[CVPR2023] SkyEye: Self-Supervised Bird’s-Eye-View Semantic Mapping Using Monocular Frontal View Images
논문리뷰
- Affiliation: University of Freiburg
- Project page: http://skyeye.cs.uni-freiburg.de/
- Code:
not yet - Video: https://www.youtube.com/watch?v=PGne5XG4f_8
Introduction
왜 BEV Segmentation을 해야할까?
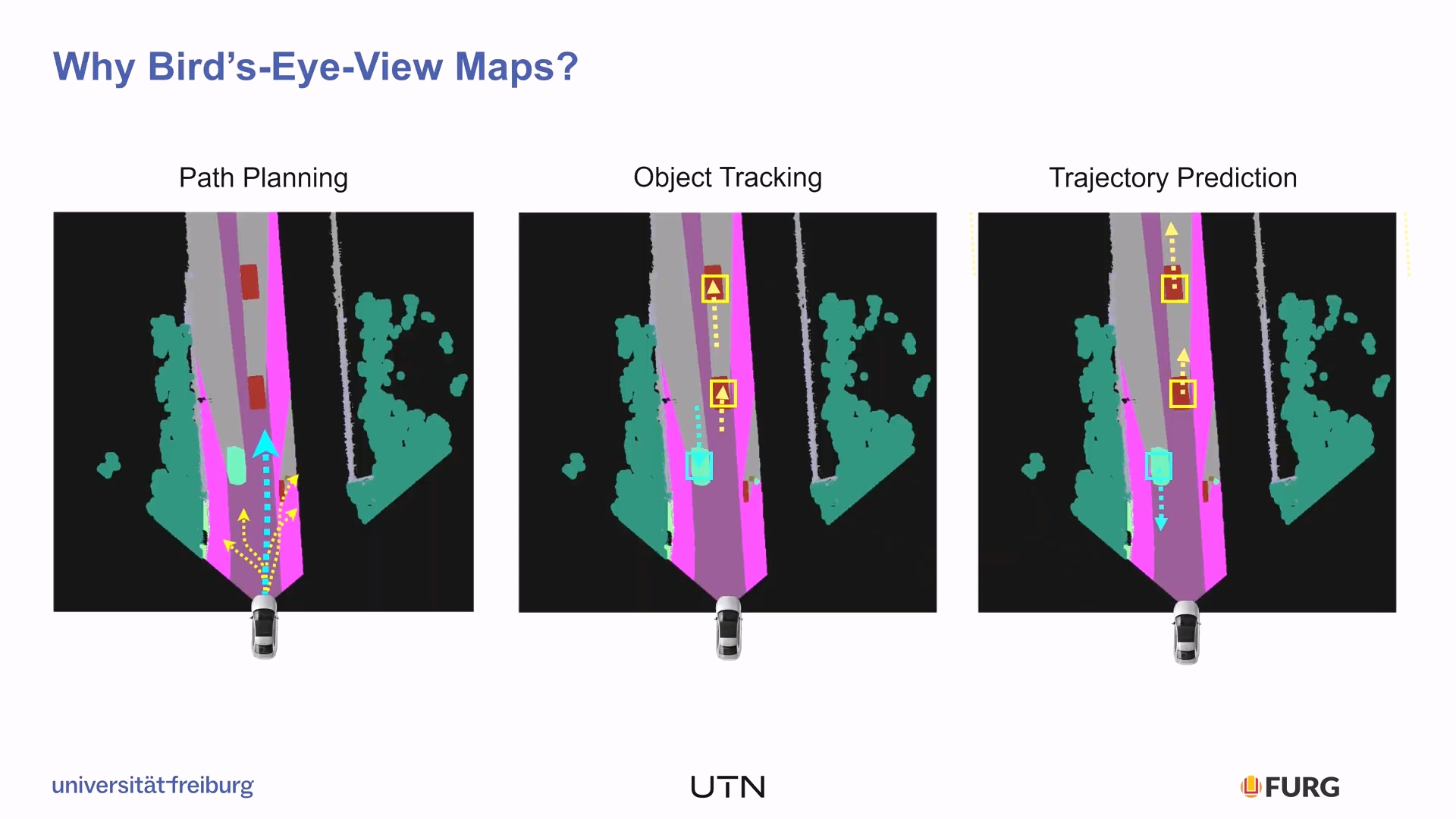
우리가 평소에도 자동차 네비게이션에서 Bird's eye view를 사용하는 것은 정면을 보는 것과는 다른 이점이 있기 때문이다. 가장 두드러진 장점은 경로를 미리 예측하기 좋다는 것이다. 내비게이션 시스템을 벗어나서 그 위에 각 object들도 표현이 된다면 각 객체의 위치를 파악하기 수월하며 이를 이용하여 다른 객체들의 행동 예측하고 액션을 결정(decision-making tasks) 하기 좋기 때문에 주행에서 사용하기에 풍부한 정보(rich representation)를 담아낼 수 있다.
