
💡14장 목표
- 파일 시스템 내부 구조
- 블록 할당 및 free block 관리
- 성능
- 에러 처리
- WAFL
🔹File-System Structure
파일 시스템은 데이터를 쉽게 저장, 위치 지정, 검색 등을 할 수 있도록 해준다.
- 파일 구조는 logical storage unit → 연속적 논리 공간
- 저장소인 디스크는 섹터들의 블록으로 구성되며 블록 단위로 I/O 전송
- File control block(FCB): file table block으로, unix와 linux에서는 inode라고 함
- Device driver: 파일 시스템과 하드웨어 간의 인터페이스 역할
File system layer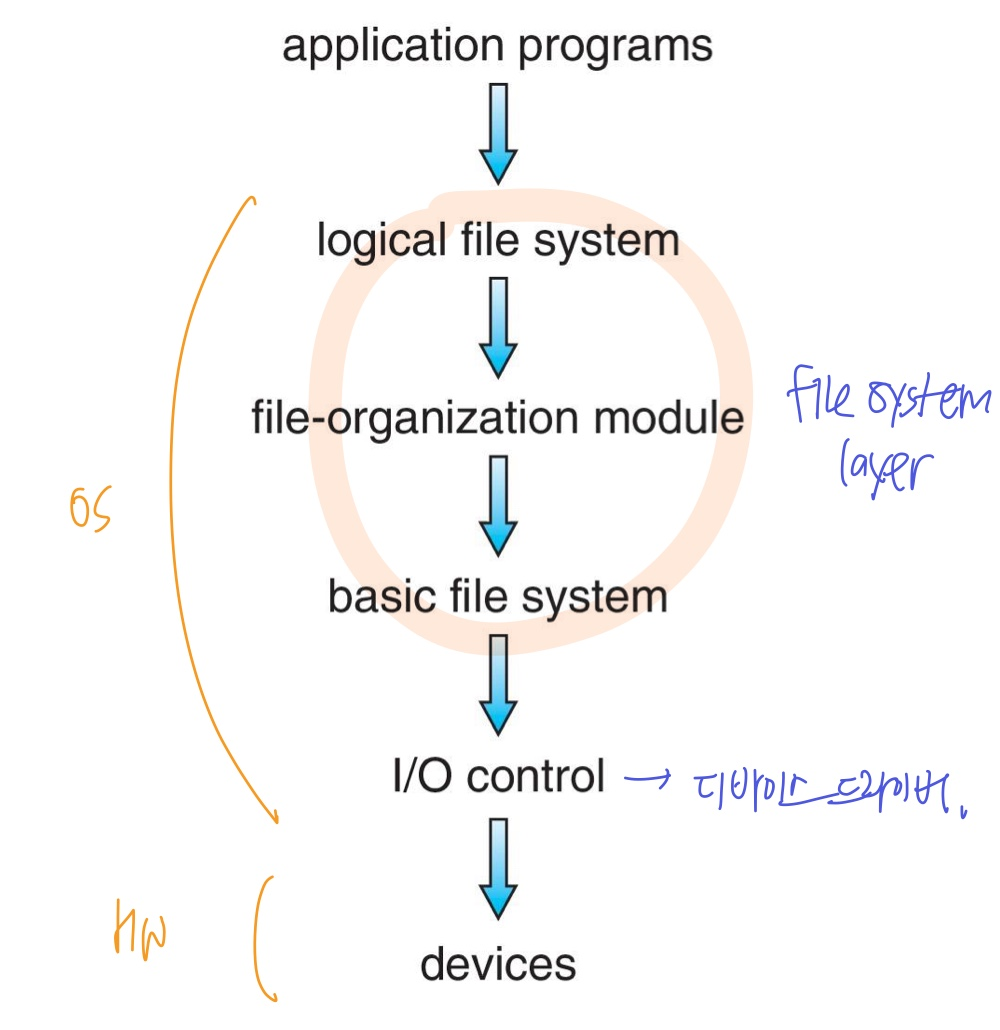
-
Device dreiver(I/O control)
- 파일 시스템 레이어는 아니고 I/O 영역이다.
