GOAL
- 네트워크 애플리케이션 프로토콜의 개념적, 구현적 측면
- transport-layer service models
- client-server paradigm
- peer-to-peer paradigm
- Application layer에서 가장 많이 쓰이는 프로토콜들
- TCP vs UDP (Transport layer이지만 프로토콜과 밀접한 관계라서, 특징/사례)
- HTTP
- FTP
- SMTP / POP3 / IMAP
- DNS
- 네트워크 애플리케이션을 구현하기 위해 필요한 것?
- Socket API
1. Principles of network applications
Application Layer
Funtions
- 네트워크를 통해 서로 통신할 수 있도록 전달 가능한 데이터로 변환
In OSI model
- Application: 사용자와 인터넷 간의 인터페이스 제공
- Presentation: 데이터 해석/압축/암호화 등 데이터를 표현
- Session: 대화(dialog)를 생성하고 유지(데이터 교환의 경계, 연결)

Socket
- 프로세스와 네트워크 간의 소프트웨어 인터페이스로 호스트의 Application layer와 Transport layer 간의 인터페이스 (IP주소와 포트번호를 가진 인터페이스)
- 프로세스가 네트워크를 통해 통신하기 위해 필요
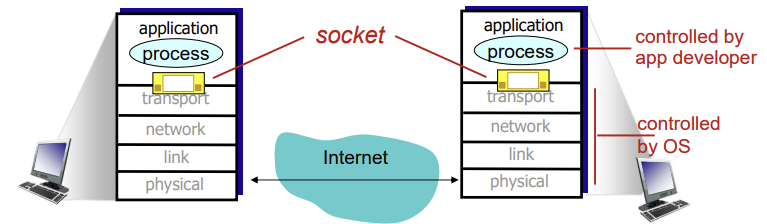
- process: 호스트(컴퓨터)에서 실행 중인 애플리케이션(응용 프로그램)
- 동일한 호스트 내의 두개 이상의 프로세스가 통신하는 경우, inter-process communication(OS에서 제공하는 프로세스 간 통신 기능)을 사용
- 다른 호스트 간에 프로세스들이 통신하는 경우, 메세지를 교환하여 통신
- process: 호스트(컴퓨터)에서 실행 중인 애플리케이션(응용 프로그램)
- Socket은 두 호스트를 연결해주는 일종의 통로역할
- 프로세스가 데이터를 받거나 보내기 위해 소켓으로부터 읽거나(read) 써야함(write)
- Socket은 프로토콜, IP주소, 포트번호로 구성되어있는 일종의 구조체이며, 소켓을 통해 통로가 만들어짐
- 역할에 따라 클라이언트 소켓, 서버 소켓으로 구분 됨
- 프로세스가 방이면 소켓은 문
- application layer와 protocol layer 사이의 네트워크 프로그래밍을 하는데 사용되는 도구, 인터페이스를 의미하기도 함
- 네트워크 애플리케이션이 인터넷에 만든 프로그래밍 인터페이스이므로, 애플리케이션과 네트워크 사이의 API라고도 함
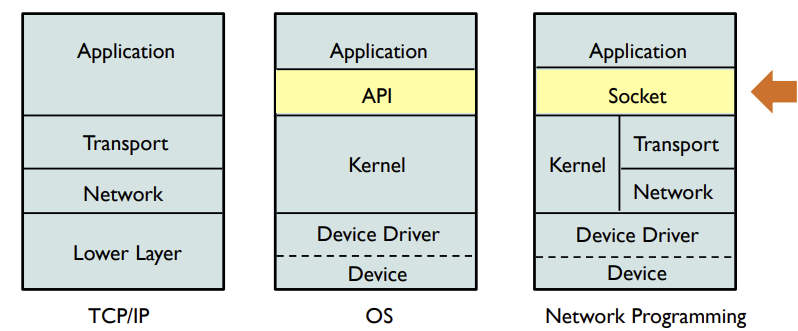
소켓 통신 함수 bind() & connect()
- socket(): 소켓을 만드는 함수
int socket(int family,int type,int proto)- family: 프로토콜 패밀리 지정 ex)PF_INET는 TCP/IP를 나타냄
- type: 서비스 유형 지정 ex)SOCK_STREAM는 TCP 소켓, SOCK_DGRAM는 UDP 소켓
- protocol: 특정 프로토콜 지정; 일반적으로 0(기본 프로토콜)
- bind(): 소켓과 프로세스를 묶어 해당 프로세스가 소켓을 통해 다른 컴퓨터로부터 연결을 받아들일 수 있게하는 함수 (소켓을 바인딩)
- connect(): 원격 호스트(컴퓨터)와 연결하는 함수
- 클라이언트가 소켓을 만들어 서버와 연결
connect()하고, 데이터를 서버로 보내고(요청)write()데이터를 받아온다read() - 그동안 서버에서는 소켓과 프로세스를 묶어
bind()클라이언트의 연결 요청을 기다리며accept()로 연결 요청을 수락, 클라이언트 쪽에서 요청한 데이터를 수신하고read(), 데이터를 작성write()해 보낸다. - 통신이 완료되면
close()로 소켓 연결을 종료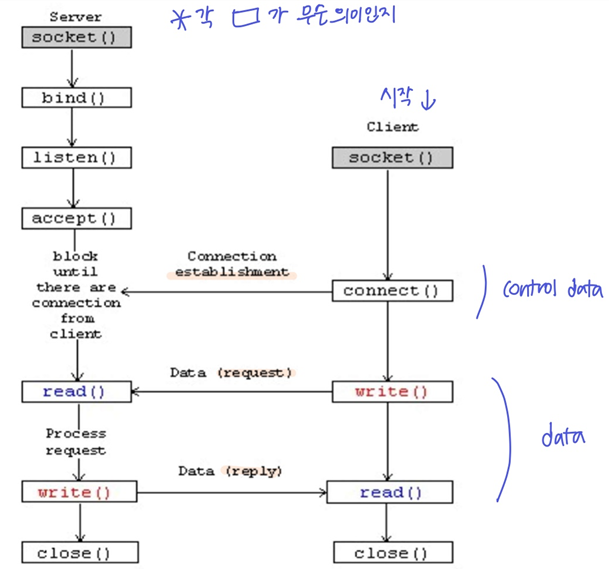
Network Applications
examples
create
- end systems에서 실행되고 네트워크를 통해 통신하는 애플리케이션을 만들 때, network-core 장치에 대한 소프트웨어를 작성할 필요가 없다.
- network-core 장치는 애플리케이션에 직접적으로 관여하지 않기 때문
- end systems의 애플리케이션은 빠른 개발과 배포를 가능하게 함
-> "no need to write software for network-core devices"
-> peer-to-peer protocol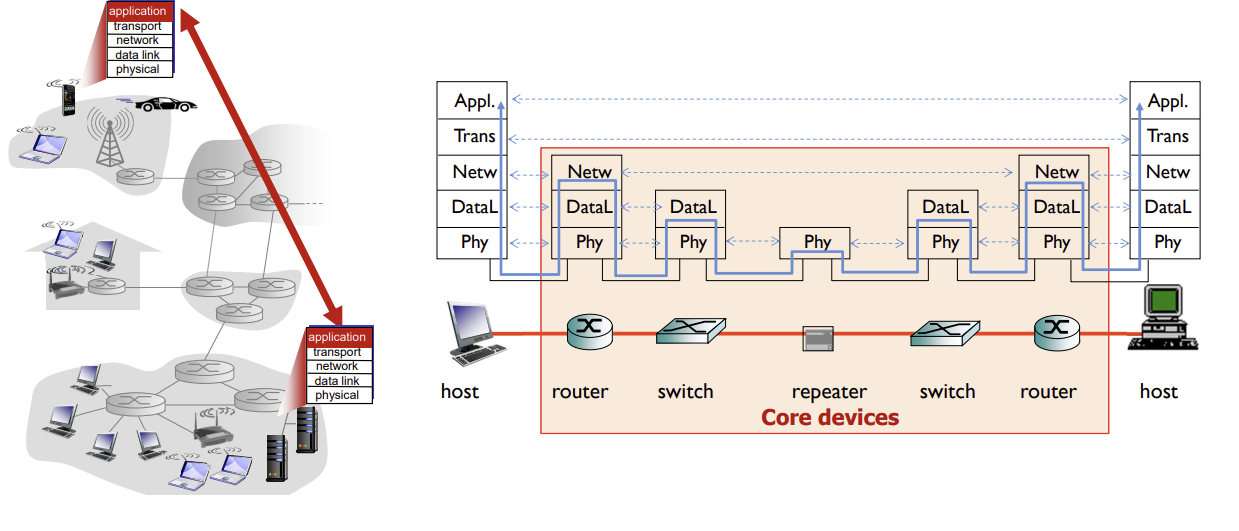
App-layer protocol
- App-layer protocol이 정의하는 것:
- types of messages exchanged (ex-요청, 응답)
- Message syntax (메세지 내의 필드가 무엇인지, 필드는 어떻게 구분하는지)
- Message semantics (필드 내 정보 의미)
- Rules for when and how processes send & respond to messages (프로세스가 메세지를 언제, 어떻게 보내고 응답해야하는지)
Open or Proprietary protocol
- Open protocol
- RFC 문서에서 정의되며, 서로 다른 제조업체나 시스템간의 상호 운용성(interoperability) 허용
- HTTP, SMTP
- Proprietary(독점적인) protocol
- 특정 회사나 제조업체에 의해 개발되고 소유되어 해당 제조업체의 제품 간 통신을 위해 사용
- Skype
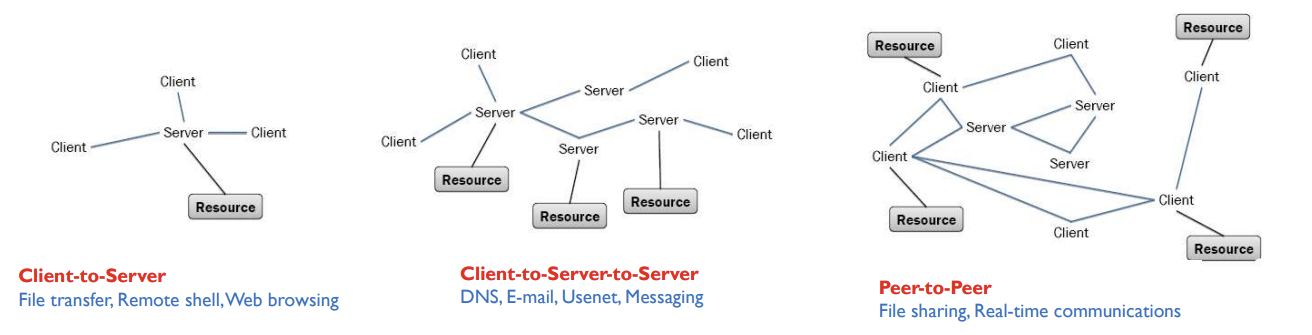
Application Architecture
- Client-to-Server
- peer-to-peer (P2P)
Client-to-Server model
server
- always-on host (항상 동작하는 서버)
- permanent IP address (영구적인 IP 주소)
- data centers for scaling
- 서버가 클라이언트로부터 오는 모든 요청에 더 응답하는 것이 불가능할 때, 많은 수의 호스트를 갖춘 데이터 센터가 강력한 가상의 서버를 생성하는 역할
Client
- communicate with server
- may be intermittently connected, may have dynamic IP addresses
- 때때로(간헐적으로) 연결되므로, 연결될때마다 IP주소가 바뀌니까 동작 IP 주소를 할당
- do not communicate directly with each other
- 다른 클라이언트들과 직접 통신하지 않으며, 서버를 통해 데이터 교환
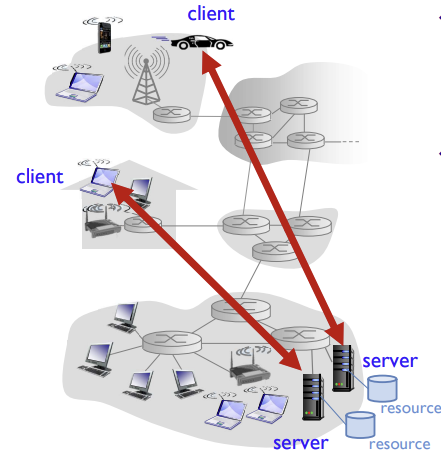
- 다른 클라이언트들과 직접 통신하지 않으며, 서버를 통해 데이터 교환
P2P model
- no always-on server (항상 켜져있지 않음)
- arbitrary end systems (Peer) directly communicate
- 대신 peer라는 간헐적으로 연결된 호스트 쌍이 서로 직접 통신 (특정 서버를 중심으로 하는게 아닌 분산 구조)
- peers request service from other peers, provide service in return to other peers
- 피어들은 서로에게 서비스를 요청하고 제공
- self scalability: new peers bring new service capacity, as well as new service demands
- 자가 확장성: 새로운 피어가 추가될 때 용량과 수요가 함께 증가
- 중앙 서버에 큰 부하가 가지 않고, 각 피어들이 자원을 공유
-> 비용적으로 효율적이지만 보안/성능/신뢰성에 문제가 생길 수 있음
- peers are intermittently connected and change IP addresses (complex management)
- 피어들은 주기적으로 연결되므로, 연결될때마다 IP주소가 바뀜 (복잡한 관리)
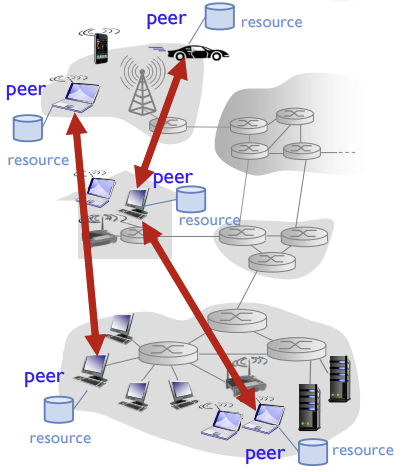
- 피어들은 주기적으로 연결되므로, 연결될때마다 IP주소가 바뀜 (복잡한 관리)
Evolution of Network App
- Client-to-Server: 파일 전송(서버에 업로드, 서버에서 다운), 원격 로그인, 웹 브라우징
- Client-to-Server-to-Server: 이메일 (나라별 서버로 전달할 때?)
