
Compute shader
- 렌더링과 전혀 관계없으며, 오직 계산만을 위한 쉐이더
- draw함수가 아닌 별도의 함수로 compute shader 호출 (다른 쉐이더들과 분리되어있음)
- OpenCL 이나 CUDA 등을 사용해 병렬 연산을 할 수 있긴 하지만
General Purpose Computation on GPU, OpenGL과 분리되어있어서, OpenGL에 속한 compute shader 쓰는게 편함
- OpenCL 이나 CUDA 등을 사용해 병렬 연산을 할 수 있긴 하지만
- 직접적으로 유저가 정의하는 input/ouput이 없다 (uniform 변수마냥..)
- cs에 데이터를 넘겨주기 위해 image load/store operation이나 shader storage buffer 등을 사용
Compute Space & Work Group
- Compute shader를 몇 번 사용할 것인지 (= 몇 번의 shader invocation) 정하기 위해 사용자가 정의하는 정보
- Compute space를 몇 개의 Work group으로 나눌지를 결정하고, 각 Work group을 몇 번의 shader invocation으로 나눌 것인지 결정
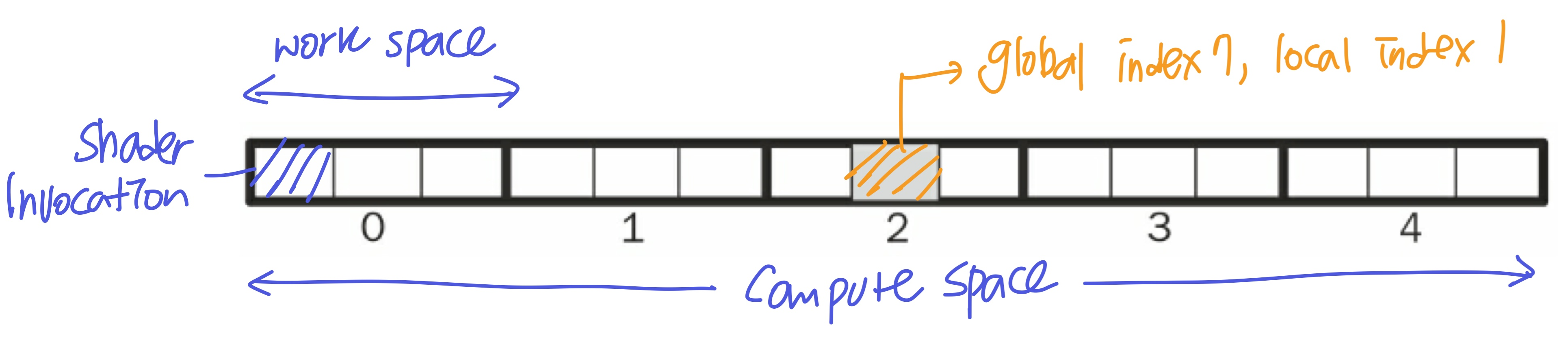
- 한 compute space에 5개의 work group
- 한 work group에 3개의 shader invocation
- 총 15개의 shader invocation
- Compute space는 1D, 2D, 3D 공간에 정의 가능하고, 적절한 차원을 선택해야함
- 2D인 경우, 2개의 index로 shader invocation을 식별하게되고, 이는 아래/위/좌/우의 cs의 관계성을 파악할 수 있게 됨
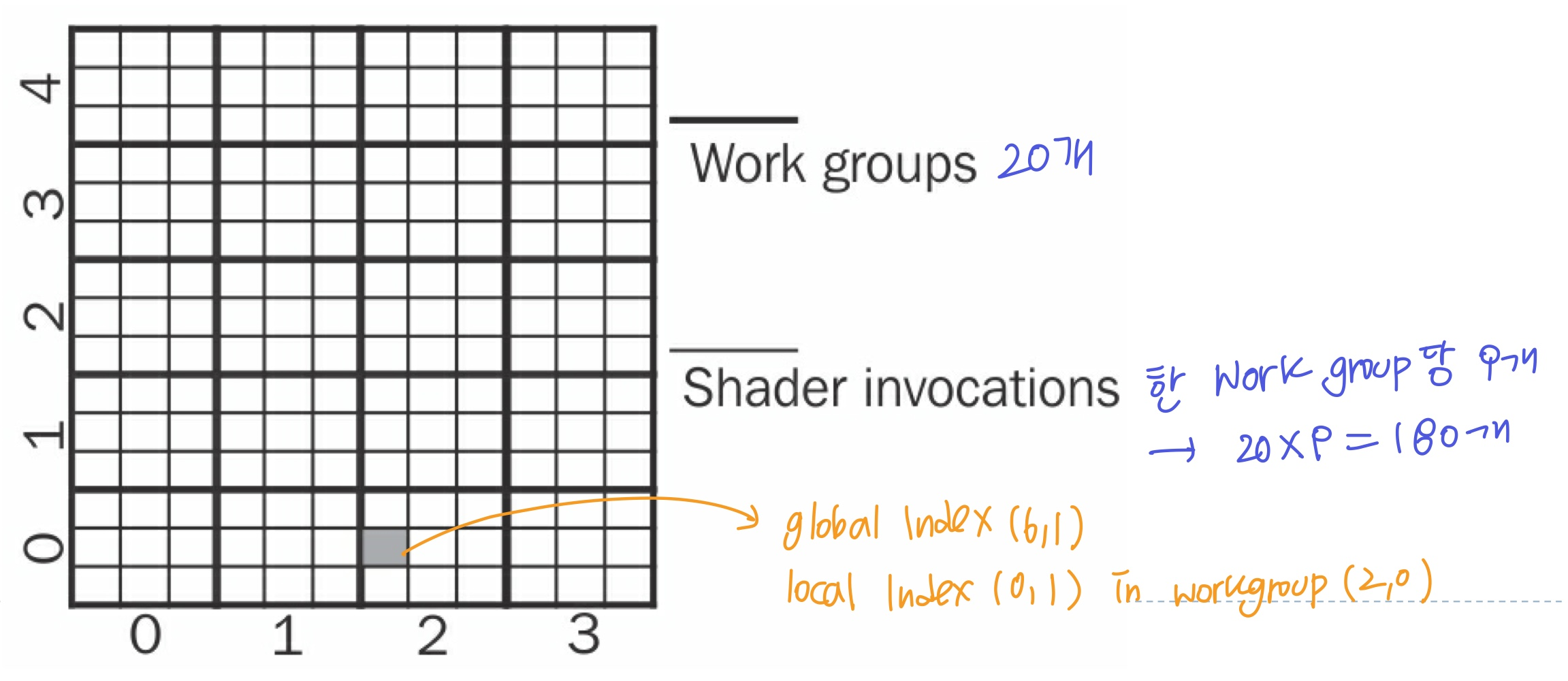
- ex) 파티클은 1D(list), 옷감은 2D(grid)
- 각 시스템마다 work group의 최대 개수와 각 work group의 shader invocation의 최대 개수가 제한

