🔗https://programmers.co.kr/learn/courses/30/lessons/72412
처음 든 생각
백퍼 완전 탐색 하면 효율성 빵점일 것 같다..
이진탐색으로 lower bound upper bound 를 구한다음
upper bound - lower bound 하면 조건에 맞는 지원자 명수가 나오지 않을까? < bisect를 사용하자!
그리고 "-"가 나오는 경우를 풀어써서 해당 조건들을 다 검색하면 되지 않을까? < 여기서 부터 뇌정지
구글링 및 해설 참고...
구현
info 늘려주기
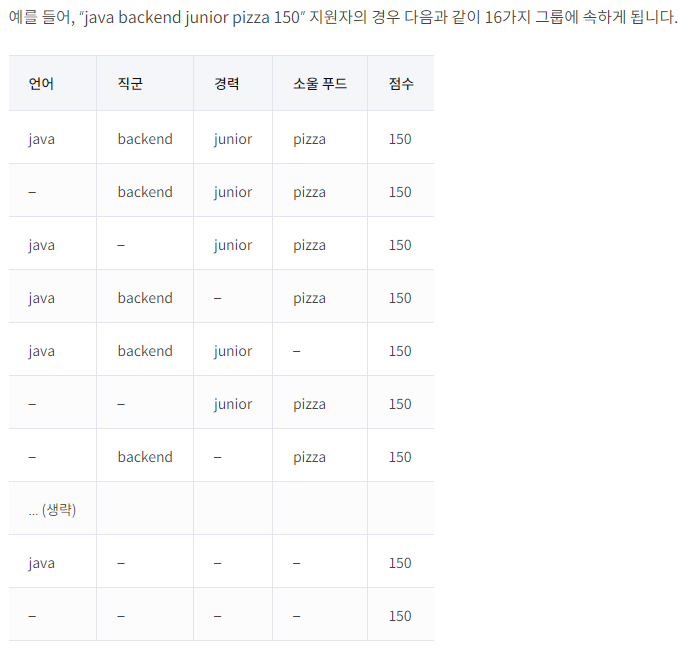
java backend junior pizza 150은 이런식으로 다양한 조건에 맞을 수 있음.
dic=defaultdict(list)
for i in info:
i=i.split()
score=int(i[-1])
condition=i[:-1]
for i in range(5): #총 16번 반복하게됨. "-"가 들어갈 수 있는 모든 경우를 넣어준다.
#i=0:[], i=1:[0],[1],[2],[3]
#i=2:[0,1],[0,2],[0,3],[1,2],[1,3],[2,3] i=3:[0,1,2],[0,1,3].. 이런식으로!
case=list(combinations([0,1,2,3], i))
for c in case:
tmp=condition.copy()
for idx in c: #조합해둔 리스트 요소를 따라서 인덱스에 "-"를 덮어써주면서 변형시킴
tmp[idx]="-"
key=''.join(tmp)
#dic에 해당 정보를 key로, 점수는 value로 해서 넣어준다.
dic[key].append(score)
for value in dic.values():
value.sort()info 리스트를 돌면서 지원자 한명마다 존재하는 열여섯가지의 경우의 수들을 이렇게 뻥튀기 해준다.
그리고 점수를 제외한 '언어,직군,경력,소울푸드' 경우의 수들을 딕셔너리의 키로 넣어주고, value에 해당 그룹의 점수를 추가 시켜준다. 그리고 이 value들을 오름차순 정렬시켜준다.
이 부분이 사실 너무 이해가 안갔는데.. 딕셔너리를 한번 출력해보면 이해가 간다.
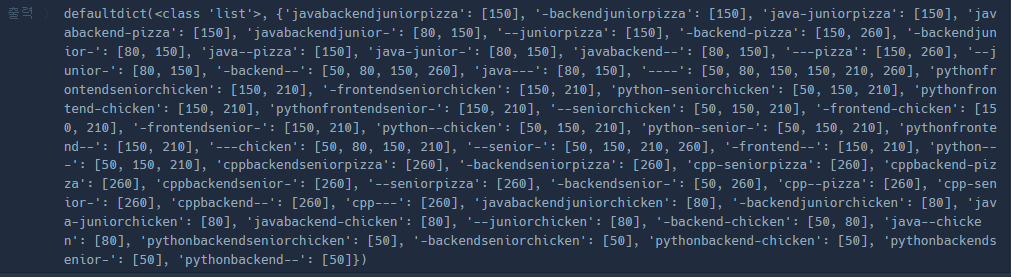
중간에 '----':[50,80,150,150,210,260]를 보면 알다시피 모든 지원자의 점수가 오름차순 정렬한채로 들어가있음!!
왜 defaultdict?
사실 defaultdict도 이번에 처음 봤다...
defaultdict()는 딕셔너리를 만드는 dict클래스의 서브클래스이다.
작동하는 방식은 거의 동일한데, defaultdict()는 인자로 주어진 객체(default-factory)의 기본값을 딕셔너리의 초깃값으로 지정할 수 있다.
숫자, 리스트, 셋등으로 초기화 할 수 있기 때문에 여러 용도로 사용할 수 있다.
출처 - [파이썬 기초] 유사 딕셔너리 defaultdict() 활용법
여기서 중요한 점은 기본값을 초깃값으로 지정해줄 수 있는 것 같음!
여태 우리가 파이썬에서 딕셔너리를 사용할 때, value가 리스트형태일 경우 key가 기존에 있는거면 바로 append를 시켜줄 수 있지만, 기존에 없다면 케이스를 나눠서 value를 따로 추가를 시켜줘야했는데 그걸 편리하게 하기 위해 많이 사용하지 않았을까? 싶다. 근데 기존 dict로 충분히 구현 가능할듯!
이진 탐색
for query in queries:
q=[]
#"and" 지워준다
query=query.replace("and","")
query = query.split()
#점수와 다른 정보들을 따로 저장
score=int(query[-1])
query=''.join(query[:-1])
count =0
if query in dic: #만약 해당 query가 dic에 존재한다면
target=dic[query] #key가 query인 value(점수 리스트)를 불러옴
idx=bisect_left(target,score) #점수 리스트를 이진탐색(lower bound)해서, 가장 먼저!! score보다 큰 점수가 나오는 곳을 찾는다.
count=len(target)-idx #이미 점수가 오름차순 정렬되어있기 때문에, '리스트의 길이-해당 인덱스'를 하면 해당 점수보다 큰 지원자 수를 알수 있음!!
answer.append(count)lower bound / upper bound
lower bound : 찾고자 하는 값보다 이상인 값이 처음 나타나는 위치 찾기
upper bound : 찾고자 하는 값보다 초과된 값이 처음 나타나는 위치 찾기
bisect
bisect_left(범위, left_value) => 왼쪽 인덱스를 구하기
bisect_right(범위, right_value) => 오른쪽 인덱스를 구하기
성공 코드
from bisect import bisect_left
from collections import defaultdict
from itertools import combinations
def solution(info, queries):
answer = []
dic=defaultdict(list)
for i in info:
i=i.split()
score=int(i[-1])
condition=i[:-1]
for i in range(5):
case=list(combinations([0,1,2,3], i))
for c in case:
tmp=condition.copy()
for idx in c:
tmp[idx]="-"
key=''.join(tmp)
dic[key].append(score)
for value in dic.values():
value.sort()
for query in queries:
q=[]
query=query.replace("and","")
query = query.split()
score=int(query[-1])
query=''.join(query[:-1])
count =0
if query in dic:
target=dic[query]
print(target)
idx=bisect_left(target,score)
count=len(target)-idx
answer.append(count)
return answer