- Peer-to-Peer: 파일 공유(피어 간에 직접 공유), 실시간 통신 (누구나 클라이언트, 서버가 될 수 있다.)
Transport Service (Transport layer)
why need?
- The Internet is based on datagram packet-switching technology
-> 이것은 간단하지만 연결없이 통신하며 신뢰성이 낮기 때문 (connectionless and unreliable) - Transport Service가 없다면 확인되지 않은 메일을 보내는 셈 (받는 사람이 알 수 없다)
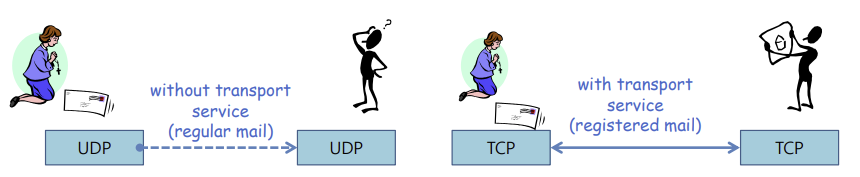
송신 측의 애플리케이션은 소켓을 통해 메시지를 보내고, transport protocol은 네트워크를 통해 그 메시지를 수신 프로세스의 소켓으로 이동시킬 책임이 있다.
key point
- transport protocol이 애플리케이션에게 제공할 수 있는 4가지 서비스
-
data integrity
- 데이터 무결성, 신뢰적 데이터 전송
- 송신 프로세스는 데이터를 소켓으로 보내고 그 데이터가 오류 없이 수신 프로세스에 도착할 것이라는 확신을 가질 수 있음
- 일부 앱은 100% 신뢰성 있는 전송(무결성)을 요구 (file transfer, web transactions)
- 다른 앱은 손실을 허용하기도 한다. (audio, 실시간 피드)
-> TCP/UDP의 결정 요소
-
timing
- 시간 보장 제공 (ex-송신자가 소켓으로 내보내는 모든 비트가 수신자의 소켓에 100ms 내에 도착하게 하게 함)
- 일부 앱은 effective하게 작동하기 위해 낮은 delay를 요구 (Internet telephony, interactive games)
-
throughput (=speed, 처리율)
- 가용한 처리율은 시간에 따라 변하므로 어느 명시된 속도에서 보장된 가용 처리율을 제공
- 일부 앱은 effective하게 작동하기 위해 일정 수준 이상의 throughput을 요구 (multimedia)
- 유연한(elastic) 앱들은 주어진 환경 내에서 최대한 활용하기도 함
-
security
- 송신 호스트에서 모든 데이터 암호화(encryption) 가능, 수신 호스트에서 해독 가능
TCP
- reliable transport between sending and receiving process (신뢰성 있는 전송)
- flow control(흐름 제어): sender won’t overwhelm receiver
- 수신 측이 데이터를 처리할 수 있는 속도로 송신 측이 데이터를 전송하도록 조절
- congestion control(혼잡 제어): throttle sender when network overloaded
- 네트워크 혼잡 상황을 감지하고 속도 제어
- connection-oriented(연결 지향): setup required between client and server processes
- 클라이언트와 서버에 패킷이 곧 도달할테니 준비하라고 알려주는 역할 (전송 제어 정보 교환)
timing,minimum throughput guarantee,security- 타이밍 서비스 제공X
- 최소 대역폭 보장 서비스 제공 안하므로 보장이 안돼서 보안 서비스도 제공X (신뢰성이 없다는 UDP의 security와 다름)
UDP
- unreliable data transfer between sending and receiving process (신뢰성 없는 전송)
reliability,flow control,congestion control,timing,throughput guarantee,security,connection setup- flow control이 없어 프로세스 속도 저하 없이 네트워크 이용 가능
- 하지만 congestion때문에 throughput이 낮아져 속도이 오히려 더 낮아질 수 있음
그래도 UDP가 존재하는 이유
- 낮은 프로토콜 오버헤드 -> 빠른 데이터 전송
- 실시간 애플리케이션 -> 손실을 허용하더라도 빠른 전송이 중요한 경우에 사용
- 신뢰성이나 흐름제어를 요구하지 않는 경우 효율적이고 간단한 프로그램을 작성할 수 있음
- TCP: garanteed(보장됨=무결성), flow/congestion control
- UDP: not garanteed(보장X, 손실 허용)
⭐ 아래 표 보고 어떤게 UDP인지 TCP인지 알 수 있어야 한다. (loss-tolerant가 UDP)
(typically TCP/UDP는 security에 따라 결정됨)
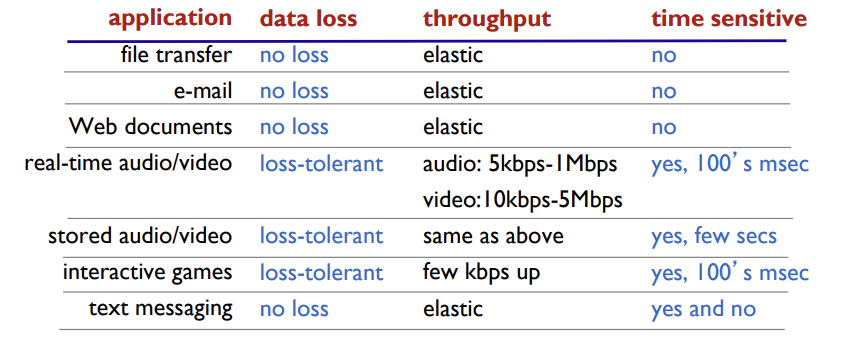
⭐ 채팅 app은 time-sensitive한가?
(= 어느 정도의 시간까지 전송된 것으로 간주할 것인가?)
- 일정 시간까진 time-sensitive하지 않다.
- 그 시간을 넘기면, 해당 채팅을 삭제할지, 재전송할지 판단(app 내에서)
여기서부터는 Application layer의 프로토콜
2. WEB and HTTP
Web
- 객체(Objects)로 구성
- 참조된 여러 객체들을 포함하는 HTML 파일로 구성
Object
- HTML, JPEG, Jave applet, audio file, etc...
URL(Uniform Resource Locator)
- 각 객체는 URL에 의해 주소 지정(host name+path name)
- 웹에서 객체를 찾고 접근하기 위한 경로
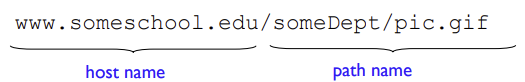
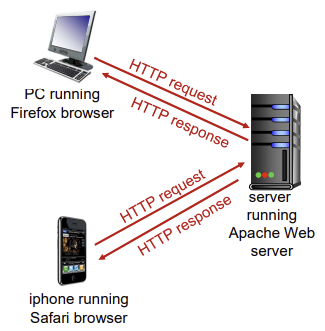
HTTP
- HyperText Transfer Protocol (web application layer의 프로토콜)
- 메세지의 구조 및 클라이언트와 서버가 메세지를 어떻게 교환하느지에 대해 정의
client/server model 사용
- HTTP client
- web 객체를 요청(request), 수신(receive), 표시(display)해주는 브라우저
- 웹의 관점에서는
브라우저=클라이언트
- HTTP server
- 요청(request)에 대한 응답(response)으로 web 객체를 보내는 서버
 (TCP 이후 과정)
(TCP 이후 과정)
- 요청(request)에 대한 응답(response)으로 web 객체를 보내는 서버
TCP 프로토콜 사용
- HTTP 클라이언트가 서버와의 TCP 연결 개시(initiate) = socket 생성
- 서버가 TCP 연결을 받아들임 (연결 성공)
- 서버와 클라이언트간 HTTP 통신이 이루어짐 (client/server model을 사용한 메세지 교환)
- 클라이언트는
HTTP 요청 메세지를 소켓 인터페이스로 보내고, 소켓 인터페이스로부터HTTP 응답 메세지를 받는다. - 반대로, 서버는 소켓 인터페이스로부터 요청 메세지를 받고, 응답 메세지를 소켓 인터페이스로 보냄
- 클라이언트는
- 다 끝나면 TCP 연결이 종료(closed)
- 이렇게 TCP를 통해 메세지를 보내면 신뢰성이 있으므로 모든 HTTP 요청 메세지가 서버에 잘 도착 (서버에서 보낸 것도 마찬가지)
- HTTP는 TCP가 어떻게 손실 데이터를 복구하고, 올바른 순서로 데이터를 배열하는지 전혀 걱정할 필요가 없음 -> 계층구조의 장점
HTTP is "stateless"
- 서버는 과거에 받은 요청들을 저장하지 않음 (클라이언트에 대한 정보 유지X)
- 클라이언트가 같은 객체를 두 번 요청해도, 서버는 전에 보냈다고 알려주지 않음
- 간단하고 고성능인 웹서버를 제공함 (수천 개의 동시 TCP연결을 처리해야 되거든)
- "state"를 유지하는 프로토콜은 복잡하다
- 과거 정보들이 모두 유지되는데 서버와 클라이언트가 crash되면, 서버와 클라이언트 간의 차이(inconsistent)가 생겨서 메꿔야함(must be reconciled)
History
HTTP Connections
- 위에도 적었지만 HTTP는 TCP연결 위에서 진행
- 이 과정안에서 TCP 연결, HTTP 요청, HTTP 응답, 총 세 가지의 교환이 이뤄진 뒤, 연결이 해제됨
- Connection establishment
TCP실제 HTTP 교환 전에 TCP 연결이 이루어저야함(sender와 receiver 연결)
- Data transfer
HTTP데이터 전송의 신뢰도 유지를 위해 전송 여부를 확인해야함
- Closed
TCP데이터 전송이 끝나면 TCP연결 해제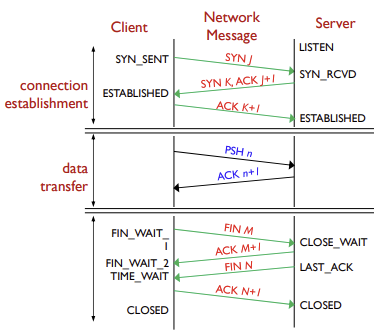
