[유니티 그래픽스 최적화 스타트업] Part 04 | 드로우콜과 배칭

1. 드로우콜 (Draw Call)
1. 드로우콜의 이해
- CPU가 GPU에 오브젝트를 그리라는 명령을 호출하는 것
☑️ 컬링(Culling)
- 카메라의 시야 밖에 위치하는 오브젝트는 렌더링 대상에서 제외하는 과정
- 컬링 과정을 거친 오브젝트가 렌더링 되려면 CPU로부터 GPU에 정보가 전달되어야 함
- CPU와 GPU의 메모리 공간은 독립적
- 스토리지로부터 파일을 읽어와 CPU메모리에 데이터를 올리고, 렌더링 되기 전 CPU 메모리의 데이터 중 메시 정보를 GPU 메모리에 복제하여 GPU에서 접근할 수 있도록 함
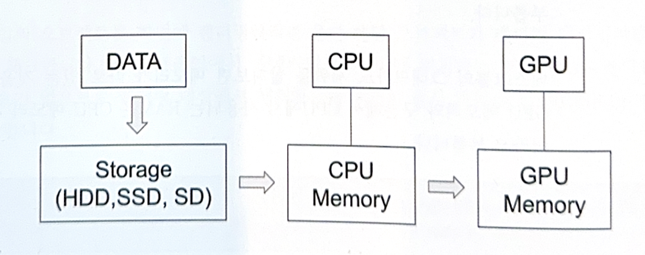
- 위의 데이터 전달 과정을 매 프레임마다 수행하면 치명적 성능 하락 -> 로딩 시점에 메모리에 데이터를 올려두고 적절한 시점(씬 변환 등)에 데이터를 해제 (게임이 수행되는 동안은 데이터가 계속 메모리에 상주)
◾ 렌더 상태(Render States)
- 그려야 하는 상태 정보를 담는 GPU의 테이블
- CPU의 순차적인 명령을 기억하여 어떤 텍스처, 쉐이더, 버텍스들을 사용할 것인지 기억, 즉 GPU 메모리의 데이터 위치 정보(메모리 주소)를 가짐
- 텍스처 상태 슬롯, 렌더링 모드(z테스트, 알파 블렌딩 등) 정보 슬롯 등 존재
CPU가 렌더 상태를 변경하는 명령을 보내고, GPU는 렌더 상태에 오브젝트를 그리기 위한 정보 저장
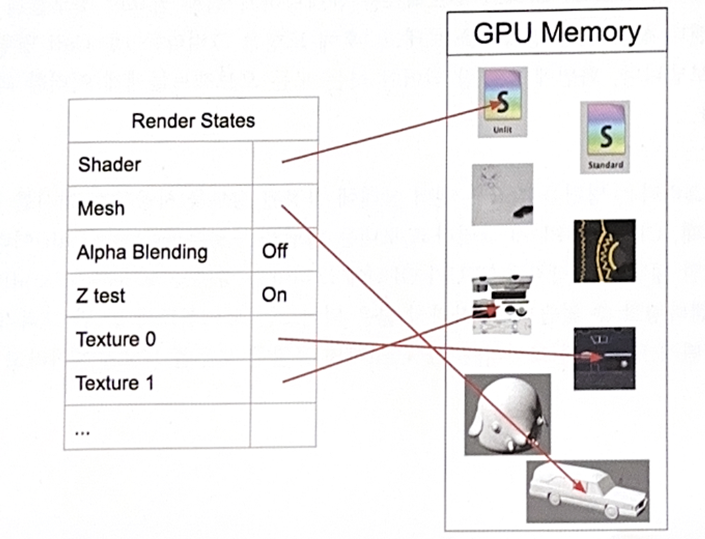
- CPU가 마지막으로 메시를 그리라는 Draw Primitive Call (DP Call) 명령을 GPU에게 보내면 렌더상태의 정보들을 기반으로 오브젝트를 렌더링
- 다음 오브젝트를 위해 변경될 명령만 보내 렌더상태 변경을 진행하고 나머지는 그대로~ 반복
- CPU는 GPU가 다른 작업을 수행하고 있지 않은 유휴(idle)상태까지 기다려야 하므로 사실 CPU에서 GPU로 바로 명령을 보내면 성능 문제 발생
- CPU의 명령을 커맨드 버퍼에 쌓아두고 GPU가 작업이 끝나면 커맨드 버퍼에서 다음 할 일을 가져가 CPU와 GPU가 서로의 간섭 없이 병렬 작업을 수행⭐
(선입선출 FIFO-First in First out)
- 다른 그래픽스 API 과정은 p.130 참고
- 유니티는 공통적인 API 구성되고 드라이버 칩셋의 알맞은 해석과 변형으로 드로우콜을 하기 때문에 멀티 플랫폼에 대응할 수 있음
- 근데 위와 같은 과정은 오버헤드를 발생시키므로 드로우콜은 CPU 바운더리의 오버헤드가 됨
- 즉, 드로우콜은 CPU 성능에 의존적이며, 드로우콜로 인한 성능 하락을 줄이기 위해서는 드로우콜 횟수를 줄여야 함
2. 드로우콜의 발생 조건
- 오브젝트 하나에 메시 1개, 머터리얼 1개 -> 드로우콜 1번
◾ 메시가 여러 개인 경우
- ex) 캐릭터 오브젝트의 머리, 몸통, 팔, 다리 등 따로따로 이루어진 경우
- 메시의 개수만큼 드로우콜 발생
◾ 머터리얼이 여러 개인 경우
- ex) 한 메시에 몸통 머터리얼, 눈 머터리얼 (몸통과 눈 2개의 서브메시가 존재)
- 머터리얼의 개수만큼 드로우콜 발생
◾ 쉐이더에 의한 경우
- 멀티 패스(Multi pass)로 두 번 이상 렌더링되면 드로우콜이 늘어남
- ex) 툰 쉐이더 - 외곽선
- 데스크톱 CPU에서는 1000개의 드로우콜이 넘어도 가능하지만
- 모바일 CPU에서는 100개도 많음 (최신 디바이스는 200개 정도?)
3. Batch & SetPass
- 드로우콜은 포괄적인 개념이고, 유니티에서는 Batch와 SetPass라는 용어로 나누어 표시
◾ Batch
- DP Call과 상태 변경등을 합친 넓은 의미의 드로우콜
◾SetPass
- 드로우콜이 일어날 때 상태 변경의 발생 여부 (메시 변경은 포함 X)
- 쉐이더로 인한 렌더링 패스 횟수를 의미하며 쉐이더의 변경 혹은 쉐이더 파라미터들의 변경이 일어나면 SetPass 카운트가 증가
- SetPass가 높으면 CPU 성능이 소모되는 것
- ex) Batch 10번, SetPass 1번
-> 10번의 드로우콜 동안 쉐이더 변경 X, 메시 및 트랜스폼 정보 등 최소한의 상태 변경만 이루어짐- ex) Batch 10번, SetPass 10번
-> 10번의 드로우콜 동안 매번 쉐이더 변경 O, 경우에 따라 많은 상태 변경들이 동반


- 만약 CPU 바운드이고, 드로우콜이 병목이라면 SetPass 수를 줄이는 것이 가장 효율적!
