
💡 8장 목표
- 데드락 특징
- 데드락 해결책
- Prevention, Avoidance, Detection, Recovery
System model
프로세스가 자원을 사용하는 것을 모델링
- 시스템은 리소스로 구성되어있고, 여러 리소스 타입(R1, R2, …)이 존재
- 각 리소스 타입(Ri)은 여러 인스턴스(Wi개)를 가질 수 있다.
- 각 프로세스는 reqeust, use, release로 리소스 사용
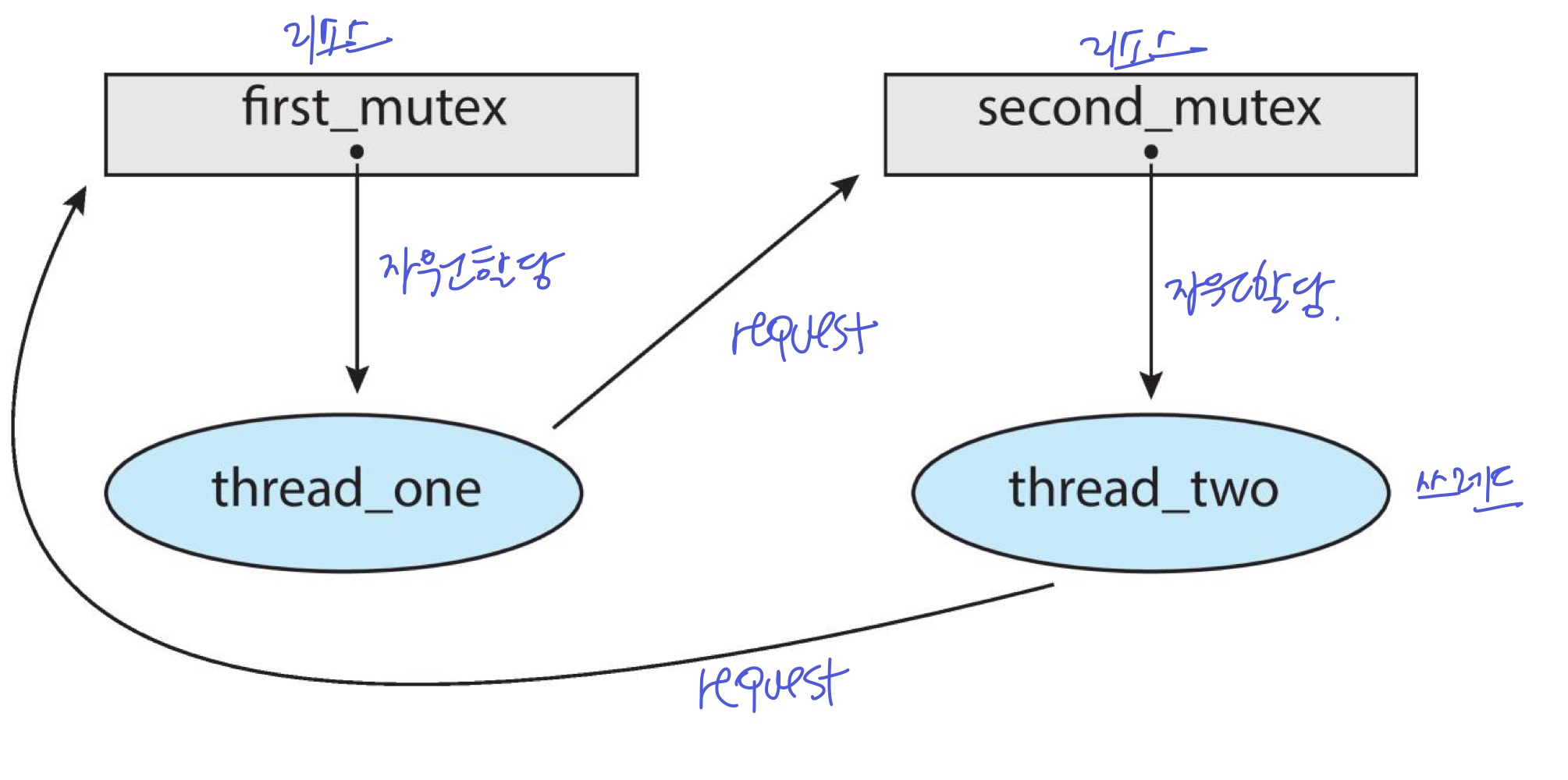
Deadlock in multithread application
멀티스레드에서 데드락이 발생하는 상황
- 두 개의 mutex lock, 두 개의 스레드
- 한 스레드는 mutex1을 먼저 잡고 mutex2를 잡고, 다른 스레드는 mutex2를 먼저 잡고 mutex1을 잡는다.
- 이 때, 스케줄러에 의해 우연이 두 스레드가 동시에 실행돼서 각 스레드가 mutex1, mutex2를 잡게되면, 서로 가진 걸 요청하고 기다리게되며 deadlock

- resource allocation graph는 아래와 같다
Deadlock Characterization
데드락은 아래 네 가지 조건이 동시에 만족될 때 발생한다.
- Mutual Exclusion: 한 번에 한 프로세스만 자원 사용 (독점권)
- Hold and Wait: 최소 하나의 자원을 잡고 있는 프로세스가 다른 프로세스가 잡고있는 자원을 얻기 위해 기다리는 상태
- No preemption: 선점 불가, 강제로 빼앗을 수 없다
- Circular wait: 서로 기다리는 관계 (대기 중인 프로세스 집합 {P0, P1, …, Pn}이 존재하며, P0는 P1이 보유하고 있는 자원을 기다리고, P1은 P2가 보유하고 있는 자원을 기다리며, …, Pn–1은 Pn이 보유하고 있는 자원을 기다리고, Pn은 P0가 보유하고 있는 자원을 기다리는 형태이다.)