non-persistent HTTP (HTTP 1.0) vs persistent HTTP (HTTP 1.1, 2)
non-persistent HTTP
- 하나의 request는 오직 하나의 response
- TCP연결에서 하나의 객체만 전송됨 -> 각 객체 요청마다 새로운 TCP 연결/해제
- 여러 객체를 다운로드하려면 여러개의 TCP 연결 필요
클라이언트의 TCP연결 요청, 서버의 연결 수락 및 데이터 전송, 연결해제과정이 모든 HTTP request마다 반복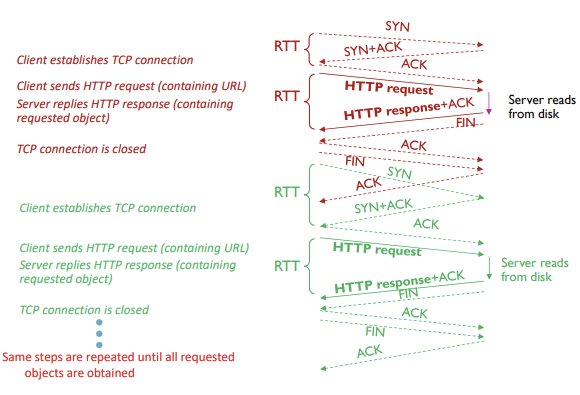
RTT(round trip time)
- 패킷이 클라이언트와 서버 사이를 왕복하는 데에 소요되는 시간
HTTP Response time
- Initiate TCP connection -> 1RTT
- HTTP request, 그리고 HTTP response 수신 시점까지 -> 1RTT
- Time to transmit file (파일 수신 시간)
-> non-persistent 상의 HTTP 응답시간 = 2RTT + 파일 수신 시간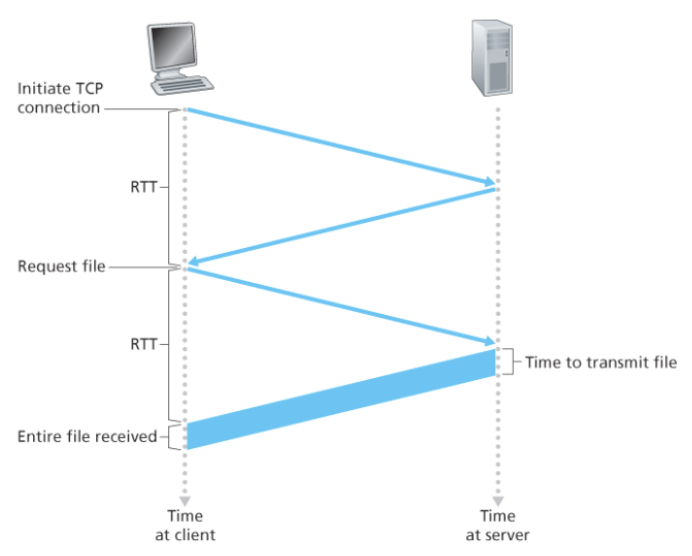
issues
- 각 객체마다 매번 2RTT를 필요로 함
- 웹 서버에 부담
-> 그래서 브라우저들이 병렬(parallel)로 TCP 연결해서 여러 object를 받아오고(fetch) 이후에 합치기도 함 -> persistent HTTP
persistent HTTP
- 하나의 request로 여러개의 response 가능
- 서버는 응답을 보낸 후에도 TCP연결을 해제하지 않고 계속 열어두기 때문에 열린 TCP 연결 위에서 연속적으로 HTTP request와 responce가 오감
- Single TCP 연결로 여러개의 객체가 전달될 수 있음
- 모든 데이터를 받은 후 연결을 닫을 수 있음 (일정 기간 사용되지 않으면 닫음)
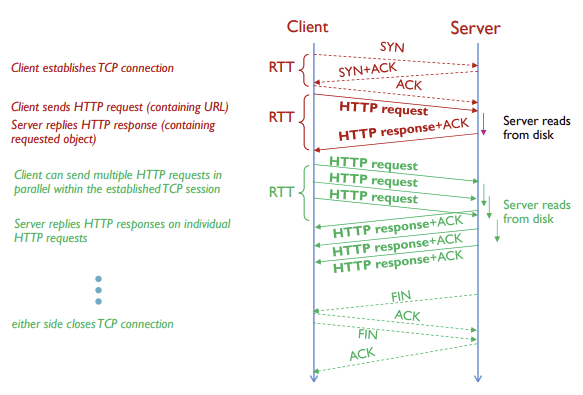
- fewer RTT (1RTT으로만 모든 객체에 대한 요청을 보낼 수 있음)
- lower CPU & memory usages, less congestion
HTTP Message Format
- 일반적인 HTTP message format (항상 이런게 아니라 대체적인 형태)
- HTTP message의 2가지 타입: request, response
- request message는 entity body가 비어있어 가볍고, response message는 데이터를 가지고 있어서 무거움
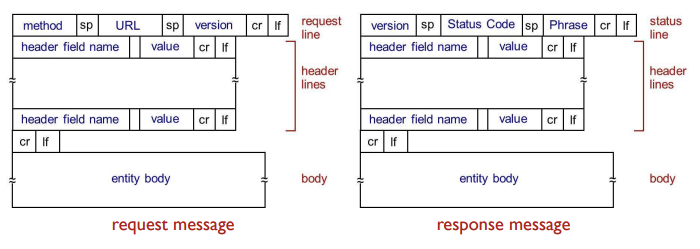
request message
- ASCII 텍스트로 구성 (human-readable format)
- 각 줄은 CR(carriage return)과 LF(line feed)로 구별되며 마지막 줄에 이어서 CR, LF가 따름
- 첫 줄이 request line, 이후는 header lines
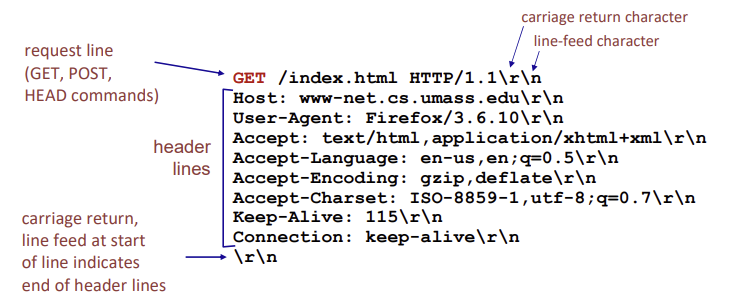
request line의 method field
- HTTP/1.0
- GET: 지정한 object 보여달라고 요청, 데이터를 가져올 때 사용
- POST: 웹 서버에 데이터 제줄하거나 저장, 첨부된 object를 서버에 업로드하도록 요청
- HEAD: 지정한 object의 metadata(데이터 정보) 요청, 실제 데이터의 내용(body)을 요청하지는 않음
- HTTP/1.1
- GET, POST, HEAD
- PUT: 지정한 URL에 (body에 들어있는)file 업로드
- DELETE: 지정된 URL에 있는 file 삭제
response message
- ASCII 텍스트로 구성 (human-readable format)
- 각 줄은 CR(carriage return)과 LF(line feed)로 구별되며 마지막 줄에 이어서 CR, LF가 따름
- 첫 줄이 status line, 이후는 header lines
- 마지막에 data들이 존재 (ex-requested HTML file)
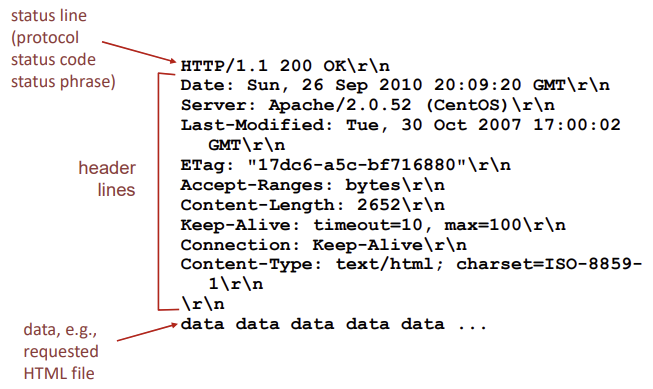
status line의 status code
- status code는 server-to-client response message의 첫 줄에 나타남
- status code와 status phrase(상태 코드와 메세지; 외울 필요X, 느낌만):
- 200 OK: 요청이 성공했고, 정보가 응답으로 보내졌다.
- 301 Moved Permanently: 요청 객체가 영원히 이동되었다. 이때, 새로운 URL은 응답 메시지의 Location 헤더에 나와있다.
- 400 Bad Request : 서버가 요청을 이해할 수 없다.
- 404 Not Found : 요청한 문서가 서버에 존재하지 않는다.
- 505 HTTP Version Not Supported : 요청 HTTP 프로토콜 버전을 서버가 지원하지 않는다.
Entity body
- HTTP version, language 따위가 들어감
- KEEP-Alive 항목이 있는 것 -> persistent HTTP라는 것
- GET일 때 비어있고, POST일 때 사용됨
- GET이면? body에 데이터 없음 -> 작은 파일 사이즈
- POST면? body에 데이터 있음 -> 큰 파일 사이즈
-> format에 따라 body는 상이 (ex-ID, PW의 글자수 제한은 body 내에 field 최대 용량으로 결정하는 것)
Cookies
HTTP는 "stateless"한 프로토콜로 작동, 그래서 웹 서버는 "forgetful" (서버는 클라이언트가 과거에 무슨 요청을 보냈는지 기억을 하지 못한다는 것 상기)
- HTTP 서버는 상태를 유지하지 않지만, 사용자와 서버 간의 상호작용에서 정보를 유지하고 기억하는 것이 필요한 경우가 존재 -> 쿠키 사용
- Cookies: 웹사이트에서 생성된 작은 데이터 조각으로, 사용자가 해당 웹사이트를 브라우징 하는 동안 사용자의 웹브라우저에 저장됨
- (장바구니와 같이) 유지할 필요가 있는 정보(state)를 기억하기 위해
- (로그인 기록, 과거 방문기록 등) 사용자의 브라우저 활동을 기록하기 위해
components
- HTTP response message의 cookie header line
- 다음 HTTP request message의 cookie header line
- 사용자(host)의 브라우저에 저장되는 cookie file
- Web site에 존재하는 back-end database
what cookies can be used for
- authorization (인증)
- shopping carts (장바구니)
- recommendations (추천)
- user session state (Web e-mail) (유저 세션-이메일 등)
생성 과정
- 웹 서버에 HTTP 요청 메시지 전달
- 서버는 브라우저에게 고유한 식별 번호(unique ID)를 부여
- 식별 번호로 인덱싱되는 벡엔드 데이터 베이스 안에 엔트리를 생성
- HTTP response message에
set-cookie: (식별 번호)의 헤더를 포함해서 전달 - 브라우저는 헤더를 보고, 관리하는 특정한 쿠기 파일에 그 라인을 덧붙임
- 다시 동일 웹 서버에 요청을 보낼 때:
브라우저는 쿠키 파일을 참조하고 이 사이트에 대한 식별 번호를 발췌하여cookie: (식별 번호)의 헤더를 요청과 함께 보냄 - client의 해당 ID에 대해 (ID가 맞는 경우) cookie-specific action
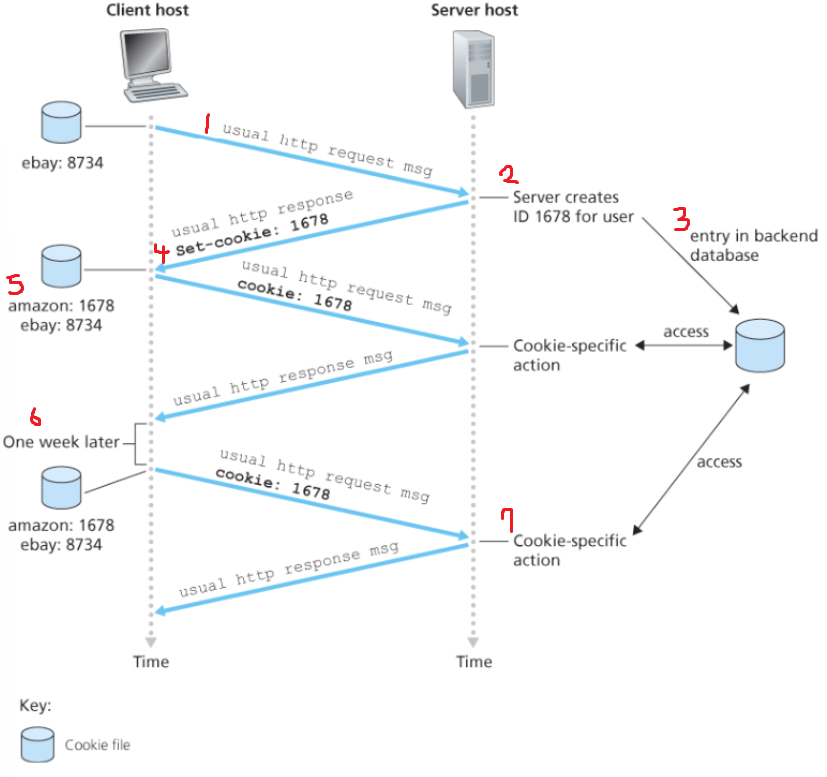 (쿠키는 클라이언트 측에 저장)
(쿠키는 클라이언트 측에 저장)
how to keep "state"
- protocol의 endpoints: 여러 transactions(거래)동안 클라이언트와 서버간의 상태 정보를 유지
- ex) 서버가 클라이언트의 이전 요청과 상호작용 내역을 기억해 다음 요청에 대한 응답 조정
- cookies: HTTP 메세지에 상태 정보를 포함하여 클라이언트와 서버 간에 상태 유지
cookies and privacy
- 쿠키를 사용하면 웹 사이트는 사용자에 대한 정보를 수집할 수 있게됨
- (오용될 경우) 이름, 이메일, 비밀번호 등의 민감한 개인정보가 암호화되지 않고 전송될 수 있음
Proxy Server (local Web Caches)
goal: 메인 서버를 거치지 않고(without involving origin server) client의 request를 해결하려면?