- 서로 다른 메시여도 동일한 머터리얼을 사용하면 SetPass는 동일
❗ SetPass call이 적으면 Batch 구성이 잘 된 것
2. 배칭(Batching)
1. 배칭의 이해
- 드로우콜을 줄이는 작업으로 1개의 드로우콜이 1개의 배치인데 여러 배치를 하나로 묶어서 하나의 배치로 만드는 것
- 드로우콜을 줄이기 위한 가장 효율적인 기능 중 하나
- 다른 오브젝트, 다른 메시를 사용하더라도 같은 머터리얼을 사용하면 하나의 배치로 구성하는 것이 가능
(아래 첫 그림은 3개의 오브젝트를 배칭처리하여 1개 배치, 즉 1개의 드로우콜로 표현)
- 텍스처 아틀라스(Atlas): 다른 메시에도 머터리얼을 공유할 수 있도록 여러 개의 텍스처를 하나의 텍스처로 합치는 것
(텍스처를 합치면 해상도가 높아지므로 해상도 고려 필요)
✔️ 주의점
- 동일한 머터리얼은 동일한 머터리얼 인스턴스를 의미하며 아래와 같이 다른 머터리얼 에셋이면 배칭 X
- 스크립트로 머터리얼 접근 시에도 아래와 같이 속성을 수정하면 머터리얼의 복사본이 생기므로 배칭 X
GetComponent<Renderer>().material.color = Color.red; //대신 Renderer.sharedMaterial 사용해서 수정하기! //(해당 머터리얼을 사용하는 모든 오브젝트에 적용되는 점 유의)

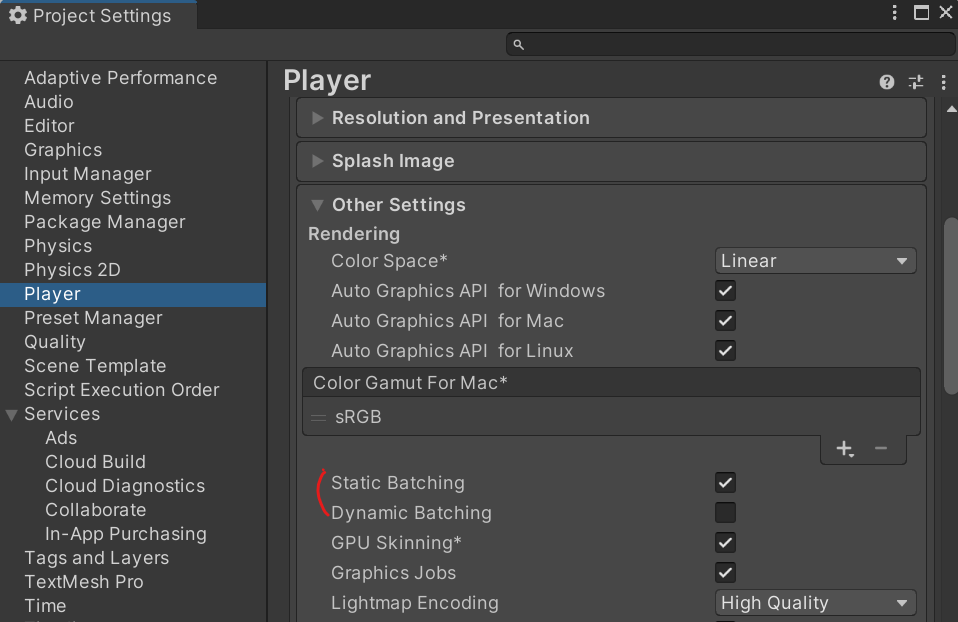
- 배칭은 스태틱 배칭과 다이내믹 배칭 두 종류이며 Project Setting > Player에서 사용 여부 체크
2. 스태틱 배칭(Static Batching)
- 정적이고 움직이지 않는 오브젝트를 위한 배칭 기법
- 주로 배경 오브젝트이며 게임 오브젝트의 인스펙터에서 Static 플래그가 켜져야함
