
지금까지는 machine을 위한 특징을 살펴보았고, 지금부터는 ‘사람’을 위한 Assembler에 대해 알아본다.
🔸Machine-Independent Assembler Features
Machine architecture와 관련되지 않은 독립적인 몇 가지 특징은 프로그래머의 편의성 및 SW환경과 같은 문제와 밀접하게 관련되어 있다.
- Literal
- Symbol definitions
- Expressions
- Program Blocks
- Control sections
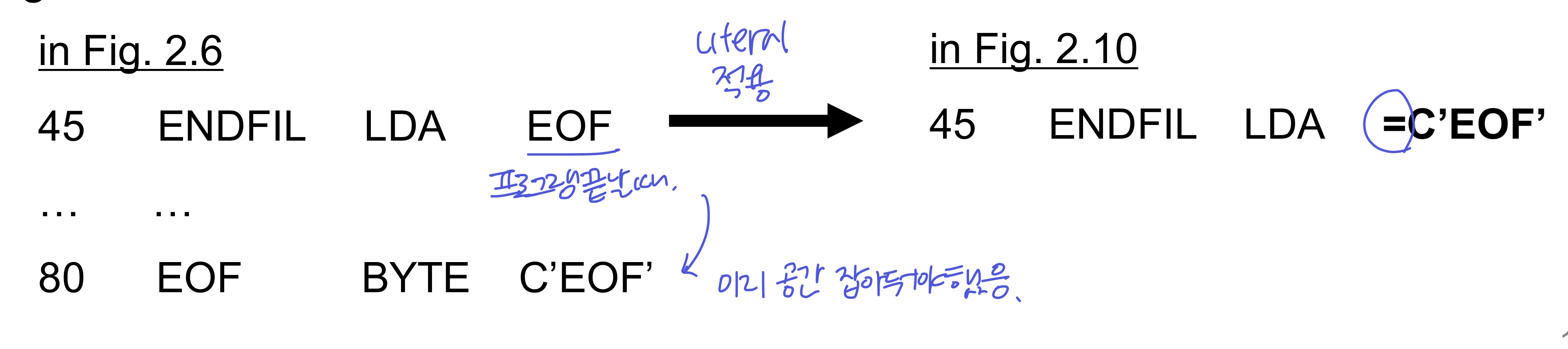
🔸Literals
- 프로그래머가 상수 operand(피연산자)의 값을 instruction의 일부로 작성 → 즉, 명령에서 문자 그대로 명시
- 프로그램 내의 다른 곳에서 상수를 정의할 필요가 없어짐 (상수에 대한 레이블 생성X)
- prefix ‘=’ 뒤에 BYTE 문에서와 동일한 표기법 사용
Literals vs Immediate Operand
Literals은 immediate와 비슷하게 생겼지만, Literal은 메모리 공간을 사용하고, immediate는 사용하지 않는다.
- immediate addressing에서 피연산자 값은 machine instruction의 일부로 조립 → immediate value 자체가 address field에 그대로 들어감
- address filed는 15bit이므로 그 이상의 값을 넣을 수 없음
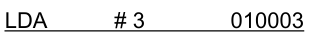
- address filed는 15bit이므로 그 이상의 값을 넣을 수 없음
- Literals은 어셈블러가 다른 메모리 위치에서 지정된 값을 상수로 생성 → 상수의 주소가 address field에 들어감
- literal값을 메모리에서 가져옴
- EOF와 관련된 레이블을 만들지 않았지만(공간 할당X), 어셈블러가 Literal인걸 보고 해당 공간을 만들고 참고하여 가져옴
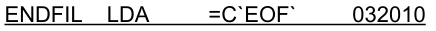 (24bit의 ‘EOF’의 주소를 넣음)
(24bit의 ‘EOF’의 주소를 넣음)
Literal Pool
그럼 어셈블러는 Literal값의 메모리를 어떻게 잡을까?
- 어셈블러는 프로그램에 사용되는 모든 Literal operand를 하나 이상의 Literal pool로 수집 (주소값 할당)
- 기본 위치는 프로그램의 끝으로, END문 뒤에서부터 수집
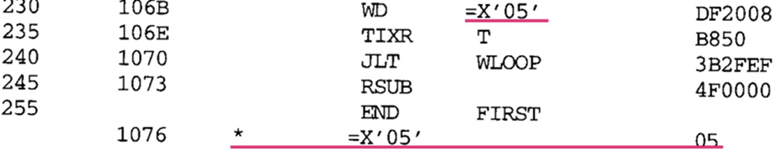
- 기본 위치는 프로그램의 끝으로, END문 뒤에서부터 수집
- 만약, Literal pool을 프로그램의 다른 위치에 선언하고 싶다면, 어셈블러 directive인 LTORG를 사용
- 어셈블러가 LTORG를 만나면, 이전 LTORG(또는 프로그램 시작) 이후 사용된 모든 Literal operand를 포함하는 풀을 생성

- 어셈블러가 LTORG를 만나면, 이전 LTORG(또는 프로그램 시작) 이후 사용된 모든 Literal operand를 포함하는 풀을 생성
- Literal Pool을 나누는 이유는?