- 서버의 형태를 하고 있는 쿠키
- 목적지의 메인 서버가 사용자로부터 너무 멀어서, 메인 서버 대신 (영향을 끼치지 않고) 브라우저에 저장되는 것을 프록시 서버라고 함
- cache는 ISP가 운영 (하나의 네트워크를 운영하는 대학교, 회사 등등)
- user sets browser: cache를 거쳐 웹 서버에 접속
- 브라우저는 모든 HTTP request들을 cache로 전송(웹 캐시와 TCP연결)
- cache 안에 request한 object가 있다면 cache가 바로 클라이언트에게 보냄
- 없다면, origin server에 요청해서 받고(TCP 연결), 다시 클라이언트로 보냄
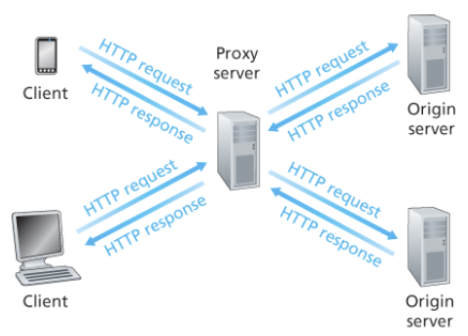
캐시는 요청과 응답을 모두 하는 클라이언트이면서 서버
- server for origin requesting client
- client to origin server
consistency (일관성)
- origin server는 consistent 해야한다 -> 모든 유저의 요청에 대해 동일한 response를 받아야 함
-> 여러 개의 proxy server를 일관성있게 여러 지역에 걸쳐서 사용
Delay
- Internet delay: HTTP request와 responce의 시간 차이(RTT)
Application layer - Access delay: 라우터와 라우터 사이의 지연
Network layer - LAN delay: 클라이언트와 라우터 사이의 지연
Physical layer - Total delay = Internet delay + Access delay + LAN delay
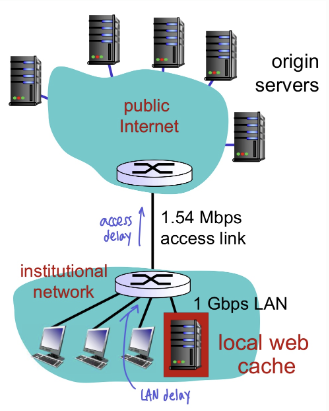
- delay를 줄이기 위해 phsical line을 교체하여 access link rate를 늘리거나, local web cache(proxy server) 사용
- proxy server가 줄여주는 delay는?
- internet delay (application layer니까)
- 사용하는 이유는?
- respnse time, traffic을 절약
- 인터넷 환경이 좋지 않은 "컨텐츠 공급자"가 효과적으로 전달하기 위해
- P2P의 경우 N개의 user = N개의 server = N개의 web cache
example (꼭 다시 정리하기)
- Web cache를 사용하지 않은 경우와 사용한 경우의 delay 비교
- 가정
- avg object size: 100K bits (패킷 크기)
- avg request rate (client -> origin server): 15/sec
- RTT (institutional router -> origin server): 2 sec (Internet delay)
- access link rate: 1.54 Mbps
- avg data rate to browsers: 1.50Mbps
- (1)client에서 origin server까지 15개의 object를 request하고, object size가 100K bits 이기 때문에 avg data rate는 15 * 100K bits = 1500K bits = 1.5Mbits 이다.
- (2)hit rate: 0.4
- 가정
1. Web cache를 이용하지 않은 경우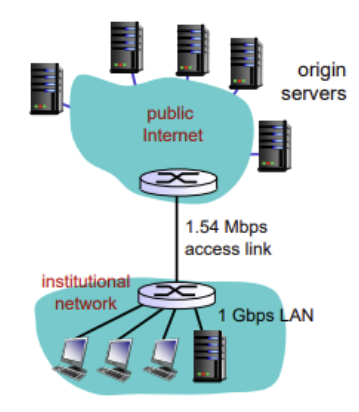
- institutional network가 public Internet에 1.54Mbps의 access link로 연결되어있음
- web cache를 이용하지 않는다면 이 access link를 거쳐 origin server를 다녀와야 함
- 1Gbps LAN이 깔린 institutional network에서는 1.5Mbps를 사용하여 데이터가 전달되므로 LAN delay=1.5Mbps/1Gbps 이다. (아주 여유로움; 수 마이크로초)
- access link에서는 1.54Mbps가 주어져 있는데, 1.5Mbps를 보내고 있으니, bandwidth에 거의 꽉차게 보냄
-> 1.5Mbps/1.54Mbps=0.97..로 엄청난 access delay (1에 가까울수록 큰 delay; 거의 수 분) - Total delay = Internet delay (2sec) + access delay(minutes) + LAN delay (1.5Mbps / 1Gbps)
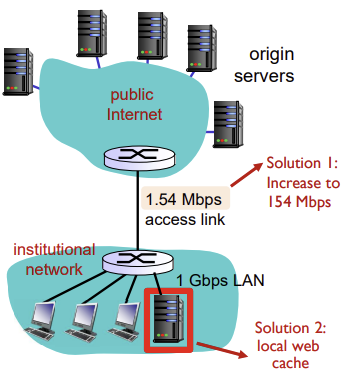
2. Web cache를 이용하는 경우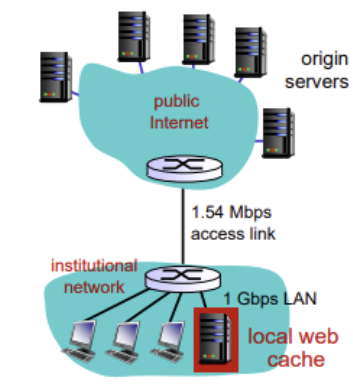
- hit이 40%라면, access link를 통과하는 데이터는 원래 지나던 데이터의 60%만 지남
-> LAN delay = 변화X (캐시나 서버나 어쨋든 LAN을 거치므로, 0.4L + 0.6L = 1) (수 마이크로초)
-> access delay는 1.5Mbps x (0.6)/1.54Mbps = 0.52..로 훨씬 감소 (수 분에서 수 밀리초로 줄어듦) - 서버까지 가는 딜레이 = Internet delay (2sec) + access delay(msecs) + LAN delay (1.5Mbps / 1Gbps) =~ 2.01
- 캐시에서의 딜레이 = 캐시 확인 딜레이 + LAN delay = (수 밀리초)
- Total delay = 0.6 x (delay from origin servers
2.01) + 0.4 x (delay when satisfied at cache(msec)) =~ 1.2 secs
❗결론: web caches를 사용하면 훨씬 적은 delay
Conditional-Get
- 웹 캐싱이 딜레이를 줄일 수는 있지만, 웹 캐시 내부에 있는 복사본이 새 것이 아닐 수 있다는 문제 야기
- 캐시가 최신버전이라면 새로운 객체를 보내지 않고, 이전 캐시된 버전을 사용하여 응답함
- 이전에 한 번 요청해서 돌려받은 리소스에 대해 다시 한 번 요청을 할 때, 불필요한 트래픽을 줄이기 위해 해당 리소스가 변경된 경우에만 다시 보내달라고 요청
- 조건부 GET (클라이언트의 요청에서 cache가 최신 버전일 때와 아닐 때)
Cache
- HTTP request에서 캐시된 복사본의 날짜 지정
If-modified-since: (date)
Server
- 캐시된 복사본이 최신 버전이라면 객체를 포함하지 않고 response
HTTP/1.0 304 Not Modified
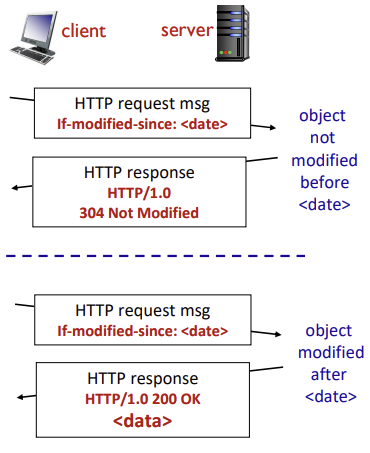
장점
- no object transmission delay (객체 전송 지연 없음, 새로운 객체를 기다리지 않음)
- lower link utilization (낮은 링크 활용도, 객체를 다시 전송하지 않으므로 네트워크 링크 부하 감소)
3. FTP
File Transfer Protocol
- TCP/IP suite에서 사용되는 주요 파일 전송 프로토콜
- 원격으로부터 디렉토리 목록을 나열하거나, 파일을 양방향으로 전송
features
- client/server model
- client: 원격으로부터 송, 수신하는 통신의 주체
- server: 원격 호스트
- Authentication control (인증 제어)
- 로그인, 비밀번호 관리 등
FTP Process
FTP process model
- FTP 프로세스 모델에는 두가지 모델이 있으며, 분리된 연결 구조(seperate connection)로 FTP 과정이 진행됨
- Control connections (1st TCP)
- FTP 세션동안 항상 유지되는 연결
- 데이터와 별개로 동작, 클라이언트와 서버 간의 명령 및 제어정보 교환 (out-of-band connection)
- Data connections (2st TCP)
- 연결이 필요할 때 동적으로 생성되는 연결

- 연결이 필요할 때 동적으로 생성되는 연결
과정 (seperate connection)
- 클라이언트가 TCP로 port21의 서버에 연결
Control connection - 클라이언트는 control connection으로 서버에 인증되고, 원격 디렉토리를 검색하고 명령을 전달
- 서버가 명령을 수신하면, 서버는 파일을 클라이언트로 전송하기 위한 두번째 TCP 연결
Data connection - 한 파일을 전송 한 뒤, 서버는 데이터 연결을 닫음
- 또 다른 파일을 전송하려면 또 다른 data connection
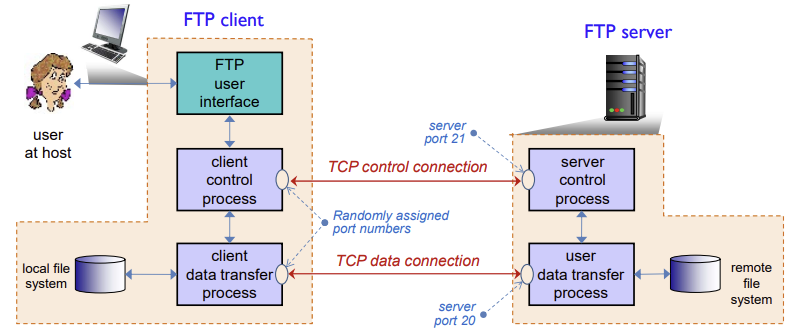
- Client control process에서는 서버의 response를 통해 data connection port num을 알려줌
- FTP 서버는 현재 디렉토리와 이전의 인증 정보를 유지 (State 유지)
- Login = control connection established / Logout = control connection terminated
FTP commands and Response
- HTTP와 헤더구조가 다름
- 하지만 HTTP처럼 모든 경우에 대응하는 status code가 존재

4. E-mail(SMTP, POP3, IMAP)
major component
- User agent ("mail reader")
- 메일 작성, 조회, 편집 등
- 송수신되는 메일은 mail server에 저장됨
- Mail server
- 사용자가 수신하는 메일 저장 (mailbox)
- to-be-sent 메일들의 전송 대기열 (message queue)
- SMTP(simple mail transfer protocol)
- 메일을 보내기 위해 메일 서버들 사이에 존재하는 프로토콜
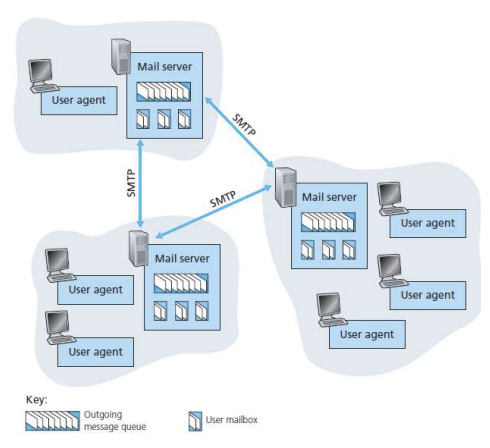
- 메일을 보내기 위해 메일 서버들 사이에 존재하는 프로토콜
Protocols for e-mail
