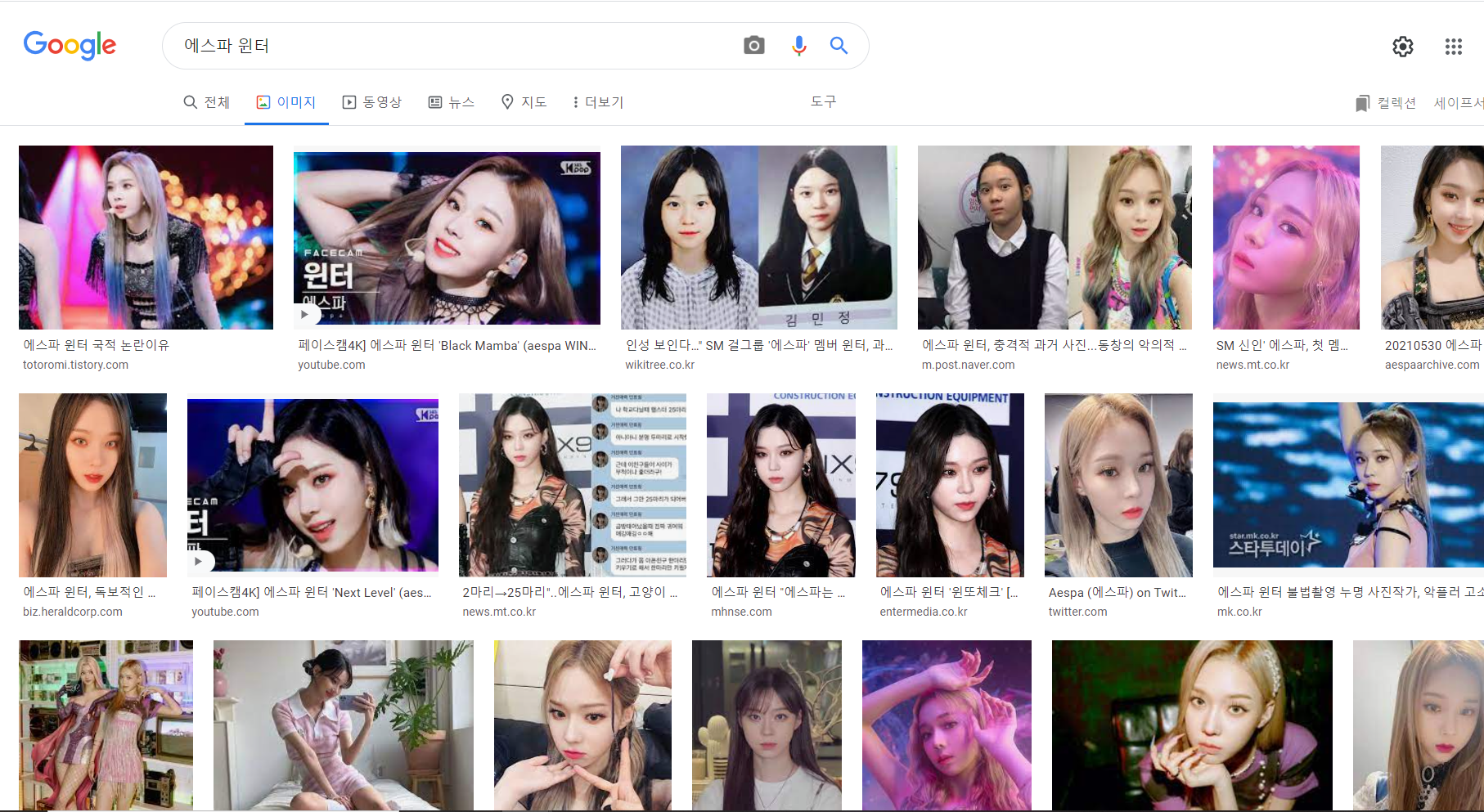
이와 같이 뜨는 모습을 볼수있다.