- 만약 모든 Literal operand가 END이후에 위치하는데 프로그램 초반에 Literal을 사용하면 disp를 12bit로 채우지 못할 수 있음
- 그래서 Literal 명령어와 변수는 가까이 위치시켜야 함
- Literal이 중복되는 경우
- 대부분 어셈블러는 중복된 Literal을 인식하고 지정된 데이터 값의 복사본 하나만 저장
- 동일한 Literal operand ‘=X’05’’가 사용되지만, 이 값을 가지는 데이터 영역은 하나만 생성 → 두 명령어는 Literal pool의 동일한 주소 참조

Assembler handle
어셈블러가 literal operand를 어떻게 다룰까?
- LITAB(Literal Table)라는 자료구조를 사용
- 테이블에는 사용된 각 literal에 대한 이름, 피연산자 값, 길이, 풀에서 할당된 주소를 포함
Pass1. 각 Literal operand 인식
- 어셈블러는 지정된 literal 이름을 LITAB에 검색하고, 만약 없다면 추가 (아직 주소 할당X)
- 만약 코드가 LTORG 또는 END이면, 각 literal에 주소를 할당
Pass2. 각 Literal operand를 해당 주소로 변환
- object code 생성에 사용할 operand 주소는 LITAB를 검색하여 얻음
- 그리고 literal의 데이터값이 object program에 들어감
🔸Symbol Definitions (EQU)
- EQU(equate): Symbol을 정의하는 어셈블러 directive
- #define과 유사
- (symbol) EQU (value) → #define (symbol) (value)

- 어셈블러가 EQU문을 만나면 MAXLEN을 SYMTAB에 입력
- EQU로 선언한 Symbol을 만나면 SYMTAB에 검색하고, 이 값을 해당 instruction의 operand로 사용
- (symbol) EQU (value) → #define (symbol) (value)
- 결과로 나오는 object code는 원본과 동일 → 즉, 기호 대신 값을 사용
- 숫자 값 대신 기호 이름을 설정하여 가독성 향상 (ex-PI)
- 이해하기 쉬울 뿐 아니라, Symbol의 값을 바꾸는 것이 더욱 간단
- 또 다른 용도로, 레지스터의 mnemonic 이름을 정의
- 레지스터가 많은 경우, 레지스터에 대한 mnemonic 이름을 사용하는 것이 도움이 될 수 있음

- 레지스터가 많은 경우, 레지스터에 대한 mnemonic 이름을 사용하는 것이 도움이 될 수 있음
Restrction in Symbol definitions
- EQU 오른쪽에 사용되는 모든 숫자 값(변수, 기호)은 프로그램에 미리 정의되어 있어야함
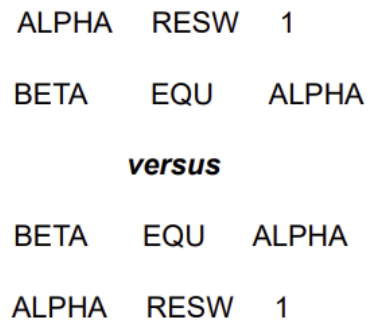
- 위에 두 줄은 ALPHA가 미리 정의된 상태로, BETA를 ALPHA의 Symbol definition으로 사용 가능
- 반면에, 밑에 두 줄은 ALPHA가 정의되지 않았으므로 오류 발생 (모든 기호들은 PASS1에서 정의되야하는데, 어셈블러가 EQU문을 만나고 ALPHA를 BETA로 정의하려하는데 ALPHA가 아직 뭔지 몰라서 정의 불가능)
🔸Expression
어셈블러에서는 Expression(수식)을 사용해서 주소나 값을 계산할 수 있다. 이는 메모리 주소를 유동적으로 관리하고, 코드의 재사용성을 높이는데 중요한 역할을 한다.
- 어셈블러는 label, literal 등 단일 피연산자가 허용되는 곳에 Expression을 사용할 수 있음
- 각 expression은 어셈블러에 의해 평가(계산?)되며 주소나 값을 생성해야 함
- 위의 예시에서 EQU의 피연산자 위치에 BUFEND-BUFFER라는 수식이 들어감
- arithetic expressions(산술 표현식)
- 어셈블러는 +, -, *, /등의 operator(연산자)를 사용하여 만들어진 산술 표현식을 허용
- 이러한 연산자는 상수, 사용자 정의 기호, 특별한 항(아래 설명)을 포함할 수 있음
- 위의 예시에서 BUFEND-BUFFER수식은 ‘-’를 사용하여 만들어진 산술표현식
- 특별한 항
- 예를 들어, 현재의 위치 카운터를 나타내는 값을 ‘’로 표시 (operand에 ‘’가 단독으로 나오면 이 위치의 주소를 의미하는 것)
- BUFEND에 현재 LOC값 저장

Absolute/Relative expression
Expression은 산출되는 값의 유형에 따라 분류할 수 있다.
- Absolute expressions: 프로그램 위치와 무관
- Relative expressions:프로그램 시작 위치와 연관
example (EQU에 의해 정의된 symbol은 절대적이거나 상대적일 수 있다)
- 16진수 1000: Loc열의 다른 대부분 항목과 다르게 주소를 나타내는게 아니라 symbol값을 나타냄
- MAXLEN: 시작 주소가 바뀌어도 4096이라는 값을 유지 → Absolute expression
- BUFEND, BUFFER: 시작 주소에 따라 값이 바뀜 → Relative expression
- 근데 S를 프로그램의 시작 주소라고 한다면 (BUFEND+S)-(BUFFER+S)로 표현할 수 있어서 S가 식에서 전부 사라짐 → 시작 주소에 대한 정보 필요 X → Absolute expression
Determine type of expression
위처럼, expression의 유형을 결정하려면 프로그램에 정의된 모든 symbol의 유형을 추적해야한다.