- SMTP -> 서버로 메일 보낼 때
- mail access protocol -> 서버에서 메일 받을 때
- POP
- IMAP
- HTTP
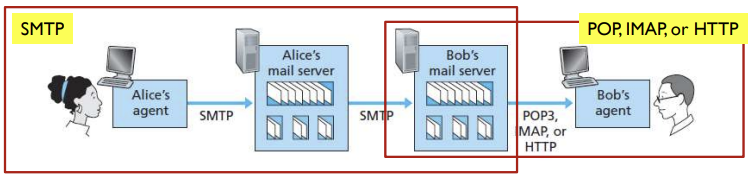
SMTP(Simple Mail Transfer Protocol)
- 클라이언트에서 서버로 메일을 전달하거나 서버 간 메일을 전달할 때 사용
- 대부분의 Application Layer protocol처럼 클라이언트와 서버를 가지는데, 상대 메일로 송신할 때는 클라이언트, 수신할 때는 서버(port 25)가 됨
- TCP vs UDP? 당연히 TCP사용 (손실 허용X)
- 3단계에 걸친 transfer
- handshaking (greeting)
- transfer of message
- closure
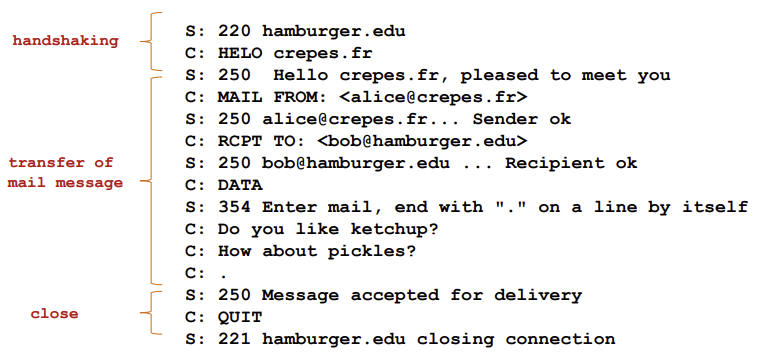
- HTTP나 FTP처럼 command/response interaction 존재
- commands: ASKII text
- response: status code and phrase
example
- Alice가 자신의 UA(User Agent)를 사용해 Bob의 메일 주소를 제공해 메세지를 보내라고 명령
- UA는 메세지를 메일 서버에 보내고, 메세지는 queue에 배치
- Alice의 메일서버의 SMTP 클라이언트는 Bob의 메일서버의 SMTP 서버에게 TCP연결 요청하여 메일 서버에 연결
handshaking - SMTP 클라이언트가 메세지를 Bob 메일서버로 전송하고
transfer더이상 보낼 메세지가 없다면 TCP를 닫음closure - Bob의 메일 서버가 수신한 메세지를 mailbox에 메세지 배치
- Bob이 자신의 UA를 호출해 메세지 읽음

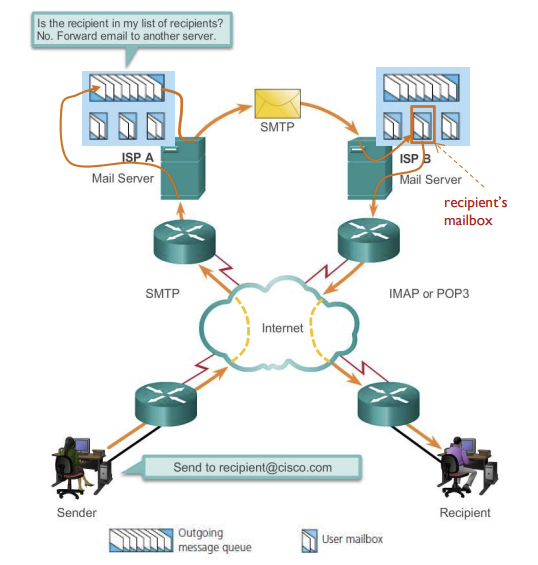 -> 두 메일 서버가 멀어도 중간 메일 서버를 이용하지 않으므로 메세지 전송에 실패하더라도 중간 메일 서버에 저장되는 것이 아니라 송신자의 메일 서버에 남아있음
-> 두 메일 서버가 멀어도 중간 메일 서버를 이용하지 않으므로 메세지 전송에 실패하더라도 중간 메일 서버에 저장되는 것이 아니라 송신자의 메일 서버에 남아있음
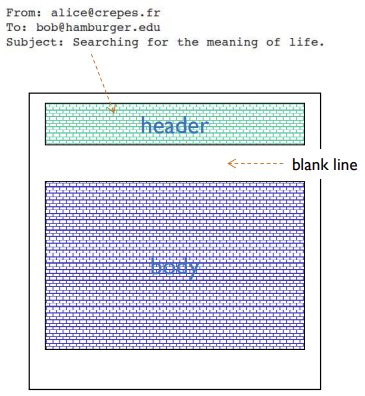
message format
- 7-bit ASCII code
- RFC 5322 (Internet Message Format)
- 헤더에는 메세지에 대한 구조화된 정보 (from, to, subject(제목), date등)
- 바디에는 메세지의 기본/본문 내용, 비구조화된 텍스트
- 헤더와 바디 사이에는 blank line 존재
POP3(Post Office Protocol-Version3)
- 메일을 서버로부터 받거나, 복사본을 다운할 때 사용
- TCP 사용 (TCP port 110)
- Authorization phase
- client commands: 유저이름과 비밀번호
- server responses: +OK와 -ERR

- Transaction phase
- list: list message numbers
- retr: munber로 메세지 되찾음(retrieve)
- dele: delete
- quit
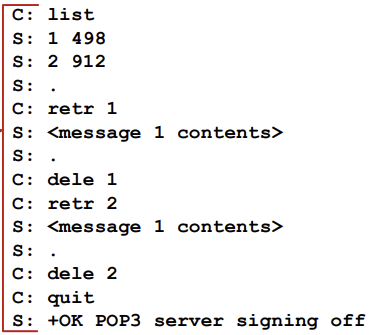
- Updata phase
- download and delete mode: 다운 받으면 다시 읽기 불가능
- download and keep mode: 클라이언트마다 다른 버전의 복사본 존재
delivery procedure (다시 정리)
- email
someone@example.com이 유저에게 제출됨 - SMTP서비스는 example.com을 해결하여 인터넷 상의 메일서버
mailserver1.example.com결정 - 이메일이 example.com 도메인으로 라우팅되어 메일서버
mailserver1.example.com의 SMTP에서 수신 - SMTP는 대상 메일 서버의 Queue폴더에 배치하고, delivery service는 새 이메일 감지
- delivery service는 이메일을 수신자의 메일박스인
P3_someone.mbx에 이동시킴 - 사용자는
someone@example.com의 메일 박스에 연결하여 이메일을 확인하고 POP3서비스는 사용자 자격 증명을 확인하고 연결을 수락하거나 거부 - 성공적으로 인증되면 이메일이 사용자 컴퓨터로 다운로드 됨
IMAP (Internet Mail Access Protocol)
- RFC3501에 정의된 인터넷 메일 접근 프로토콜
- POP3와 달리 서버에 모든 메세지 저장하고 관리할 수 있음
- 클라이언트가 이전 세션에서 작업한 폴더 이름 및 메세지 ID와 같은 정보를 보존(keep user state across sessions) -> 사용자 경험 향상
- 클라이언트가 메세지를 폴더로 구성하여 구조화하고 정리할 수 있음
- p.80 멀정리하지
5. DNS (Domain Name System)
- Distributed(분산), hierarchial(계층 구조) database
- 인터넷 상의 호스트 이름과 IP주소 간의 매핑 관리
- host name -> IP address로 해석
- IP address -> host name translation
- UDP 사용 (UDP port 53)
Why not centralize DNS?
- single point of failure: 전체 시스템이 마비될 수 있음
- traffic volume: 트래픽 부하로 인한 서비스 지연 및 다운타임
- distant centralized database: 중앙집중화된 데이터베이스를 유지하려면 네트워크를 통해 데이터를 전달해야하는데, 지연 및 오류 가능성을 증가시킴
- maintenance: 복잡하고한 유지관리를 필요로 함
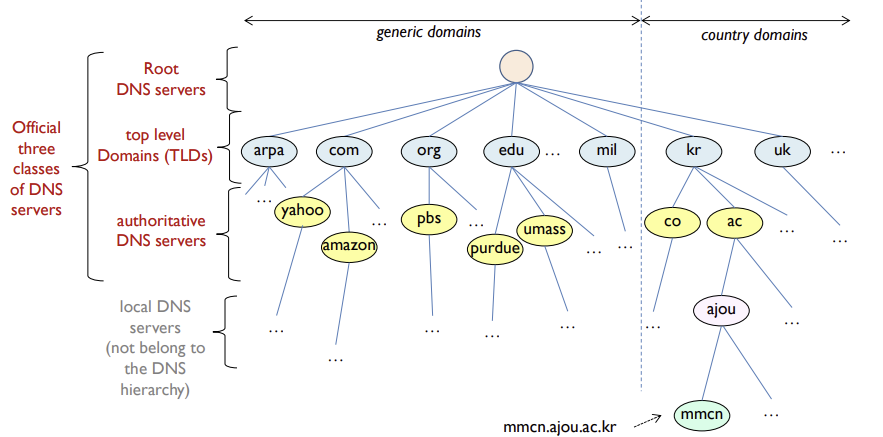
3 class of DNS(Tree 구조)
-
Root DNS Servers(루트)
- 많은 루트 서버 인스턴스가 세계에 흩어져 있음
- TLD 서버의 IP 주소 제공
-
Top-Level Domain (TLD) servers(최상위 레벨 도메인)
- 최상위 도메인에 해당하는 도메인 이름과 관련된 DNS 정보 관리 및 제공
com,org,net같은 상위 레벨 도메인(generic nameservers)과kr,uk같은 모든 국가의 상위 레벨 도메인(country nameservers)에 대한 TLD 서버 존재
- Authoritative 서버에 대한 IP 주소 제공
- 최상위 도메인에 해당하는 도메인 이름과 관련된 DNS 정보 관리 및 제공
-
Authoritative DNS servers (책임)
- 특정 조직(호스트)의 DNS 정보와 호스트의 도메인 이름을 IP주소로 해석하는 역할
- 인터넷에서 접근하기 쉬운 호스트를 가진 모든 기관을 호스트 이름을 IP주소로 매핑하는 공개적인 DNS 레코드를 제공해야하고, 기관의 Authoritative DNS서버가 이 레코드를 갖고 있는 것
- 조직의 자체 서버로 운영되거나, 관리 서비스 제공 업체에 의해 운영되거나
-
local DNS server
- 완전 계층 구조에 속하는 것은 아니고, DNS 구조의 중심에 존재
- 각 ISP는 local DNS 서버를 소유 (default name server)
- 호스트가 DNS query를 하면 local DNS 서버로 전송되고, 이 서버에서 IP주소를 호스트에게 제공
- 가장 최근에 조회된 <name, IP address> 쌍을 저장한 cache를 갖고 있음
- 만약 out of date라면 root로 올라가서 다시 조회 후 update
- stack 구조: 가장 최근에 조회된 쌍이 top일 것
- proxy server처럼 행동, 쿼리를 다음 계층으로 전달
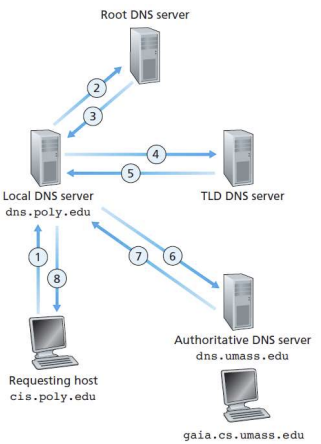
- 클라이언트가 DNS서버(local name server)에 특정 도메인 이름에 대한 IP주소를 물어봄
-> local name server가 도메인 이름을 해석할 수 없는 경우 root name server에 접근
-> root name server는 TLD 또는 authoritative name server에 접근해 도메인 이름을 해석하고, local name server에 다시 반환
DNS name resolution (이름 해석)
- 접근한 DNS서버가 쿼리를 해결하지 못한 경우(도메인 이름을 해석하지 못한 경우)에 대한 2가지의 mechanism이 있으며 DNS 쿼리의 비트에 의해 결정됨
1. Recursive queries
- 재귀 쿼리 (DNS쿼리의 기본 동작 방식)
- 쿼리를 다른 서버로 넘겨버림
- 클라이언트의 DNS서버가 모든 중간 서버와 연락하고 도메인 이름을 해석해야 하는 부담
-> 높은 계층에 있는 DNS 서버가 책임져야 하는 것이 많음(heavy load)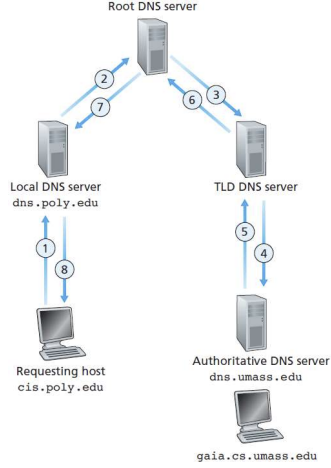
2. Iterative Queries (non-recursive)
- 반복 쿼리
- 클라이언트에게 다른 서버의 이름를 제공하고, "I dont know this name, but ask this server"라고 답함
- 클라이언트의 DNS서버에 적은 부담 (but, 클라이언트 자체가 중간 서버와 통신해야함)

Caching/Updating records
purpose
- delay를 줄이고, 인터넷에 DNS 메세지의 수를 줄이기 위해 (DNS쿼리 수 최소화)
DNS서버가 DNS응답을 받으면?
- <name, IP주소> mapping을 캐쉬에 저장
- TLD서버는 보통 local DNS 서버에 캐쉬됨 -> root로의 방문을 최소화
TTL(time to live) for cached entries?