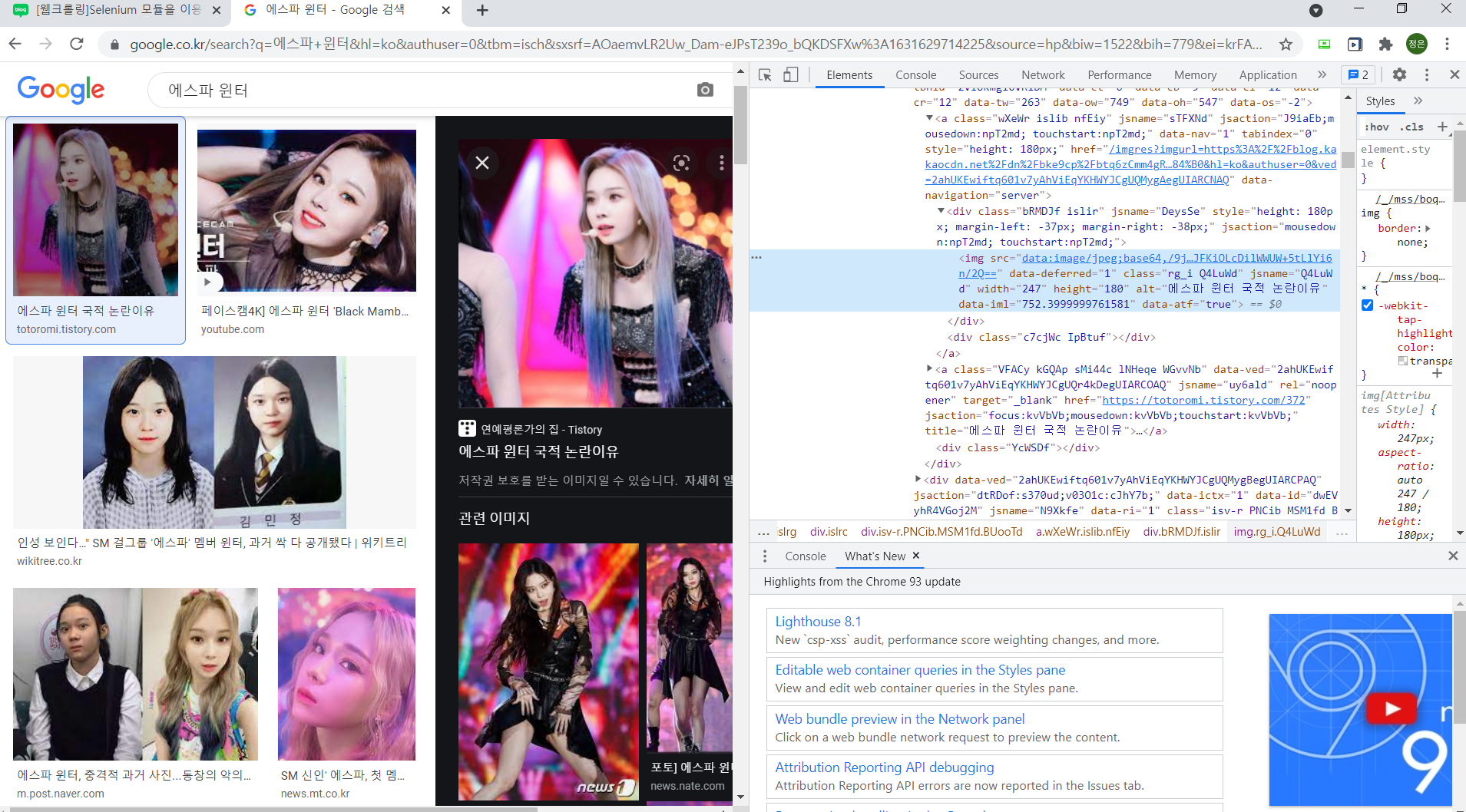
첫번째 이미지를 클릭해서 보면 src가 base64로 인코딩된 이미지 url을 확인 할 수 있다.
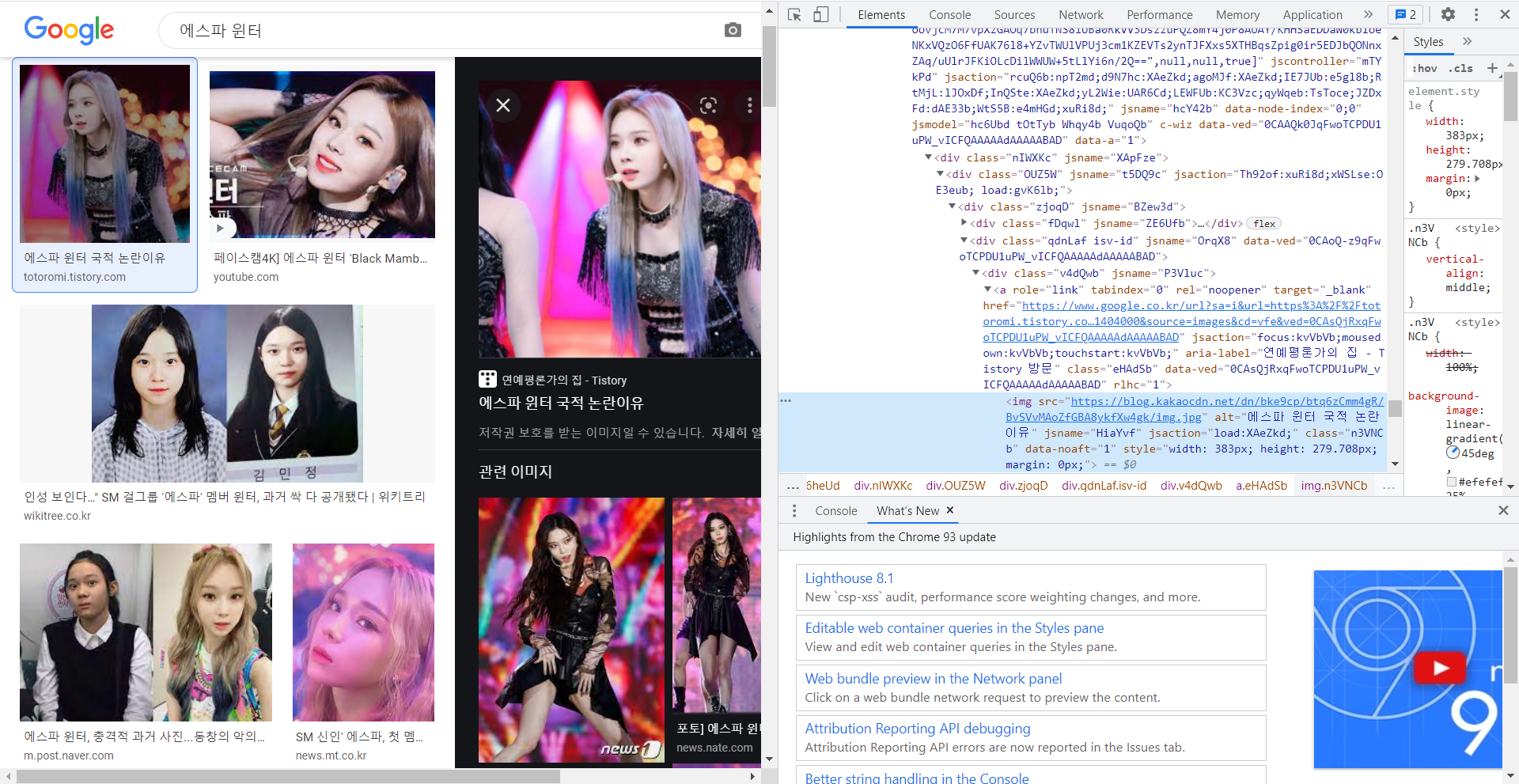
하지만 오른쪽에 뜨는 큰 사진을 다시 선택해보면 우리가 구하는 이미지 url을 확인 할 수 있다!
imgs = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") #작게 뜬 이미지들 모두 선택(elements) for img in imgs: try: img.click() time.sleep(2) imgUrl = driver.find_element_by_xpath( '//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img').get_attribute( "src") # 크게 뜬 이미지 선택하여 "src" 속성을 받아옴 path = "C:\\Users\\paqgl\\PycharmProjects\\pythonProject_crawling\\bs4\\idols\\" + name + "\\" #저장할 경로 urllib.request.urlretrieve(imgUrl, path + name + str(count) + ".jpg") // count = count + 1 if count > 260: #다운 받을 이미지 갯수 조정 break except: pass
driver.find_elements_by_css_selector : css선택자를 통해 해당 선택자에 해당하는 모든 것을 가져온다(".rg_i.Q4LuWd"는 작은 이미지의 클래스이름 "rg_i Q4LuWd"로 앞에 .과 빈칸은 없애고 .을 추가해준 것)
driver.find_element_by_xpath : 클래스는 여러개를 가질수 있다 큰 이미지 선택시 같은 클래스 이름을 가진 의미 없는 이미지가 크롤링 되는 오류를 막기위해 하나뿐인 full xpath를 이용하여 이미지를 가져왔다.
(이는 해당 부분에서 오른쪽 마우스 클릭 -> copy - > copy full x-path 를 통해 얻을 수 있다)
👏 그렇다면 이미지들을 스크롤 끝까지 내려서 더이상 이미지가 없을때까지 다운받으려면?