- 디바이스 컨트롤러에게 명령을 내린다.
- ex) "read drive1, cylinder 72, track 2, sector 10, into memory location 1060”
-
Basic file system
- “retrieve block 123”과 같은 명령을 받아 해당 블록을 읽어옴
- Buffer/Caches: CPU와 디스크 사이 버퍼를 두어 속도 및 형식 차이 보완하고 메모리에 캐싱하여 자주 사용 데이터 저장 및 접근 속도 높임
-
File organization module
- 논리 블록을 물리 블록으로 변환
- free space 관리
- 디스크 할당 관리
-
Logical file system
- 파일 이름을 파일 번호, 핸들, 위치로 변환 (file control block(inode)으로)
- 디렉토리 관리 및 접근 제어
이러한 계층 구조 방식은 단순화(추상화)를 통해 복잡성을 줄인다. 하지만 계층화로 인해 성능이 저하된다.
OS 내에 다양한 파일 시스템이 존재한다. UFS, extended file system, ZFS, GoogleFS 등… 이런 파일 시스템에서 공통으로 사용되는 특징들을 알아본다~
🔹File-System Operation
파일 시스템 작업은 system call(API)로 시작되는데, 이러한 호출의 기능이 어떻게 구현하는가
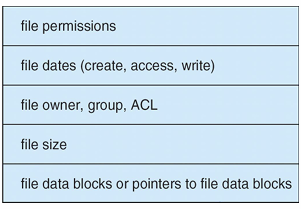
- Boot control block: OS boot 관련 정보를 가지는 블록
- Volume control block(superblock 또는 master file table): volume 정보를 가지는 블록
- 블록 총 수, free 블록의 수, 블록 크기, free 블록 포인터 등
- Directory 구조: 파일 이름, inode number 등을 가짐
- FCB(file control block): 각 파일마다 존재하며, 파일의 세부 정보 등을 포함
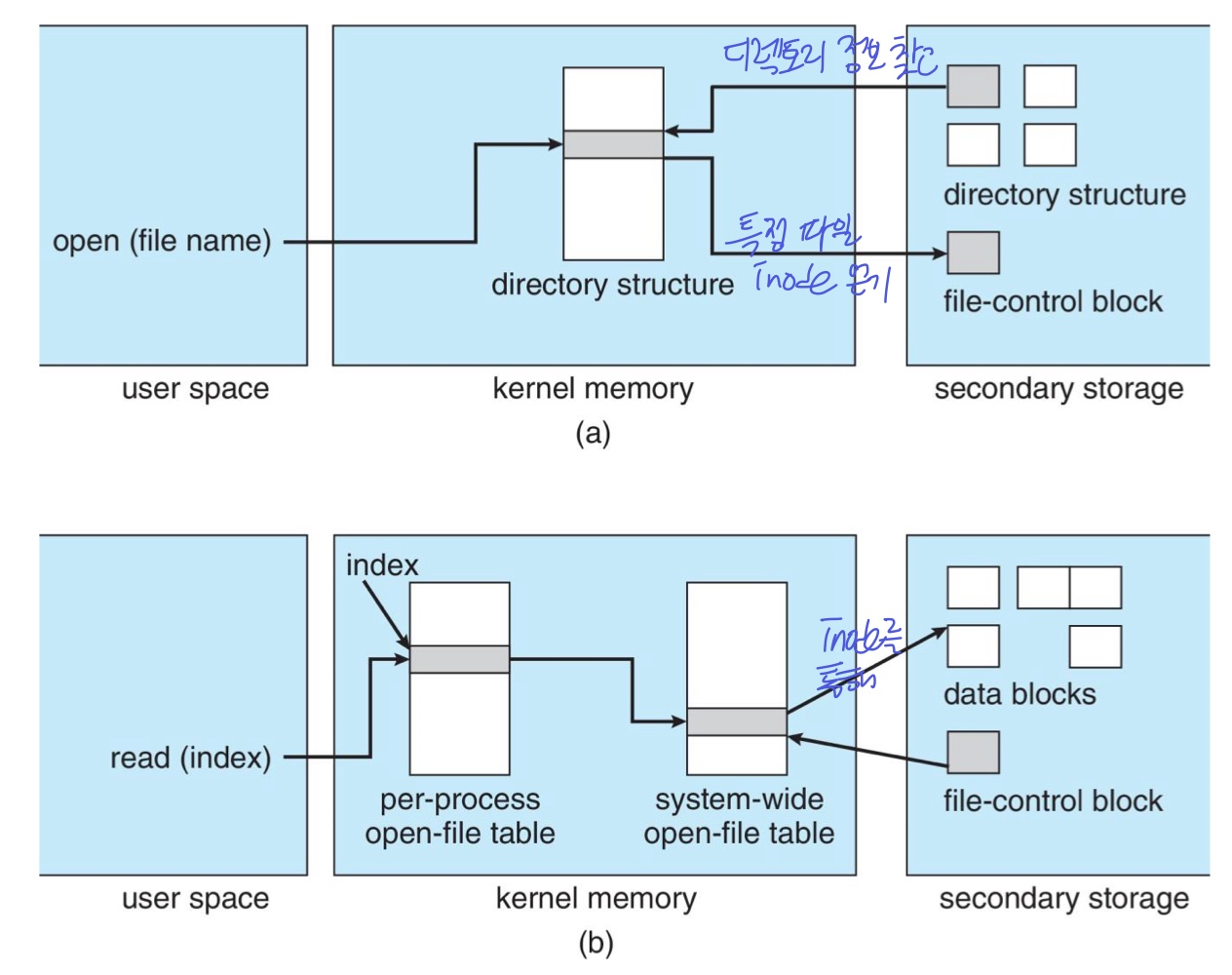