- 2D인 경우, 2개의 index로 shader invocation을 식별하게되고, 이는 아래/위/좌/우의 cs의 관계성을 파악할 수 있게 됨
Communication between invocations
- 병렬처리는 독립적으로 동작하므로 데이터를 공유하지 않지만, 단계를 나눠서 한 Work Group 내의 invocations들끼리 데이터를 공유할 수 있도록 함
- 다른 work group의 invocation과 공유하면 문제(deadlock, data races)가 발생할 수 있음을 고려해야함
- 사실, 한 work group 안에서도 문제가 생길 수 있음
- work group과 shader invocation이 numbering되어있지만, 실행 순서는 정해져있지 않으므로 (병렬처리니까) 다른 invocation 실행 완료를 기다리는 delay가 생길 수 있음
- 그래도 Work group은 이러한 문제점을 보완할 수 있는 기능을 가지고 있음
- atomic operations (공유하는 invocation 연산 사이에 다른 연산을 하지 않도록 함)
- memory barriers 등
- 그래서, work group 내에서만 데이터를 공유하는 것이 효율성을 위해 굳
Executing the Compute shader
- draw 함수가 아닌,
glDispatchCompute라는 특정 함수로 cs 실행- dimension에 따른 인자 전달
- ex) 2D compute space의 4x5 workgroup