Resource-Allocation Graph
- node: 프로세스 P = {P1, P2, …}, 리소스 R= {R1, R2, …}
- edge: P→R은 프로세스가 리소스를 요청, R→P는 프로세스에 리소스 사용권 할당
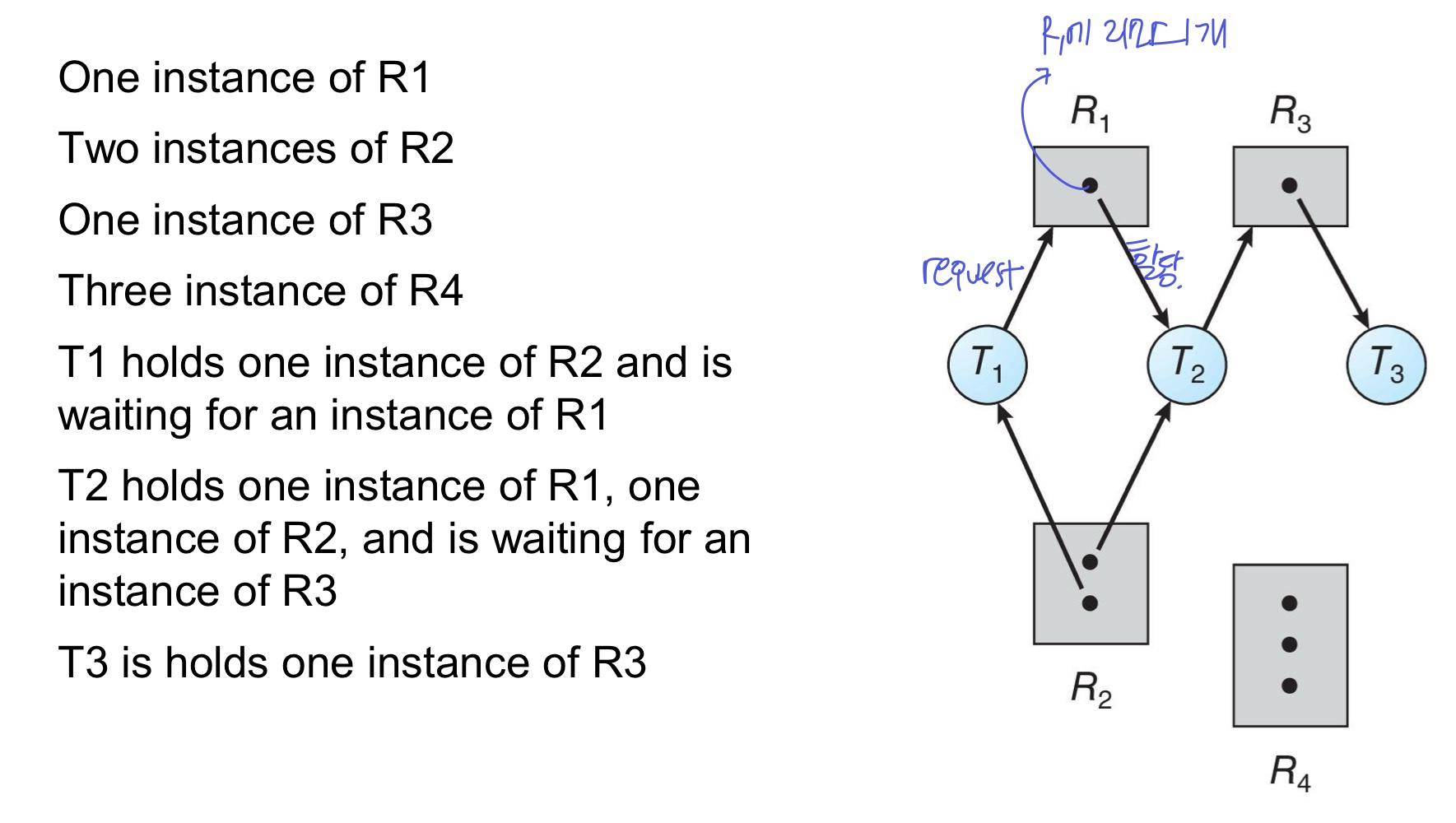
- deadlock의 resource allocation graph는 아래와 같다. circle을 가진다.