이렇게 좋은 BEV Segmentation을 기술적으로 구현하기 위해서는 사실 굉장한 어려움이 있는데 언제나 그렇듯 학습 데이터다.
이 논문은 BEV Segmentation의 최대 난제인 데이터셋 구축의 어려움을 해결하고자 한다.
그러면 BEV Segmentation에서 사용하고 있는 데이터셋 구축 방법부터 알아보자.
- 데이터를 직접 annotate 하기
- 위성 지도 혹은 HDMap에서 masking을 할 수도 있고, LiDAR data와 같은 pcd 데이터에서 3D bounding box를 이용하여 객체들을 따로 annotate할 수도 있다.
- Simulator 이용하기
- Simulator에 공간을 구축하고 그 공간에서는 카메라를 자유롭게 설정할 수 있으니 하늘에서 바라보는 뷰와 함께 싱크를 맞추어 데이터를 취득한다.
이와 같은 방식들은 문제가 있는데, 저자가 주장하는 바는 아래와 같다.
- Cumbersome of annotate: 비용이 너무 비싸다
- Sim-to-Real gap: 시뮬레이터와 실제 환경 사이의 도메인 갭이 무조건 존재할 수 밖에 없다
그래서 그것을 FV(정면뷰)의 데이터셋(이미지+mask)만 가지고
Self-Supervised로 풀어보겠다!!
Method
Network Architecture
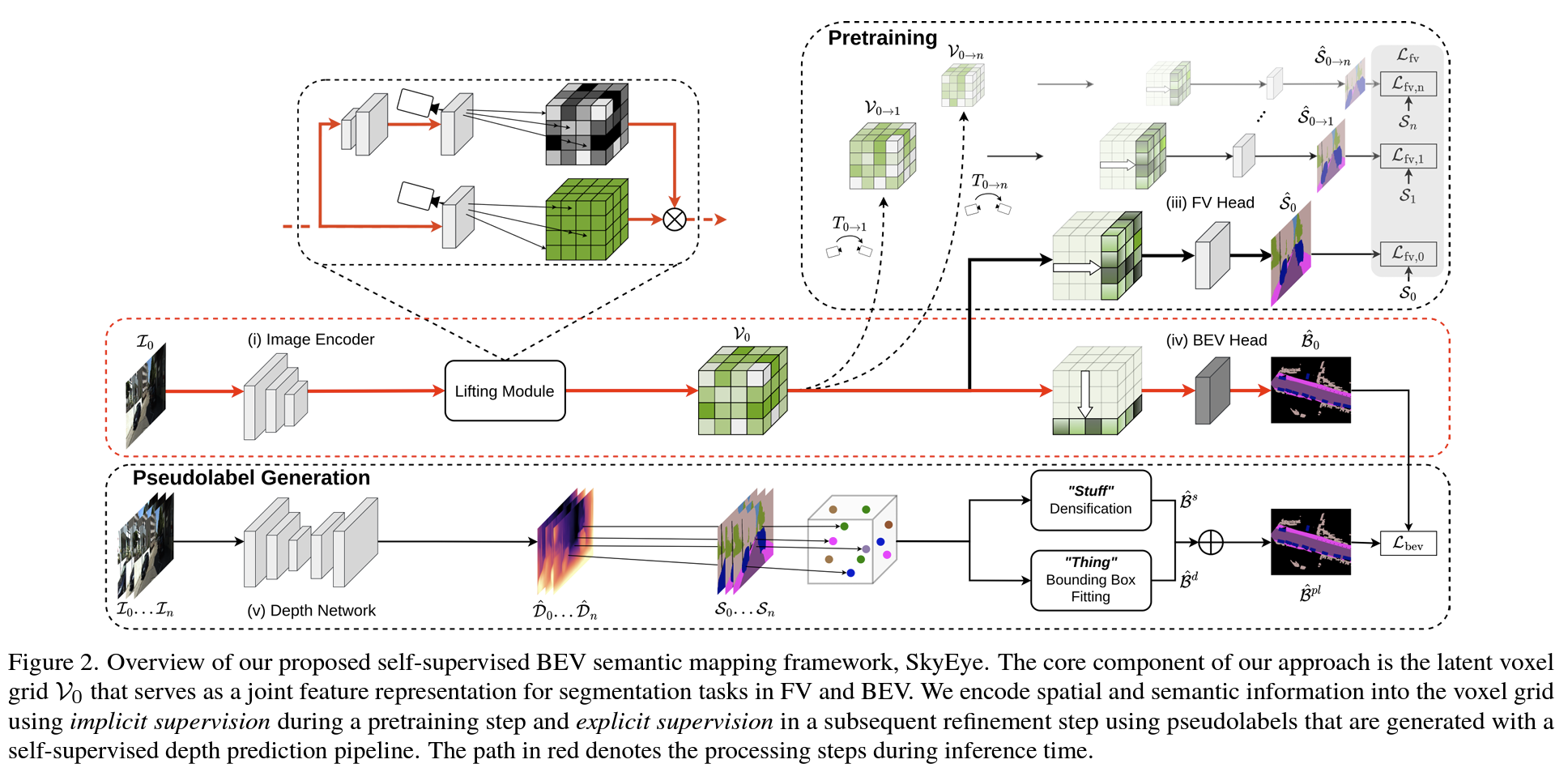
기능별 part
1. Image encoder to generate 2D image features
2.Lifting moduleto generate the 3D voxel grid using a learned depth distribution