- 하나의 work group을 몇 개의 invocation으로 쪼갤지는 cs안에서 지정
- layout specifier 사용
- ex) 3x3 invocation
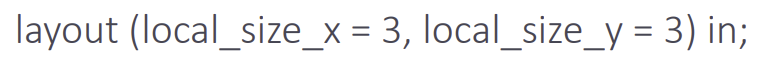
Input/Output
- 유저가 지정하지 않는 input
: shader invocation에서 계산하는데 사용되는 변수들- 유저가 지정하는 input
: 하나의 work group을 몇 개의 shader invocation으로 쪼갤지
Built-in input variables
- work groud ID와 local invocation ID를 알면 global invocation ID도 구할 수 있지만, 그냥 주어지는 값도 있다~
1. Particle simulation
이전과 동일한데, compute shader에 데이터 전달을 어떻게 하는지!
- One million particle system
- 많은 입자
1x1, transparancy들의 집합으로 시각적 효과 만들어냄 - 힘이 주어지는 점(attractors)
5x5을 정의 (가속도 계산 필요)
- 많은 입자
- 각 파티클이 attractor에 의해 받는 힘
- 파티클과 attractor의 거리가 멀수록 힘의 영향이 작다
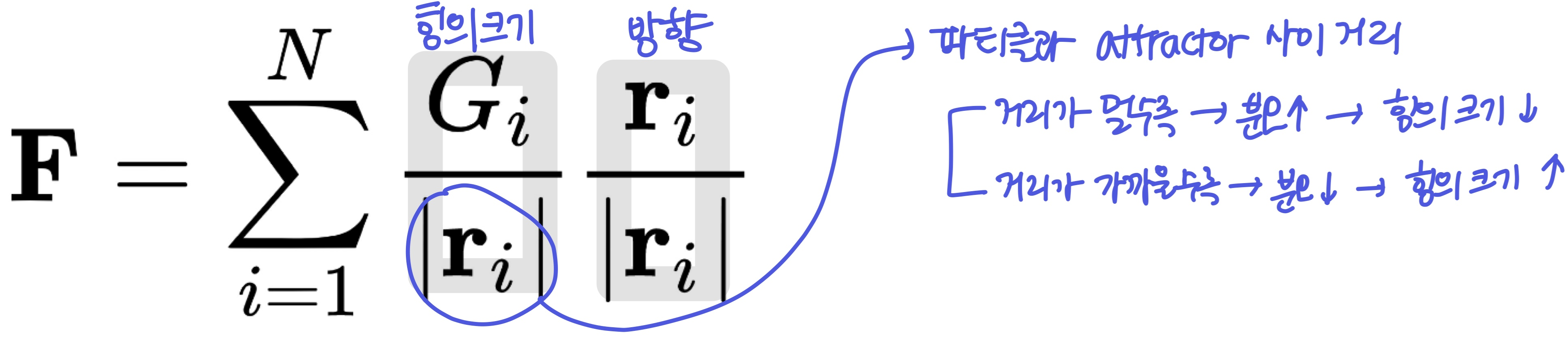
- N: attractor의 개수
- r: 파티클과 attractor 사이 벡터
- G: attractor의 힘
- 파티클과 attractor의 거리가 멀수록 힘의 영향이 작다
- 위의 힘 F를 계산해서 가속도를 새로 계산하는 것
- cs에서 파티클 position update하고(Euler method), 그 값으로 파티클 렌더링
- cs에서 계산하면 GPU 병렬 연산으로 빠를 뿐만 아니라, compute space를 쪼개는 정도로 효율성을 조절할 수 있으므로.. GPU에서 가장 좋은 효율성을 찾아갈 수 있음 -> 가성비 굳!
- 직전 프레임의 데이터(pos, vel)를 전달하기 위해 shader storage buffer objects에 저장해서 cs에 전달
- 이 값으로 파티클 렌더링도 해야하니까 vs의 input으로도 연결해줘야함
Compute space
- 몇 번째 파티클인지만 알면 되므로 1D compute space 정의
- 한 work group 안에 1000개의 invocation
= 한 work group 안에서 1000개의 파티클을 계산한다 (하나의 파티클은 하나의 shader invocation) - work group의 개수는
전체 파티클 수 / 1000
- 한 work group 안에 1000개의 invocation
OpenGL Application
- 파티클의 position과 velocity를 위한 버퍼를 생성하고, shader storage buffer에 바인드
- 초기 위치는 임의의 값으로, 초기 속도는 0으로 미리 만들어 두었고, 그 값을 버퍼에 올린다
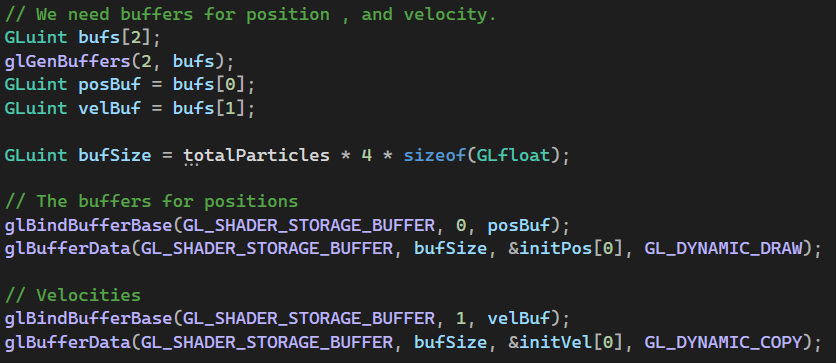
- 초기 위치는 임의의 값으로, 초기 속도는 0으로 미리 만들어 두었고, 그 값을 버퍼에 올린다
- vertex array도 만들어서 position buffer를 담는다 -> vs에서 사용하여 파티클 렌더링
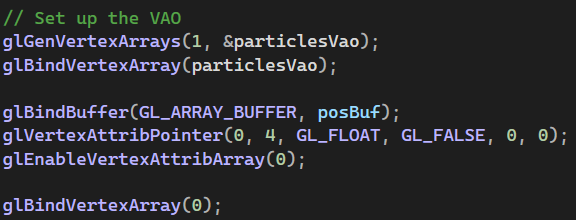
- 투명도를 가지는 파티클을 위해 blend enable