- 이를 위해 SYMTAB에 값 뿐만 아니라 값의 유형(절대/상대)를 나타내는 플래그가 필요 → type field에 표시
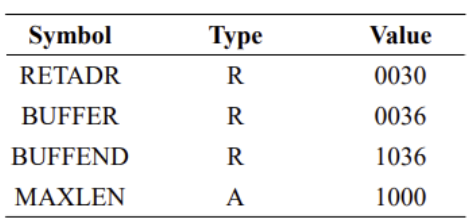
- format4 instruction의 operand는 relative value를 가질 수 있고, 이 값은 loader가 relocation할 수 있도록 수정되어야 함
🔸Program Blocks
지금까지는 어셈블리되는 프로그램이 하나의 단일 단위로 처리되었다. 서브루틴, 데이터 영역등이 있긴하지만, 어셈블러에 의해 하나의 entity(독립체)로 처리되어 object code의 single block이 생성되었다.
많은 어셈블러는 source code와 object program을 유연하게 처리할 수 있는 기능을 제공한다.
- Program Blocks: single object program 단위로 재배치된 code segments들
- machine insturctions과 데이터를 소스 코드의 순서와 다르게 메모리에 로드할 수 있음
- Control sections: independent object program 단위로 번역되는 segment들 (뒤에 나옴)
- object program의 독립적인 부분들은 identity를 유지하고 lodader가 분리하여 처리
- 어셈블러 directive USE는 소스 프로그램의 어떤 부분이 어떤 블록에 속하는지를 나타냄
- USE문이 없다면, 전체 프로그램은 단일 블록으로 간주
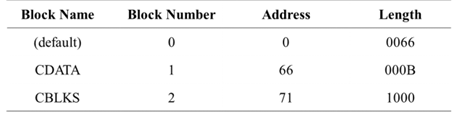
example
- 이 예제에서는 세 가지 프로그램 블록으로 나눔(사용자 맘대로 기준)
- Excutable instructions (unnamed block) → 0
- CDATA (길이가 짧은 데이터 영역) → 1
- CBLKS (더 큰 메모리 블록으로 구성된 데이터 영역 → 2
- 각 프로그램 블록은 각각 relative address 공간을 가짐
- 각 블록마다 starting address가 다름
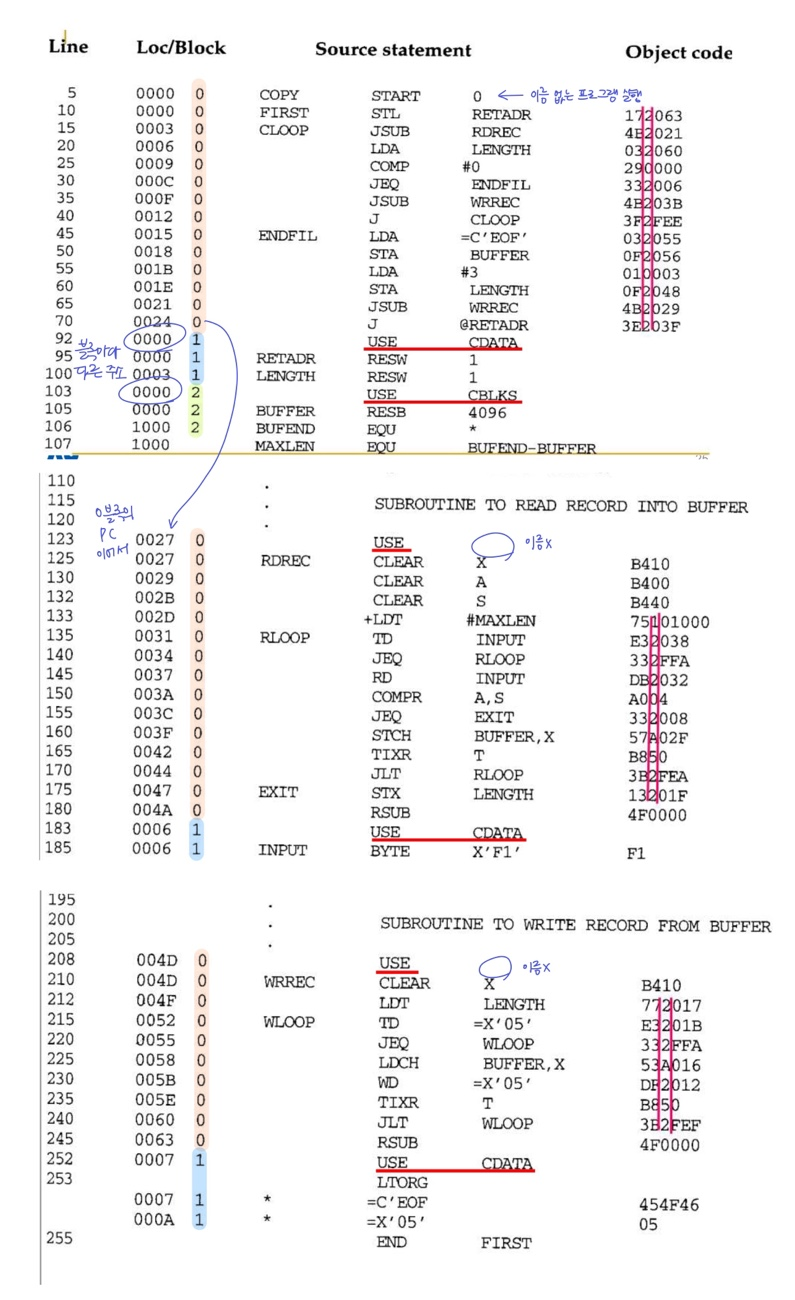
- 각 블록마다 starting address가 다름
Pass1:
- 각 프로그램에 대해 LOCCTR(location counter) 유지
- 각 label은 자신이 해당한 블록의 시작 주소를 기준으로 상대 주소가 할당
- SYMTBL에는 각 symbol의 블록 번호 저장
- Block table에는 각 블록의 시작 주소와 길이 저장
Pass2:
- 번역 과정에서 어셈블러는 각 symbol의 주소를 object프로그램의 시작 주소를 기준으로 계산
- symbol의 블록 내 상대주소 + 해당 블록의 시작 주소