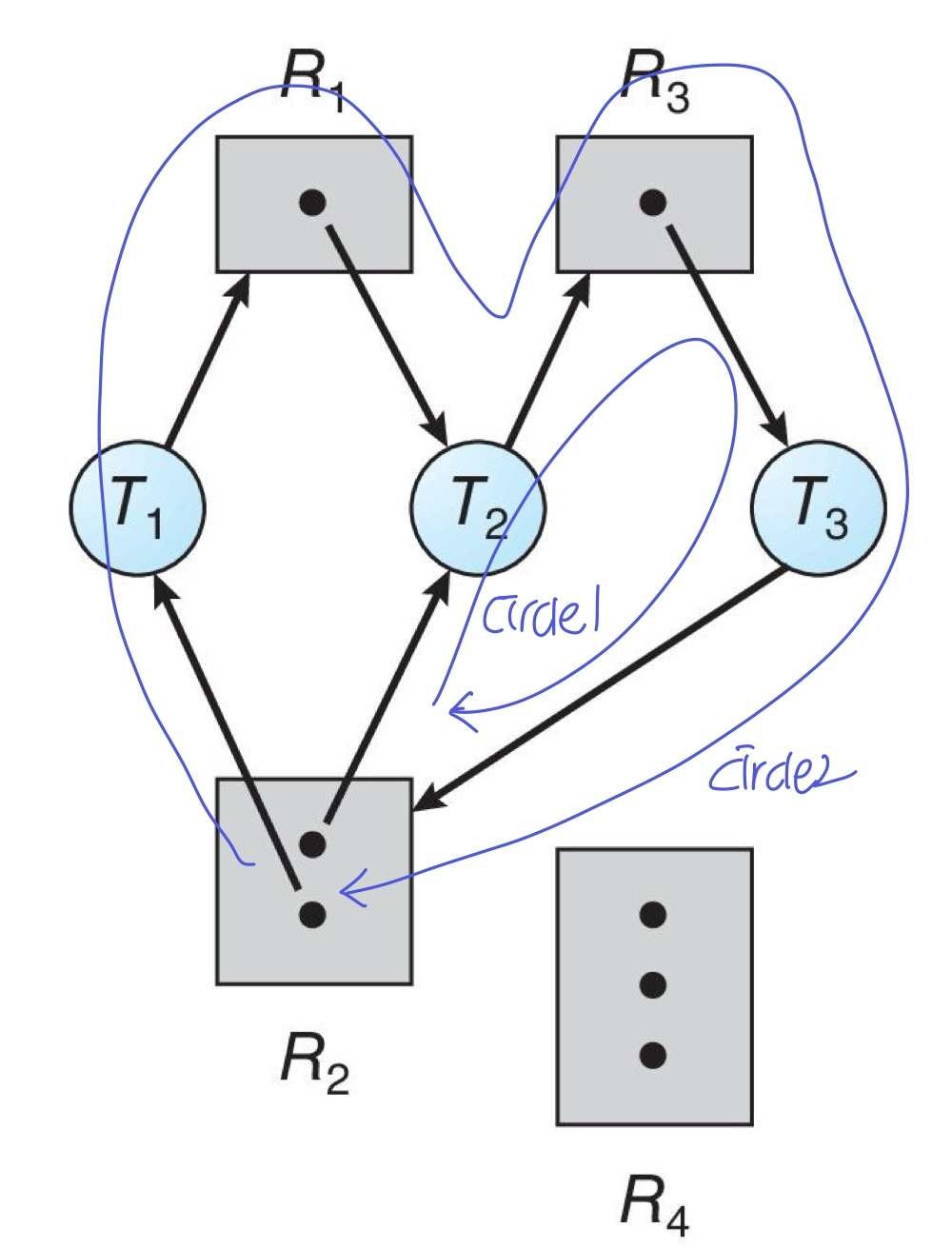
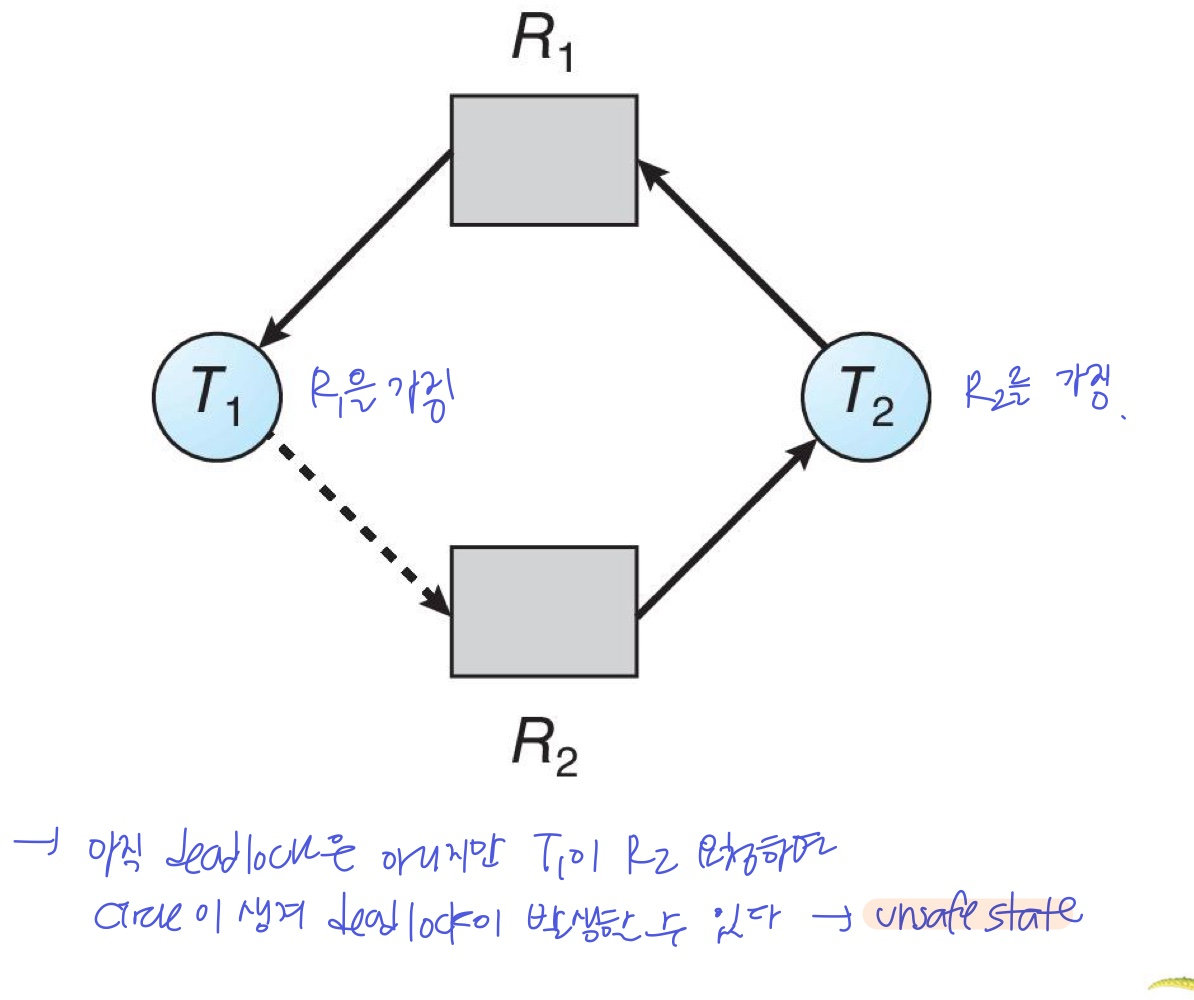
- circle을 가져도, 아래와 같은 경우라면 deadlock이 아닐 수 있다
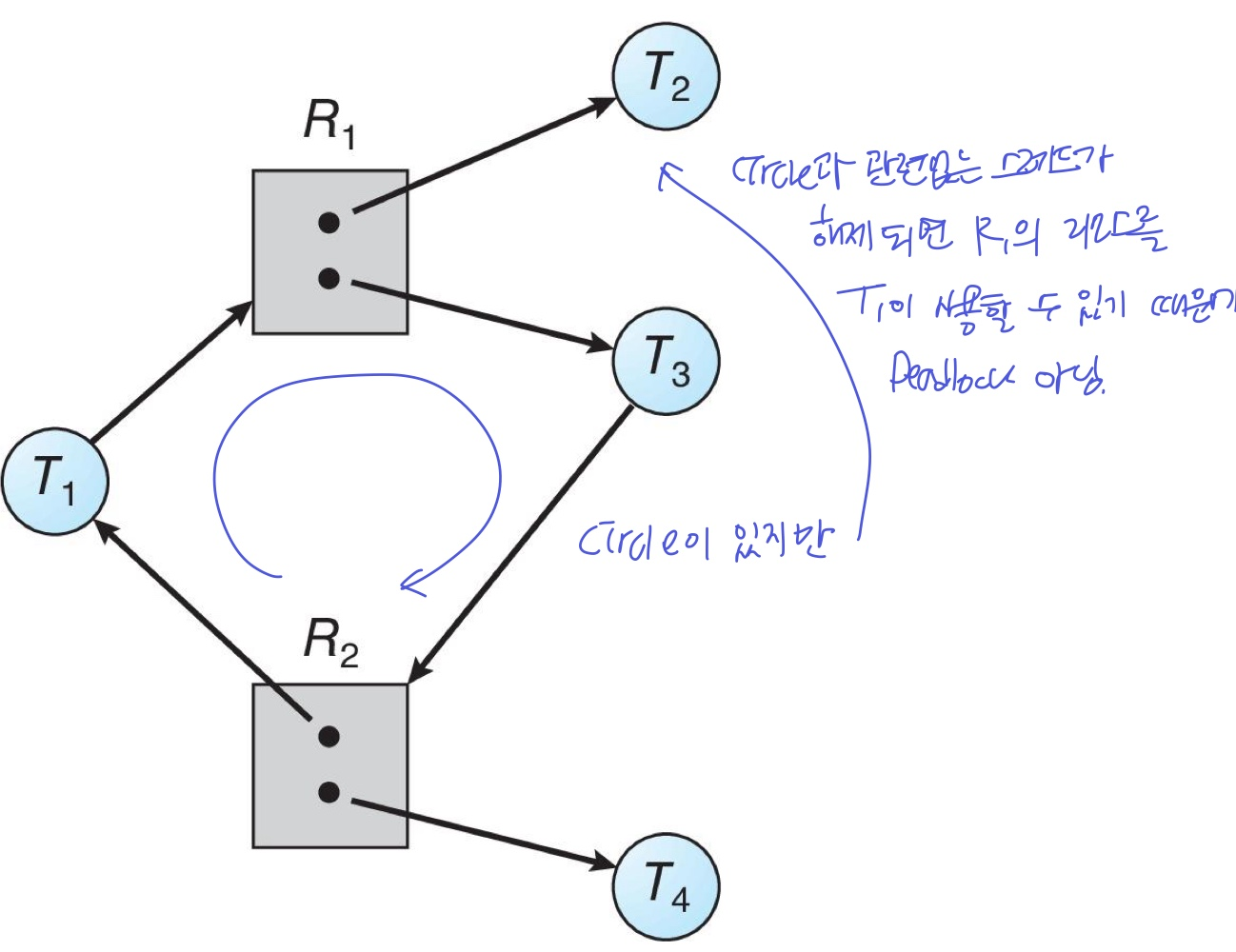
graph로 Deadlock 판단
- Cycle이 없다 → Deadlock 아님
- Cycel이 있다
→ 모든 리소스에 인스턴스 1개라면 Deadlock
→ 리소스에 인스턴스 여러개라면 Deadlock일 수도, 아닐 수도 있음
Methods for Handling Deadlocks
- 1, 2번은 데드락을 사전 방지 → 사전 방지 하면 좋지만, 리소스 활용도가 떨어지고 알고리즘이 어려움
- 3, 4번은 데드락 발생 후 처리
1. Prevention
데드락 발생 조건 4가지 중 하나를 없애는 방법
- Mutual Exclusion: 이건 없애면 race condition이 발생하기 때문에 없애기가 사실상 불가능
- Hold and Wait: 프로세스 실행 전 모든 자원을 한꺼번에 할당하고, 한꺼번에 해제
- 자원을 요청할 때 다른 자원을 보유하지 않도록 보장
- 필요하지도 않은 자원까지 잡아버리므로 자원 낭비, 활용도 떨어짐 (starvation 현상)
- No Preemption: 자원을 요청했는데 못잡았다면 전에 잡았던 자원도 다 놓기(선점으로 바꾸기) → 자원 활용도 떨어짐
- Circular Wait: 자원마다 번호를 매기고, 프로세스가 자원을 요청할 때 순서대로 요청하도록 요구

2. Avoidance
- 데드락이 발생할 것 같으면 리소스를 할당해주지 않는다.