- cs 실행을 위해
glDispatchCompute함수 호출 - shader storage buffer의 모든 데이터가 덮어씌워지고 난 뒤에 다음 프로세스가 실행되도록 보장
- 이전 프레임의 모든 파티클 계산이 완료된 후에 다음 프레임을 계산해야하므로

- 이전 프레임의 모든 파티클 계산이 완료된 후에 다음 프레임을 계산해야하므로
compute shader ✨
- shader storage buffer로 파티클의 위치/속도 정보를 읽어오고, 새로 업데이트한 값도 쓰고 (하는 듯?)
- attractor가 파티클에 미치는 힘을 계산하고, 그 값으로 가속도를 계산해 파티클 위치/속도 업데이트

2. Fractal texture
- Fractal: 일부 작은 조각이 전체와 비슷한 기하학적 형태를 갖는 기하학적 구조
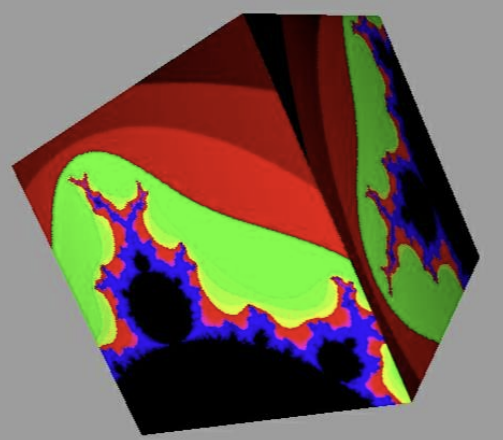
- Mandelbrot set
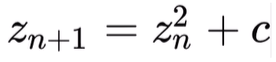
- z, c는 복소수 (z의 초기값은
0+0i) - 으로 다음 을 계산 (iteration)
- z, c는 복소수 (z의 초기값은
- 각 픽셀마다의 컬러를 결정하기 위해 z값을 계산하는데,
- z가 수렴하면 -> 검정색
- z가 발산하면 -> 발산되는 순간의 iteration 수로 color 결정
- 각 픽셀 좌표에 따라 c의 값이 결정
- ex) (0.1, 0.5) -> c = 0.1 + 0.5i
- 픽셀에 따라 달라지는 값은 c뿐이고, 이를 통해 반복하며 z값을 업데이트 시키는 것
- 픽셀마다 compute shader 실행
- 모든 연산이 픽셀마다 독립적 (주변 픽셀에 따라 달라지지 않음)
- compute shader의 결과를 텍스처로 저장하는게 포인트인 예제
Compute space
- 대응되는 픽셀을 찾기 쉽도록 2D compute space
- 한 work group 안에 32x32개의 invocation
= 한 work group 안에서 32x32개의 픽셀을 계산한다 (총 invocation 횟수 = 픽셀 개수) - work group의 개수는
텍스처크기/32
OpenGL Application
- fractal 계산 결과를 담을 텍스처 생성 (unit=0)