- ex) INPUT의 주소 = 6 + 66 = 6C
Object code
위와 같은 과정을 어셈블리 코드의 순서와 다르게 object code는 각 block의 순서로 배열된다. (default→CDATA→CBLKS)
- 블록이 바뀔 때 새로운 text record를 출력
- 다른 기존 블록으로 돌아가는 경우, 기존 text record에 이어서 하거나 새로 만들어서 하거나 상관 없음


Text record & Load
- object program의 text record가 주소 순서와 다르게 생성되더라도 문제X
- loader가 각 record에서 지정된 주소에 따라 올바르게 데이터를 배치하기 때문
- 로딩이 완료되면, 각 블록에서 생성된 코드는 아래 범위의 상대 주소를 차지
- default: 0000~0065
- CDATA: 0066~0070
- CBLKS: 0071~1070
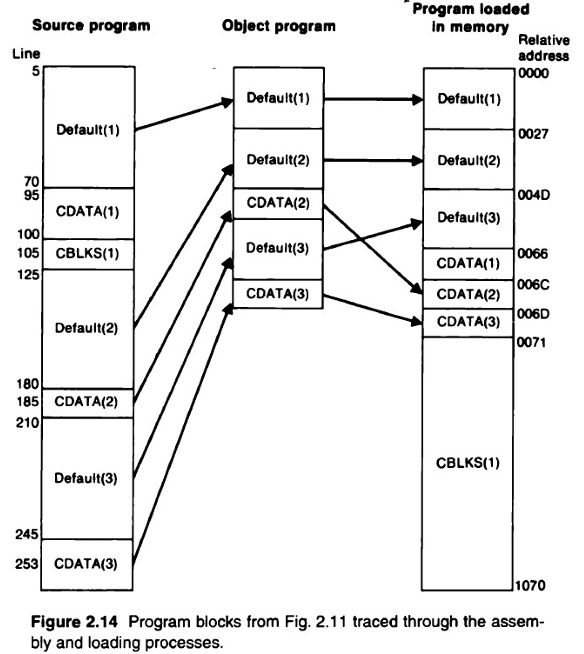 즉, 어셈블리 코드에서 흩어져있던 각 블록들을 메모리 상에서 블록별로 모을 수 있음
즉, 어셈블리 코드에서 흩어져있던 각 블록들을 메모리 상에서 블록별로 모을 수 있음
Advantages
Program blocks은 모순되는 목표를 이룰 수 있다.
- 특정 순서에 따라 프로그램을 블록으로 구분
- 위 예시에서는 가장 큰 버퍼 영역이 object program의 가장 끝에 위치 → 프로그램 사이에 위치했다면 해당 영역 앞과 뒤에 위치한 구문들이 멀어짐 → 결국 extended format, base-relative를 더욱 빈번하게 사용
- Literal Pool을 배치하기 쉬움 (literal을 CDATA 블럭에 넣기만 하면 됨)
- 데이터 영역을 퍼트릴 수 있음
- 가독성을 높이기 위해 각 블록에 사용되는 변수들을 근처에 배치 (데이터 영역이 참조되는 구문에 가까울수록 가독성 증가)
즉, 모순되는 목표란 “소스코드에서는 데이터 영역을 흩어지게 하여 가독성을 높이고, Object code에서는 메모리 상에서는 데이터 영역을 한 곳에 모아 프로그램의 성능을 높이기” 이다.
🔸Control Section
Control section(CS)은 어셈블리 이후 프로그램의 일부로, 각 CS는 다른 섹션과 독립적으로 로드되거나 재배치될 수 있다.
- 프로그램의 서브루틴이나 하위 부문에 서로 다른 CS 사용
- 프로그래머는 각 CS를 개별적으로 assemble, load, manipulate할 수 있음
- 이를 통해 프로그램의 유연성 증가
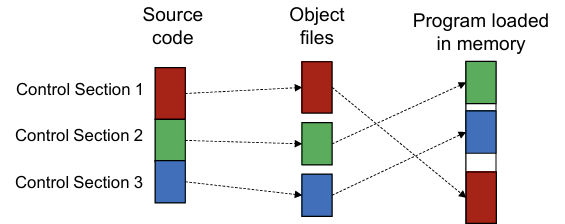
약간… 라이브러리 코드 링크하는 것 처럼… 헤더파일 include하는 것 처럼..