- 프로세스가 자원을 요청할 때, 할당해도 safe state를 유지하는지 판별해야한다. safe state일 때만 리소스를 할당해준다.
- safe sate라면 아래 조건을 만족하는 프로세스 시퀀스<P1, P2, …>이 존재 Pi의 자원 요구가 즉시 사용 가능하지 않다면, Pi는 모든 Pj가 완료될 때까지 기다릴 수 있다. (j<i) Pj가 완료되면 Pi는 필요 자원을 얻어 실행하고, 자원을 반환한 후 종료된다. Pi가 종료되면 Pi+1은 필요한 자원을 얻을 수 있다.
- Safe State → no deadlock
- unSafe State → deadlock이 생길 수도 있고 아닐 수도 있고
- safe sate라면 아래 조건을 만족하는 프로세스 시퀀스<P1, P2, …>이 존재 Pi의 자원 요구가 즉시 사용 가능하지 않다면, Pi는 모든 Pj가 완료될 때까지 기다릴 수 있다. (j<i) Pj가 완료되면 Pi는 필요 자원을 얻어 실행하고, 자원을 반환한 후 종료된다. Pi가 종료되면 Pi+1은 필요한 자원을 얻을 수 있다.
- Safe state 확인 방법
- 모든 자원이 싱글 인스턴스라면 → resoruce allocation graph러 circle이 생기는지 확인