3.FV semantic headto generate the FV semantic predictions for implicit supervision
4. BEV semantic head to generate the BEV semantic map
5. independent self-supervised depth network togenerate the BEV pseudolabels
Lifting module
2D feature를 3D voxel grid로 mapping하는 것을 담당한다. 이 과정에서 camera projection 방식을 이용하는데 학습된 depth distribution을 사용한다.
이 부분이 이해가 잘 가지 않는데, 여기서 말하는
depth distribution은 architecture 그림에 나와있는 pseodolabel에 사용된 depth network와 완전히 별개이다. 이 부분이 헷갈릴까봐 저자도 그것을 명시해서 써놨다. paper에는likelihood of features in a given voxel을 제공하는 것이depth distribution이라고 한다.
- lift에 대하여
출처: Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
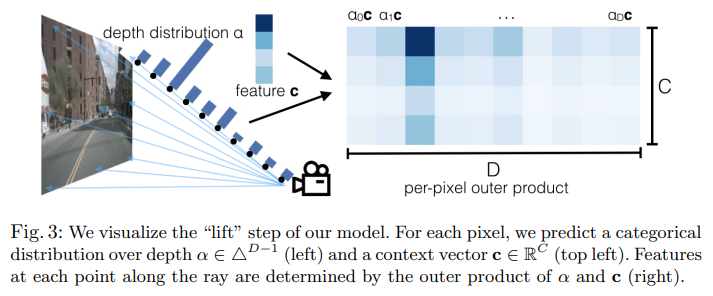
- 카메라 ray 상에 D개의 point(거리마다)가 있을 때 각 point의 거리의 분포도
FV(Frontal Veiw) semantic head (=Implicit Supervision)

여기서 여러 time step의 segmentation을 추정하는데, 이때 각 time step의 여러 장의 이미지가 아니라 첫번째 하나의 이미지만 사용된다. 이렇게 생성하는데는 2가지 의도가 있다.