🔹Program Linking
CS가 프로그램의 논리적으로 관련된 부분을 형성할 때, 그것들을 linking할 수 있어야한다. 즉, 한 CS의 instruction은 다른 섹션에 있는 insturction 및 데이터를 참조할 수 있어야한다. → external reference(외부 참조)
- Loader가 external reference에 대한 정보를 생성하여 어셈블러에게 다른 CS가 어디에 있는지 알려주고 link를 할 수 있도록 함
External reference
어셈블러 directives에 의해 외부 참조가 처리된다.
- CSECT: 새로운 CS의 시작을 알림
- 어셈블러는 program block과 마찬가지로 각 CS마다 독립적인 LOC을 설정 → CSECT하면 starting address 0000
- EXTDEF: 현재 CS에 정의된 symbol, 다른 섹션에서 사용하기 위해
- EXTREF: 다른 곳에서 정의된 symbol을 사용하기 위해
다른 섹션의 symbol을 사용하려면, 해당 symbol이 있는 섹션에서 EXTDEF를 사용해 외부에서 사용할 수 있게끔 알려야하고, 해당 symbol이 필요한 섹션에서는 EXTREF로 내가 다른 섹션에 있는 symbol을 여기서 사용하겠다라고 알려야한다.
example
- CSECT를 이용하여 프로그램을 COPY, RDREC, WRREC 3개의 CS로 나눔
- COPY SC에서 EXTDEF로 BUFFER, BUFEND, LENGTH를 다른 섹션에서 참조할 수 있게하고, EXTREF를 이용해 외부의 RDREC와 WRREC를 참조 가능
- RDREC와 WRREC에서는 EXTREF를 이용해 COPY 섹션의 BUFFER BUFEND, LENGTH등을 참조
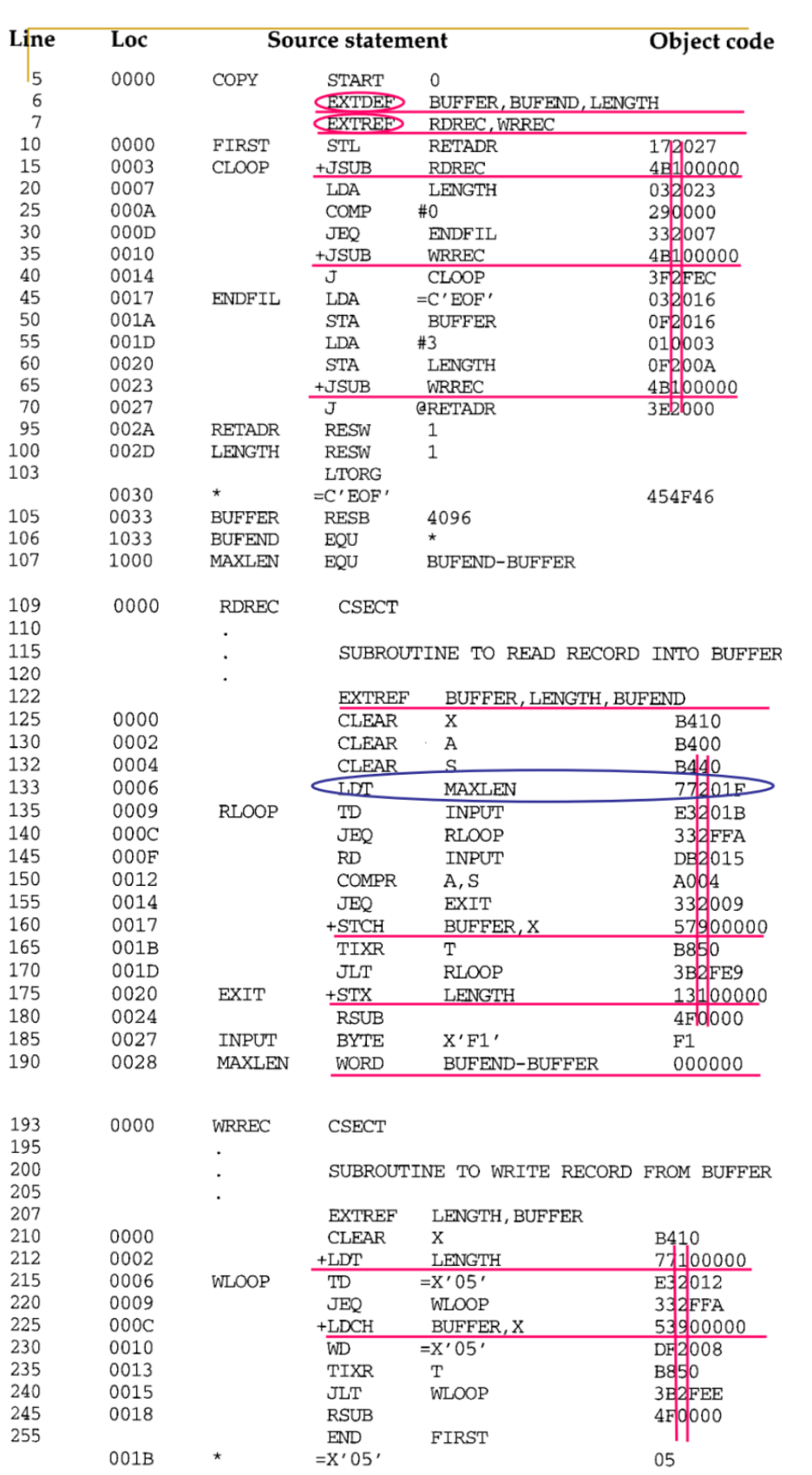
Object code with External references
어셈블러는 EXTREF로 사용하는 symbol의 위치를 알 수 없어서 object code에 주소를 넣을 수 없다. 그래서 0주소를 넣고 loader에게 보내고, 이후 loader가 적절한 주소를 넣는다. 이때, format4 instruction을 사용하여 실제 주소를 넣을 공간을 제공해야한다. 메모리 어디에 로드될지 모르기 때문에 메모리 전체를 표현할 수 있어야한다.