- 캐쉬로 저장된 것은 일정기간(TTL; ex-2일)동안 보관 후 삭제됨
- 만약 name host가 IP주소를 바꾼다면? (저장된 캐쉬에서 IP주소가 갑자기 변경되면?)
-> TTL이 만료될 때 까지 모를 것
-> sol) update, notify mechanism
DNS records
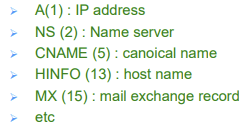
- DNS서버들은 호소트 이름을 IP주소로 매핑하기 위해 Resource Record(RR)의 형식을 따름
- RR format: (name, value, type, TTL)
(TTL은 자원 레코드의 생존 기간)
- RR format: (name, value, type, TTL)
Type = A
- Address
- Type A 레코드는 표준 호스트 이름의 IP 주소 매핑을 제공한다.
Name : 호스트 이름(hostname)
Value : 호스트 이름에 대한 IP 주소
Type = NS
- Name Server
- Name : 도메인(domain)
- Value : 이 도메인의 (내부의 호스트에 대한 IP 주소를 얻을 수 있는 방법을 아는) Authoritative DNS 서버의 호스트 이름
Type = CNAME
- Canonical NAME
- Name : 정식(canonical; the real) 호스트 이름의 alias name
- Value : 정식 호스트 이름
(servereast.backup2.ibm.com에서www.ibm.com가 정식)
Type = MX
- Mail eXchange
- Value : 이름과 관련있는 메일 서버의 이름
DNS messages
- DNS의 요청(query)과 응답(reply) 메세지는 모두 같은 포맷
- Header영역은 처음 12bytes
- Identification(식별자): 질의를 식별하는 16bits 숫자
- flags: query/reply, recursion desired, recursion available, reply is authoritative
- 나머지 4개의 Number 필드는 헤더 다음에 오는 데이터 영역의 네 가지 타입의 발생 횟수를 나타냄
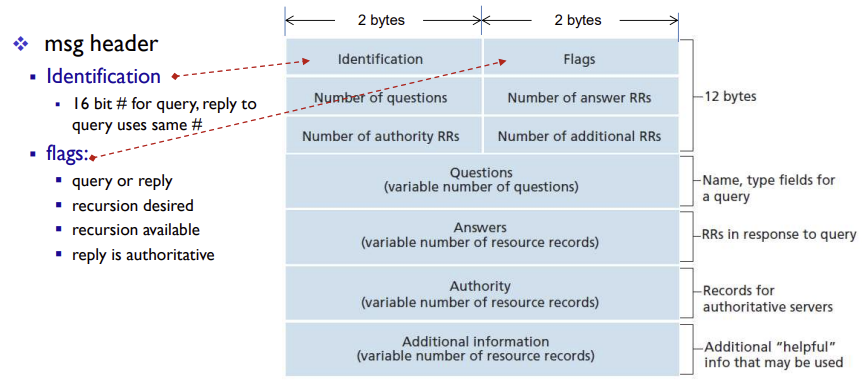
flag field
- OP (Operation Code):
- 0: DNS 쿼리(Query)
- 1: DNS 응답(Response)
- Query Type (쿼리 유형):
- 0: 표준 쿼리(Standard Query)
- 1: 역쿼리(Inverse Query)
- 2: 서버 상태 요청(Server Status Request)
- AA (Authoritative Answer):
- 이 플래그가 설정되면, 응답을 보내는 DNS 서버가 질문 부분의 도메인에 대한 Authoritative Answer임을 나타냄
- TC (Truncated, 잘린 응답):
- 이 플래그는 UDP를 사용할 때 응답의 총 크기가 512 바이트를 초과하는 경우 설정 (이 경우, 응답은 처음 512 바이트만 반환)
- RD (Recursion Desired, 재귀적 쿼리 원함):
- 0: recursive query
- 1: iterative query
- RA (Recursion Available, 재귀적 쿼리 가능):
- 1: 서버가 재귀적 쿼리를 지원하는 경우
- Response Type (응답 유형):
- 0: 오류 없음 (No error)
- 1: 쿼리 형식 오류 (Format error in query)
- 2: 서버 오류 (Server failure)
- 3: 도메인이 존재하지 않음 (Name does not exist)
Question Section
- 현재 질의에 대한 정보

- Query name: ex) 도메인 이름 "mmcn.ajou.ac.kr"의 표현

- Query type(or resource record type):
- Query class: 보통 인터넷 주소를 의미하는 1
Attacking DNS
DDoS attacks
- root 서버를 대상으로 트래픽을 폭발적으로 보내 공격
- 현재까지 성공적이지 않았음, Traffic filtering으로 대응
- 지역 DNS서버는 TLD서버의 IP를 캐슁해서 root 버서 우회 접근이 가능
- TLD 서버를 대상으로 트래픽을 폭발적으로 보내 공격
Redirect attacks
- Man-in-the-Middle(중간자 공격): DNS쿼리를 가로채고 재지정
- DNS Poisoning(DNS 독립): 가짜 응답을 DNS서버에 보내 캐시에 저장하게 함
Exploit DNS for DDos
- DDoS공격을 위한 DNS 악용
- IP주소를 위조해 DNS 쿼리 보냄
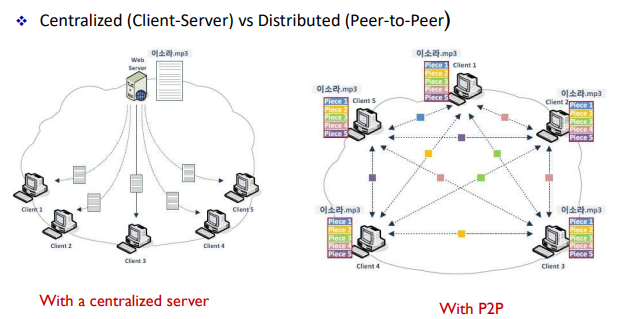
6. Peer-To-Peer (P2P)
(위에서 clinet/server 모델과 비교했음)
FTP(and HTTP)와 비교한 P2P
- 서버 없이 직접 컴퓨터에 연결
- 업로드, 다운로드 용이 (다운로드 속도 문제X)
- 파일 공유 관리는 어려움
P2P Architecture
- overlay network (기존 네트워크를 바탕으로 그 위에 구성된 또 다른 네트워크)
- 서버 중심이 아닌 Peer(end system)끼리 직접적으로 연결(link)되며, 각 링크는 하나 이상의 IP링크로 이뤄짐
- no always-on server
- 피어들이 주기적으로 연결되며 연결될때마다 IP주소가 바뀜
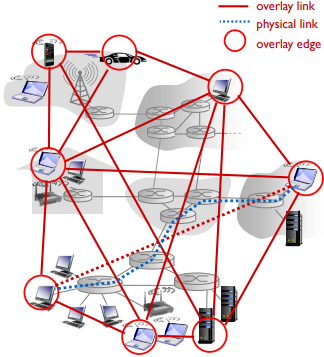
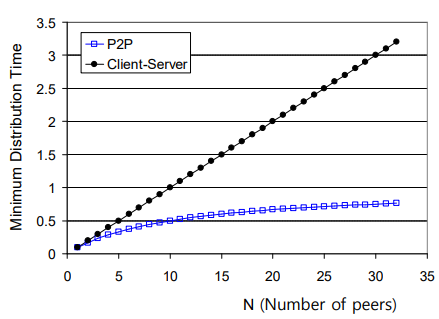
- Centralized은 peer가 많아질 수록 시간이 늘어나는데, P2P는 아님
Video traffic
- 비디오는 인터넷 bandwidth의 많은 부분을 차지
- challenge
- scale: 기하급수적인 규모의 시청자를 단일 서버로 수용할 수 없음
- heterogeneity(다앙성): 사용자마다 서로 다른 네트워크 환경
- solution
- distributed: 분산 서버 사용
- application-level infrastructure: 네트워크 환경을 app단계에서 조정
Video coding
- 영상: 일정 속도로 재생되는 이미지의 나열
- 이미지: 픽셀들의 나열
- spatial coding: 이미지에 같은 색상이 N번 반복되는 경우 <색상, N> 형태로 전송
- temporal coding: i+1th frame을 통째로 전송하는게 아닌, ith frame과의 차이를 전송
- P2P가 아닌 server-client 모델을 사용하는 video 프로토콜 (centralized)
Dash (Dynamic, Adaptive Streaming over HTTP)
- persistent HTTP
- Server
- 비디오 파일을 여러 chunks로 분할
- chunk는 네트워크 환경에 따라 다른 encoding rate로 저장됨
- manifest file: chunk마다 다른 URL 제공
- Client
- server-to-client bandwidth 수시로 측정
- bandwidth 따라서 manifest 수정
- 언제 chunk를 요청할지 (buffer starvation, overflow가 발생하지 않도록)
- 어떤 인코딩 속도를 요청할지 (해당 시점의 bandwith에서 가능한 최대 coding rate 결정)
- 어디서 chunk를 요청할지 (client와 가까운 서버 or high bandwidth 서버)
- DASH는 클라이언트가 서로 다른 품질 수준을 자유롭게 변화시킬 수 있도록 함
Challenge
- how to stream content to some N simultaneous users?
(수많은 비디오 중에서 선택된 콘텐츠를 수많은 사용자에게 어떻게 동시에 스트리밍 할 것인가?)
option 1. 하나의 엄청 큰 mega server -> X
option 2. CDN: 영상의 복사본을 세계 각지에 분산된 서버에 저장
CDN (Content Distribution Networks)
- 인터넷 스트리밍 서비스를 제공하는 가장 단순한 방법
- CND 노드에 콘텐츠의 복사본 저장
- CND 가입자가 CND에 콘텐츠를 요청
- 지리적으로 가장 가까운 복사본을 찾아냄
- 기존 네트워크 경로가 혼잡한 경우 다른 서버를 찾아갈 수 있음
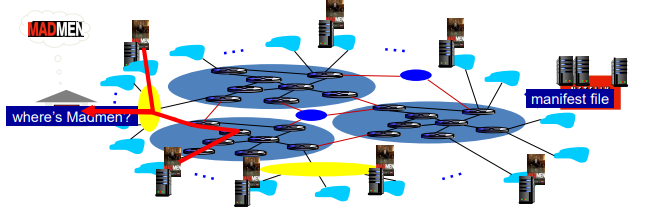
- CDN 서버 위치의 두 가지 철학 (둘 중 하나 채용)
- enter Deep
- CDN서버를 많은 access network(ISP)로 깊게 푸시 -> 서버를 최대한 사용자 가까이
- bring home
- access network 근처(IXP)에 large clusters 소수 배치 -> enter deep보다 throughput이 낮아 느리지만 유지보수가 편함
- 혼잡한 상황의 OTT(Over The Top) challenge
- from which CDN node to retrieve content? (어떤 노드에서 콘텐츠를 검색?)
- 지리적 환경이 무의미한 경우 server load, speed 등의 조건을 따짐
- 이러한 과정들이 over the top = 위에서 이루어진다
- viewer behavior in presence of congestion? (혼잡할 때 시청자는?)
- what content to place in which CDN node? (어떤 콘텐츠를 어느 노드에?)
- from which CDN node to retrieve content? (어떤 노드에서 콘텐츠를 검색?)