(이 2가지 의도라는 것은 순전히 저자의 의도이지 이것이 진짜 효과가 있는 지 증명되어 있지는 않다.)
- the network generate a spatially consistent volumetric representation of the scene from a single FV image
: 공간적인 일관성을 유지하도록 도움을 주기 위해
- the voxel grid encode complementary information from multiple images to resolve occlusions and hence play a pivotal role in generating accurate BEV semantic maps from the limited view of only a single time step.
: 여러 이미지의 상호 보완적인 정보를 인코딩하여 occulusion을 해결하기 위해
이렇게 여러 time step의 semantic map을 추정하게 되면 dynamic object에 대해서 맞지 않는 경우가 발생할 수 있기 때문에 time이 멀어질 수록 weight를 작게 주어 loss에 반영한다.
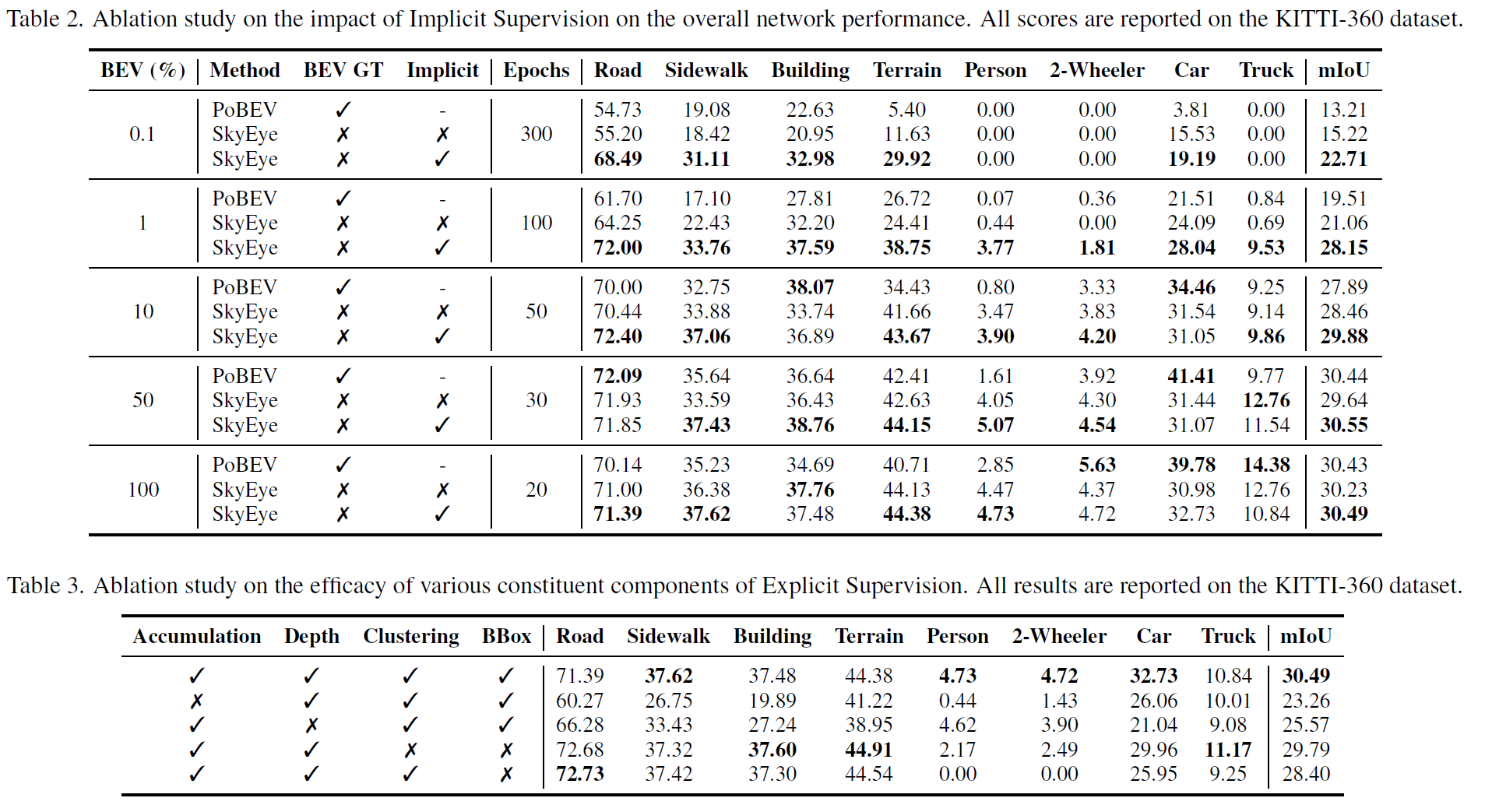
BEV pseudolabels (=Explicit Supervision)

여러 step의 이미지를 입력으로 해서 monodepth2 network를 사용하여 depth를 추론하고, camera intrinsics과 poses 정보를 알고 있으므로(KITTI는 pose 정보까지 제공) 여러 step의 depth prediction된 결과를 중첩해서 pcd 데이터를 생성한다.