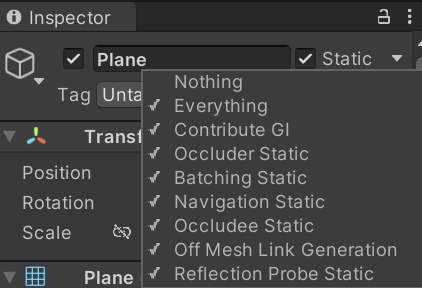
- 런타임에서 버텍스 연산을 하지 않으므로 다이나믹 배칭보다 효율적
- 유니티에서 기본 오브젝트들은 Default-Material을 사용하므로 배칭되는 것을 확인할 수 있음
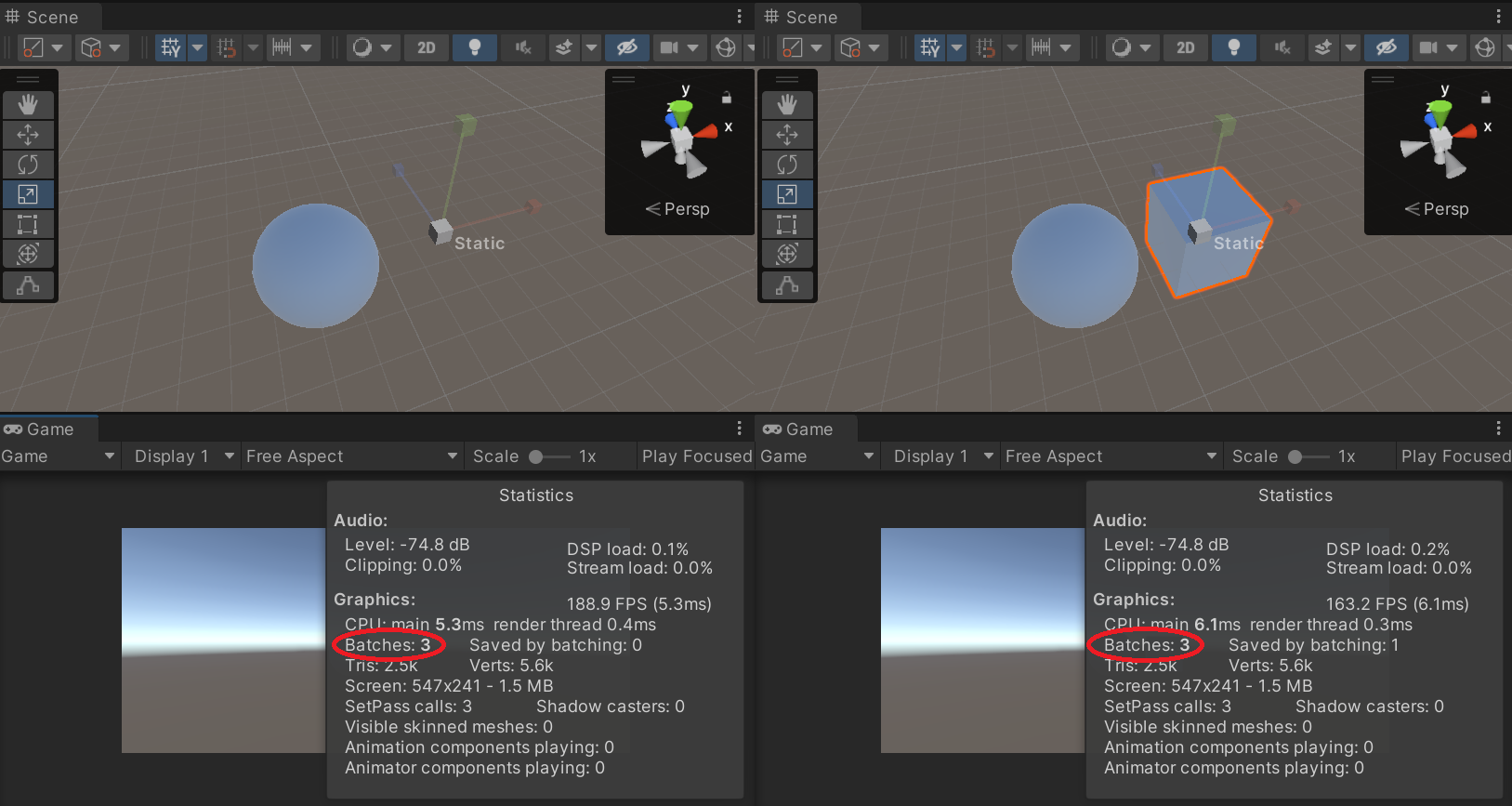
- 유니티에서 기본 오브젝트들은 Default-Material을 사용하므로 배칭되는 것을 확인할 수 있음
- 사용법은 간단하지만 메모리가 추가로 필요하다는 주의점이 있음
-> 배칭은 오브젝트를 합쳐서 내부적으로 하나의 메시로 만들기 때문에 3개의 오브젝트가 1개의 메시만 사용하더라도 3개의 메시를 합친 만큼의 추가 메모리가 필요 (원래 배칭이 아닌 오브젝트인 경우 1개의 메시만 메모리에 상주하고 이를 매 오브젝트마다 사용해서 렌더링) - 위처럼 만들어진 새로운 하나의 메시를 GPU가 가져가서 그래도 화면에 렌더링하므로 오브젝트"마다" 상태 변경과 드로우콜 거칠 필요 없이 한 번의 드로우콜로 처리
- 메모리를 희생해 드로우콜을 줄여 런타임 성능을 높임
- 보통 스태틱 배칭 대상의 오브젝트는 처음부터 씬에 존재해야 함
- 런타임 상에서 추가한 정적 오브젝트도 스태틱 배칭으로 묶고 싶다면
StaticBatchingUtility.Combine()메소드를 이용할 수 있지만 시간이 많이 필요하므로 추천 X
- Max나 Maya에서 모듈을 조합해 하나의 커다란 메시로 만드는 것 보다 모듈화하여 배칭하는 것이 더 나음
- 하나의 커다란 메시는 화면에 일부만 보이더라도 메시 전체의 폴리곤이 처리되며, 배칭되더라도 원래의 오브젝트 기준으로 컬링이 이루어지기 때문
3. 다이내믹 배칭 (Dynamic Batching)