In-Memory File System Structure
디스크에 있는 파일에 빠르게 접근할 수 있도록, 파일 관련 정보를 메모리에 올리는 과정
- Mount table: 파일 시스템이 어느 루트에 마운트 되어있는지
- Open file table
- system wide하게 열린 파일의 FCB 정보 등을 가지고 있는 open file table이 있고
- 각 프로세스는 system wide open file table의 적절한 항목에 대한 포인터를 포함하는 프로세스별 open file table을 가진다.
- open file table에 열린 파일에 대한 PCB가 올라와있으면 더욱 빠르게 inode를 얻어 블록에 접근할 수 있다.
🔹Directory Implementation
디렉토리를 구현하는 방법
-
Linear list
- 파일 이름과 데이터 블록에 대한 포인터(inode)를 일차원 리스트로 가짐
- 구현 간단
- 선형 검색 방식으로 파일을 찾음
- 근데 파일 수가 많아져서 테이블이 커지면 검색 시간 증가
-
Hash table
- 해시 함수를 사용해서 파일 이름을 해시 값으로 변환하여 이를 인덱스로 사용
- 만약 해시 값이 같다면 linked list로 관리
- 검색 시간 단축
🔹Allocation methods
파일이 저장 공간(블록)을 할당받는 방법
1. Contiguous allocation
- 연속적인 공간 할당
- 파일 접근 속도가 빨라 성능 우수 (random access에도 우수한 성능)
- 디렉토리에는 파일 이름과 시작 위치 및 길이 정보를 가짐
- 물리 주소 = 논리 주소를 블록 크기로 나눠서 Q번째 블록의 R번째 위치
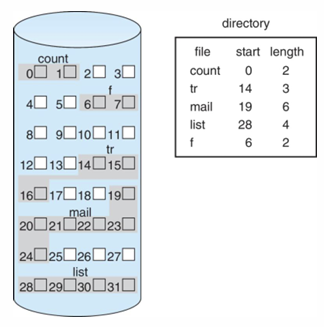
- 물리 주소 = 논리 주소를 블록 크기로 나눠서 Q번째 블록의 R번째 위치
- 하지만 external fragmentation 발생, 새로운 공간 찾기 어려움
- 이를 해결하기 위해 fragmentation을 모아 사용하는 compaction 필요
