
🔸Translating and Starting a Program
- 초기에는 프로그래머가 기계어(이진 코드)로 직접 개발
- 현대에는 사람이 이해하기 쉬운 언어를 사용하기 때문에 기계어로 번역해야 함
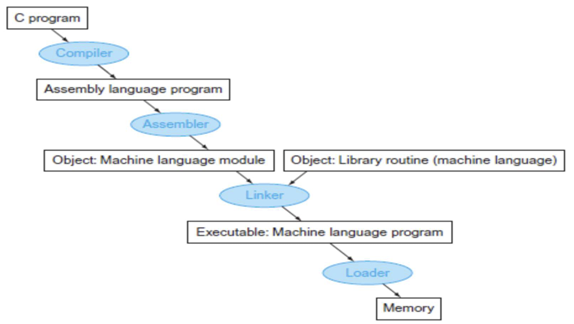
🔹Translation Hierarchy
- Complier: high-level language(C Program)를 low-level language(Assembly)로 변환
- Assembler: Assembly를 기계어로 변환하여 오브젝트 생성
- Assembly language: 기계어와 1:1대응되는 low-level 언어
- Linker: 여러 개의 오브젝트 파일을 하나의 실행 파일로 결합하여 기계어 프로그램을 만듦
- Loader: 실행 파일을 메모리에 올려 실행할 준비
🔹Assembler
- Assembly언어로 작성된 프로그램을 기계어로 변환하는 시스템 소프트웨어
- 최종적으로 오브젝트 파일을 생성하고, 기계어 instructions, data, 명령어를 메모리 내에 적절히 배치하는데 필요한 정보를 포함
- 주요 기능
- opcode table을 사용하여 Mnemonic operation code를 기계어로 변환
- symbol table을 사용하여 각 레이블의 이름과 그 레이블이 차지하는 메모리 주소를 매칭
- 기본적인 기능을 고려하면 대부분 유사하지만, machine architecture에 따라 기능과 설계가 달라짐 → Machine Dependent Feature
🔸SIC Assembler Lauguage Program
🔹Components
- line number (참조용, 프로그램의 일부가 아님)
- symbol label
- Mnemonic instruction
- Indexed addressing
- comments
🔹Assembler Directive (지시어)
Directive는 기계어로 변하지 않고, assembler에 대한 instrictons을 제공 → assembler는 이러한 지시어를 통해 동작
- START: 프로그램의 이름과 시작 주소 명시
- END: 원시 프로그램(source program)의 끝을 나타냄, (선택적으로) 최초로 실행할 명령어 지시
- BYTE: 문자나 16진수 상수 생성, 상수를 표현하는데 필요한 만큼의 바이트 사용
- WORD: 1워드의 integer 상수 생성
- RESUB: 데이터 영역의 크기를 지시된 바이트 수 만큼 예약(reserve bytes)
- RESW: 데이터 영역의 크기를 지시된 워드 수만큼 예약(reserve words)
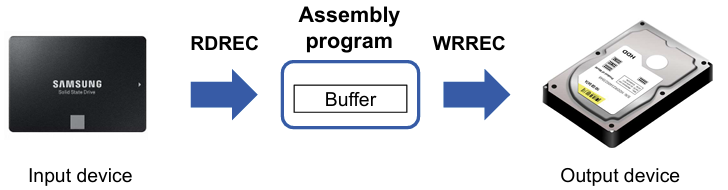
🔹I/O처리 방식
- assembler language program은 입력 장치
F1로부터 레코드를 읽고 출력 장치05로 복사하는 메인 루틴을 가짐 - 메인 루틴은 두 개의 subroutine을 호출함
- RDREC: 입력 장치로부터 레코드를 읽어 버퍼
4096bytes에 저장 - WRREC: 버퍼에 저장된 레코드를 출력 장치로 기록
- RDREC: 입력 장치로부터 레코드를 읽어 버퍼
- 각 subroutine은 레코드를 한 번에 한 문자씩만 전송 (SIC에서 제공하는 I/O 명령어가 RD, WD뿐이라서)
- 레코드는 여러 문자를 포함하고, 끝은 Null문자(hex 00)으로 표시됨
- 입력 및 출력 장치 간의 I/O 속도 차이로 인해 버퍼가 필요
🔹EOF 처리, Subroutine
- 파일의 끝(EOF) = 서브루틴의 끝
- 프로그램은 파일의 끝이 감지되면 EOF를 출력하고, RSUB명령어로 파일 종료 시킴
- JSUB: 파일(서브루틴) 호출
- JSUB m: 현재 PC의 값을 레지스터L에 저장, PC를 subroutine 시작 주소 m으로 설정
L ⇐ (PC); PC ⇐ m
- JSUB m: 현재 PC의 값을 레지스터L에 저장, PC를 subroutine 시작 주소 m으로 설정
- RSUB: OS로 제어 반환 (프로그램의 흐름을 이전 상태로 되돌림)
- RSUB: 레지스터 L에 저장된 주소를 PC에 복원
PC ⇐ (L)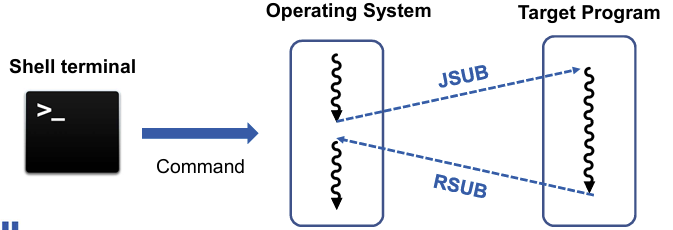
- RSUB: 레지스터 L에 저장된 주소를 PC에 복원
Example of Assembly program
- 키보드로 입력 받은 값을 버퍼로 옮겨서 그대로 출력하는 예제