이미지를 클릭해서 다운받기 전 해당 페이지의 스크롤을 끝까지 내리고 시작하자!
last_height = driver.execute_script("return document.body.scrollHeight") # 브라우저의 높이를 자바스크립트로 찾음 while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 브라우저 끝까지 스크롤을 내림 # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: try: driver.find_element_by_css_selector(".mye4qd").click() #스크롤을 내리다 보면 "결과 더보기"가 뜨는 경우 이를 클릭해준다 except: break last_height = new_height
🏁 최종 코드
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os
def createDirectory(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print("Error: Failed to create the directory.")
def crawling_img(name):
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl")
elem = driver.find_element_by_name("q")
elem.send_keys(name)
elem.send_keys(Keys.RETURN)
#
SCROLL_PAUSE_TIME = 1
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight") # 브라우저의 높이를 자바스크립트로 찾음
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 브라우저 끝까지 스크롤을 내림
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
imgs = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
dir = ".\idols" + "\\" + name
createDirectory(dir) #폴더 생성
count = 1
for img in imgs:
try:
img.click()
time.sleep(2)
imgUrl = driver.find_element_by_xpath(
'//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img').get_attribute(
"src")
path = "C:\\Users\\paqgl\\PycharmProjects\\pythonProject_crawling\\bs4\\idols\\" + name + "\\"
urllib.request.urlretrieve(imgUrl, path + name + str(count) + ".jpg")
count = count + 1
if count >= 260:
break
except:
pass
driver.close()
idols = ["넣고 싶은 검색어"]
for idol in idols:
crawling_img(idol)
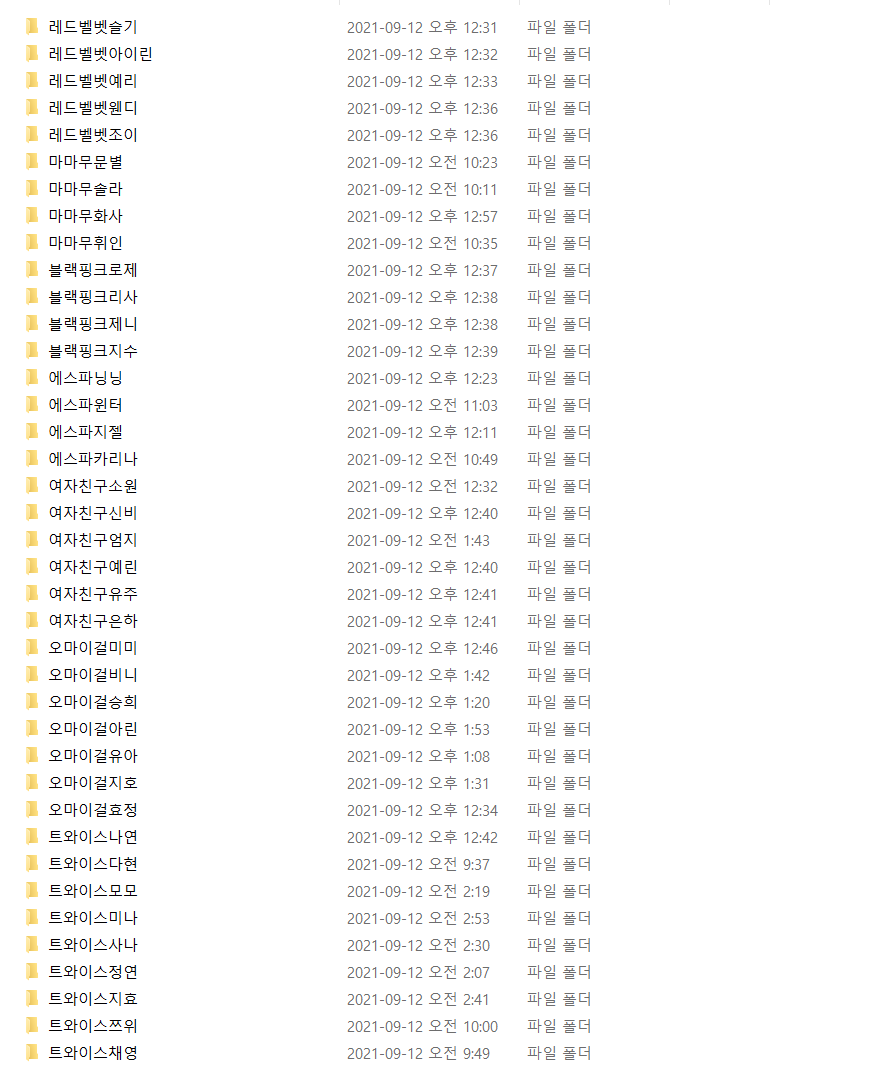
크롤링 성공!
( 질문이 있다면 댓글 부탁드립니다 😊)

5개의 댓글

제가 작성해본 코드도 그렇고, 작성자분 코드로도 돌려보고 있습니다만, 첫번째 사진을 제외한 나머지 사진들이 미리보기 화질로 저장되는 문제가 계속 생기네요..? 제 환경에서만 이런지 모르겠습니다 ㅎ


코드는 돌아가는데 사진이 폴더에 안들어오는 건 왜 그럴까요? ㅠ