- Extent-based system: 보완된 contiguous 할당 방법으로, A 파일에 contiguous 공간을 할당해주고, 뒤로 다른 파일들이 할당되었는데 A파일 할당 공간을 확장하고 싶은 경우, 꼭 이전 contiguous 공간과 이어지지 않아도 다른 곳에 contiguous 공간을 할당해줄 수 있음
2. Linked allocation
- linked list로 흩어진 공간 할당, 블록 별 linked list
- 각 블록에 한 바이트는 다음 블록의 포인터로 사용
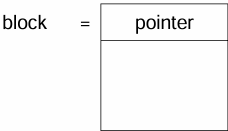
- 디렉토리에는 파일 이름과 시작 위치, 끝 위치 정보를 가짐
- 물리 주소 = 논리 주소를 (블록 크기-1)로 나눠서 Q번째 블록의 (R+1)번째 위치
- 물리 주소 = 논리 주소를 (블록 크기-1)로 나눠서 Q번째 블록의 (R+1)번째 위치
- external fragmentation도 없고 compaction도 필요 없음
- 하지만 접근 속도가 느리다 → random access에 취약
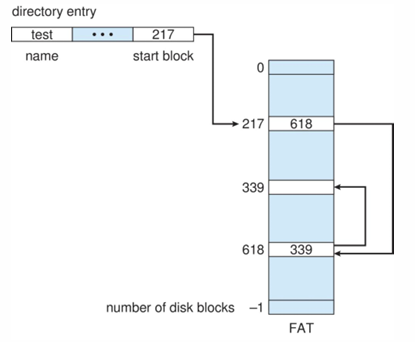
- Free Allocation table: 접근 속도를 빠르게 하기 위해 link 관계만 가진 테이블을 메모리에 올려둔다.
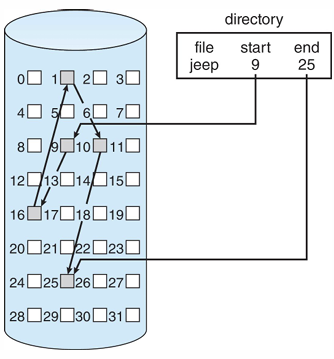
3. Indexed allocation
- 각 파일에 대한 인덱스 블록을 사용해서 관리 (각 블록의 포인터를 가리킴)
- 디렉토리는 파일 이름과 시작 위치 정보를 가진다. 시작 위치를 보고 해당 인덱스 블록에 접근
- 물리 주소 = 논리 주소를 블록 크기로 나눠서 Q번째 블록(index table의 Q번째)의 R번째 위치
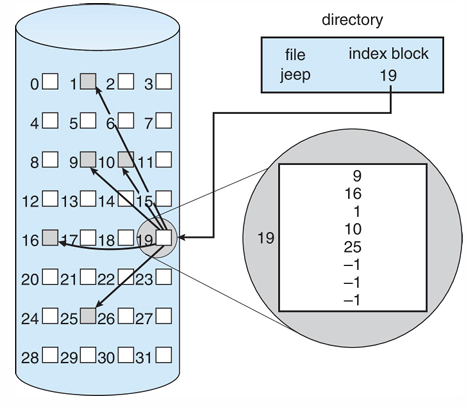
- 물리 주소 = 논리 주소를 블록 크기로 나눠서 Q번째 블록(index table의 Q번째)의 R번째 위치
- 속도가 빠르다.
하지만, 인덱스 블록도 하드디스크에 있기 때문에 2번 접근하는 문제가 있다. 게다가 파일이 커지면 하나의 인덱스 블록으로 부족할 수 있다.