이 중에서 stuff에 해당하는 클래스는 morphological dilate+erode를 수행하여 pcd를 densify한다.
그 다음으로 thing에 해당하는 클래스는 box를 fitting한다. 그런데 FV data에는 instance 정보가 annotate 되어있지 않으며 추론된 depth마저도 outlier가 발생하기 쉽다. 그래서 DBSCAN을 이용하여 각 instance를 clustering했는데 여러가지 heuristic한 기법들(M개 clustering하고.. RANSAC돌리고.. ellipse 찾고.. center point+theta 찾고.. 등)을 적용하여 instance를 box 형태로 생성했다.
그리고 이 둘을 합쳐서 최종 pseodolabel을 완성한다.
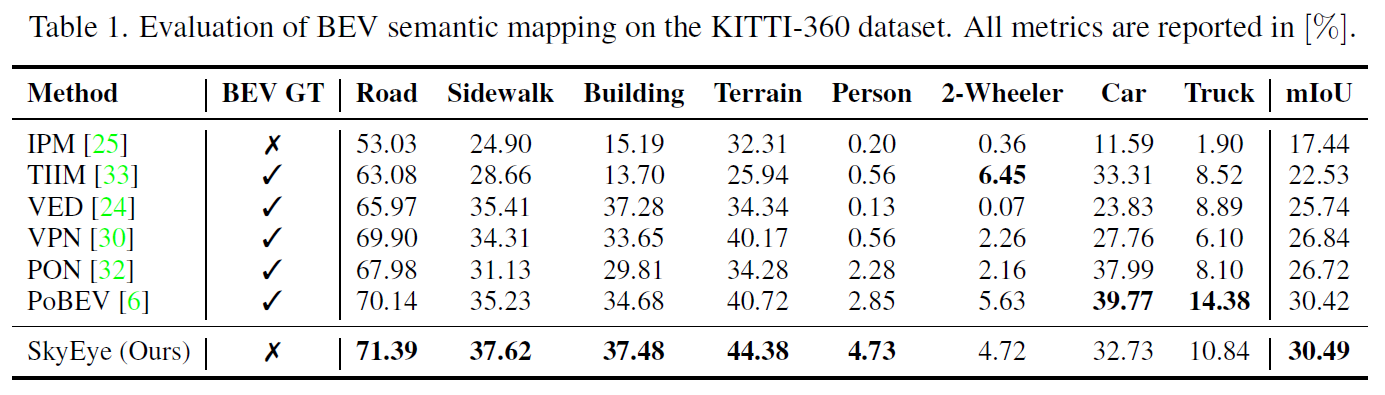
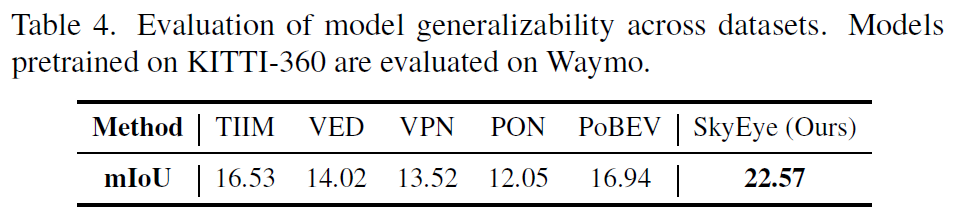
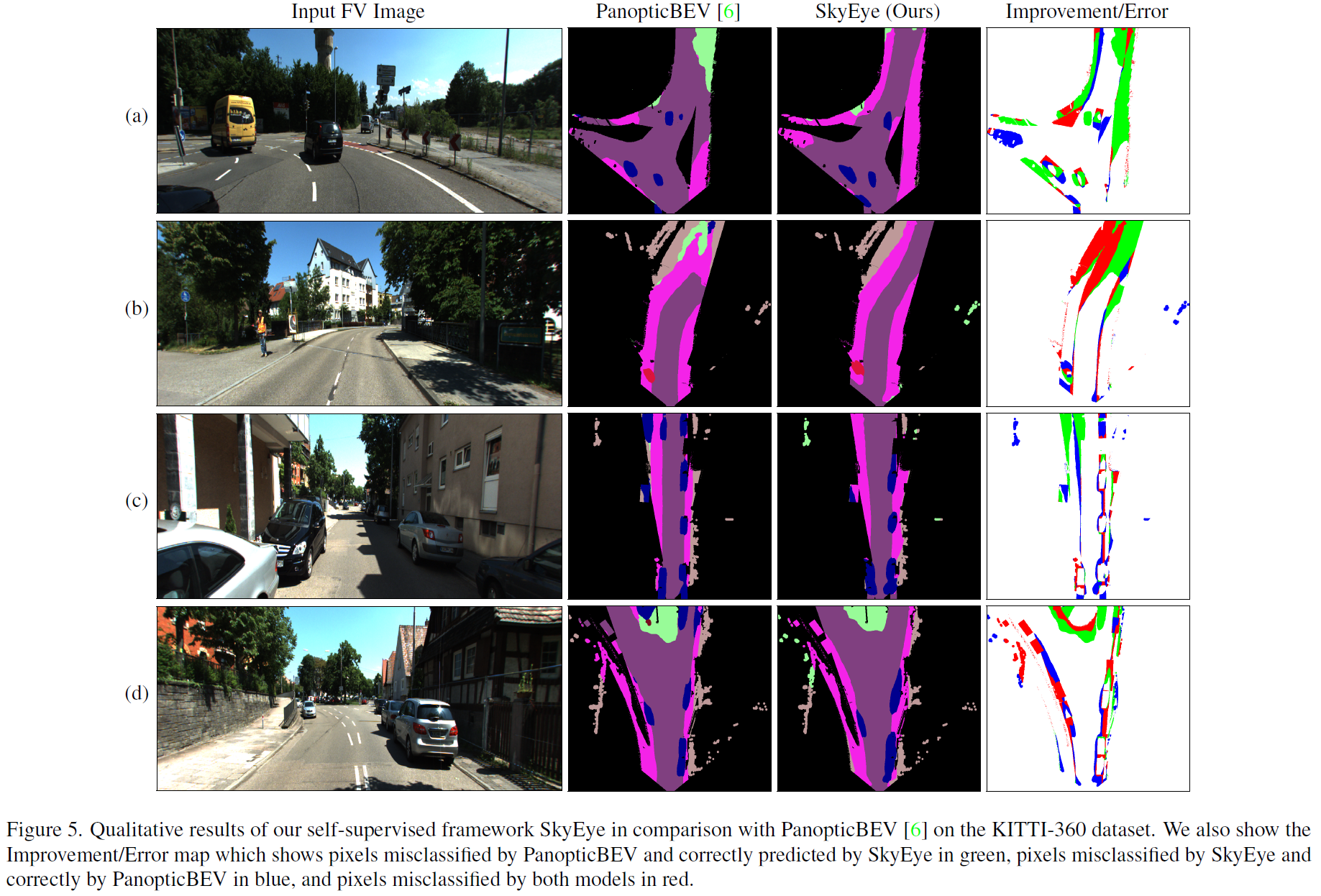
Result
Generalizability(KITTI -> Waymo)를 확인한 부분을 보면 이 방법이 꽤 유효한 것을 알 수 있다.