이때, format4 instruction을 사용하여 실제 주소를 넣을 공간을 제공해야한다. 메모리 어디에 로드될지 모르기 때문에 메모리 전체를 표현할 수 있어야한다.
New Record types
어셈블러는 loader가 필요한 위치에 적절한 값을 넣을 수 있도록 필요한 정보를 object program에 포함해야한다. 그래서 새로운 record가 필요하다.
- Define record: EXTDEF에 의해 CS에 정의된 symbol용으로, 해당 CS에 있는 symbol의 relative address를 나타냄
- Col. 1: D
- Col. 2-7: 해당 CS에 정의된 symbol의 이름
- Col. 8-13: 해당 CS에서의 상대 주소(16진수)
- Col. 14-73: 다른 symbol에 대해 Col. 2-13의 정보 반복
- Refer record: EXTREF에 의해 CS에서 사용되는 외부 symbol용으로, 주소 정보가 없음
- Col. 1: R
- Col. 2-7: 해당 CS에서 언급한 symbol의 이름
- Col. 8-73: 다른 external reference symbol 이름
- Modification record (이전 Relocation때 나왔던 record로 Col.10-16이 추가)
- Col. 1: M
- Col. 2-7: 수정할 address field의 시작 주소(16진수)
- Col. 8-9: 수정할 address field의 길이, half-bytes(16진수)
- Col. 10: 수정 플래그(+ or -)
- Col. 11-16: 표시된 필드에 값을 추가하거나 뺀 external reference symbol
→ 이렇게 하면 프로그램이 여러개의 섹션으로 나눠져도 loader가 필요한 external section의 정보가 메모리 어디에 위치하는지 알 수 있게 됨
example
- 3개의 CS로 나눠져서 object code가 3개의 프로그램으로 분리된 것처럼 보임
- COPY섹션의 define record에는 BUFFER, BUFFEND, LENGTH와 각각의 상대주소가 존재하고, refer record에는 해당 섹션에서 참조할 외부 symbol의 이름이 존재
- loader는 modification record를 참고해서 00000으로 바꿔놨던 address field값들을 변경


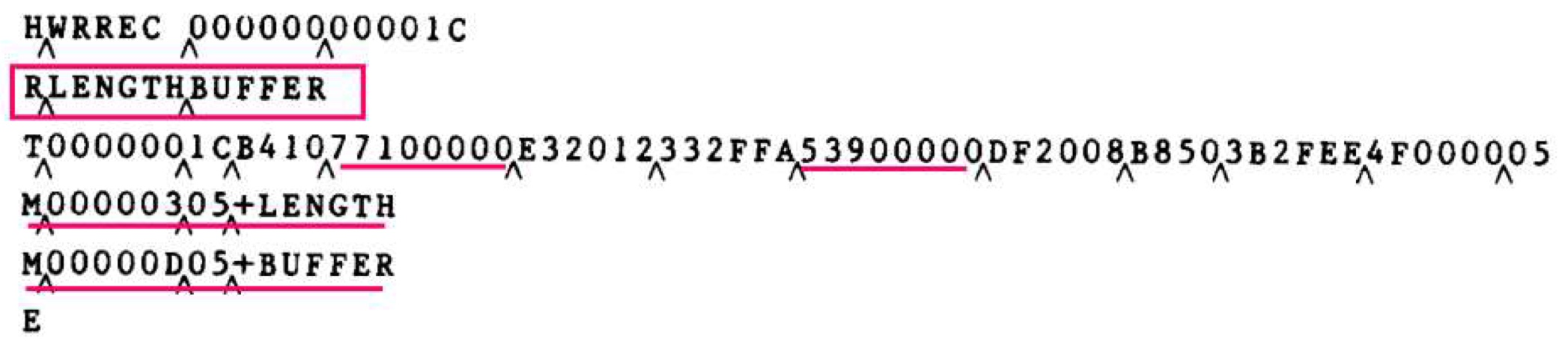
- loader는 modification record를 참고해서 00000으로 바꿔놨던 address field값들을 변경
Loader
그래서~~ 로더가 모든 external symbol에 대해 해야할 일은
- 정의된 레코드에서 상대주소 찾기
- symbol이 정의된 CS의 시작 주소 추가하기
- field 수정하기
🔸1-pass Assembler
지금까지는 2-pass 어셈블러에 대해 다뤘다. 하지만 이것이 어셈블러를 설계하는 유일한 방법은 아니고, 1-pass나 multi-pass로도 설계할 수 있다.