- 동적으로 움직이는 오브젝트들끼리의 배칭 처리
- Static 플래그 비활성화 된 오브젝트가 대상이며, 동일한 머터리얼이면 자동으로 배칭 (Player설정에서 Dynamic batching만 활성화하면 됨)
- 런타임에서 이뤄지는 다이내믹 배칭은 매 프레임 씬에서 대상 오브젝트의 버텍스들을 모아 합치고, 다이내믹 배칭에 쓰이는 버텍스 버퍼, 인덱스 버퍼에 담음 -> 매번 데이터 구축과 갱신이 발생하므로 매 프레임마다 오버헤드가 발생하지만 드로우콜을 어쨋든 줄였으니,, 성능 향상됨
- 하지만 위와 같은 오버헤드 때문에 제약 사항이 존재
✔️ 제약 사항
1. 스키닝을 수행하는 Skinned Mesh에 적용 불가
- 스키닝: 기본 T포즈에서 스켈레탄 애니메이션 포즈에 맞춰 메시의 버텍스 위치들을 보정하며 메시가 변형되는 과정
- 이러한 애니메이션이 적용되는 메시는 Skinned Mesh Renderer라는 특수 렌더러가 적용
- 스키닝 연산은 CPU에서 이뤄지기 때문에 다이나믹 배칭으로 묶으면 연산 효율이 떨어짐
- GPU에서도 연산할 수 있긴 해서 CPU 병목인 상황일 때 GPU 스키닝을 활성화할 수도 있음
2. 버텍스가 너무 많은 메시는 다이나믹 배칭의 대상에서 제외
- 너무 많은 버텍스를 수집하면 오버헤드가 드로우콜의 비용보다 높아질 가능성이 있음
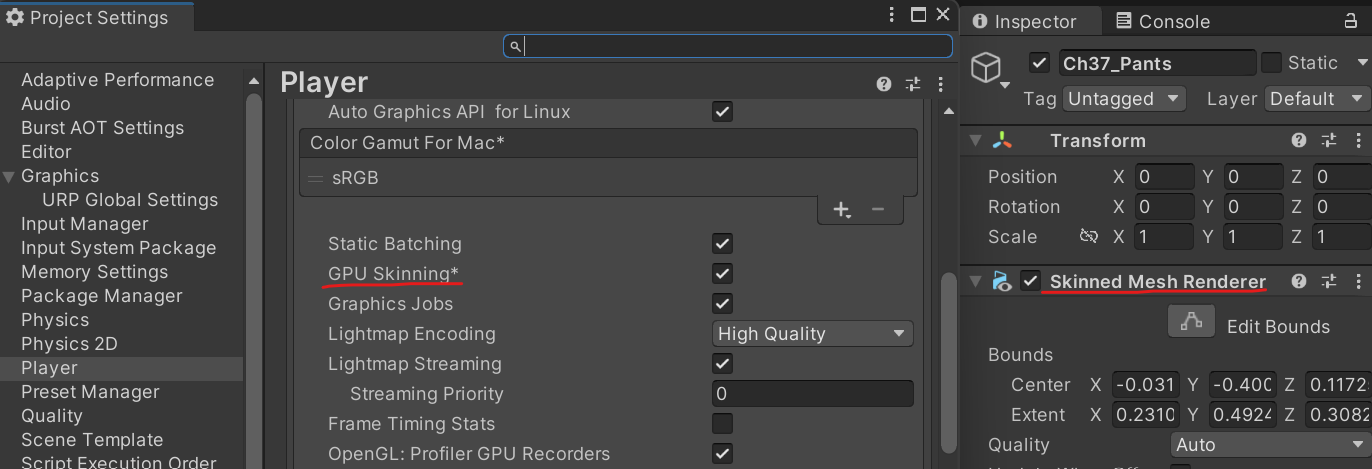
- 일반적으로 메시가 렌더링 될 때에는 버텍스 쉐이더에서 월드스페이스로의 변환되는 GPU에서의 고속 연산이지만, 다이내믹 배칭을 위해서는 CPU에서 연산이 이뤄짐
- 이러한 연산 과정이 드로우콜보다 더 많은 시간을 잡아먹으면 오히려 비효율적