- 인덱스 블록들을 연결(Link blocks of index table)
- 물리 주소 = 논리 주소를 블록 크기^2로 나눠서 Q번째 인덱스 블록의… R을 블록 크기로 나눠서 Q2번째 블록(index table의 Q2번째)의 R2번째 위치
- 인덱스의 인덱스(two-level index)
- 물리 주소 = 논리 주소를 블록 크기^2로 나눠서 Q번째 인덱스의… R을 블록 크기로 나눠서 Q2번째 블록의 R2번째 위치
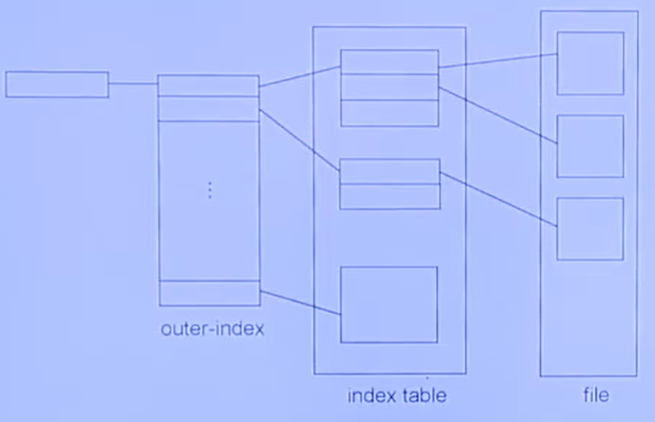
- 물리 주소 = 논리 주소를 블록 크기^2로 나눠서 Q번째 인덱스의… R을 블록 크기로 나눠서 Q2번째 블록의 R2번째 위치
하지만 위 방법은 디스크를 여러번 접근해서 비효율적이다.
-
Combined Scheme(UNIX UFS): 블록 개수가 적을수록 아주 빠르게 접근할 수 있는 방법
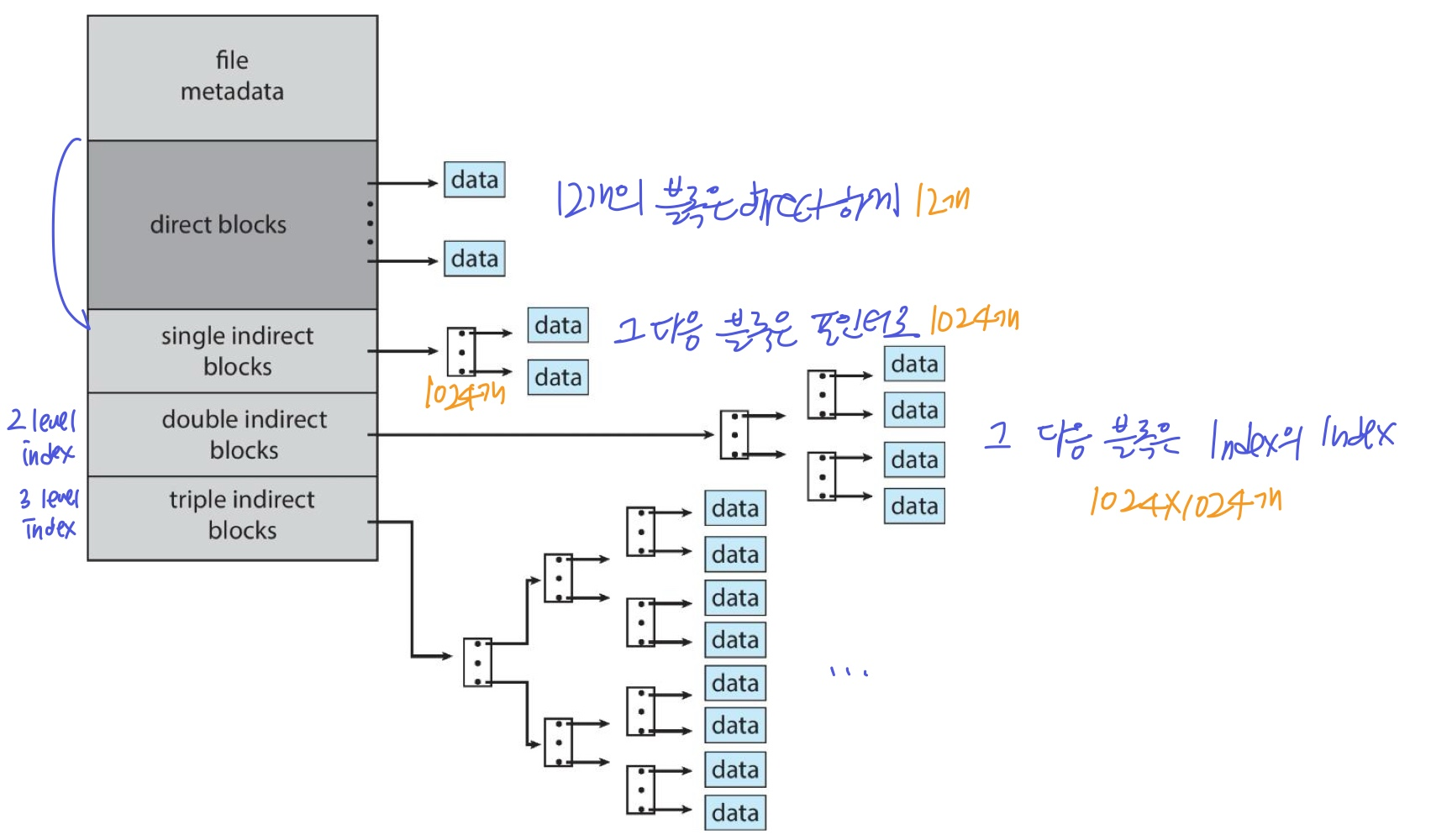
-
Clustering: 여러 블록을 그룹으로 묶어 할당하는 방법, 대량 데이터 전송 시 성능 높일 수 있음 → contiguous의 장점 가져옴
🔹Free-Space management
1. Free space list (Bit map)
- 빈 블록인지 아닌지를 나타내는 한 비트를 나타내는 리스트 (빈블록이면 1)
- 빈 블록 수 계산 (1word = 4bit = 4block)

- Bit map의 크기 → word 단위로 표현해서 크기 줄이기

2. Linked list (Free list)