- 인스턴스가 여러개라면 → Banker’s Algorithm으로 확인
- 모든 자원이 싱글 인스턴스라면 → resoruce allocation graph러 circle이 생기는지 확인
Banker’s Algorithm
사용 데이터 구조는 아래와 같다.
- Avaiable: OS에 남아있는 자원 개수 (사용 가능한 자원 개수)
- j번째 리소스가 k개 남아있다.
- Max: 프로세스가 필요로 하는 자원 개수
- i번째 프로세스가 j번째 리소스를 k개 필요로 한다.
- Allocation:프로세스가 사용 중인 자원 개수
- i번째 프로세스가 j번째 리소스를 k개 사용 중이다.
- Need: 프로세스가 추가적으로 더 요청할 자원 개수 (Max - Allocation)
- i번째 프로세스가 j번째 리소스를 k개 더 필요로 한다.
- Safety를 확인하는 알고리즘은 아래와 같다.
- i번째 프로세스가 리소스를 요청하는 알고리즘은 아래와 같다. 중요한 것은 자원 충분하다고 바로 할당하는게 아니라,할당했을 때 안전한지 확인하는 것
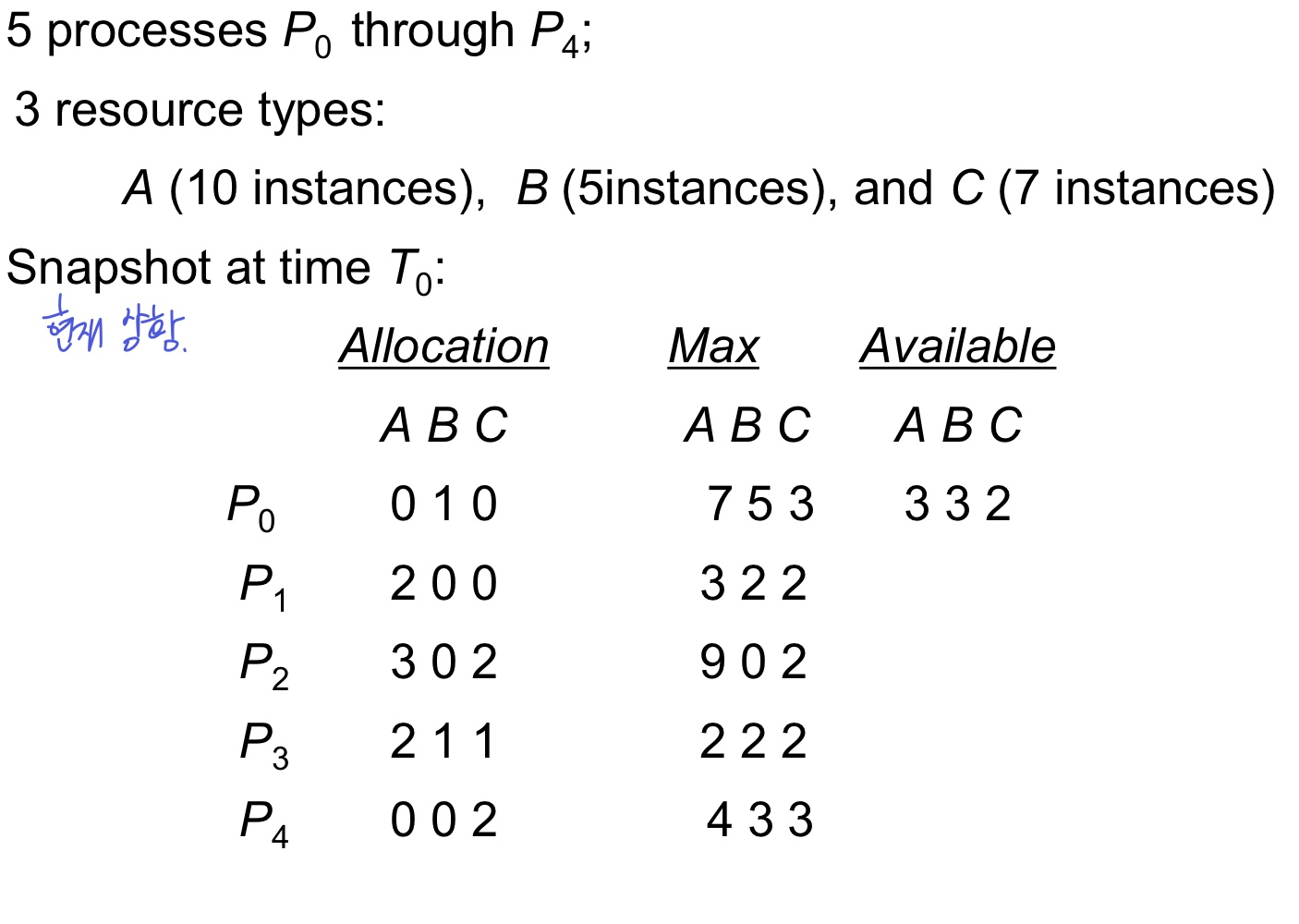
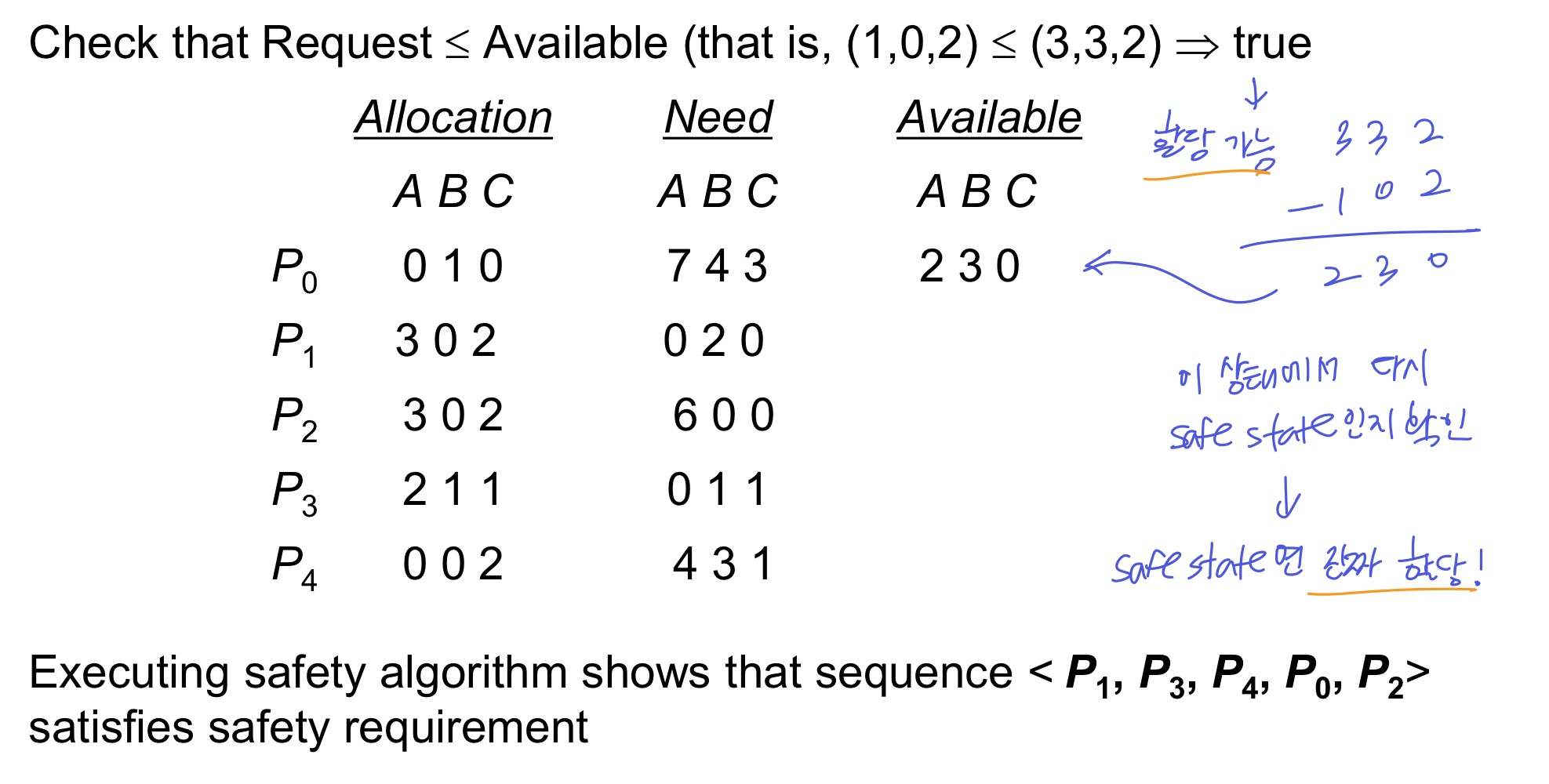