- 이후 큐브 렌더링 및 텍스처 매핑
compute shader
- cs에서 계산한 값을 이미지에 저장하기 위해
image2D오브젝트를 사용 - c를 사용해서 z를 반복하여 계산하고, 수렴/발산에 따라 컬러를 결정

- fragment shader에서도 같은 계산을 할 수 있지만
- FBO를 사용해서 texture를 만들어야하고 (multi-pass)
- GPU의 효율성을 극대화하기 위한 조절을 못한다
3. Cloth simulation
- 5개의 핀으로 고정되어있는 옷감의 버텍스 위치를 계산
- 그리드 형식의 각 버텍스들은 spring으로 연결되어있고, 이로 인한 힘 발생
- 단일 스프링의 힘
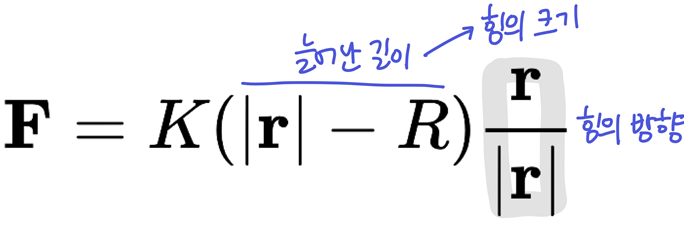
- K: stiffness(얼마나 뻣뻣한지, 스프링의 강도)
- R: 스프링을 가만히 뒀을 때의 길이
- r: 두 파티클 사이 벡터
- 한 파티클에 가해지는 최종 힘은 주변 8개 파티클과의 힘의 합
- 단일 스프링의 힘
- 공기 저항
D고려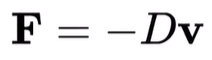
- 저항이므로, 원래 가려던 방향
v의 반대로 힘이 가해지도록-부호 붙임
- 저항이므로, 원래 가려던 방향
- 각 compute shader Invocation에서 주변 8개의 파티클의 위치/속도로 새로운 값 update
- 이때, 위치/속도에 각각 한 버퍼만 있으면, 현재 데이터인지 업데이트된 데이터인지 헷갈릴 수 있음
- 그래서 위치/속도 각각 input/output 2개의 버퍼를 만들어주고, swap하며 사용 (ping-ponging)
- 자연스러운 시뮬레이션을 위해 단위시간을 아주 작게
0.000005설정하여 계산- 계산은 아주 작은 단위 시간으로 하지만,
- 모든 계산 결과를 다 렌더링 할 필요는 없음 (이 예제에서는 1000번 계산하고 1번 그려줌)
Compute space
- grid 형태의 천에서 한 지점을 정의해야하므로 2D compute space 정의
- 아래/위/좌/우의 cs의 관계성을 파악
- 한 work group 안에 10x10개의 invocation
= 한 work group 안에서 10x10개의 버텍스(파티클)를 계산한다 (총 invocation의 개수 = 전체 버텍스 개수)
OpenGL Application
- 파티클의 위치/속도 버퍼 2쌍 생성, shader storage buffer에 바인드
- row major order: 왼쪽 아래부터 오른쪽 위까지 row방향으로 numbering (2D data를 1D buffer에 넣을 때)
- vertex array object에 위치 버퍼를 담는다(노멀, 텍스처좌표 버퍼도) -> vs에서 해당 버텍스 값으로 삼각형 렌더링
- 1000번 계산하고, 1번 렌더링
- 1000번 반복문에서 cs 호출 및 버퍼 swap

- 1000번 반복문에서 cs 호출 및 버퍼 swap
compute shader

- 해당 파티클의 1D index로 기존 위치/속도 정보를 받아옴 (inputBuffer에서)