- 빈 블록을 linked list로 나타낸다.
- 앞에서 부터 차례대로 (보통 free는 앞에서부터 사용함)
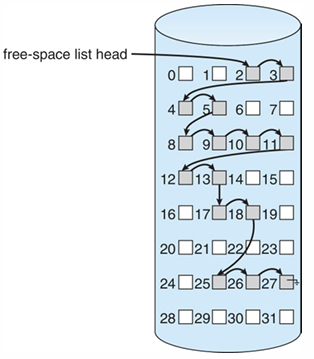
블록을 개별적으로 관리하면 비효율적이다. 아래와 같은 방법을 활용할 수 있음
3. Grouping
- Linked list를 그룹으로 묶어서 관리
4. Counting
- 연속적으로 비어있는 블록 수 카운트
- ZFS에서 사용하는 방법(metaslab)
- contiguous의 장점을 가짐
TRIM
- 파일 시스템이 NVM에서 특정 페이지가 비어있음을 알리는 역할로, 이 명령을 통해 블록이 garbage collection될 수 있도록 함 → 시간 지연
(NVM에서 overwrite를 할 때는 free page 지우고 사용해야하는데, 한 페이지가 아닌 블록 단위로 지워야하는 특징때매)
🔹Performance
파일 시스템의 효율성과 성능은 여러가지 요소에 의해 영향을 받는다.
성능을 향상하는 여러가지 방법
- Buffer cache: 자주 사용되는 블록을 위한 별도 메모리
- Asynchrounous write: 버퍼 캐시를 사용하여 버퍼에 데이터를 저장한 후 빠르게 응답
- Synchrounous write: 캐싱한다고 디스크에서 메모리로 데이터를 올리면 빠르긴 하지만 불안정하다. 메모리에 있는 데이터가 수정됐는데 전원이 꺼지면 다 사라지기 때문, 그래서 Synchronous write는 버퍼링/캐싱을 하지 않는다.