그 중 1-pass 어셈블러는 소스코드를 한 번만 스캔하기 때문에 오버헤드를 줄여주지만, 스캔 도중 생성된 object code를 patch(수정)해야하는 경우가 있다.
Forward reference
- 1-pass를 위해서는 Forward reference(전방 참조)에 대한 문제를 극복 필요
- 이를 위해 모든 데이터 항목 정의는 참조 명령보다 먼저 배치
- 하지만 모두 이렇게 해결할 수 없음
- 아래 예시의 빨간 점선처럼, label에 대한 전방 참조는 피할 수 없음
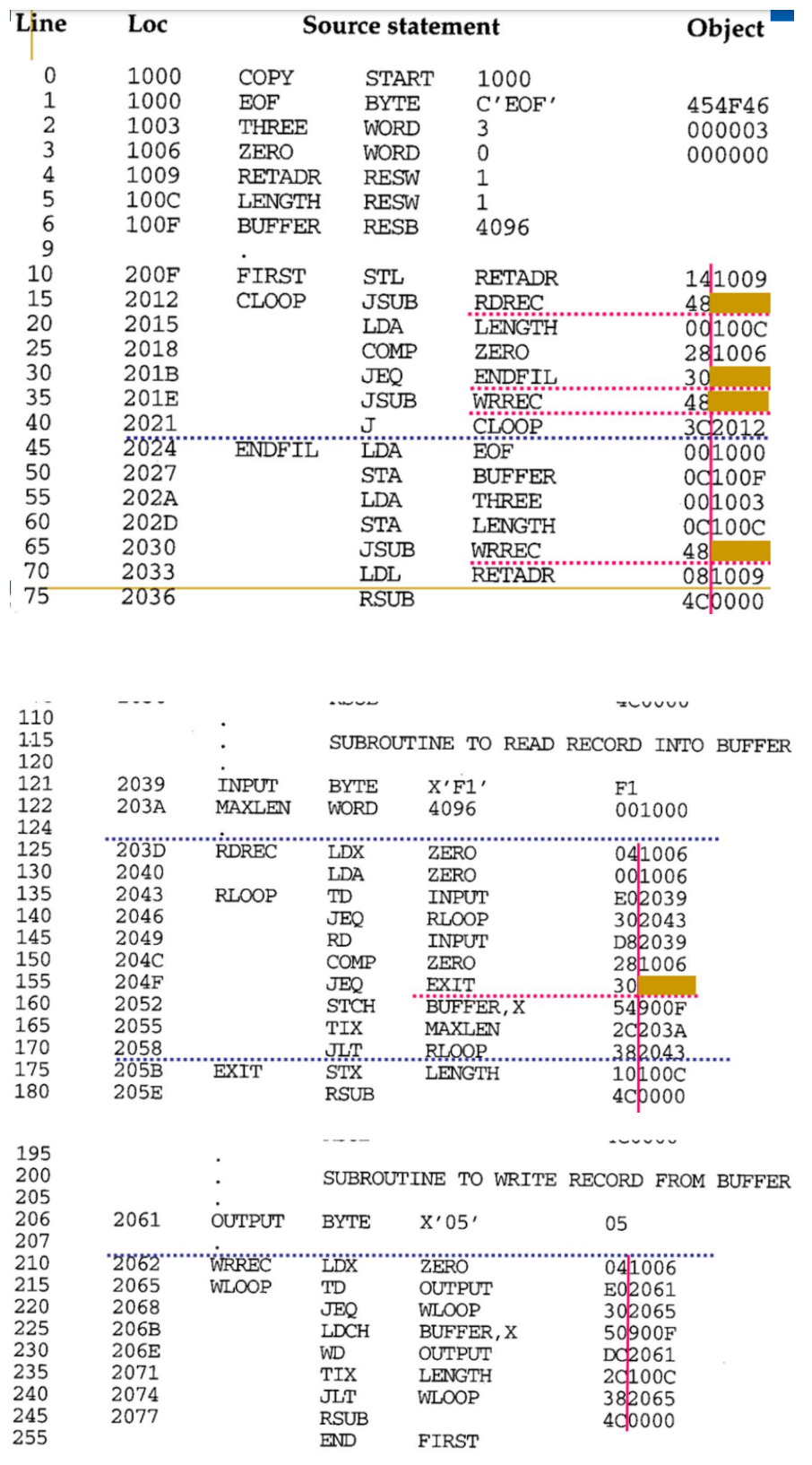
그렇다면…… 1-pass 어셈블러는 이걸 어떻게 해결했을까?!!?!
1-pass 어셈블러에는 두 가지 타입이 존재한다. 각각 위 문제를 어떻게 해결하는지 살펴본다.