- 특히 드로우콜은 그래픽스 API에 영향을 많이 받아 Apple Metal, Android Vulkan은 OpenGL ES보다 훨씬 빨라서 다이내믹 배칭의 오버헤드가 크면 비효율적으로 되기 쉬움
- 오버헤드가 더 크다고 판단되면 DisableBatching 플래그를 True로 설정할 수 있음
Sub Shader {
Tags{ "RenderType"="Opaque" "DisableBatching"="True" }4. Mesh.CombineMeshes
- 위의 자동적인 유니티의 배칭 시스템 외의 수동 배칭 처리 방법
- 동일한 머터리얼을 사용하는 메시끼리 스크립트를 통해 합쳐주는 것
- 스크립트에서 오브젝트 자식들의 메시 컴포넌트를 가져와
Mesh.CombineMeshes()메소드로 하나의 메시로 합쳐줌
5. 2D 스프라이트 배칭
◾ 조건
- 2D스프라이트는 버텍스가 적어 효율적인 배칭 가능
- 머터리얼 같으면 자동으로 배칭
- 그래서 스프라이트들을 하나의 이미지에 모아 넣는 시트로 많이 제작됨 (Sprite mode를 Multiple로 설정)
◾ 스프라이트 아틀라스 (Sprite Atlas)
- 스프라이트들을 하나의 이미지에 모아 넣는 기법
- Project Settings > Editor에서 Sprite Packer를 Always enabled로 설정
- Sprite Atlas를 생성하고 Inspector의 Objects for packing에 각 스프라이트들을 드래그하여 Pack Preview를 눌러 패킹 가능
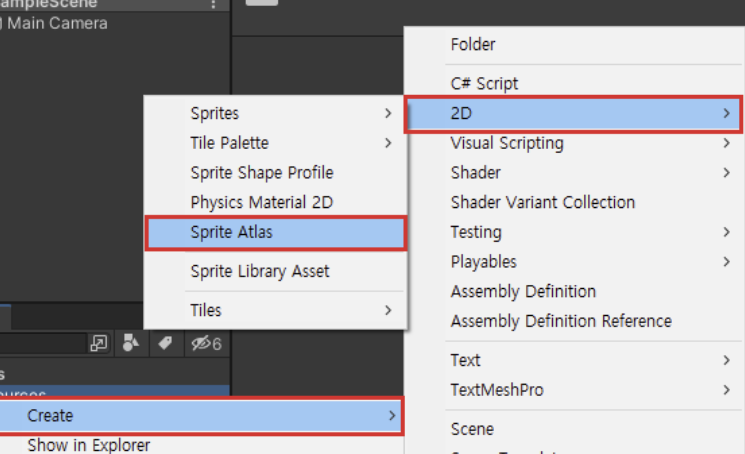 (2D 프로젝트에서만 생성 가능)
(2D 프로젝트에서만 생성 가능)
6. GPU 인스턴싱
- 한번의 드로우콜로 오브젝트의 여러 복사본을 렌더링하여 드로우콜을 줄이는 방법 (메시의 복사본을 만드는 것이 배칭과의 차이점)