- Free-behind: 읽자마자 버퍼의 기존 데이터 버리기 (free space 미리 만들기)
- Read-ahaed: 다음 데이터 블록도 읽을 걸 예상해서 미리 읽기
→ 3, 4번은 미리 예측하여 성능을 향상시키는 방법, 하지만 잘못 예측하면 더 안좋아질 수도)
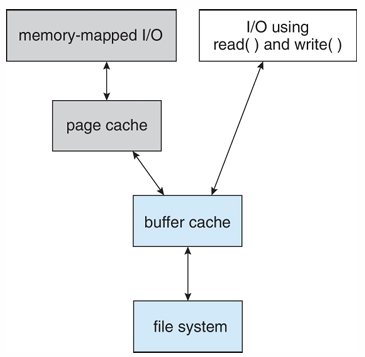
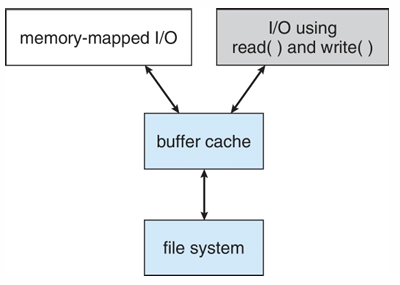
Unified Buffer Cache
캐싱을 두 번 한다면?
- Page cache: 블록이 아닌 페이지를 캐싱하는 방법, memory-mapped I/O에서 주로 사용
- 만약 I/O처리를 할 떄 buffer cache와 page cache를 동시에 적용한 경우
- 다른 알고리즘이긴 하지만 어쨌든 2번 접근으로 성능이 저하된다. 둘 중 하나만 사용해야함 → 어떤게 좋은지 잘 따져야 한다.
- 캐싱 중복
- 한 캐싱만 사용 → 이게 더 좋은 성능
🔹Recovery
- Consistency Checking
- 데이터 일관성 검사, 불일치 시 에러 감지
- Backup
- Log structered File system
- wirte로 변화된 이력(log) 보관
- 백업은 특정 시점의 데이터를 복구하는거라 그 이후 데이터를 잃어버리는데, log 그렇지 않음
WAFL file system
WAFL은 최신 기법들이 포함된 파일 시스템
- Distributed file system
- Write-anywhre file layout
- Random I/O 및 write 작업의 성능 최적화에 중점
- 하드디스크 대신 NVRAM을 사용하여 쓰기 캐싱 수행
WAFL에 필요한 다양한 정보들은 전부 파일로 존재한다. 이러한 파일 정보를 가진 table도 존재한다.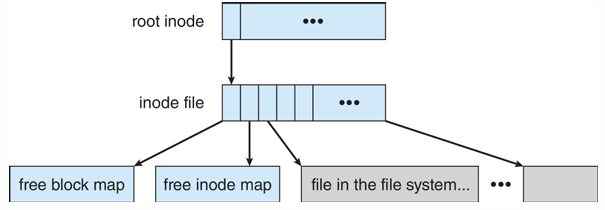
Snapshot할 때, 원래는 전부 copy하는데, 시간이 오래 걸리므로 공유를 먼저한다. 그리고 write해서 바뀌는게 생기면 그 때 copy하기 (copy on write, 앞에서 했떤 내용임 걍 다!!!!!!! 앞에서 했던 내용이야 비슷해)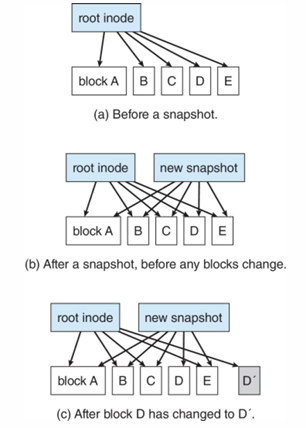
Apple file system
- snapshots
- space sharing(볼륨이 파티션들(일부 디스크)을 공유)
- atomic safe-sace primitives