Type 1: “Load-and-Go”
- 실행 중에 메모리에 object code를 직접 생성 (HDD, SSD와 같은 2차 저장소에 작성하지 않고)
- 메모리의 속도가 2차 저장소의 속도보다 훨씬 빠르기 때문에 어셈블리 과정의 효율성을 높임
- object program이 작성되지 않고, Loader가 필요 없음
- 전방참조를 해결하기 위해
- 정의되지 않은 symbol과 이 symbol을 참조하는 field 주소(이 symbol을 부른 instruction의 주소)와 함께 SYMTAB에 저장
- 나중에 symbol이 정의되면 SYMTAB에서 참조했던 주소를 찾아 올바른 주소로 field를 수정
- 정의 전에 여러번 참조된다면, linked list를 통해 참조 주소를 이어서 연결
- 즉, 한 번의 pass에서 SYMTAB를 만들어감
메모리에 적힌 Object code와 Symbol table
- Line 40까지 스캔한 상황
- RDREC, WRREC, ENDFIL이 정의되기 전에 참조했기 때문에 object code의 주소값 부분이 비어있음
- symbol table에서는 해당 symbol을 참조하는 위치를 linked list형식으로 연결
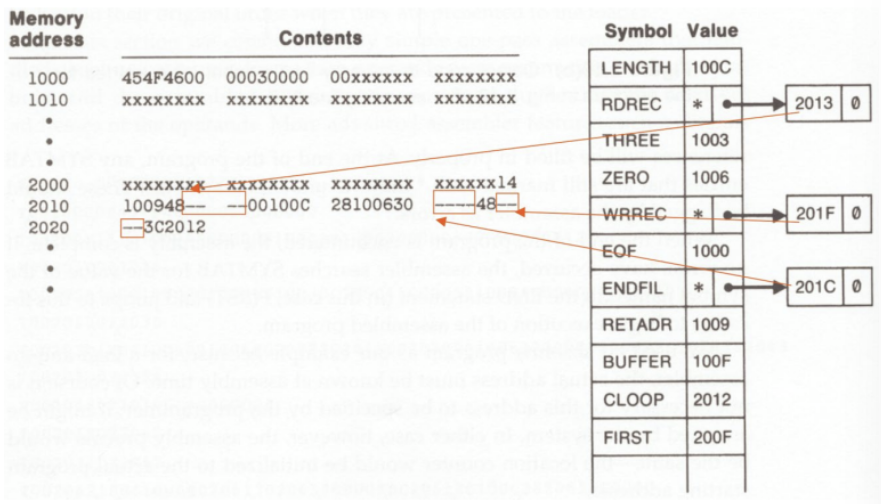
- Line 160까지 스캔한 상황
- ENDFIL과 RDREC가 선언되었고, linked list에 적혀있던 참조 위치로 가서 object code의 주소값 부분에 symbol의 주소를 넣어줌
- 아직까지 선언되지 않았는데 또 참조된 경우, linked list에 이어서 해당 위치를 연결
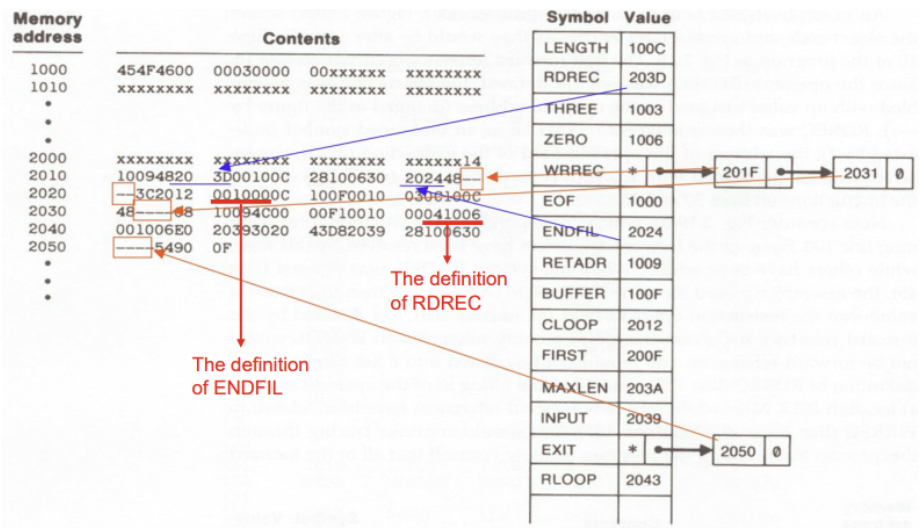
Type 2
- 메모리가 아닌 디스크에 object program을 작성
- 나중에 실행 가능하도록 일반적인 object program 생성
- Loader 필요
- 전방 참조를 해결하기 위해
- 우선 type1처럼 linked list에 참조 위치 기록
- symbol이 정의된다면 새로운 text record를 생성 (정확한 피연산자 주소와 함께)
- 이후 로드될 때, loader에 의해 올바른 주소가 들어감
디스크에 적힌 Object program
- 두번째 text record은 line 10-40에서 생성된 object code
- 전방참조로 주소를 모르는 경우는 0000으로 채워져 있음
- 세번째 text record는 line 45에서 ENDFIL symbol의 정의가 발견돼서 어셈블러가 새로 만든 text record
T.00201C.02.2024→ine30의 JEQ의 피연산자 address field의 주소 201C(위치)에 / ENDFIL의 주소 2024(값)를 로드하도록 지정
- symbol정의로 만들어진 새로운 text record는 어떻게 구분할까?
- symbol정의로 만들어진 text record의 주소는 이미 위에 있는 text record에 있는 주소이다. 그래서 알 수 있는 듯?