- 배칭과 다르게 별도의 메시를 생성하지 않고, 인스턴싱 되는 오브젝트의 트랜스폼 정보를 별도의 버퍼에 담음
- GPU가 그 버퍼와 원본 메시를 가져다가 여러 오브젝트들을 한번에 처리하기 때문에 런타임 오버헤드가 적음 (인스턴싱 처리를 GPU에서 함) -> 메시의 버텍스 개수와 상관 없이 동적 오브젝트 배칭 처리 가능
- Standard 쉐이더를 사용하는 머터리얼의 Enable GPU Instancing을 체크
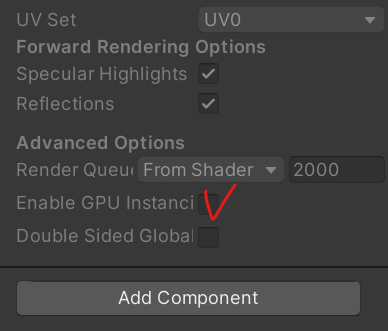
- 동일한 모양의 오브젝트들이 여러 개 렌더링 되는 경우 유용 (우주 운석, 미사일 등)
✔️ 제약 사항
- Mesh Renderer에만 적용되기 때문에 Skinning Mesh에 적용 X (캐릭터는 또 안됨,,)
- GPU에서의 처리이므로 디바이스에서 GPU 인스턴싱을 지원하는 경우에만 사용 가능
3. 프레임 디버거 (Frame Debugger)
- 프레임이 어떻게 렌더링되는지 직관적으로 확인 가능
- 각 드로우콜 과정에서 어떤 메시가 렌더링 되는지, 쉐이더의 속성, 배칭 처리 중 드로우콜 발생 시 그 이유 등을 확인할 수 있음
- Window > Analysis > Frame Debugger로 프레임 디버거 창을 열어 원하는 프레임에서 Enable을 누르면 해당 프레임이 렌더링 되며 드로우콜의 숫자가 표시됨
- 드로우콜의 순서 목록과 해당 드로우콜의 속성 창을 확인할 수 있음
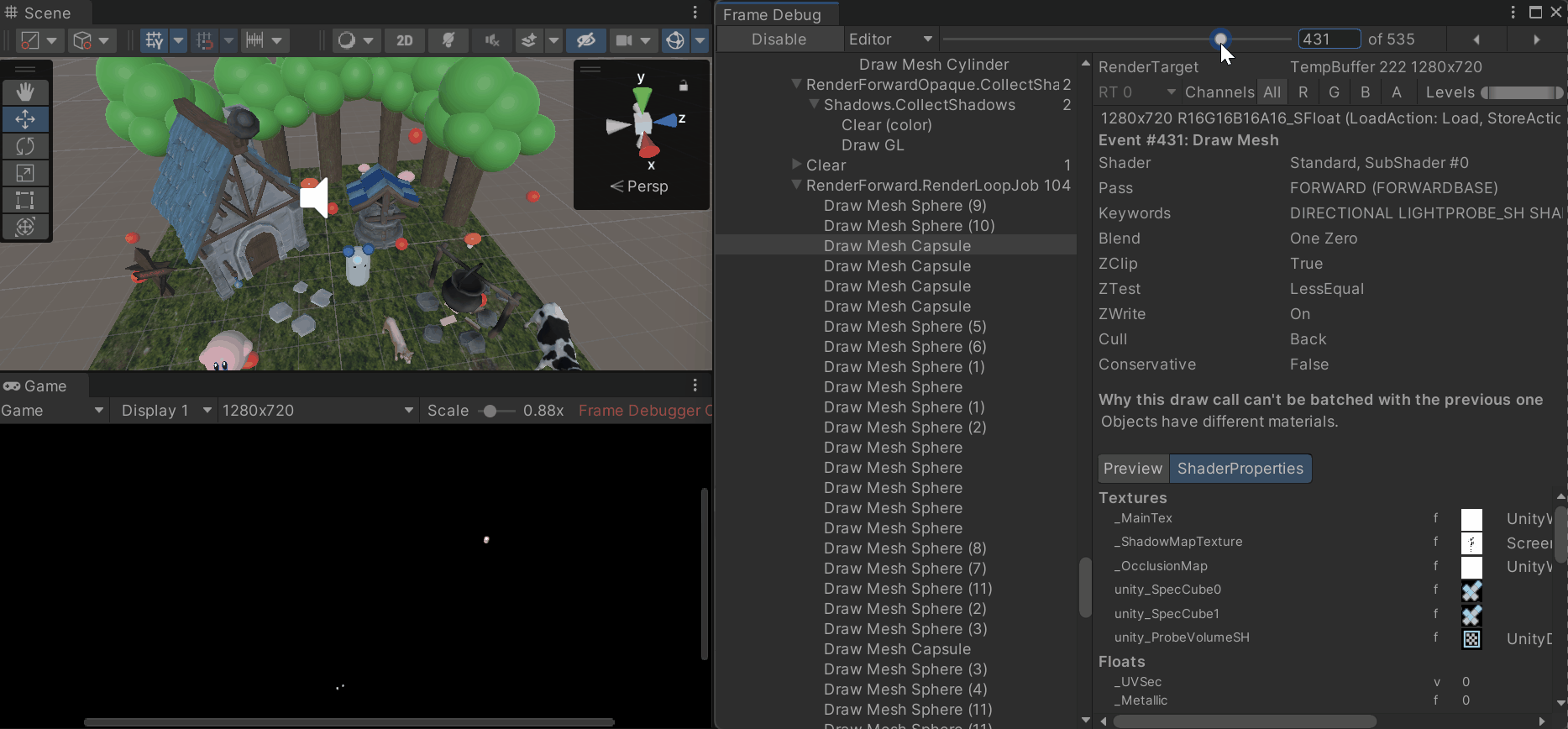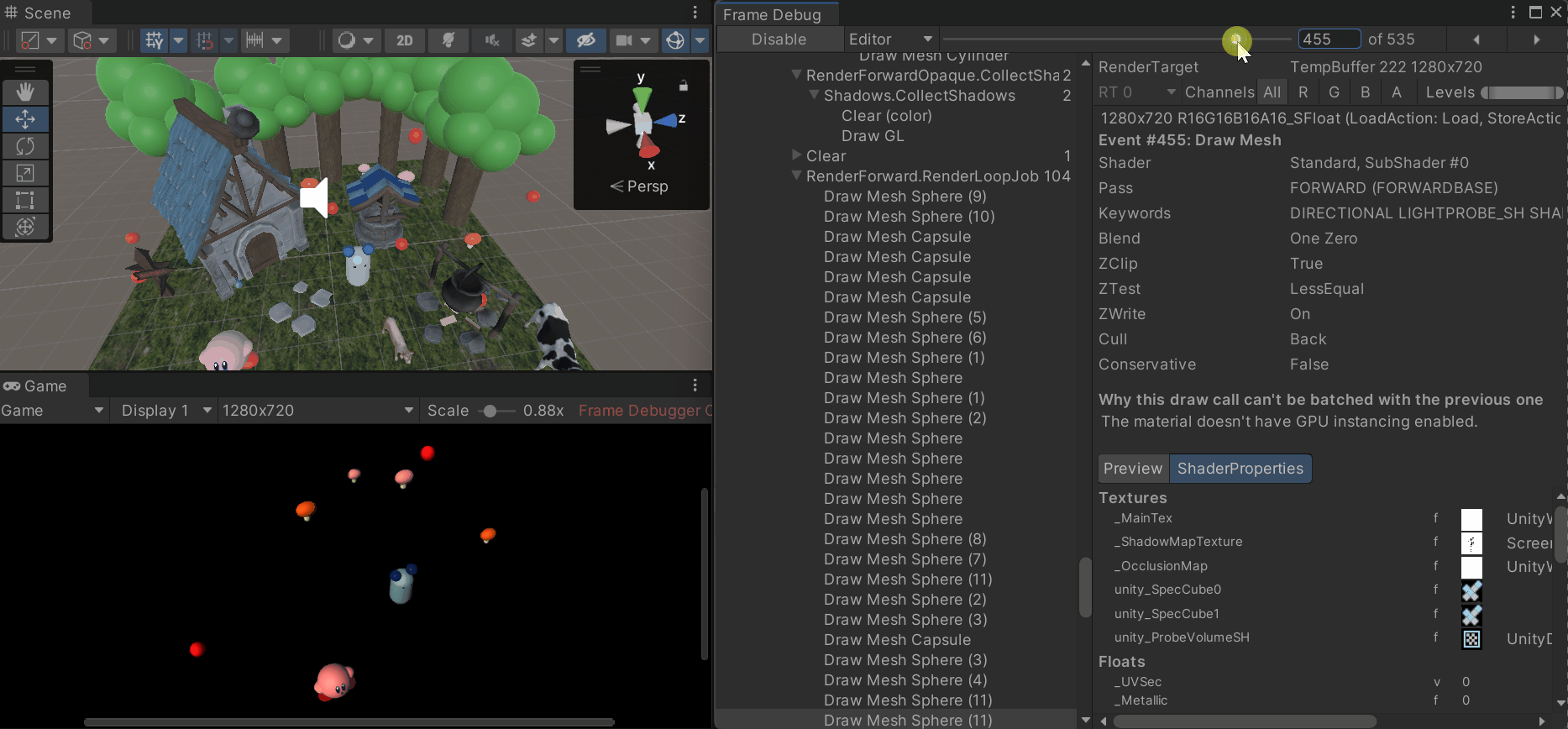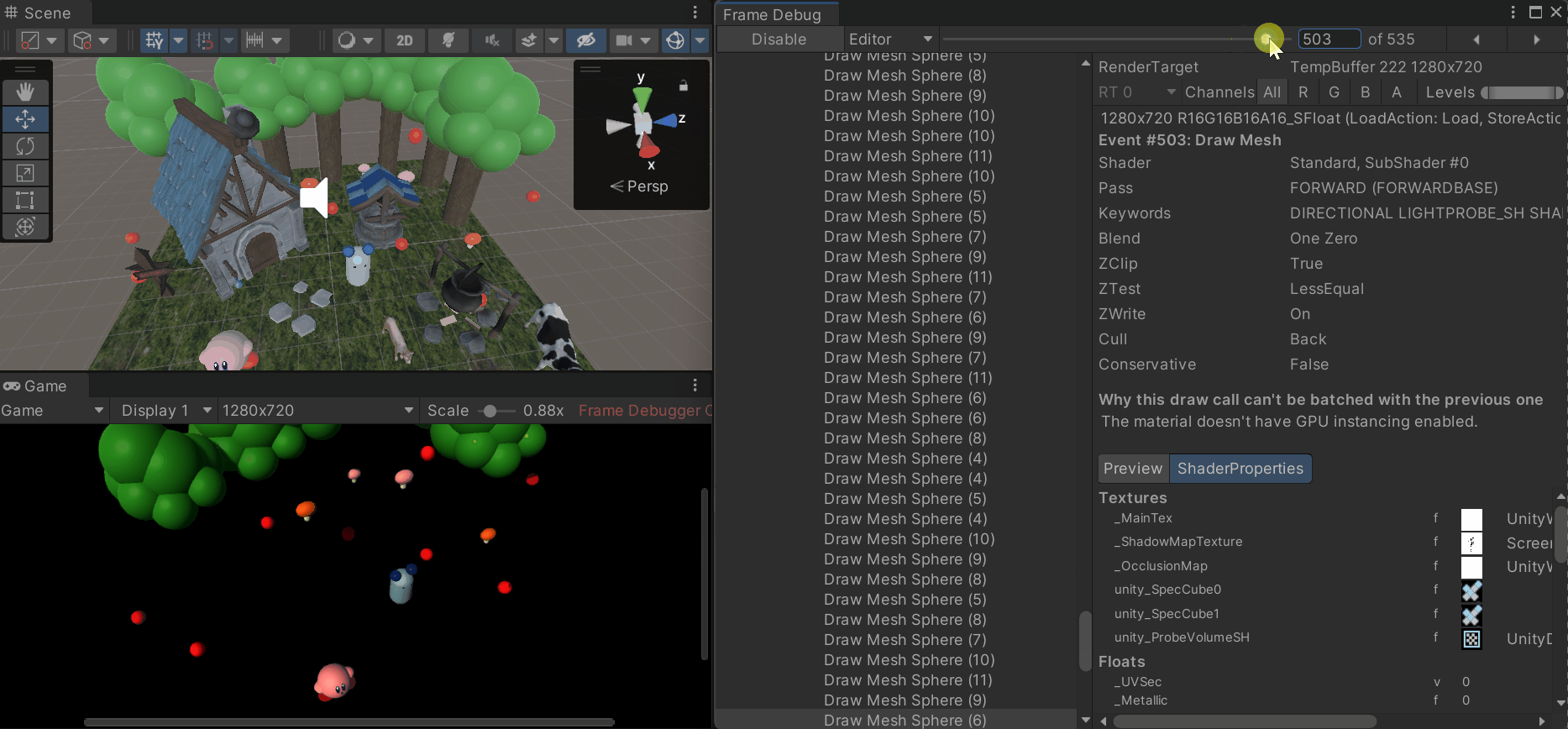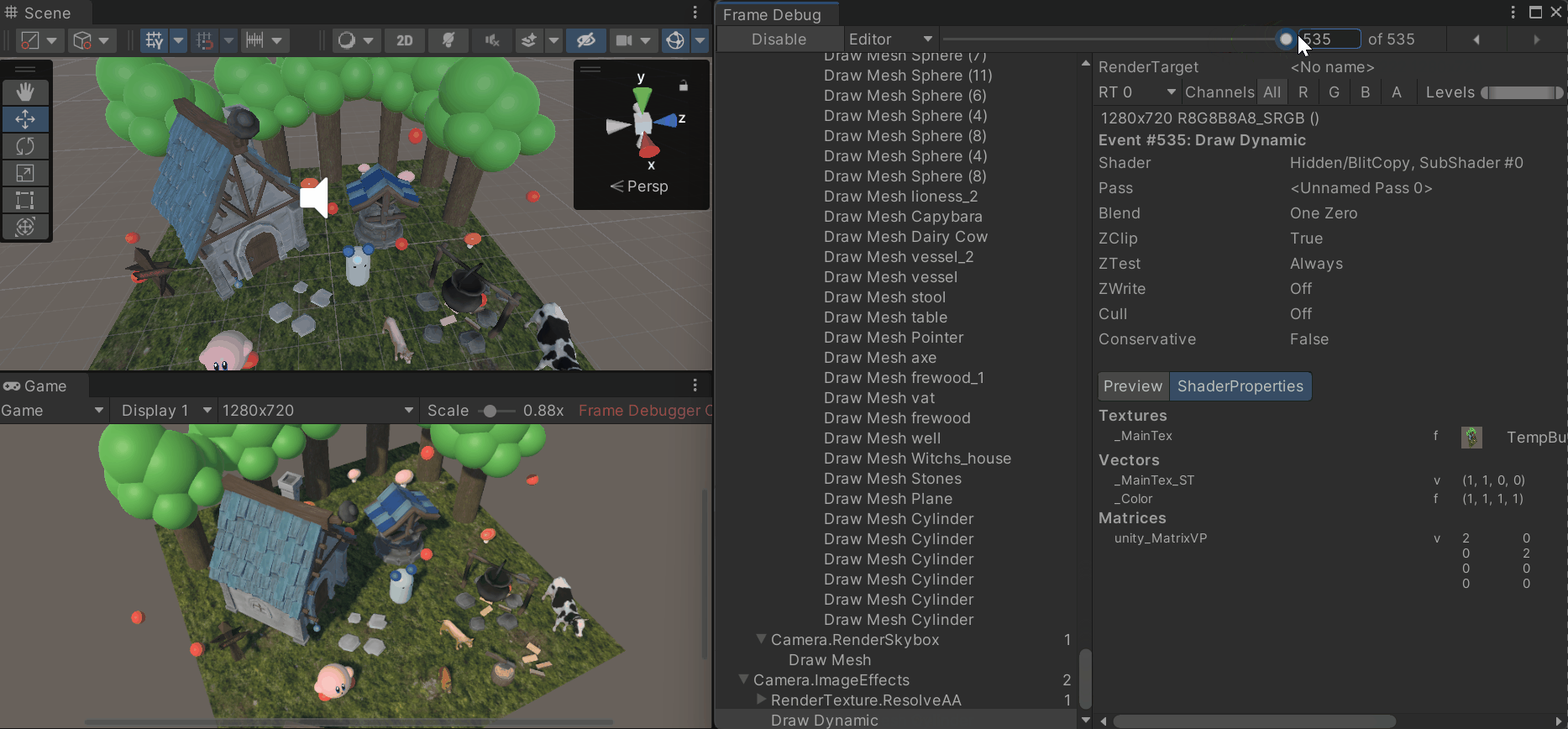