example
만약 P1이 (1, 0, 2)를 요청했다면,
- (1, 0, 2) ≤ (3, 3, 2)니까 할당은 가능함
- 할당 했을 때 안전한지 다시 확인하고 안전하면 그때 진짜 할당



3. Detection and Recover
Detection
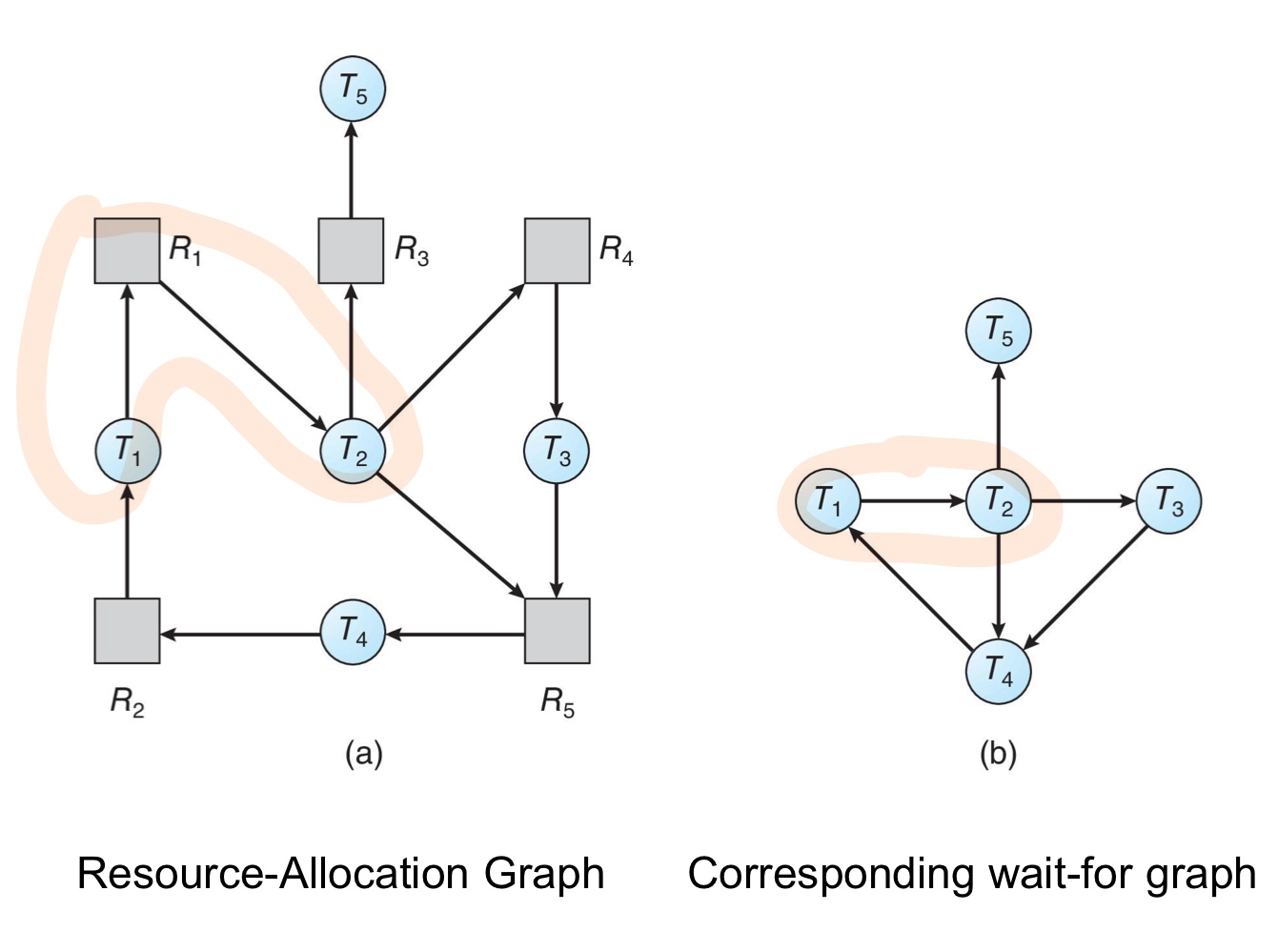
- SIngle Instance인 경우 → wait-for 그래프에서 cycle이 있는지 확인
- wait-for그래프는 리소스 없이 프로세스로만 나타낸 그래프
- pi → pj는 프로세스i가 프로세스j가 사용 중인 리소스를 기다린다를 의미
- 하지만 cycle 찾는 것은 노드가 n개 일 때, n^2시간 걸림
- Serveral Instance인 경우 → detection algorithm 사용 (bankers와 비슷함)
- 근데 이 알고리즘은 자원이 m개, 프로세스가 n개일 때 m*n^2시간이나 걸림


- 근데 이 알고리즘은 자원이 m개, 프로세스가 n개일 때 m*n^2시간이나 걸림
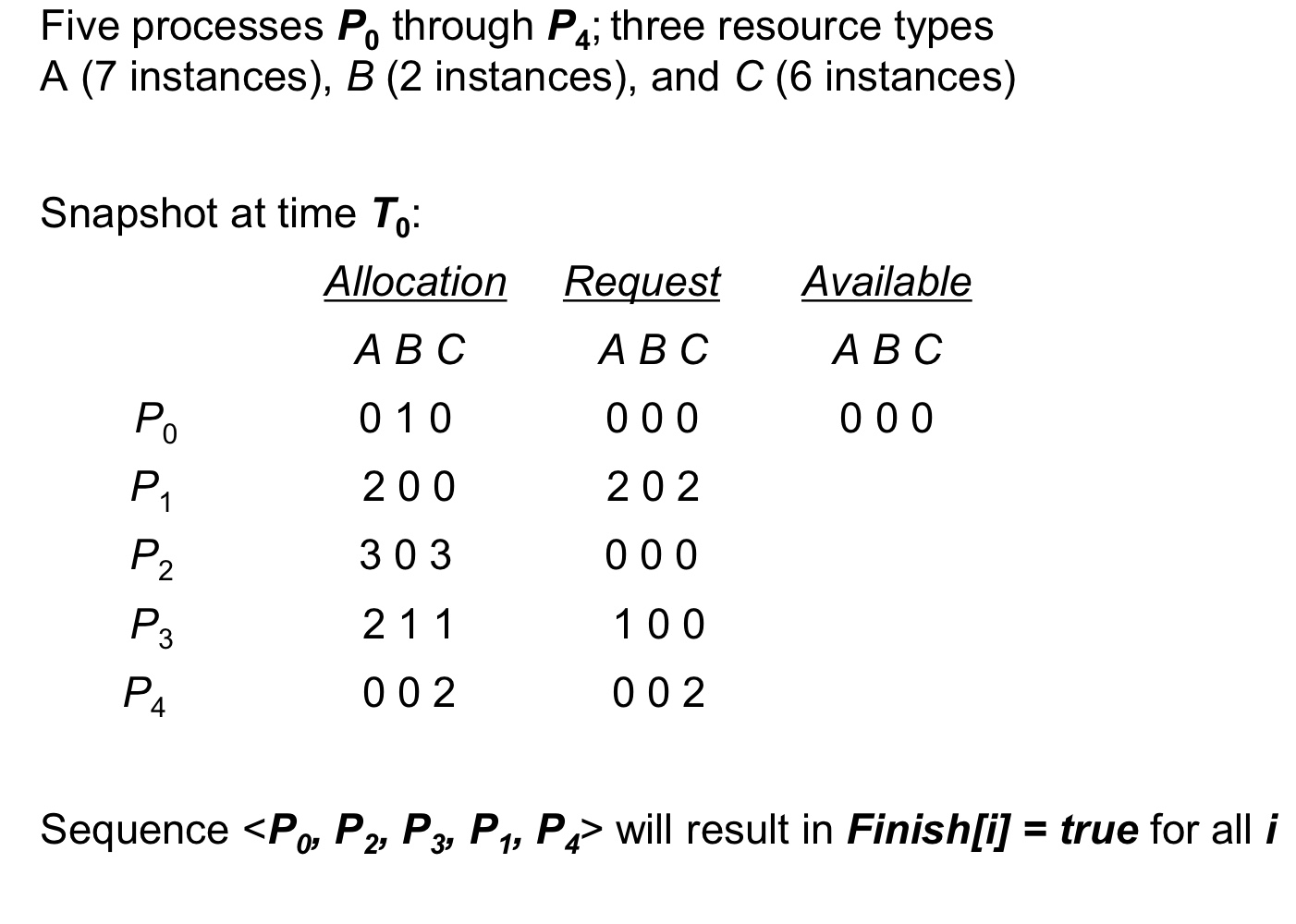
example