🔹Object Code
- 각 instruction에 대한 Object code와 machine address가 존재
- Machine address
- 위의 예시에서 주소를 나타내는 ‘LOC’ 열이 빠져있음 (COPY프로그램은 주소 1000에서 시작)
- ‘LOC’ 열은 machine address(in hex)를 제공
- instruction 한 줄은 word
3byte단위라서 3씩 증가 (1000 > 1003 > 1006 > …)
- 소스 프로그램을 Object code로 변환하기 위한 여러 functions
- OP code table을 이용해서 mnemonic operation codes
STL를 machine language equivalents14로 변환 → opcode - Symbol table을 이용해서 Symbolic operands(피연산자)
RETADDR를 equivalent machine addresses1033로 변환 → X + address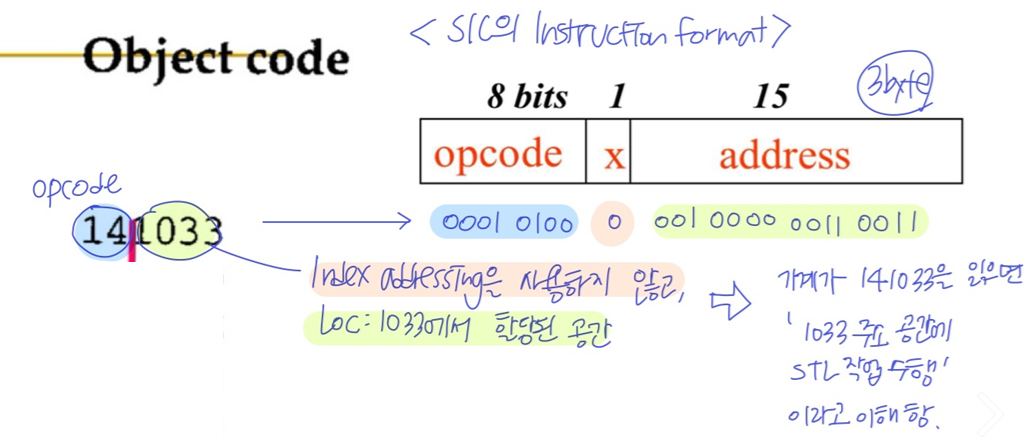
- Machine instruction 빌드 (addressing mode 등과 같은 적절한 형식으로)
- data constants
EOF를 내부 machine representation454F46으로 변환 - object program과 assembly listing file 작성
- assembly listing file: 프로그램이 어떻게 변환되었는지를 검토하는데 사용
- OP code table을 이용해서 mnemonic operation codes
- Forward reference
- 위 예시의 Line 10에 forward reference가 포함되어있음

- 이것 때문에 대부분의 어셈블러는 2pass로 구현
- 1pass: Label 정의 스캔 및 symbol table에 label의 주소를 기록
- 2pass: 위의 Object code로의 변환 과정 수행
- 위 예시의 Line 10에 forward reference가 포함되어있음
Example of Object code
🔹Object Program
- 어셈블러는 생성된 object code를 출력 장치(storage)에 저장된 object program에 기록
- 저장된 object program이 memory에 로드되며 실행됨
Object program 형식의 3가지 type record
- Header record: 프로그램 이름, 시작 주소 및 길이
- Col. 1: H
1byte - Col. 2-7: Program name
6byte(아래도 같은 형식으로) - Col. 8-13: object program의 시작주소(16진수)
- Col. 14-19: bytes로 표현한 object program의 길이(16진수)
- Col. 1: H
- Text records: 변환된 instruction과 data와 이것들이 로드될 주소
- Col. 1: T
- Col. 2-7: 해당 레코드의 object code 시작주소(16진수)
- Col. 8-9: bytes로 표현한 해당 레코드의 object code 길이(16진수)
- Col. 10-69: 16진수로 표현된 object code(column 2개가 1 byte)
- End records: 프로그램의 끝, 시작될 떄 주소
- Col. 1: E
- Col. 2-7: object program에서 첫 번째 실행 가능한 주소(16진수)
Example of Object Program
- object code를 나열
- 위의 3 types of record와 함께 보기