- 드로우콜과 배칭이 연결되지 않고 깨지는 경우 원인이 표시됨

4. 컬링 (Culling)
- 매 프레임마다 화면에 그려질 필요 없는 오브젝트를 걸러내는 과정
- 컬링 과정이 효율적일수록 드로우콜도 줄어들면 CPU와 GPU 성능 절약
1. 프러스텀 컬링 (Frustum Culling)
- 프러스텀: 카메라를 통해서 씬을 바라보는 영역
- 게임 엔진들은 카메라의 뷰 프러스텀(절두체)로 컬링이 수행되며 앞부분은 Near Clipping Plane, 뒷부분은 Far Clipping Plane

- 씬에 얼마나 많은 오브젝트가 존재하는가 보다, 렌더링 하는 프레임 내에 얼마나 많은 오브젝트가 뷰 프러스텀 내에 포함되는가를 따지는 것이 중요
- Far Clipping Plane을 조절해 렌더링 오브젝트 수를 줄이고 Fog를 활성화하여 여색함을 방지
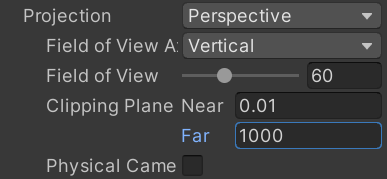

- 주로 Free Look, Top View, Quarter View 카메라에서 사용
2. 오클루전 컬링 (Occlusion Culling)
- 다른 오브젝트에 가려진 오브젝트를 걸러내는 기능
- 주로 실내 씬에서 사용 됨 (벽)
- Window > Rendering > Occulusion Culling 오클루전 창 하단의 Bake 버튼을 눌러 적용이 가능하고 Visualization버튼을 누르면 씬 뷰에서 미리 볼 수 있음
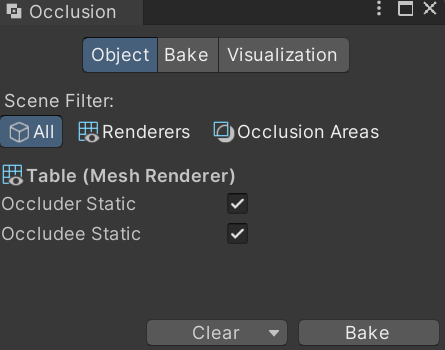
- 오클루전 스태틱 정보를 토태로 연산이 이루어지므로 오클루전 컬링이 적용되는 오브젝트는 스태틱 플래그를 설정해줘야 함
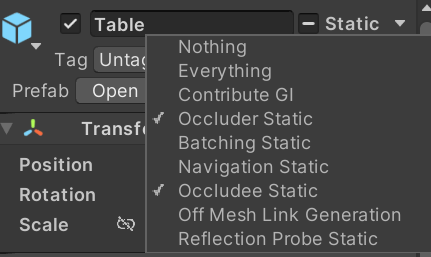