CDN Content access 과정
- 사용자가 비디오 요청 (URL 지정)
- CDN은 그 요청을 가로채(DNS) 클라이언트에게 가장 적당한 CDN 클러스터 선택
- 그 클러스터의 서버로 클라이언트 요청을 보냄
-
Client gets URL for video
(clinet가 URL 입력) -
resolve the URL via client's local DNS server
(client의 로컬 DNS 서버에서 URL 해석) -
host's DNS changes URL for specific CDN node
(영상 host의 DNS가 URL을 특정 CDN 노드(clinet에게 적당한)로 변경) -
resolve the CDN node URL via CDN's DNS
(선택된 CDN의 DNS로 CDN 노드 URL 해석) -
returns the IP address of CDN node with video
(비디오를 포함한 CDN 노드의 IP주소 반환) -
requesting video from CDN server via HTTP
(HTTP를 통해 CDN서버에서 비디오 요청)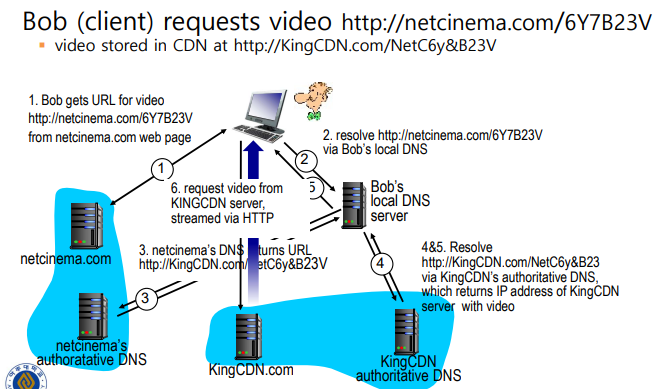
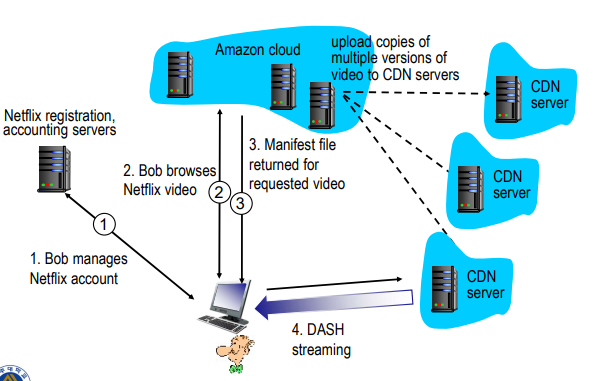
- 즉, 웹사이트 따로, 스트리밍하는 서버가 따로 있어서 DNS서버를 사용해서 다른쪽의 URL을 얻고, 그 URL로 가서 사용자가 거기의 서비스를 활용할 수 있게 해줌
- Netfilx 실제 사례
DHT (Distributed Hash table)
- 기존 데이터 베이스는 key-value 쌍 존재
- key를 통해 DB 조회(query)
-> 더 간편하게 저장, 검색할 수 있는 형태로 고안된 것이 Hash table
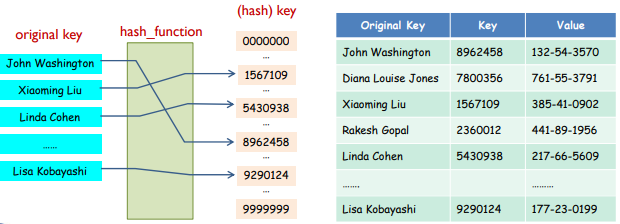
Hash table
- key = hash_function (original_key)
- original key 대신 그 hash 값을 key로써 사용, hash로 DB query(요청)
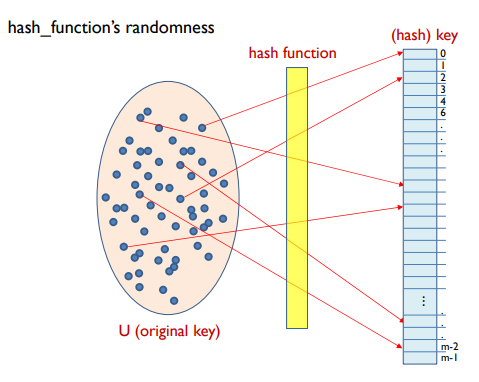
Distributed Hash table
- DB에 저장되어있는 (key, value)쌍을 수많은 peer들에게 균등하게 분산
- 어떤 peer든 key와 함께 DB를 query할 수 있음
-> DB는 key의 value를 반환 - 각 peer는 소수의 다른 peer에 대해 알고 있고, query를 해결하기 위해 약간의 peer간의 메세지가 교환됨
DHT key-value
- 각 peer는 고유한 ID를 가지고, ID는 무작위로 생성됨
- 가장 가까운 ID를 가진 peer에게 key-value 쌍 할당
(이 peer는 key의 immediate successor) - n비트 ID 공간의 범위는 [0, 2^(n-1)]
- ex) 6비트 ID 공간 {0, 1, ..., 63}
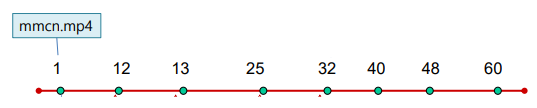
ex) ID가 1, 12, 13, 25, 32, 40, 48, 60인 8개의 peer
- if key=51 -> peer 60에 할당
- if key=60 -> peer 60에 할당
- if key=61 -> peer 1에 할당
DHT-P2P
- ex) ID가 1, 12, 13, 25, 32, 40, 48, 60인 8개의 peer
- Storing key-value
1-1. peer 1에mmcn.mp4존재
1-2. peer 1이mmcn.mp4의 hash key 얻음 -> 28
1-3. peer 32에 key-value쌍 (28, 1)이 저장 (closest peer)- ( hash key of file
28, peer ID of file1)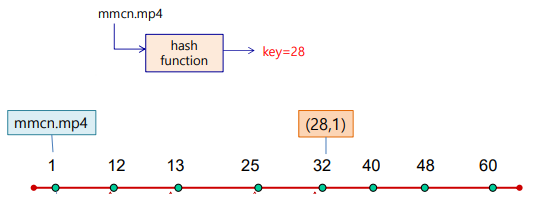
- ( hash key of file
- searching and getting file
2-1. peer 13이mmcn.mp4원함
2-2. peer 13이 파일의 hash key인 28을 얻음
2-3. peer 13이 28 key를 가지고 있는 peer에게 query -> peer 32 알아냄
2-4. peer 32가 peer 13에게 (28, 1) 반환 -> peer 1에 파일 있음을 알아냄
2-5. peer 13이 peer 1에게mmcn.mp4요청
2-6. peer 1이mmcn.mp4를 peer 13에게 전송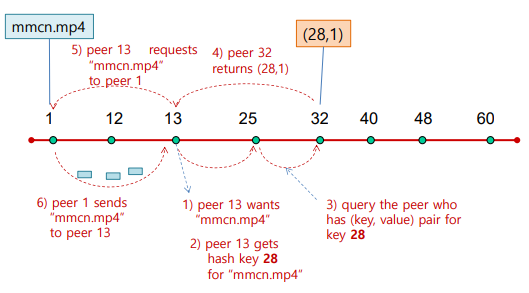
- Updating key-value
3-1. 이젠 peer 13도mmcn.mp4를 가짐
3-2. peer 32에 (28, 13) 저장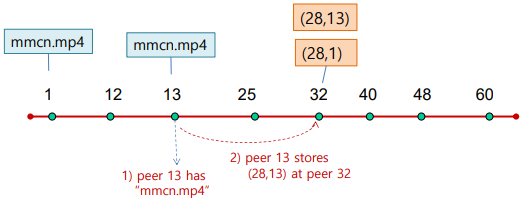
- Searching and getting file
4-1. peer 25가mmcn.mp4원함
4-2. peer 25가 key 28을 가진 peer에게 query -> peer 32 알아냄
4-3. peer 32는 (28,1), (28, 13) 반환
4-4. peer 25는 peer 1과 peer 13에게mmcn.mp4요청
4-5. peer 1과 peer 13이mmcn.mp4를 peer 25에게 전송
Cirular DHT
- peer들이 ID 순서에 따라 원으로 구성
- 각 peer는 immediate successor(다음)와 predecessor(이전)만 안다. (앞/뒤 peer만 앎)
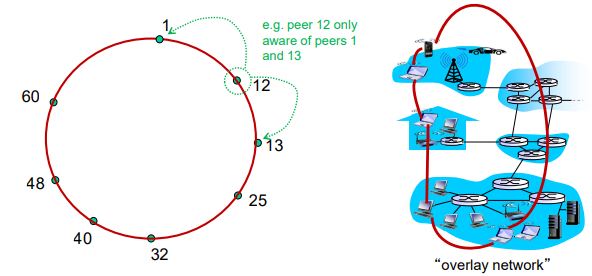
- N개의 peer가 있으면, query를 해결하기 위해 보통 O(N)개의 메세지 필요
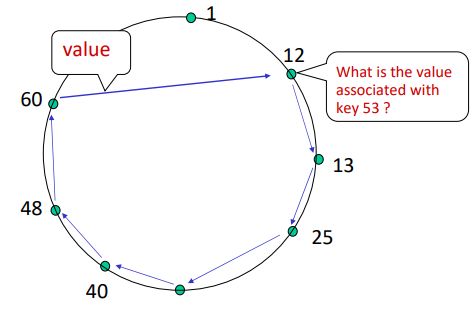
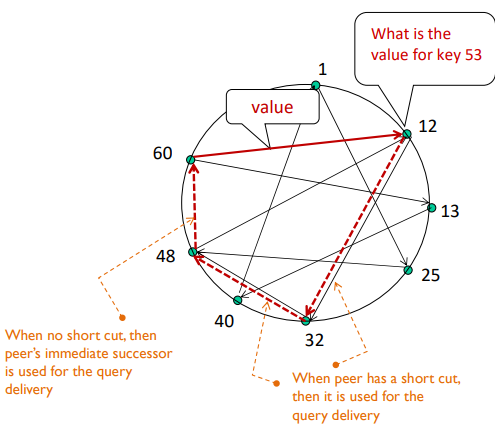
- 각 peer는 이전(predecessor), 다음(successor) 및 short cuts의 IP주소를 추적
- Short cut이 있으면 빠르게 query를 전송할 수 있다 (없다면 immediate successor이 사용됨)
- 메세지 수를 줄일 수 있음 (아래 이미지에서 6개에서 3개로)
- O(N)에서 O(logN)으로
peer churn
- peer는 경고 없이 들아갔다 나갔다 할 수 있다
- peer churn을 처리하기 위해
- 각 peer는 2개의 successors peer 주소를 알고 있음
- 각 peer는 주기적으로 2개의 successors peer에 ping을 보내서 확인
- ex) peer 5가 갑자기 사라진 경우
- immediate successor이 사라지면, 그 다음 peer를 새로운 immediate successor로 선택
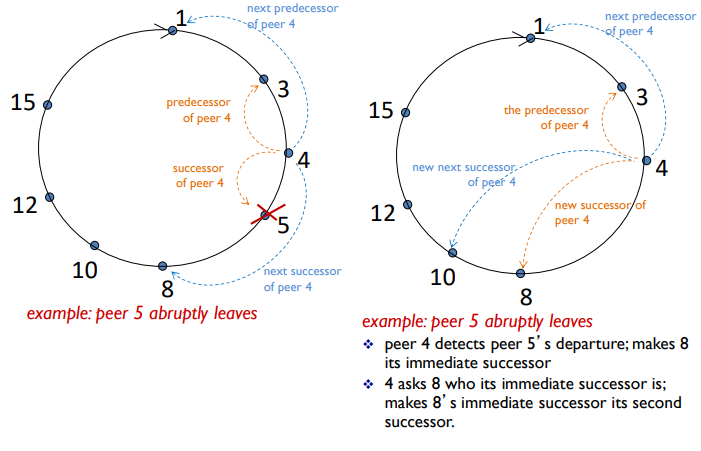
- immediate successor이 사라지면, 그 다음 peer를 새로운 immediate successor로 선택
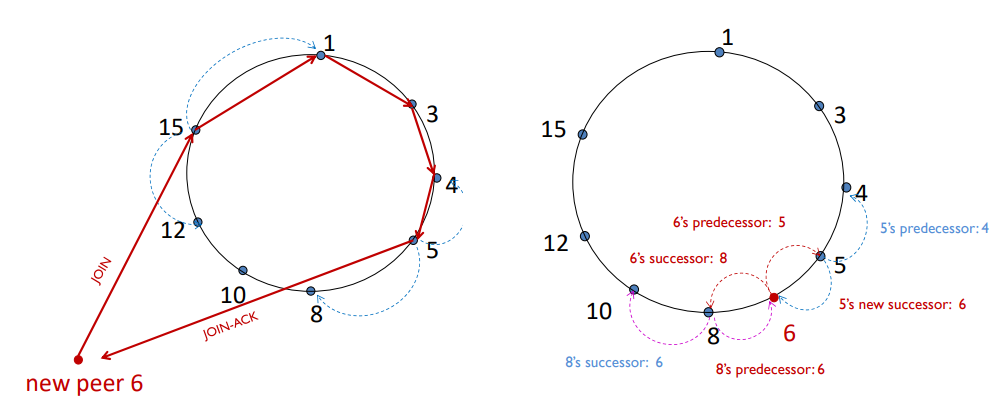
- ex) peer 6이 갑자기 생기는 경우
- peer 6이 peer 15만 안다면
- peer 6이 peer 15에게 가입 요청 보냄
- peer 15는 pred: 12, succ: 1이므로 peer 6이 들어갈 자리 없음, 가입 요청을 1로 보냄 (peer 1, 3, 4도 동일)
- peer 5는 pred: 4, succ: 8이므로 peer 6이 들어갈 자리가 있음
-> peer 6에게 자신의 pred, succ 정보를 보냄 - peer 6은 받은 정보로 자신의 pred, succ 설정
- peer 8과 5도 그들의 이웃 정보를 업데이트
P2P Systems and Applications
P2P systems
- 두 종류: Centralized / Distributed 네트워크 구조
- 각 노드(peer)들은 server, client로 모두 작동
- 모든 peer들은 동일한 능력과 책임을 가지며, 모든 통신은 대칭적이고 분산적
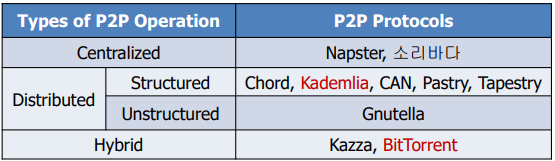