- spring force의 sum을 계산할 때, 이웃이 있는 경우만 force sum을 해준다
- 가장자리(테두리)에 있는 파티클은 8개보다 적은 이웃 파티클을 가지기 때문
- 수많은 if문을 거치면, 이웃이 없는 방향을 제외한 force sum이 계산된다

- 공기저항의 힘까지 추가한 뒤, 그 값을 사용해 가속도를 계산하고, Euler method를 풀어 파티클의 위치/속도 정보를 update한다 (outBuffer에 작성)

- 고정된 5개의 핀은 위치는 그대로, 속도는 0으로 설정

- normal 계산을 위한 compute shader도 생성하여, position 계산 완료된 후에 normal도 업데이트한다
- position cs 1000번 계산
- normal cs 1000번 계산
- 옷감 렌더링
4. Edge detection filter
- cs에서 edge detection filter를 구현하여 이전에 fragment에서 계산한 방법보다 빠르다
- 한 픽셀에 대해서 cs 실행
local shared memory
- work group 사이즈에 맞춰 local shared memory를 생성한다
- 버퍼에서 한 work group에 해당하는 데이터를 local shared memory로 복사
- 데이터를 읽어올 때, 버퍼가 아닌 local memory에서 읽어온다
- 버퍼에 접근하는 속도보다 local shared memory에 접근하는 속도가 더 빨라서 효율적
- local memory가 GPU와 더 가깝기 때문
- 기존 주변 픽셀의 값으로 텍스처 값을 로드하는 방법은 비효율적
- 이 예제에서는 work group
25x25보다 조금 더 크게 memory27x27를 생성한다- work group의 가장자리 픽셀도 주변 정보가 필요하므로, 가로/세로 1줄씩 더 추가해줬다
- 1pass에서 모델 렌더링 결과 FBO에 저장 및 cs에서 edge 계산한 결과를 텍스처에 저장하고, 2pass에서 최종 텍스처를 쿼드에 그린다
OpenGL Application
- 2개의 텍스처를 만든다
- renderTex: 1pass의 렌더 결과 저장 -> FBO에 저장
- edgeTex: cs의 결과를 저장 -> 2pass에서 full screen quad에 그려짐
- 2개의 텍스처를
glBindImageTexture함수로 unit 0, 1에 각각 저장 -> cs에서 사용 가능 - full screen quad 그리기~
compute shader
- renderTex는 inputImg로, edgeTex는 outputImg로 사용

sharedqualifier를 사용하여27x27local shared memory 생성- 같은 work group 내의 다른 cs와도 공유되는 데이터

- 같은 work group 내의 다른 cs와도 공유되는 데이터
- soble filter 적용
- local shared memory의 값으로 주변 데이터 값을 사용하여 계산

- local shared memory의 값으로 주변 데이터 값을 사용하여 계산
- main에서 local shared memory에 데이터를 넣어준다
- 해당 픽셀의 globalIndex+1에 해당하는 input 이미지 값을 luminance로 변환하여 저장

- work group에서 가장자리에 있는 픽셀은 자기 자신의 픽셀값 뿐만 아니라, 추가 라인에 대한 픽셀값도 shared memory array에 저장해줘야한다 (25x25 -> 27x27)
 (Bottom, Top, Left, Right edge.... 다 수행)
(Bottom, Top, Left, Right edge.... 다 수행)- 근데 global하게 가장자리라 주변 데이터가 없는 경우 -> 0 저장
- 해당 픽셀의 globalIndex+1에 해당하는 input 이미지 값을 luminance로 변환하여 저장
- work group내에 다른 모든 cs도 local shared memory에 값을 저장할 때까지
barrier()에서 기다리고, local shared memory가 다 채워지면 다음 코드(sobel filtering)를 진행
- shared memory array에 저장하고 기다리는 과정에서
- work group이 너무 크면 병렬처리지만 delay가 생길 수 있고
- work group이 너무 작으면 오히려 비효율적일 수 있다
- 서로 계산된 데이터를 주고받는 경우에도 사용 가능 (communication)
- 이 예제는 그냥,, 속도를 빠르게 하기 위해 참조만 한 정도
- shared memory의 최대 크기는 시스템마다 달라서 쿼리해서 알아내면 굳

( •̀ .̫ •́ )✧