- Loc 1033-2038에는 해당하는 object code가 없음
- 메모리 공간만 할당만 해두는 ‘RESW', 'RESB'는 프로그램이 동작하면서 결정되므로 assembler가 해당 object code를 정의해둘 수 없는 것
- 이 영역은 Loader에 의해 프로그램 실행 중에 사용할 수 있도록 예약만 된 저장공간
🔹Object File (UNIX)
- Unix시스템용 object file은 6개의 영역으로 나뉨

- Header: object file의 나머지 5개 영역의 크기 및 위치
- Text segment: machine language code
- Static Data Segment: 프로그램이 살아있는 동안 할당되는 데이터
- Unix에서는 정적/동적 데이터 전부 사용 가능
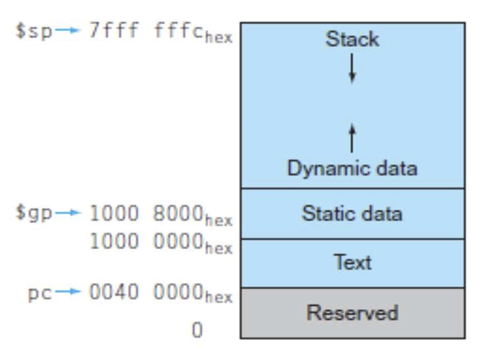
- Unix에서는 정적/동적 데이터 전부 사용 가능
- Relocation Information: program이 메모리에 로드될 때 절대 주소에 따라 달라지는 instructions 및 data words 식별
- Symbol Table: functions 및 전역 변수에 대한 [lable-address] 정보
- Debugging Information: machine instruction을 C소스파일과 연결할 수 있도록 symbolic 정보 포함
🔹2-pass Assembler
assembly code에서 object code로 변환하는 과정을 2pass로 진행
- Pass1: Define Symbols (아래 정보를 담은 intermediate file 생성)
- assembly code의 statement 읽기
- LOCCTR(location counter)을 사용해서 N(byte addressing)으로 3byte씩 주소를 증가시키며 해당 statement에 주소 할당
- 모든 label에 할당된 주소 값을 Symbol table에 저장 (Subroutine, function)
- lable 중복 선언 확인 > 중복 아니면 location counter 계산 > mnemonic code 오타 확인 > symbol table 생성
- 상수 선언, 공간 예약같은 assembler directives 처리 수행 (’RESW', 'RESB’ 등)
- Pass2: Assemble instructions & generate object program
- intermediate file을 입력으로 code 한 줄 읽기
- table을 이용해서 opeartion code을 기계어 opcode로, label을 기계주소로 변환
- pass1에서 끝내지 못한 assembler directives 처리
- object program생성
🔹Data Structures
Operational Code Table (OPTAB)
ADD, STL, COMP 등으로 표현된 opcode를 assembler가 읽고 어떠한 기능의 opcode인지, 기계어로 무엇인지 인식하기 위해 필요한 정보를 모아둠
- mnemonic opcode와 이에 해당하는 machine language
- 만약 더 복잡한 assembler라면 가변 크기나 형식을 가지는 instruction을 포함할 수 있음
- pass1에서는 mnemonic code를 조회하고 검증하는데, pass2에서는 opcode를 기계어로 변환하는데 사용
- 보통 hash table로 구성 (Key: mnemonic code)
- 최소한의 탐색으로 빠르게 탐색
- OPTAB는 준비가 되면 이후에 수정되지 않음
Symbol Table (SYMTAB)
‘FIRST STL RETADR’을 읽고 RETADR이 1033에 위치하는 것, 기계어로 변환할 때 address filed에 1033을 넣어야하는 것을 인식하기 위해 각 label과 operands symbol에 대한 정보를 모아둠
- 각 lable에 대한 이름, 값(주소), flag(오류 조건)
- 종류, 길이 정보 포함 가능
- pass1에서는 lables가 주소와 함께 symbol table에 입력되고, pass2에서는 피연산자 symbols을 table에서 찾아 assembled instruction에 넣을 주소를 얻음
- hash table


( •̀ .̫ •́ )✧