BitTorrent P2P System
- Hybrid 네트워크 구조 (Centralized + Distributed)
- tracker-based, centralized 구조: 서버가
.torrent파일 관리 - trackerless, decentralized 구조
- tracker-based, centralized 구조: 서버가
- 현재 인터넷 traffic의 20-50%는 bittorrent 사용
- 특별한 client 소프트웨어 필요
- torrent file: 트래커 주소 및 게시 파일에 관한 정보 포함
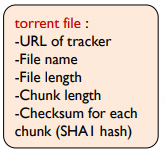
- torrent file: 트래커 주소 및 게시 파일에 관한 정보 포함
- Torrent: 파일을 주고 받는 peer들 (torrent의 peer들이 파일 chunk를 주고받음)
3 Entities
- Tracker: swarms 관리
- Seeders: 전체 데이터를 가진 peer -> leecher들에게 파일 업로드
- Leecher: swarm에서 전체 데이터를 갖고 있지 않은 peer (non-seeder peer) -> 파일 다운 중
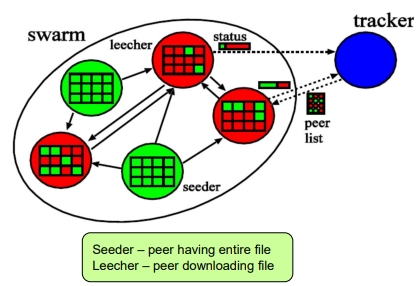
- Swarm: 동일한 파일 식별자를 갖는 peer 그룹 (file directory, file piece, file information ... )
- 파일 식별자 (file identifier)는 Queen Bee (여왕벌처럼 swarm의 기준이 됨)
Operation
- seeder가 entire file를 공유할 때, 이를 tracker에게 알린 뒤 torrent file을 웹 서버에 업로드
- 콘텐츠를 다운로드 하려는 client는 웹 서버로부터 torrent file 찾음
- torrent file의 정보로 client는 tracker와 TCP연결 요청
-> client는 tracker에게 콘텐츠와 관련된 peer 목록을 요청
-> tracker는 원하는 swarm의 존재 확인 및 swarm에서의 peer 수와 peer들의 IP 제공 - client는 tracker를 거치지 않고 목록의 peer들과 직접 통신
- 다른 peer들도 동일한 절차로 콘텐츠 조각을 가져오고 모음
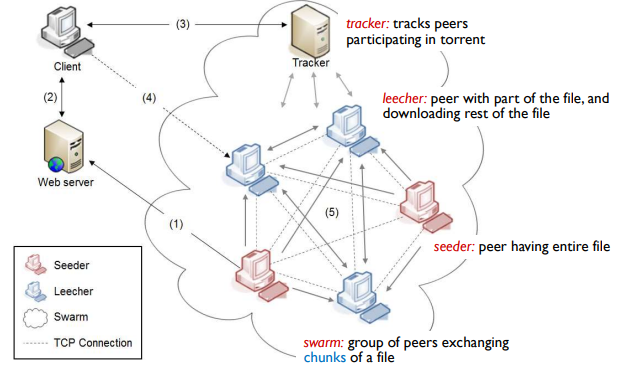
- tracker는 여러 peer들의 IP를 제공할 수 있다
- 하나의 peer가 아닌, 여러 peer들의 집합인 네트워크의 형태로 제공받아 연결 가능
Requesting chunks vs Sending chunks(tit-for-tat)
- Reqeusting chunks
- 각 peer들은 언제든지 파일 chunk subset을 가짐 (항상 entire file이 아님
- 주기적으로 각 peer들에게 어떤 chunk를 가지고 있는지 물어봄 -> chunk list 요청
- 요청은 rerest first: 희귀한 chunk부터 요청 (가지고 있는 peer가 적은 chunk부터, peer들이 떠날 수도 있으니까)
- Sending Chunks
- 요청 받으면 보내줘야 한다
- 자기한테 가장 높은 속도로 chunk를 보내주고 있는 peer (많은 데이터를 주는 peer)가 우선순위가 높고, 우선순위가 높은 상위 네 명의 peer에게 chunk 보냄
- 다른 peer들은 chunk를 받지 못함 (choked)
- 10초마다 상위 네 peer 갱신
- 30초마다 랜덤으로 peer를 고르고 chunk 보내줌
- Optimistically unchoke (상위 네 명 말고 다른 애 골라주기)
- 랜덤으로 새로 선택된 peer가 상위 네 명에 들어갈 수도 있다
- tit-for-tat
- Alice와 Bob은 서로에게 탑 4가 아님
- Alice가 Bob을 optimistically unchoke -> Bob에게 chunk 보냄
- Alice가 보내주는 속도가 빨라서 Bob의 탑 4가 됐다
- Bob은 reciprocates(답례)로 Alice에게 chunk 보내줌
- Bob도 보내주는 속도가 빨라서 Alick의 탑 4가 됐다
-> 계속해서 더 나은 파트너를 고르고, 파일을 더 빠르게 전송받도록 노력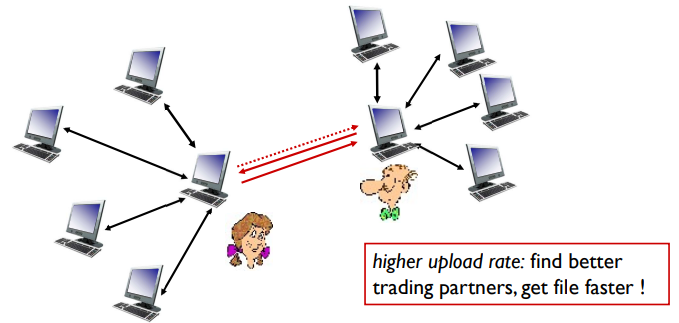
Kademlia P2P (KAD)
Chord
- 원형 DHT 기반 decentralized P2P 네트워크
- DHT기반 decentralized P2P 네트워크
- tree-based 라우팅
- 각 노드는 고유한 ID를 가짐 (무작위로 생성)
example Operation
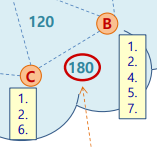
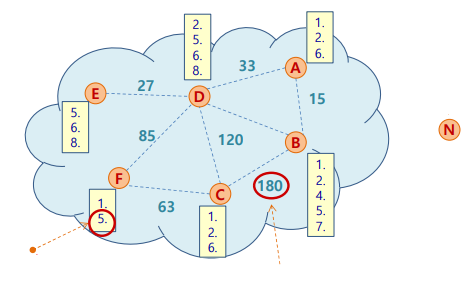
- certain content의 key
- peer F는 hash key가 5인 content를 가진 peer를 안다
- < key
5, valueIP address>- 두 peer간 거리
- 두 peer ID의 XOR 값
- XOR(ID-C, ID-B) = 180
- Initialization
- KAD 네트워크에 들어가고 싶은 새로운 Peer N
- N은 popular node를 안다 (B)
- N은 자신의 ID를 랜덤하게 생성한다
- KAD 네트워크에 들어가고 싶은 새로운 Peer N
- Bootstrap
- KAD에 가입하기 위해 N은 알고 있는 peer에게 자신의 ID로 bootstrap 요청을 보냄
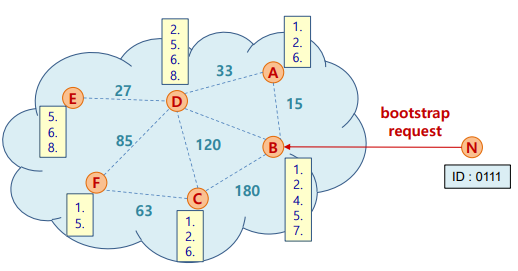
- KAD에 가입하기 위해 N은 알고 있는 peer에게 자신의 ID로 bootstrap 요청을 보냄
- Join
- B는 20개의 <key, value> 랜덤 리스트를 포함한 메세지를 반환
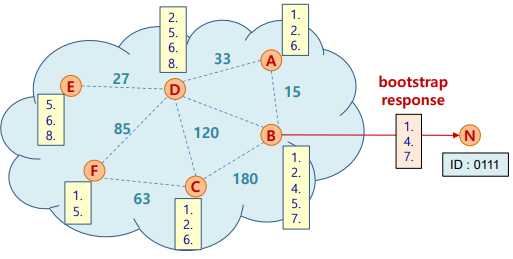
- B는 20개의 <key, value> 랜덤 리스트를 포함한 메세지를 반환
- Search an Object
- peer N이 hash key 8을 가진 파일을 열고자 할 때
- 목표까지 (보통 3번) 점프하는 과정을 반복하여 찾는다 (iterative lookup; parallel하게)
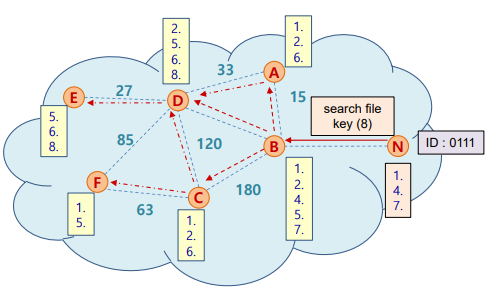
- Get response
- hash key 8을 가진 peer는 해당 정보를 peer N에게 반환
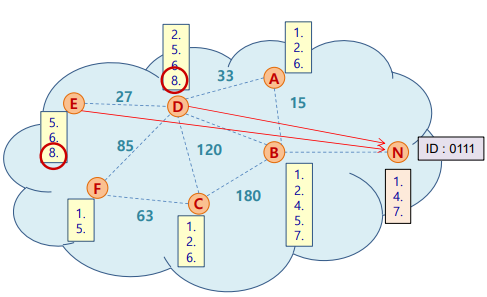
- hash key 8을 가진 peer는 해당 정보를 peer N에게 반환
- Peer selection
- 반환된 peer의 ID와 source(peer N)의 ID의 XOR값이 최소인 peer로 선택
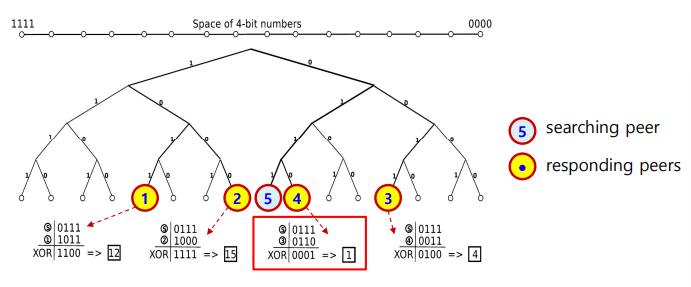
- 반환된 peer의 ID와 source(peer N)의 ID의 XOR값이 최소인 peer로 선택
- searching peer: peer N
- responding peer: peer B, E, D
- searching peer가 responding peer에게 search를 요청
- responding peer은 searching peer에게 정보 및 ID 반환
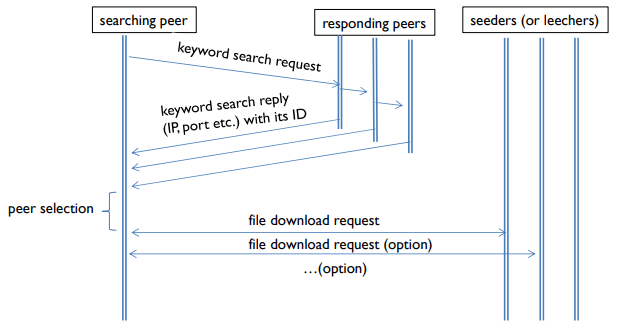
- Peer selection 뒤 file download 요청
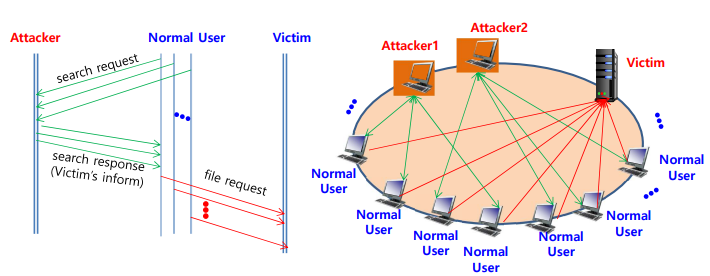
DDoS Attack Scenario
- node insertion attack
- searching peer ID와 최소 거리가 1인 ID를 악의적으로 만들어 그 노드를 삽입
- XOR (searching peer, ID attacker ID)=1
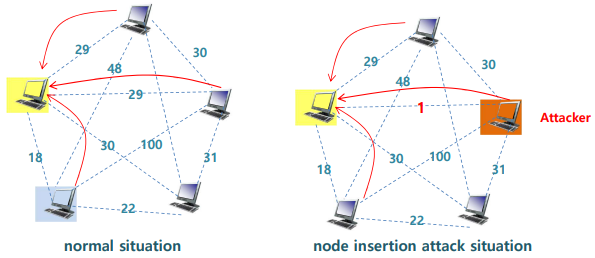
- 정상 peer들은 공격자로부터 정보를 받아 이 정보로 공격 대상에게 파일 다운로드를 요청하게됨