- 아래와 같이 알고리즘을 적용했을 때 전부 작업이 완료되는 시퀀스 시나리오가 존재하면 deadlock없음
- 근데 완료되지 않은 작업이 발생하면 deadlock

- 이 알고리즘은 너무 복잡하고 시간도 오래 걸리기 때문에 아래를 고려해야한다.
- 데드락이 얼마나 자주 발생하는지
- 얼마나 많은 프로세스가 데드락을 발생시켜 roll back을 하게 하는지
Recovery
- 데드락과 관련된 프로세스를 abort(종료)하거나 roll back(일정 시점까지만 취소, 자원 해제)
- 데드락과 관련된 프로세스들 중 어떤 프로세스를 종료할 것인가? → 우선순위, 얼마나 길게 수행했는지, 얼마나 자주 자원을 사용했는지 등을 고려
- 데드락과 관련된 프로세스들 중 어떤 프로세스를 종료할 것인가? → 우선순위, 얼마나 길게 수행했는지, 얼마나 자주 자원을 사용했는지 등을 고려
- Recovery시 고려할 점
- victim을 설정할 때 리소스 낭비를 최소화, 비용 최소화
- 리소스 낭비를 최소화하기 위해 abort보단 rollback
- 하지만 데드락이 너무 자주 발생하면 abort나 rollback도 자주 일어나며 starvation 발생 가능
4. Ignore
- 데드락 발생 무시

( •̀ .̫ •́ )✧