- Occluder: 다른 오브젝트를 가리는 역할
- Occludee: 다른 오브젝트에 의해 가려지는 역할
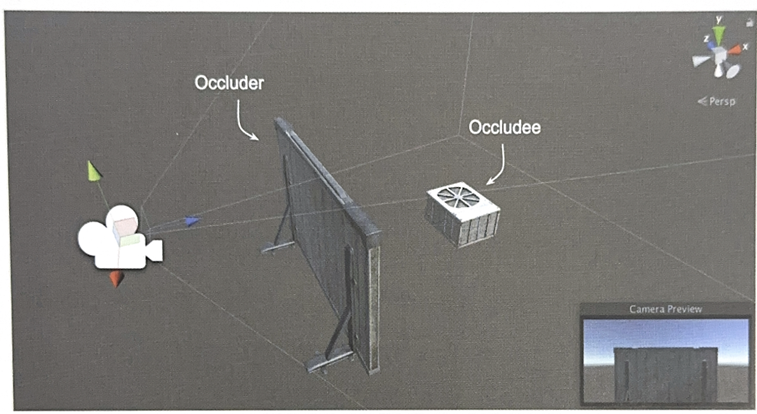 (그래서 보통 둘 다 체크하는데 걍 Static 다 설정하는게 일반적)
(그래서 보통 둘 다 체크하는데 걍 Static 다 설정하는게 일반적)
- 씬 전체의 정밀도 사전 연산을 위해 일정한 간격의 셀(cell)로 이루어진 데이터가 필요하므로 스태틱 오브젝트만 가능하다는 한계가 존재
- 하지만 Occludee는 다이나믹 오브젝트도 가능하며 Dynamic Occluded를 활성화해주면 됨 (주로 캐릭터에 적용)
- Occlustion Culling 창의 Bake 탭에 Smallest Occluder로 오클루전 컬링의 정밀도를 조절할 수 있음

- 당연히 데이터 크기가 늘어나고 연산 오브헤드가 발생할 수 있으므로 드로우콜을 줄임으로써 얻는 이득보다 큰지 확인하고 적절한 값을 찾아야 함
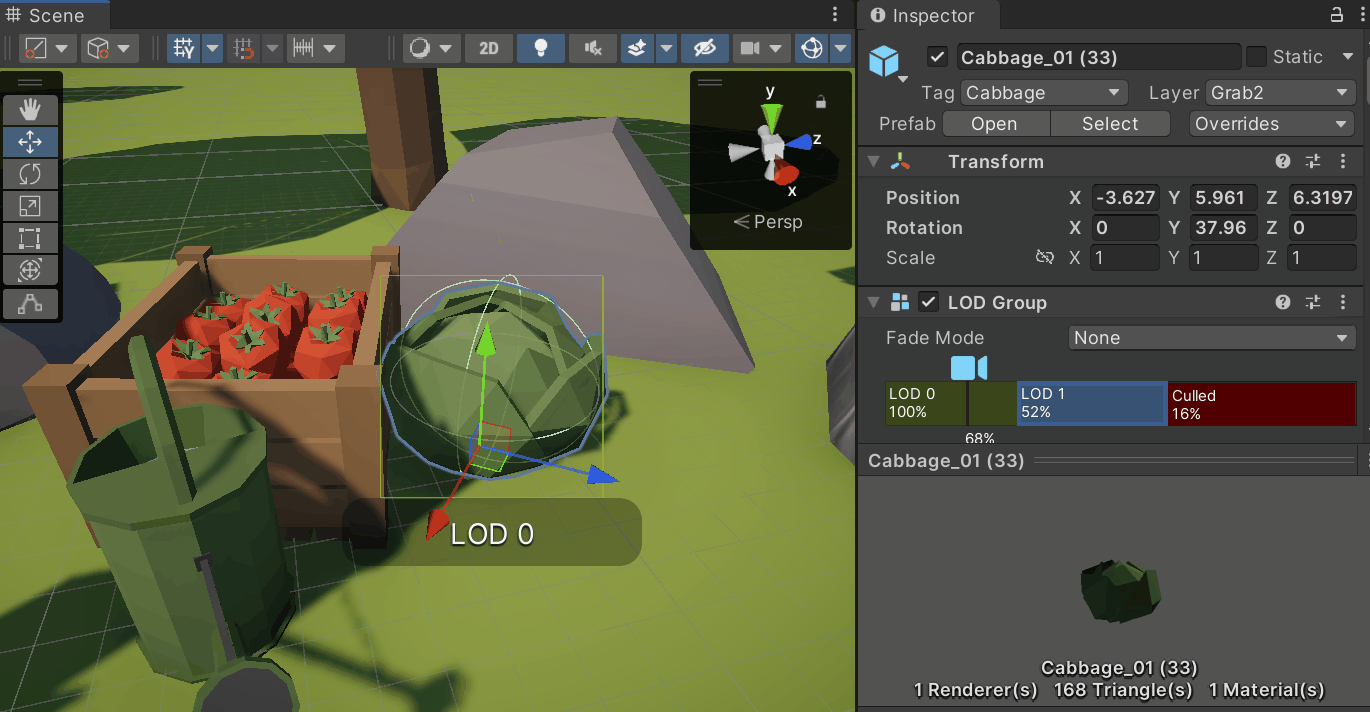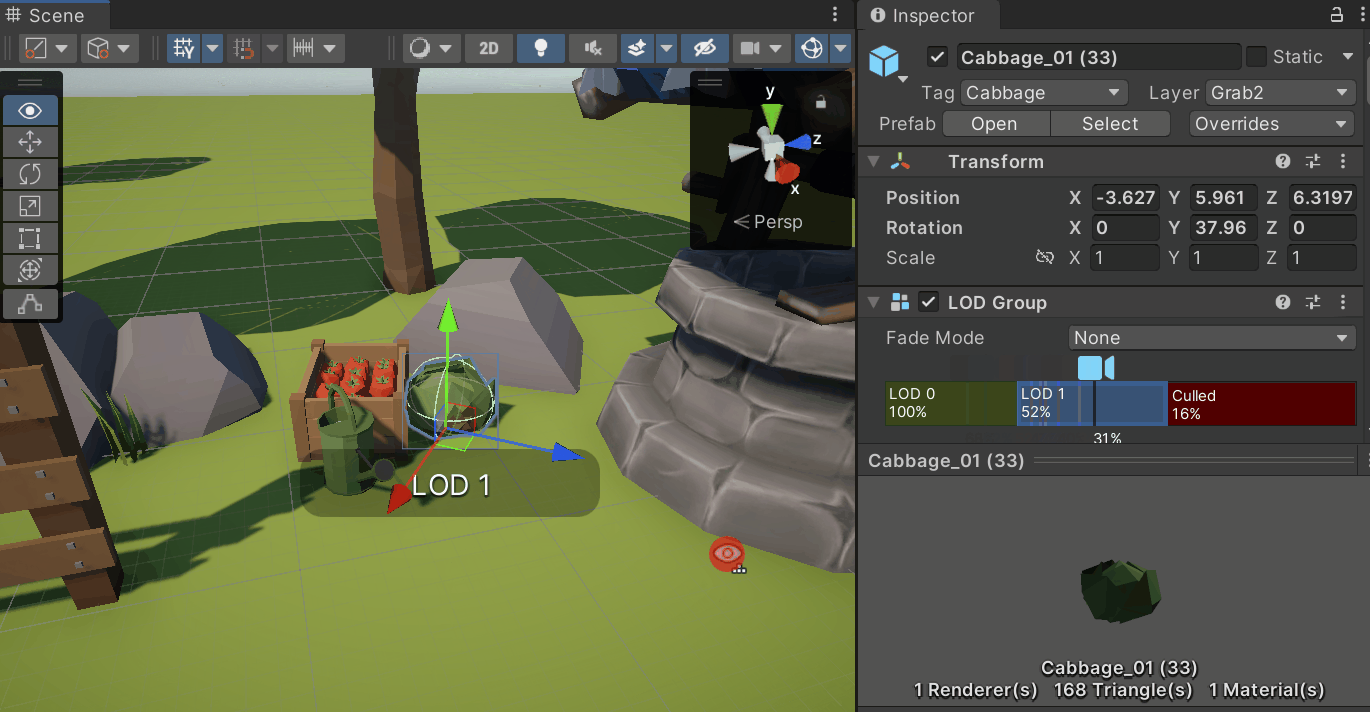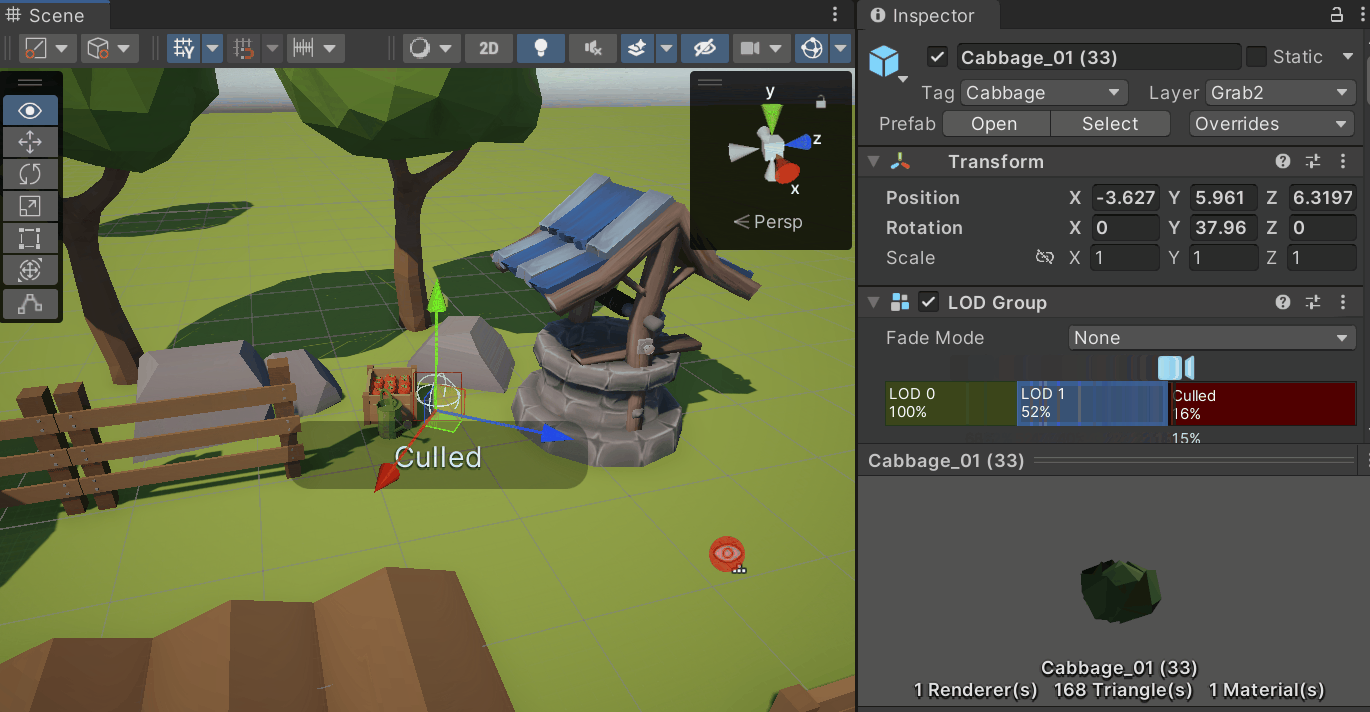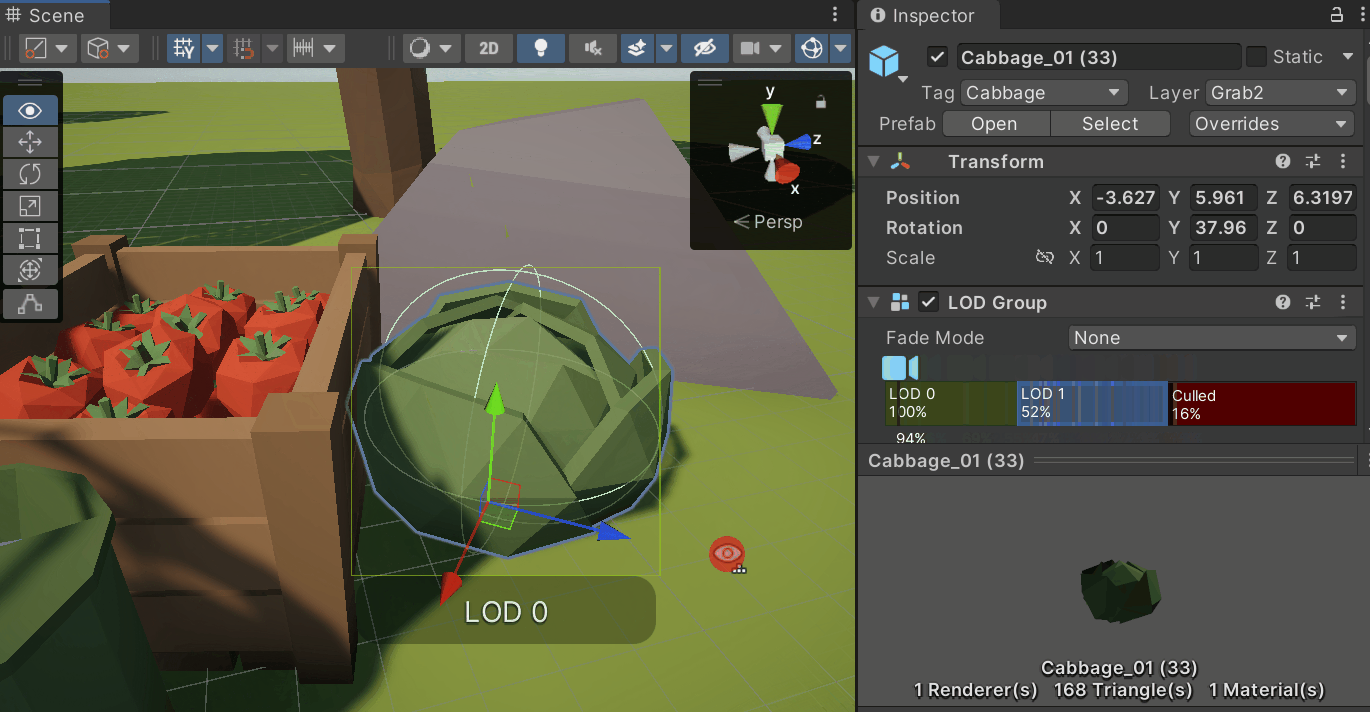
3. LOD (Level of Detail)
- 오브젝트의 시각적인 디테일을 여러 단계로 나누는 기술
- 야외 씬에서 주로 사용됨
- 뷰 프러스텀 내에 있더라도 멀리 떨어지거나 작은 오브젝트로 화면 차지 비율이 낮아지면 디테일을 떨어트려 드로우콜을 절약
- LOD Group 컴포넌트를 추가하고 각 LOD의 Renderers에 원하는 메시를 넣고 비율을 지정

( •̀ .̫ •́ )✧